Chapter 3 Special Relativity — Lorentz Transformations and Physical Consequences¶
Story so far: In Ch. 1, we saw the successes and limitations of Newton's gravitational model—the 43″/century discrepancy in Mercury's perihelion precession, and the structural problem that the Poisson equation contains no time derivative, implying gravity propagates instantaneously. In Ch. 2, we laid out the blueprint of "constructing physical laws that do not depend on coordinate systems," surveyed the tool of tensors, and took a bird's-eye view of the overall picture of describing gravity as curvature of spacetime. From this chapter onward, we implement that blueprint concretely, one step at a time.
Goals of This Chapter
- From the tensor hierarchy surveyed in Ch. 2, derive the most fundamental rank-0 tensor (invariant)—a quantity whose value does not change under coordinate transformations—the spacetime interval \(ds^2\), starting from the principle of the constancy of the speed of light
- From there, derive the Lorentz transformation, and understand the physical consequences of special relativity: relativity of simultaneity, time dilation, and length contraction
- This chapter focuses on the "physics of special relativity"; the mathematical tools for describing Minkowski spacetime (metric, 4-vectors, tensors) will be developed in the next chapter
3.1 Two Postulates¶
🟡 Lina: At the end of Ch. 2, I previewed the derivation of the spacetime invariant \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\). To derive this expression, we first need to confirm the postulates that serve as our starting point—the foundation that we "accept as experimental fact." Special relativity begins with just two postulates.
Postulate 1 (Principle of Relativity): The laws of physics take the same form in all inertial frames.
Postulate 2 (Principle of the Constancy of the Speed of Light): The speed of light in vacuum \(c\) is constant, independent of the motion of the source or the observer.
🔵 Kai: What exactly is an "inertial frame"?
🟡 Lina: You can think of it as the coordinate system of an observer who is neither accelerating nor rotating. It's the world as seen by an observer in uniform straight-line motion (or at rest). When a train runs at constant speed in a straight line, the coordinate system of a person inside that train is an inertial frame. When the train accelerates or goes around a curve, it is not an inertial frame.
🔵 Kai: I see, that gives me a good picture. Postulate 1 has been around since Galilei's time, right? Like how throwing a ball inside a train moving at constant velocity gives the same equations of motion as on the ground.
🟡 Lina: Exactly. To be a bit more precise, for forces that depend only on the relative positions of particles—like Newtonian gravity—even when coordinates shift under a Galilean transformation, relative positions don't change, so the form of the equations of motion is preserved. For example, the gravitational force between two particles depends only on their relative position \(\mathbf{r}_1 - \mathbf{r}_2\), so even if you shift the coordinate origin, the force equation keeps the same form. However, Postulate 1 is restricted to "inertial frames."
⚪ Mei: "Restricted to inertial frames" means that in accelerating coordinate systems, the form of physical laws changes?
🟡 Lina: Yes. Einstein himself was dissatisfied with this restriction. "Why should inertial frames be special? Shouldn't the laws of physics take the same form in all coordinate systems?"—this question became one of the motivations that later gave birth to general relativity (1915). But let's start with the story between inertial frames first.
🟡 Lina: The issue is with Postulate 2. Under Galilean transformations, velocities simply add and subtract, so having a constant speed of light leads to a contradiction. In other words, we must modify the Galilean transformation itself. Let me summarize the relationship between the two postulates in a table.
Table 3.1: Comparison of the two postulates of special relativity
| Postulate 1 (Principle of Relativity) | Postulate 2 (Constancy of the Speed of Light) | |
|---|---|---|
| Content | Physical laws take the same form in all inertial frames | The speed of light \(c\) is constant regardless of source or observer motion |
| History | Has existed since Galilei's era | Supported by the 1887 Michelson-Morley experiment |
| Consistency with Galilean transformation | Consistent | Contradictory (velocity addition fails) |
| Consequence | Coordinate transformations don't change the form of physical laws | Time and space mix together → Lorentz transformation required |
🔵 Kai: How exactly does the contradiction arise?
🟡 Lina: In everyday terms, if you throw a ball forward from a moving train, the ball's speed as seen from the ground is "train speed + ball speed":
This is velocity addition under the Galilean transformation. Behind this addition rule lies the implicit assumption that "time is the same for all observers"—that is, \(t' = t\). However, even if you shine light forward from a moving train, the speed of that light as seen from the ground is not "train speed + \(c\)" but remains \(c\). The Galilean velocity addition rule does not hold for light.
⚪ Mei: So somewhere in the Galilean assumption—\(t' = t\), that is, time is absolute—something must be wrong.
🟡 Lina: Exactly. Both time and spatial coordinates must be treated as quantities that change depending on the observer. However, to reach that conclusion, we need experimental support.
🔵 Kai: Has it been experimentally verified that the speed of light is constant?
🟡 Lina: Yes. The 1887 Michelson–Morley experiment failed to detect any directional dependence of the speed of light down to the order of \(\sim 10^{-8}\). At the time, it was believed that a medium called the aether existed to carry light, and if the Earth were moving relative to the aether, a directional dependence in the speed of light should appear—the experiment tried to detect this. The result was "no anisotropy." Subsequent improved experiments dramatically increased the precision, and modern laser resonator experiments have confirmed the isotropy of the speed of light (no difference depending on direction) to the order of \(10^{-18}\). Furthermore, the Kennedy–Thorndike experiment and its modern versions have verified with high precision that the speed of light does not depend on the observer's velocity either. The constancy of the speed of light is an extremely solid experimental fact.
⚪ Mei: \(10^{-18}\)... that's essentially perfectly constant.
🟡 Lina: Yes (see also Fig. 3.1 "Conceptual diagram of the Michelson-Morley experiment"). Einstein's revolution was in accepting this experimental fact as a fundamental principle of physics rather than patching it with ad hoc fixes.
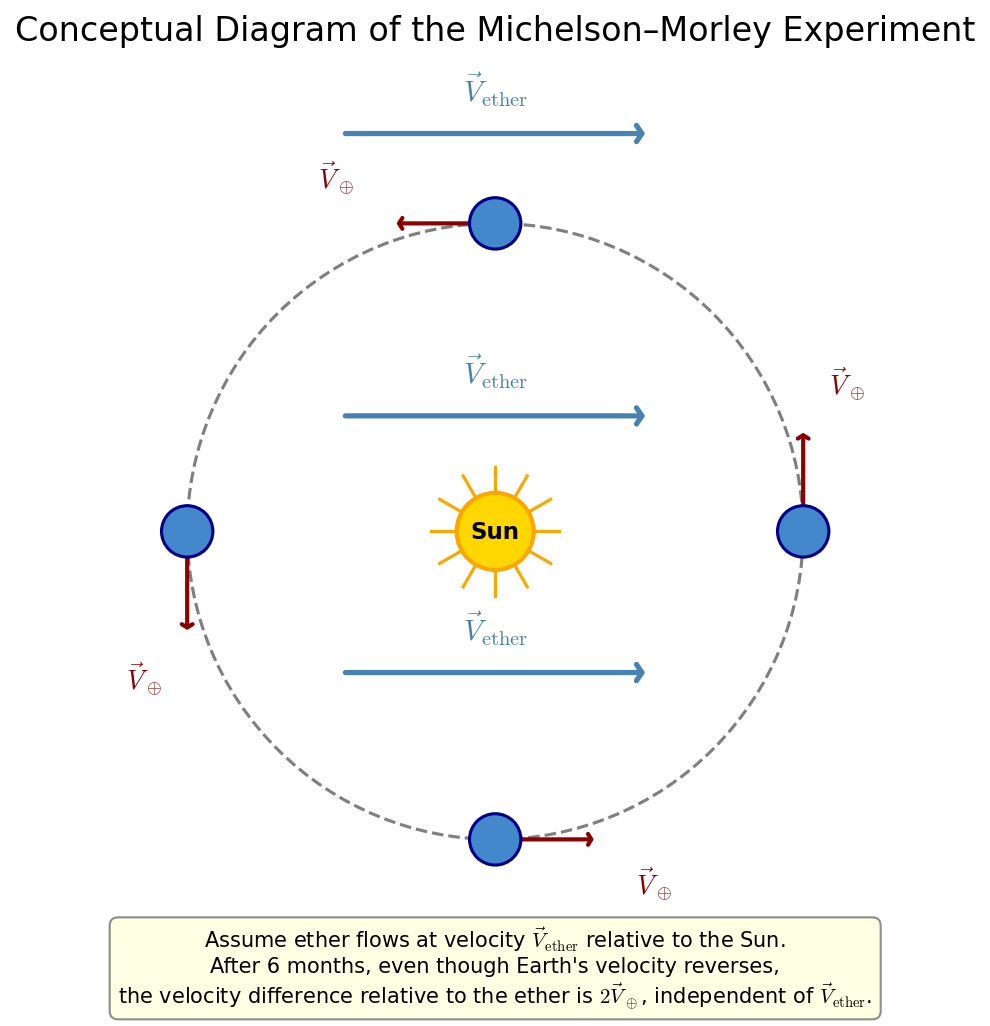
Fig. 3.1: Conceptual diagram of the Michelson-Morley experiment. The experiment attempted to detect the Earth's motion relative to the aether, but no anisotropy of the speed of light was found.
Now let's trace what follows from these two postulates—step by step.
✅ Comprehension Check: Why does the Galilean transformation contradict the principle of the constancy of the speed of light?
Answer
Under the Galilean transformation, velocities simply add (\(v_{\text{ground}} = v_{\text{train}} + v_{\text{ball}}\)). According to this rule, the speed of light emitted from a moving source should depend on the observer's state of motion and differ from \(c\), but the principle of the constancy of the speed of light requires that the speed of light is \(c\) in every inertial frame. This contradiction implies that the Galilean assumption of absolute time (\(t' = t\)) does not hold.
✅ Comprehension Check: State the two postulates of special relativity.
Answer
Postulate 1 (Principle of Relativity): The laws of physics take the same form in all inertial frames. Postulate 2 (Principle of the Constancy of the Speed of Light): The speed of light in vacuum \(c\) is constant, independent of the motion of the source or the observer.
✅ Comprehension Check: What is an inertial frame? Give one example of a frame that is not inertial.
Answer
A coordinate system of an observer who is neither accelerating nor rotating. The world as seen by an observer in uniform straight-line motion (or at rest). Examples of non-inertial frames: the interior of an accelerating train, the interior of a train going around a curve, on a rotating amusement park ride, etc.
🟡 Lina: Let's build a concrete picture of what the principle of the constancy of the speed of light means. Place a light source at the origin of inertial frame \(S\), and suppose it emits light at time \(t = 0\). Light travels in all directions at the same speed \(c\) in vacuum, so at time \(t\), the points \((x, y, z)\) that light has reached lie on a sphere of radius \(ct\) (Fig. 3.2 "Time evolution of a spherical light wavefront").
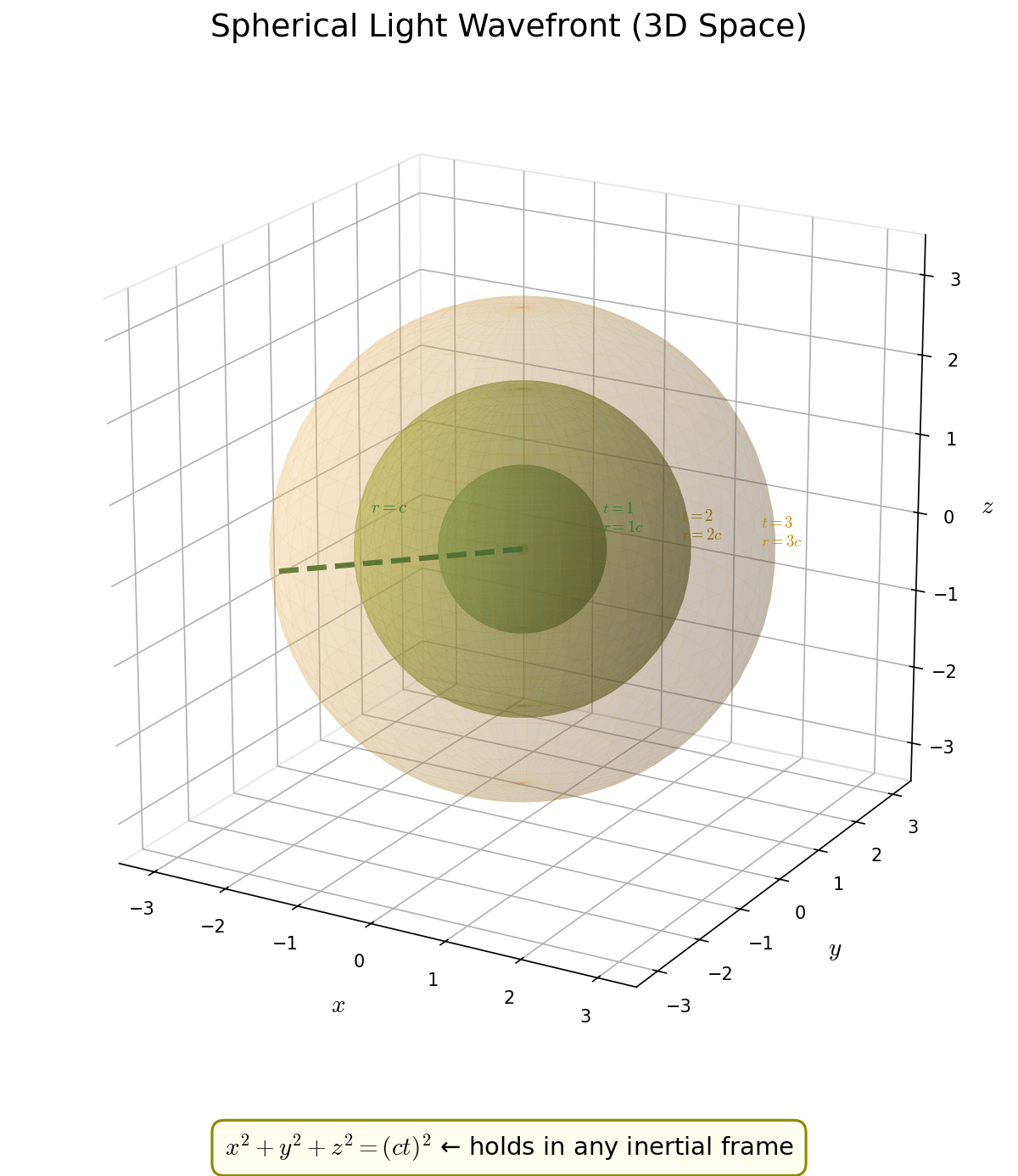
Fig. 3.2: Time evolution of a spherical light wavefront. Light emitted from a source at the origin spreads at equal speed in all directions, reaching a sphere of radius \(r = ct\) at time \(t\). Spheres at three times \(t = 1, 2, 3\) are shown overlaid.
🔵 Kai: The sphere having radius \(ct\) means \(x^2 + y^2 + z^2 = (ct)^2\), right? But if you look at this from another inertial frame, the light source is moving, so the center of the sphere shifts... wouldn't it stop being a sphere?
🟡 Lina: That's exactly the point of the constancy of the speed of light. Even when the same light is observed in another inertial frame \(S'\) (with coordinates \((t', x', y', z')\)), the speed of light remains \(c\). So in the \(S'\) frame too, \(x'^2 + y'^2 + z'^2 = c^2 t'^2\) holds. In every inertial frame, light spreads as a sphere—the sphere drawn in Fig. 3.2 "Time evolution of a spherical light wavefront" also appears the same way in the \(S'\) frame (centered on the origin of \(S'\)). This is the concrete meaning of the constancy of the speed of light. From this fact, the form of the spacetime invariant is determined.
⚪ Mei: So in every inertial frame, it appears as "a sphere centered on oneself"—that's the concrete content of the constancy of the speed of light.
3.2 Invariance of the Spacetime Interval¶
🟡 Lina: In this section, I'll first find the invariant for light. Using the principle of the constancy of the speed of light, the form of \(ds^2\) is uniquely determined. After that, we'll confirm the physical meaning of \(ds^2\) (events, light cones, the three-fold classification), and then prove that \(ds^2\) is an invariant even for general cases beyond light, establishing the universality of the spacetime interval—that's the flow. But before that, we need some preparation about what form to write the invariant in. Let's first confirm "why define it as the square of an infinitesimal quantity" and "why a quadratic combination," and then use the constancy of the speed of light to determine the signs.
Why Define It as the "Square of an Infinitesimal Distance"¶
🟡 Lina: Before we get into the spacetime invariant \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\), let's first confirm "why this form."
🔵 Kai: The invariant in 3-dimensional space was the distance \(\ell = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + (z_2 - z_1)^2}\). First, why do infinitesimal quantities like \(dx\) and \(dt\) appear?
🟡 Lina: Because in what follows, we need to account for the possibility that spacetime is curved. When it's curved, this formula can't be used. Think of the Earth's surface. For example, you can't calculate the distance between Tokyo and New York just from the difference in latitude and longitude, right? Because the sphere is curved. But in a very small region at your feet—about one square meter—the ground looks flat.
🔵 Kai: Ah, so that's why we write it with infinitesimals. Even if it's curved, in a sufficiently small region it looks flat.
🟡 Lina: Exactly. Even in curved space, a sufficiently small region is locally flat—the same idea as how zooming in enough on Google Maps makes the curvature invisible and it looks like a flat map. For any smoothly curved surface, no matter how curved, you can cut out a sufficiently small region and approximate it as flat. So for the infinitesimal distance between two very close points, the Pythagorean theorem can be used directly:
When you need a finite distance, you accumulate (integrate) this infinitesimal distance \(d\ell\) along the path—the same idea as approximating the length of a curved road by adding up short straight segments. So defining the invariant in the form of an infinitesimal distance \(d\ell\) is the universal way of writing it that also works in curved space.
🔵 Kai: Next question. Why does the time term have a minus sign? If we follow the same idea as for space, it seems like we should write \(ds = \sqrt{(cdt)^2 + dx^2 + dy^2 + dz^2}\) with everything positive—
🟡 Lina: You're right. I'll derive why it's minus from the principle of the constancy of the speed of light shortly. Before that, let me confirm one thing: why do we define the spacetime invariant in the squared form \(ds^2\) rather than taking the square root \(ds = \sqrt{\cdots}\) as in space? To preview the conclusion, the spacetime invariant has a minus sign on the time term (the reason will be derived shortly). Then the quantity inside the square root can be negative—and you can't take the square root of a negative number within the real numbers. That's why in spacetime we define the invariant in the squared form \(ds^2\), before taking the square root.
⚪ Mei: I see, since we can't always take the square root, we define it as the square. That's reasonable.
Narrowing Down the Form of the Spacetime Invariant¶
🟡 Lina: Now let's see why the time term has a minus sign. The infinitesimal distance in 3-dimensional space was \(d\ell^2 = dx^2 + dy^2 + dz^2\). When we extend this to 4-dimensional spacetime, what form does it take? We'll narrow it down using two conditions.
Condition 1: It must be a "sum of squares" of coordinates¶
🟡 Lina: Looking at the 3-dimensional distance \(d\ell^2 = dx^2 + dy^2 + dz^2\), everything is a sum of squares of coordinates. When extending to spacetime, let's assume the form is also a sum of squares of coordinates.
🔵 Kai: Why the squared form?
🟡 Lina: There are two intuitive reasons. The first is independence of direction. I said "the square of the infinitesimal distance," but what if a first-order term—like \(dx\)—were mixed into \(ds^2\)? Think about it. Moving in the \((1, 0)\) direction (positive \(x\)) by \(d\ell\), the first-order term \(dx\) contributes \(+d\ell\). But moving in the \((-1, 0)\) direction (negative \(x\)) by the same \(d\ell\), the contribution is \(-d\ell\)—the sign changes. So first-order terms carry directional dependence and cannot be included in an isotropic invariant. On the other hand, \(dx^2 + dy^2\) (second order) gives the same value \(d\ell^2\) whether you go in the \((+1, 0)\) or \((-1, 0)\) direction.
🔵 Kai: Indeed, since the Pythagorean theorem has the form \(dx^2 + dy^2\), the distance is determined regardless of direction.
🟡 Lina: The second reason is that terms of third order and higher are negligible compared to second order. Since we're considering the square of an infinitesimal distance \(d\ell^2\), the lowest order in the expansion is second order. If third-order or higher terms (like \(dx^3\) or \(dx^2 \cdot dy\)) were mixed in—think about it concretely. When \(dx = 0.001\), \(dx^2 = 0.000001\), \(dx^3 = 0.000000001\). The third-order term is only one-thousandth of the second-order term. The smaller \(dx\) is, the larger this gap becomes, so even if you add higher-order corrections to a second-order expression, they vanish in the infinitesimal limit. In summary: first order is no good (it depends on direction), third order and higher are negligible compared to second order in the infinitesimal limit—so second order remains.
⚪ Mei: So "the lowest order that doesn't depend on direction" is second order—that's why the invariant is a quadratic combination.
🟡 Lina: Right. In 4-dimensional spacetime as well, we assume the invariant takes the form of a sum of squares of coordinates:
where \(A, B, C, \ldots\) are coefficients to be determined.
🔵 Kai: Are there cross terms (the \(C\) term)?
🟡 Lina: In general, such terms could be considered. But Condition 2 will eliminate them.
Condition 2: The form must be unchanged under spatial rotations¶
🟡 Lina: Physical laws are the same in every spatial direction—this is called isotropy. So the invariant must keep the same form no matter how we rotate the spatial coordinate axes.
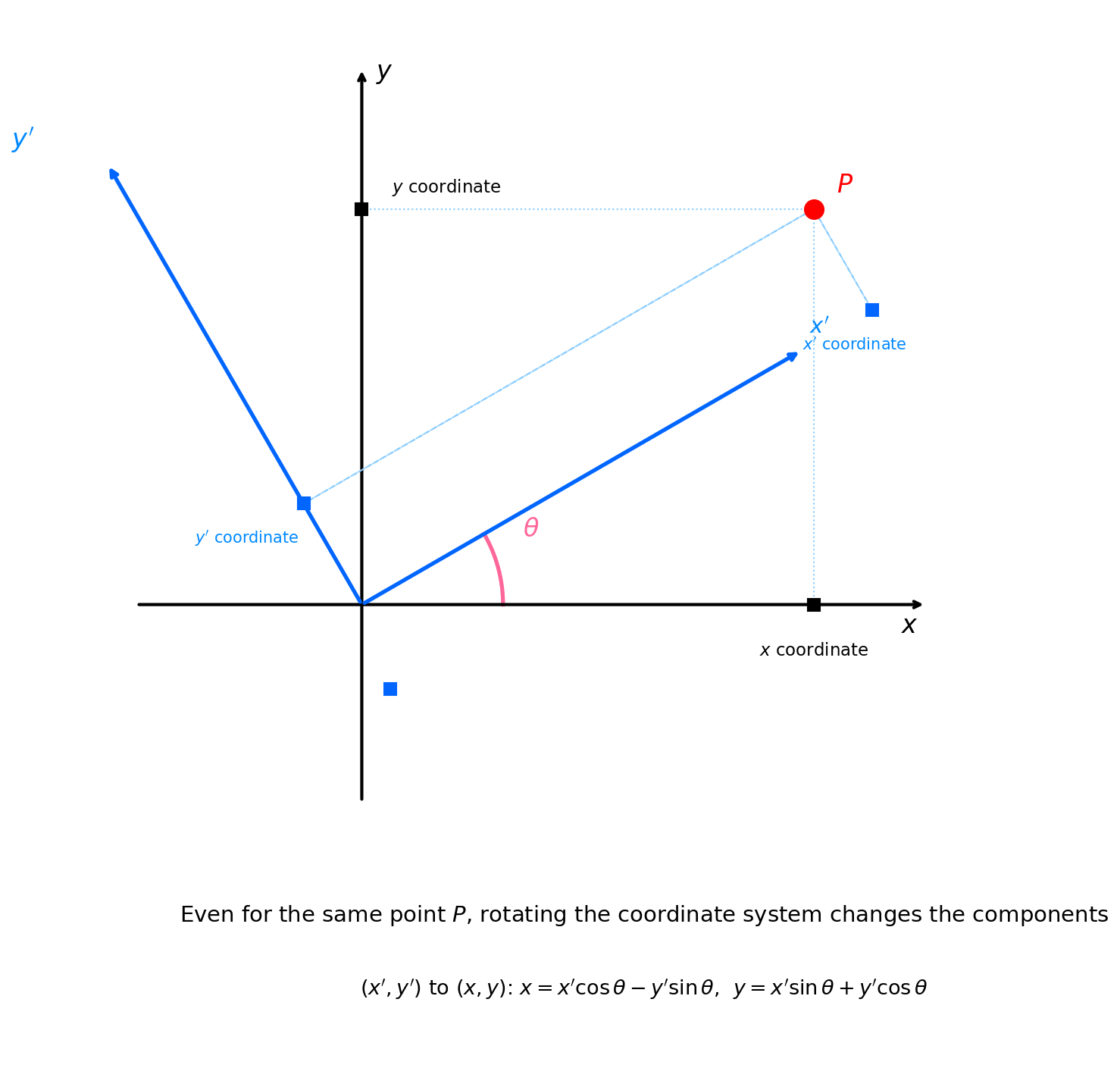
Fig. 3.3: Coordinate rotation in the xy-plane and component transformation. The same point \(P\) has different components when the coordinate system is rotated by angle \(\theta\). The original coordinates \((x, y)\) (black) and the rotated coordinates \((x', y')\) (blue) are related by \(x = x'\cos\theta - y'\sin\theta\), \(y = x'\sin\theta + y'\cos\theta\) (written in inverse transformation form).
Let's look at this concretely. Consider new coordinates \((x', y')\) obtained by rotating the coordinate axes counterclockwise by angle \(\theta\) in the \(xy\) plane. If the coordinates of a point \(P\) in the new axes are \((x', y')\), then the coordinates \((x, y)\) in the original axes are related by
This is written in the inverse transformation form—"given the new coordinates \((x', y')\), find the original coordinates \((x, y)\)." The reason we use the inverse transformation is that we want to rewrite \(dx\,dy\) in terms of the new coordinates \((dx', dy')\)—the form \(dx = (\cdots)dx' + (\cdots)dy'\) is directly usable. This formula is just the rotation matrix from high school math, where \(\cos\theta\) and \(\sin\theta\) appear because projection onto rotated axes is expressed by trigonometric functions (see Fig. 3.3 "Coordinate rotation in the xy-plane and component transformation"). The same form holds for infinitesimal quantities \(dx, dy\). Suppose a cross term \(dx\,dy\) were included in the invariant. Expressing it in the rotated coordinates:
Expanding this gives terms like \((\cos^2\theta - \sin^2\theta)\,dx'\,dy'\) and others—a different form from the original \(dx\,dy\).
⚪ Mei: It violates the condition "the form stays the same under rotation." So cross terms like \(dx\,dy\) are not allowed.
🟡 Lina: For the same reason, cross terms like \((cdt)(dx)\) between time and space also fail, because rotating space mixes \(dx\) into \(dx'\) and \(dy'\), changing the form. So those are also not allowed.
On the other hand, \(dx^2 + dy^2 + dz^2\) (sum of squares of spatial coordinates) always returns to \(dx'^2 + dy'^2 + dz'^2\) under rotation—this is precisely the invariance of 3-dimensional distance, a restatement of the Pythagorean theorem. \((cdt)^2\) contains no spatial components, so spatial rotations leave it unchanged.
In the end, the only quadratic combinations invariant under spatial rotations are \(dx^2 + dy^2 + dz^2\) and \((cdt)^2\). So the invariant is restricted to the form
All the cross terms vanish, and we're left with just the coefficients \(A\) and \(B\)—a clean form, right?
⚪ Mei: Now we just need to determine \(A\) and \(B\).
🟡 Lina: Exactly.
✅ Comprehension Check: Why doesn't the spacetime invariant \(ds^2\) contain cross terms like \(dx\,dy\) or \((cdt)(dx)\)?
Answer
From spatial isotropy (physical laws are the same in every direction), the invariant must keep the same form under any rotation of the spatial coordinate axes. Cross terms like \(dx\,dy\) change their form under coordinate rotation, violating the isotropy condition. Similarly, \((cdt)(dx)\) is not allowed because \(dx\) mixes under spatial rotation.
The Constancy of the Speed of Light Determines the Minus Sign¶
🔵 Kai: How do we determine \(A\) and \(B\)?
🟡 Lina: This is where we use the principle of the constancy of the speed of light. First, consider the infinitesimal displacement of light in an inertial frame \(S\). Light travels at speed \(c\). The distance light travels in 3-dimensional space during an infinitesimal time \(dt\) is \(\sqrt{dx^2 + dy^2 + dz^2}\). On the other hand, the distance traveled at speed \(c\) for time \(dt\) is \(c\,dt\). Since these are equal:
Squaring both sides, the infinitesimal displacement along any light ray satisfies
Substituting this into \(ds^2 = A\,(cdt)^2 + B\,(dx^2 + dy^2 + dz^2)\) obtained in "Narrowing Down the Form of the Spacetime Invariant":
⚪ Mei: So in the \(S\) frame, for light we get \(ds^2 = (A+B)\,c^2\,dt^2\).
🟡 Lina: Next, by the principle of the constancy of the speed of light, light also travels at the same speed \(c\) in another inertial frame \(S'\), so in the \(S'\) frame:
And by the principle of relativity, the form of the definition of the invariant is the same in all inertial frames—meaning in the \(S'\) frame we also use the same coefficients \(A, B\) to write \(ds'^2 = A\,(cdt')^2 + B\,(dx'^2 + dy'^2 + dz'^2)\) (if the coefficients were \(A, B\) in the \(S\) frame but different in the \(S'\) frame, it would violate "the same physical laws in every inertial frame"). Substituting:
The same form as in the \(S\) frame, just with \(dt\) replaced by \(dt'\).
🔵 Kai: So far the same form appears in both frames. But can we call this an invariant? If \(dt \neq dt'\), wouldn't the values be different?
🟡 Lina: That's precisely the next point. Our goal is to define \(ds^2\) as an invariant that takes the same value in all inertial frames. For this, if \(ds^2 = 0\) for light in the \(S\) frame, then \(ds'^2 = 0\) must also hold in the \(S'\) frame. But looking at our calculation results, \(ds^2 = (A+B)\,c^2\,dt^2\) and \(ds'^2 = (A+B)\,c^2\,dt'^2\). If \(A + B \neq 0\), then for \(ds^2 = ds'^2\) to hold, we'd need \((A+B)\,c^2\,dt^2 = (A+B)\,c^2\,dt'^2\), i.e., \(dt = dt'\).
🔵 Kai: Wait, \(dt = dt'\) means a Galilean transformation—absolute time, right?
🟡 Lina: Exactly. Let me organize the logical flow here. What we want to show is that "\(A + B \neq 0\) leads to a contradiction." If \(A + B \neq 0\), then \(ds^2 = ds'^2\) requires \(dt = dt'\)—but \(dt = dt'\) (absolute time) contradicts the constancy of the speed of light. So \(A + B \neq 0\) is impossible, and \(A + B = 0\) is the only option. Let's see concretely how "\(dt = dt'\) contradicts the constancy of the speed of light." Suppose \(dt = dt'\) (absolute time) holds. When light is emitted at the moment \(t = t' = 0\) when the origins of both frames coincide, in the \(S\) frame at time \(t\) the wavefront is a sphere of radius \(ct\) centered on the origin of \(S\)—a collection of points equidistant \(ct\) in all directions from the origin of \(S\). Meanwhile, for the observer in the \(S'\) frame, the light also departed from their origin (since they were at the origin at \(t' = 0\)). By the constancy of the speed of light, in the \(S'\) frame light also travels at speed \(c\) in all directions, so in the \(S'\) frame the wavefront should be a sphere of radius \(ct' = ct\) centered on the origin of \(S'\)—a collection of points equidistant \(ct\) in all directions from the origin of \(S'\).
🔵 Kai: But the origin of \(S'\) is displaced by \(vt\) from the origin of \(S\), right? Having the same sphere with two centers seems impossible...
🟡 Lina: Exactly. Since we're assuming \(dt = dt'\), the \(S\) and \(S'\) frames share the same space at the same time \(t\). The origin of \(S'\) is displaced by \(vt\) from the origin of \(S\) (if \(v \neq 0\) then \(vt \neq 0\)). Here the contradiction arises: one and the same wavefront (the same set of points) is said to be equidistant \(ct\) in all directions from both the origin of \(S\) and the origin of \(S'\). Think about it concretely—if the wavefront is a sphere centered on the origin of \(S\), then the distances from the origin of \(S'\) (displaced by \(vt\) from the origin of \(S\)) to various points on the wavefront should differ by direction (the near side is \(ct - vt\), the far side is \(ct + vt\)). So it cannot be "equidistant \(ct\) in all directions" from the origin of \(S'\). But the center of a sphere is "the unique point equidistant from all points on the sphere" (a sphere with two centers doesn't exist), so having the center be two points separated by \(vt\) is impossible. Therefore \(A + B \neq 0\) (which demands \(dt = dt'\)) is incompatible with the constancy of the speed of light.
⚪ Mei: On the other hand, if \(A + B = 0\), then \(ds^2 = 0\) and \(ds'^2 = 0\). Both are zero, so invariance is guaranteed regardless of the relationship between \(dt\) and \(dt'\).
🟡 Lina: Right. Under the constancy of the speed of light, the only choice compatible with any \(dt\)-\(dt'\) relationship is \(A + B = 0\)—this is the essential role that the constancy of the speed of light plays in determining the form of \(ds^2\). In a situation where absolute time doesn't hold, the only way to create an invariant is to choose \(ds^2 = 0\) for light.
🔵 Kai: Conversely, what if the speed of light weren't constant and the Galilean transformation held (\(dt = dt'\))?
🟡 Lina: In that case, \(ds^2 = (A+B)\,c^2\,dt^2\) would be frame-independent even with \(A + B \neq 0\)—the signs of \(A\) and \(B\) would be independent, and the constraint \(A + B = 0\) wouldn't arise. The minus sign wouldn't be needed. The constancy of the speed of light is what forces the minus sign on \(ds^2\).
Key logical point: Let me summarize the argument so far: 1. Light travels at the same speed \(c\) in both the \(S\) and \(S'\) frames (constancy of the speed of light) 2. For light, \(ds^2 = (A+B)\,c^2\,dt^2\) and \(ds'^2 = (A+B)\,c^2\,dt'^2\) 3. The relationship between \(dt\) in the \(S\) frame and \(dt'\) in the \(S'\) frame is not yet determined (\(dt = dt'\) is not guaranteed) 4. For invariance (\(ds^2 = ds'^2\)) to hold independent of this undetermined relationship, both sides must be zero → \(A + B = 0\)
⚪ Mei: So choosing \(A + B = 0\) means \(ds^2 = 0\) holds for light in every inertial frame—it becomes an invariant. Therefore \(A + B = 0\), i.e., \(A = -B\).
🔵 Kai: So making \(ds^2 = 0\) for light was the only option. Invariance is guaranteed regardless of the relationship between \(dt\) and \(dt'\)—because zero is zero. ...But conversely, for things that aren't light, \(ds^2 \neq 0\), right? Can we still call it invariant in that case?
🟡 Lina: Good question. I'll prove that at the end of this section. Let's first determine the sign and magnitude of \(B\). Since \(A = -B\), once we determine \(B\), \(A\) is automatically fixed. Both \(B > 0\) and \(B < 0\) are mathematically permitted, but choosing \(B > 0\) makes the spatial part \(B(dx^2 + dy^2 + dz^2)\) positive—spatial distances are positive quantities—and the time term becomes \(A = -B < 0\), giving the minus. Choosing \(B < 0\) just changes the sign convention to \((+,-,-,-)\), with the same physical conclusions. As for the magnitude, even if \(B \neq 1\), we can rescale coordinates to bring it back to the form \(B = 1\)—the value of \(B\) is absorbed into the choice of coordinate units. For example, when \(B = 4\), rescaling the spatial coordinates from "1 meter" to "0.5 meters" (\(dx \to 2\,dx\)) gives \(B\,dx^2 = 4 \cdot dx^2 = (2dx)^2\), so the coefficient becomes 1 in the new units. Therefore only the sign is physically meaningful, and choosing \(B = 1\) (thus \(A = -1\)):
⚪ Mei: The minus sign necessarily emerges from the condition that "the speed of light is finite and constant." Summarizing the earlier explanation—in Newtonian mechanics, since \(dt = dt'\), the constraint \(A + B = 0\) is unnecessary and one can construct invariants from space alone. Once you accept the constancy of the speed of light, absolute time breaks down, and you need an invariant that treats time and space together, which is where the sign difference appears.
🟡 Lina: Exactly. This is why spacetime geometry is fundamentally different from Euclidean geometry.
✅ Comprehension Check: Why does the time term in the spacetime interval \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\) carry a minus sign?
Answer
From the principle of the constancy of the speed of light, \(ds^2 = 0\) must hold for light in all inertial frames. For this condition to be satisfied, \(A + B = 0\) (i.e., the time and space coefficients must have opposite signs) is required.
🔍 Dive Deep: What if the speed of light were different in each inertial frame?
You might think "Couldn't \(A + B = 0\) be derived even without a constant speed of light?" Indeed, even if the speed of light were \(c'\) in the \(S'\) frame, defining the invariant as \(ds'^2 = A\,(c'dt')^2 + B\,(dx'^2+dy'^2+dz'^2)\) gives \(ds'^2 = (A+B)\,c'^2\,dt'^2 = 0\) for light, and \(A + B = 0\) follows.
The problem lies beyond that. Substituting \(A + B = 0\) and \(B = 1\), in the \(S\) frame \(ds^2 = -(cdt)^2 + dx^2+dy^2+dz^2\). By the principle of relativity, the same form should hold in the \(S'\) frame, but if the speed of light is \(c'\), then \(ds'^2 = -(c'dt')^2 + dx'^2+dy'^2+dz'^2\). If \(c \neq c'\), the constant appearing in the definition of the invariant takes different values in different inertial frames. This means no "invariant with the same form in all inertial frames" exists—it violates the principle of relativity.
Only when the speed of light is constant (\(c = c'\)) does \(ds^2 = -c^2\,dt^2 + dx^2+dy^2+dz^2\) serve as a single expression valid in all inertial frames. The constancy of the speed of light is needed not so much "to derive \(A + B = 0\)" but rather "to define a universal spacetime interval."
🟡 Lina: This \(ds^2\) is called the spacetime interval.
🔵 Kai: But we derived this from the case of light. Can it be used for ordinary objects that aren't light?
🟡 Lina: Good question. In fact, it can be proven separately that \(ds^2\) is a frame-independent invariant even for cases other than light. I'll prove it at the end of this section.
⚪ Mei: For light, \(ds^2 = 0\). And changing inertial frames still gives \(ds'^2 = 0\). So \(ds^2\) is, at least for light, a quantity independent of the inertial frame—an invariant.
🟡 Lina: Exactly. I mentioned that \(ds^2\) is the quantity corresponding to "the distance between two points in spacetime." Let me give a proper name to these "points in spacetime"—they're called events. Let's use the spacetime diagram introduced in Section 3 of Ch. 2 again—the 3-dimensional diagram \((ct, x, y)\) with the time axis \(ct\) added to spatial coordinates \((x, y, z)\) (Fig. 3.4 "Events and light cone in a spacetime diagram").
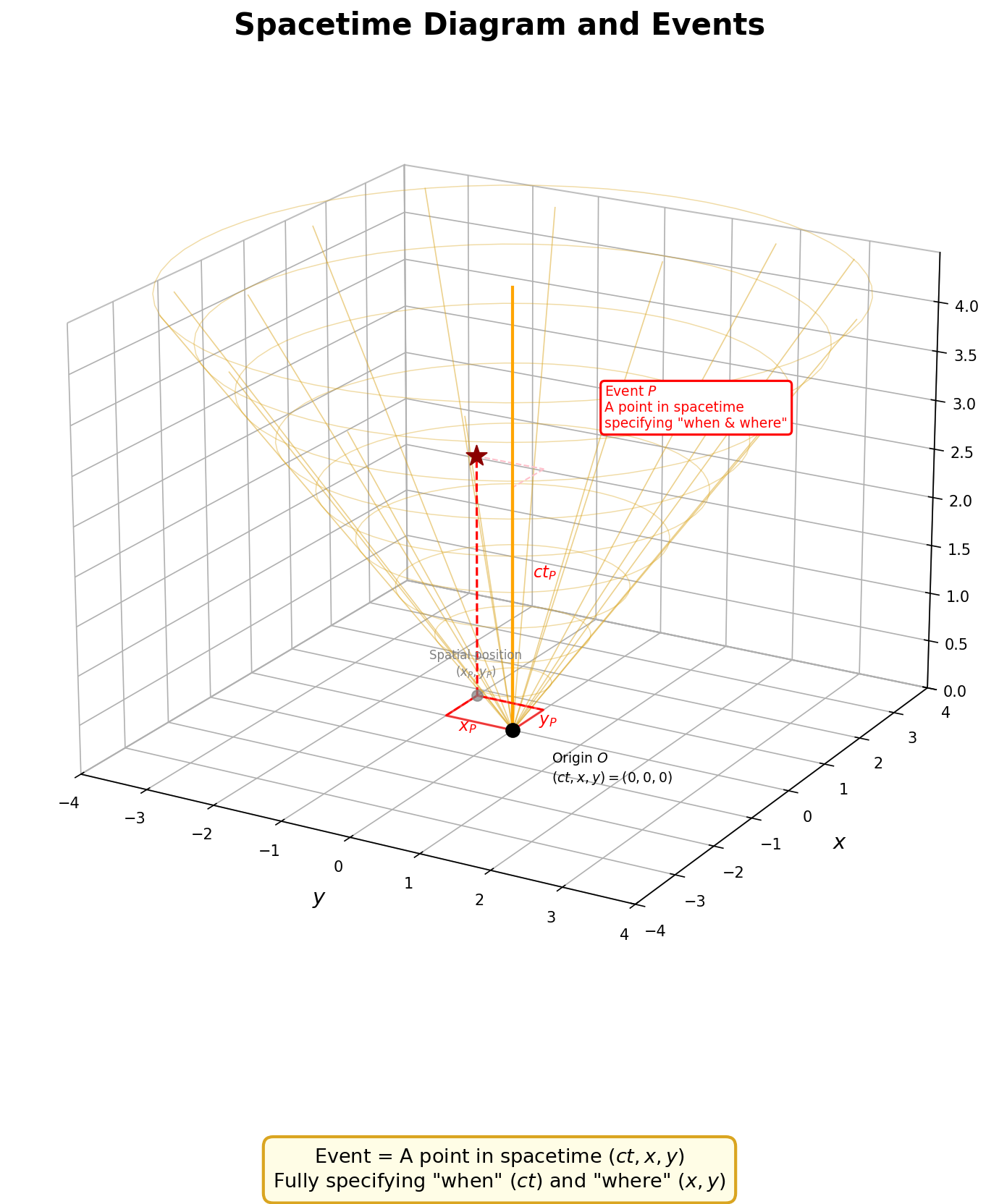
Fig. 3.4: Events and light cone in a spacetime diagram. A 3-dimensional spacetime diagram in \((ct, x, y)\). The two horizontal axes \((x, y)\) represent space, and the vertical axis \(ct\) represents time. Event \(P\) is a single point in spacetime that completely specifies "when" (\(ct_P\)) and "where" (\(x_P, y_P\)). The yellow lines are the light cone emanating from the origin.
🔵 Kai: Is an "event" different from the everyday word "happening"?
🟡 Lina: In physics, an event is a single point in spacetime—a specified combination \((t, x, y, z)\) of "when and where." Something like "April 30, 2026, at 12:00 PM, in front of the ticket gate at Tokyo Station" with time and place completely specified is one event. It has no size and no duration—a mathematical point.
⚪ Mei: The values of \((t, x, y, z)\) change with the coordinate system, but the event itself—which point in spacetime it is—doesn't depend on the coordinate system.
🟡 Lina: Exactly. The \(ds^2\) we just defined is the quantity corresponding to the "spacetime distance" between two infinitesimally separated events. Place event A at the origin and emit light from there. Since light propagates satisfying \(ds^2 = 0\), on a spacetime diagram the trajectory of light traces out a cone surface spreading at 45° from the origin—this is called the light cone. The light cone divides spacetime into 3 regions (Fig. 3.5 "Three-fold classification of spacetime intervals"). Whether event B is inside or outside the light cone determines its relationship to A.
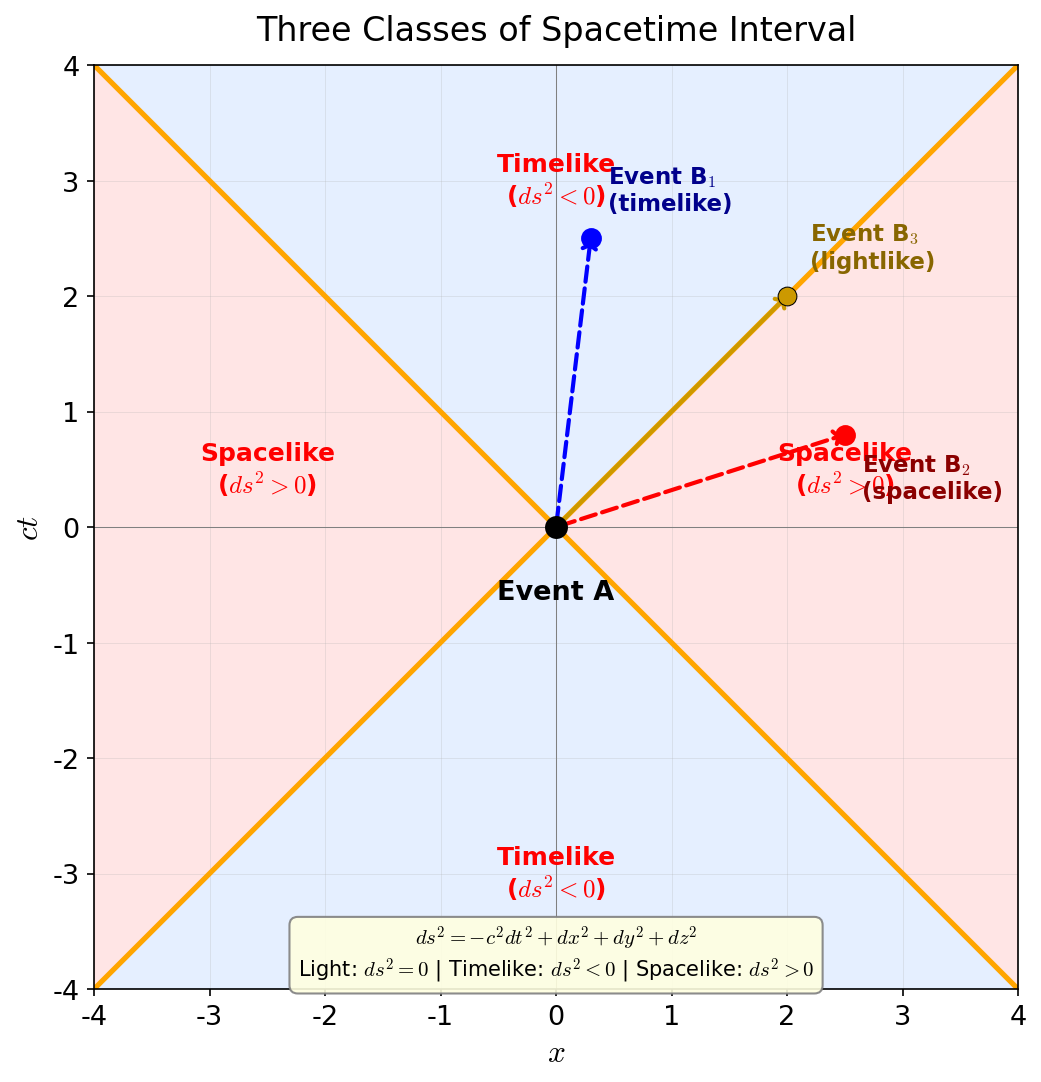
Fig. 3.5: Three-fold classification of spacetime intervals. A spacetime diagram with event A at the origin. The light cone (yellow lines, \(ds^2 = 0\)) divides spacetime into 3 regions. Event B₁ is timelike (\(ds^2 < 0\)), B₂ is spacelike (\(ds^2 > 0\)), B₃ is lightlike (\(ds^2 = 0\)).
🟡 Lina: This three-fold classification has deep physical meaning. The term "causal relationship" will come up—this means "whether one event can be the cause of the other"—that is, whether a signal or object can travel from one to the other.
Table 3.2: Three-fold classification of spacetime intervals and their physical meaning
| Classification | Condition | Physical meaning |
|---|---|---|
| Timelike | \(ds^2 < 0\) | One can travel between A and B at less than the speed of light. Causal connection is possible |
| Lightlike (null) | \(ds^2 = 0\) | A and B can be connected by a light signal. On the light cone |
| Spacelike | \(ds^2 > 0\) | One cannot travel between A and B at or below the speed of light. No causal connection |
🔵 Kai: What does "no causal connection" mean?
🟡 Lina: Two events that are spacelike separated cannot be reached from one to the other by any signal. Therefore, it's impossible for one to be the cause of the other—that's what "no causal connection" means. The light cone is "the boundary of the region that can be causally influenced."
🔵 Kai: But what about non-light cases? Can we say \(ds^2 = ds'^2\) when \(ds^2 \neq 0\)?
Proof that \(ds^2\) is Invariant in All Cases¶
Reading hint: This section is somewhat mathematical and difficult. If you can grasp the outline of the proof, that's sufficient to proceed. The conclusion is "\(ds^2\) is a frame-independent invariant for all cases (including objects other than light)"—keep this in mind and you can read the following sections.
🟡 Lina: Let me prove it. The approach has three steps.
Proof outline: 1. \(ds^2\) and \(ds'^2\) are related by a "sum of squares" form (quadratic combination) of coordinates 2. From the constancy of the speed of light, when \(ds^2 = 0\) then necessarily \(ds'^2 = 0\). This yields a proportionality relationship \(ds'^2 = a(v)\,ds^2\) 3. Connecting three inertial frames shows that the proportionality constant \(a(v)\) must actually be 1
Step 1: \(ds'^2\) has the same "quadratic combination" form as \(ds^2\)¶
🟡 Lina: First, consider the relationship between coordinates \((t, x, y, z)\) in the \(S\) frame and coordinates \((t', x', y', z')\) in the \(S'\) frame. Transformations between inertial frames are linear in coordinates—that is, of the form \(t' = (\text{number})\cdot t + (\text{number})\cdot x + \ldots\).
🔵 Kai: Why linear?
🟡 Lina: The homogeneity of spacetime—physical laws are the same at every place and time—requires it. Intuitively, if the transformation were quadratic—say \(x' = ax^2 + bt\)—then shifting the origin by \(x_0\) gives \(x' = a(x+x_0)^2 + bt\), producing an extra linear term \(2ax_0 x\), making the transformation form depend on the choice of origin. Linear equations don't have this problem—I'll confirm this more carefully in "Two Assumptions". For now, let's use this conclusion and move forward. Since multiplying linear expressions produces quadratic ones, rewriting \(ds'^2 = -c^2 dt'^2 + dx'^2 + dy'^2 + dz'^2\) in terms of the original coordinates \((dt, dx, dy, dz)\) also gives a quadratic combination of coordinates—\(dt^2, dx^2, dt\,dx, \ldots\) and so on.
⚪ Mei: So \(ds'^2\) is the same type of mathematical object as \(ds^2\)—a quadratic combination of coordinates—which means we can directly compare the two.
🟡 Lina: Exactly. In other words, the spacetime interval in the \(S'\) frame, written in \(S\) frame coordinates, becomes
a quadratic combination of \(S\) frame coordinates (the coefficients \(A', B', \ldots\) may differ from \(A, B, \ldots\) in the \(S\) frame).
Step 2: The constancy of the speed of light yields a proportionality relationship¶
🟡 Lina: Both \(ds^2\) and \(ds'^2\) are quadratic combinations writable in the same \(S\) frame coordinates \((dt, dx, dy, dz)\). Now we use the principle of the constancy of the speed of light.
When light propagates, \(ds^2 = 0\) in the \(S\) frame. By the constancy of the speed of light, the speed of light is also \(c\) in the \(S'\) frame, so \(ds'^2 = 0\) also holds for the same light propagation. That is, for any coordinate displacement \((dt, dx, dy, dz)\) that makes \(ds^2\) zero, \(ds'^2\) is also necessarily zero—the "set of points where they vanish (zero set)" of the two expressions coincides.
🔵 Kai: Does the zero sets coinciding alone give us the proportionality \(ds'^2 = a(v)\,ds^2\)?
🟡 Lina: Consider the 1-variable case. \(f(x) = x^2 - 1\) and \(g(x) = 3x^2 - 3\) both vanish at \(x = \pm 1\). Indeed, \(g(x) = 3 f(x)\)—a constant multiple. In general, two quadratic expressions with all roots in common differ only by a constant multiple. The reason is that a quadratic can be factored as \(a(x - r_1)(x - r_2)\) (where \(r_1, r_2\) are the roots). If the roots \(r_1, r_2\) are the same, the only freedom is the leading coefficient \(a\)—just a constant multiple.
🔵 Kai: I get it for one variable, but does the same hold for multiple variables? With more variables there are more coefficient degrees of freedom, so there might be more possibilities...
🟡 Lina: Intuitively, think of it this way. Let's look concretely at 2 variables. The zero set of \(f = x^2 - y^2\)—the collection of points \((x, y)\) satisfying \(f = 0\)—is \(x = \pm y\), two lines that spread out as a surface, not just the origin. If another quadratic \(g = ax^2 + bxy + cy^2\) has the same zero set (vanishes at \(x = \pm y\)), then substituting \(x = y\) gives \(a + b + c = 0\), and substituting \(x = -y\) gives \(a - b + c = 0\). From these two equations, \(b = 0\) and \(c = -a\), so \(g = a(x^2 - y^2) = a \cdot f\). When the zero set spreads across a surface, you can use information from all directions, and \(g\) is restricted to be a constant multiple of \(f\).
Conversely, if \(f = x^2 + y^2\) where everything is positive, the only point satisfying \(f = 0\) is the origin \((0, 0)\). With information from only one point, "g also vanishes at the origin" is all you can say, and \(g = 2x^2 + 3y^2\) with any ratio of coefficients still satisfies the condition.
⚪ Mei: Ah, so the minus sign in \(ds^2\) is what matters here. Because it's indefinite in sign, the zero set spreads out, and the proportionality relationship is enforced.
🟡 Lina: Right. A squared expression like this—where positive and negative terms coexist, like \(x^2 - y^2\), neither all positive nor all negative—is called an indefinite quadratic form. Here "quadratic form" means an expression consisting only of squares of variables and products of variables (\(ax^2 + bxy + cy^2\) and similar). "Indefinite" means that depending on the values of the variables, it can be positive, negative, or zero. For indefinite quadratic forms, the zero set is not just the origin but spreads out—for \(x^2 - y^2 = 0\), the entire pair of lines \(x = \pm y\) is the zero set. This "spread" provides abundant points for substitution, and any other quadratic form with the same zero set is restricted to a constant multiple. \(ds^2 = -(ct)^2 + x^2 + y^2 + z^2\) is precisely this form—the time term is negative and the space terms are positive, making it an indefinite quadratic form.
The extension to 4 variables uses the same principle. In 2 variables, the zero set was 2 lines, and substituting there determined all coefficients. In 4 variables, the zero set is the light cone—a 3-dimensional "surface"—so there are even more points available for substitution, and the coefficients are even more strongly constrained. Specifically, the same technique used in 2 variables—substituting pairs with only sign differences to eliminate cross terms—works in 4 variables too. On the light cone there are infinitely many pairs like \((1, 1, 0, 0)\) and \((1, -1, 0, 0)\) differing only in sign; substituting these and taking differences shows the cross-term coefficients are zero. The fold-out below confirms this concretely, but the procedure is the same as in 2 variables—"substitute points on the zero set and solve the system of equations for the coefficients."
Concrete verification in 4 variables (can be skipped):
The zero set of \(f = -t^2 + x^2 + y^2 + z^2\) is \(t^2 = x^2 + y^2 + z^2\) (the light cone). Fixing \(t = 1\), points on the zero set satisfy \(x^2 + y^2 + z^2 = 1\)—that is, all points on the 3-dimensional unit sphere are included in the zero set. For example, \((1, 1, 0, 0)\), \((1, -1, 0, 0)\), \((1, 0, 1, 0)\), \((1, 0, -1, 0)\), \((1, 0, 0, 1)\), \((1, 1/\sqrt{2}, 1/\sqrt{2}, 0)\), etc.—infinitely many points are available.
If another quadratic \(g = At^2 + Bx^2 + Cy^2 + Dz^2 + Etx + Fty + \ldots\) (including cross terms) vanishes at all these points, we can determine the cross-term coefficients. The method is to "substitute pairs differing only in sign and take the difference." Why does taking the difference eliminate cross terms? Because a cross term \(Etx\) is the product of \(t\) and \(x\), so flipping the sign of \(x\) only changes the sign of \(Etx\), while \(t^2\) and \(x^2\) terms remain unchanged. Let's see concretely. Substituting \((1,1,0,0)\) gives \(A \cdot 1 + B \cdot 1 + E \cdot 1 \cdot 1 = A + B + E = 0\). Next, substituting \((1,-1,0,0)\) with only the sign of \(x\) flipped gives \(A \cdot 1 + B \cdot 1 + E \cdot 1 \cdot (-1) = A + B - E = 0\). Taking the difference: \((A+B+E) - (A+B-E) = 2E = 0\), so \(E = 0\) (the coefficient of the \(tx\) cross term is zero). The \(A + B\) parts are the same in both equations and cancel in the subtraction, leaving only \(E\)—this is the mechanism of "using pairs to isolate cross terms." The same technique with \((1,0,1,0)\) and \((1,0,-1,0)\) gives \(F = 0\) (the \(ty\) cross term). The \(xy\) cross term can also be eliminated the same way. If \(g\) has a \(xy\) cross term \(Gxy\), substituting \((1, 1/\sqrt{2}, 1/\sqrt{2}, 0)\) contributes \(G \cdot (1/\sqrt{2})(1/\sqrt{2}) = G/2\), and substituting \((1, 1/\sqrt{2}, -1/\sqrt{2}, 0)\) contributes \(G \cdot (1/\sqrt{2})(-1/\sqrt{2}) = -G/2\). Taking the difference gives \(G = 0\)—thus all cross terms vanish.
For the diagonal components, from both \((1,1,0,0)\) and \((1,0,1,0)\) being on the zero set, we get \(A + B = 0\) and \(A + C = 0\), hence \(B = C\). Similarly \(C = D\) can be shown, so \(B = C = D\). In the end, \(g = A(-t^2 + x^2 + y^2 + z^2) = (-A) \cdot f\)—restricted to a constant multiple of \(f\).
Conclusion so far: For indefinite quadratic forms whose zero sets spread across a surface, any other quadratic form with the same zero set differs only by a constant multiple. In 4 variables too, "pair substitution → subtraction" determines all coefficients.
By repeating substitutions as in the 2-variable case, all coefficients of \(g\) can be shown to be restricted to a constant multiple of \(f\). The rigorous proof is deferred to linear algebra textbooks, but in conclusion:
This proportionality relationship holds, where \(v\) is the magnitude of the relative velocity between the two inertial frames, and \(a(v)\) is the proportionality constant.
🔵 Kai: Does the coefficient \(a\) depend on the direction of the velocity too?
🟡 Lina: Good question. Recall spatial isotropy—physical laws are the same in every direction. If \(a\) depended on the direction of the velocity vector \(\vec{v}\), then \(ds'^2\) would take different values when moving in one direction versus another. That violates isotropy. So \(a\) is a function only of the magnitude \(v = |\vec{v}|\).
⚪ Mei: I see, \(a = a(v)\).
🟡 Lina: This completes Step 2. What remains is Step 3—showing that \(a(v) = 1\).
Step 3: Connecting three inertial frames gives \(a(v) = 1\)¶
🟡 Lina: Consider three inertial frames \(S_1\), \(S_2\), \(S_3\). \(S_2\) moves at velocity \(\vec{v}_1\) (speed \(v_1\)) as seen from \(S_1\), and \(S_3\) moves at velocity \(\vec{v}_2\) (speed \(v_2\)) as seen from \(S_2\).
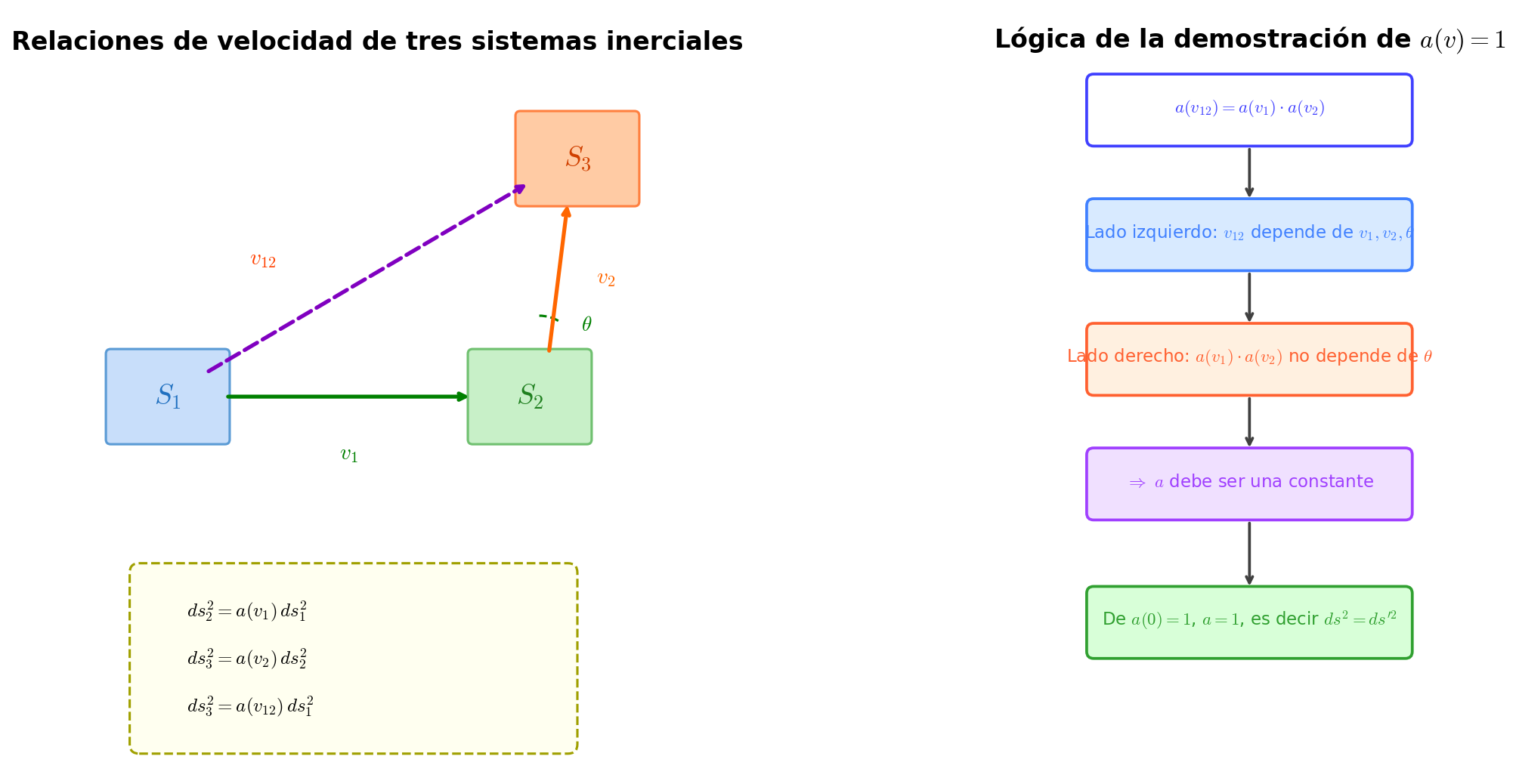
Fig. 3.6: Velocity composition of inertial frames and proof of invariance. Left — velocity relationships among the 3 inertial frames \(S_1, S_2, S_3\). The angle \(\theta\) between velocity \(\vec{v}_1\) from \(S_1\) to \(S_2\) and velocity \(\vec{v}_2\) from \(S_2\) to \(S_3\) affects the composed speed \(v_{12}\). Right — the left side of \(a(v_{12}) = a(v_1) \cdot a(v_2)\) depends on \(\theta\) while the right side does not, so \(a\) must be constant, and from \(a(0) = 1\) it follows that \(a = 1\).
🟡 Lina: Applying the proportionality relationship from Step 2 between each pair of frames:
- \(S_1 \to S_2\): \(ds_2^2 = a(v_1)\,ds_1^2\)
- \(S_2 \to S_3\): \(ds_3^2 = a(v_2)\,ds_2^2\)
Combining these:
On the other hand, transforming directly from \(S_1\) to \(S_3\), with \(v_{12}\) being the speed of \(S_3\) as seen from \(S_1\):
Since both expressions represent the same \(ds_3^2\):
🔵 Kai: \(v_{12}\) is the speed of \(S_3\) as seen from \(S_1\), right? But that depends not only on the magnitudes of \(v_1\) and \(v_2\), but also on the angular relationship between \(\vec{v}_1\) and \(\vec{v}_2\)—the angle \(\theta\).
🟡 Lina: Exactly. For example, when \(v_1 = v_2 = 0.5c\): if \(\vec{v}_1\) and \(\vec{v}_2\) point in the same direction (\(\theta = 0\)), \(v_{12}\) is large; if they're perpendicular (\(\theta = \pi/2\)), it's about \(\sqrt{v_1^2 + v_2^2}\); if they're opposite (\(\theta = \pi\)), it approaches 0. \(v_{12}\) depends on \(v_1, v_2, \theta\)—all three.
Now look at the equation \(a(v_{12}) = a(v_1)\cdot a(v_2)\) again.
⚪ Mei: The left side depends on \(\theta\) (because \(v_{12}\) depends on \(\theta\)), but the right side contains no \(\theta\) at all (it's determined by \(v_1\) and \(v_2\) alone).
🟡 Lina: That's the decisive point. The right side \(a(v_1) \cdot a(v_2)\) doesn't contain \(\theta\)—it's a constant determined by \(v_1\) and \(v_2\) alone. Meanwhile, the left side \(a(v_{12})\) can vary through \(\theta\). But if left = right holds for any \(\theta\), then the left side must also be a constant independent of \(\theta\).
🔵 Kai: So \(a(v_{12})\) returns the same value regardless of what value \(v_{12}\) takes... does that mean \(a\) is a constant function?
🟡 Lina: Good question. More precisely, fixing \(v_1\) and \(v_2\) and continuously varying \(\theta\) (the angle between \(\vec{v}_1\) and \(\vec{v}_2\)) from \(0\) to \(\pi\), \(v_{12}\) also varies continuously from some minimum to some maximum. For example, when \(\vec{v}_1\) and \(\vec{v}_2\) point in the same direction (\(\theta = 0\)), the composed speed is maximum, and when they're opposite (\(\theta = \pi\)), it's minimum—if both \(v_1\) and \(v_2\) are nonzero, the maximum and minimum differ.
🔵 Kai: So varying \(\theta\) makes \(v_{12}\) change continuously... but why can we say "continuously"?
🟡 Lina: Because the transformation between inertial frames is linear in coordinates (the linearity confirmed in Step 1), the composition of two linear transformations is also linear, and its coefficients are polynomials of the original transformation coefficients—hence continuous functions. This guarantees that changing \(\theta\) slightly changes $v_{12} $ only slightly (the concrete velocity addition formula and its \(\theta\) dependence can be verified in the exercise → Problem M-5. Derivation of the Velocity Addition Formula).
The key point is that varying \(\theta\) makes \(v_{12}\) take not just one value, but a range of values. If \(a\) were not constant, then as \(v_{12}\) changes, \(a(v_{12})\) should also change—but the right side is a constant independent of \(\theta\), so that's impossible.
⚪ Mei: So \(a\) is constant over that range.
🟡 Lina: Right. Specifically, fixing \(v_1\) and \(v_2\) and varying \(\theta\) from \(0\) to \(\pi\), \(v_{12}\) varies continuously from some minimum to some maximum (in Galilean mechanics, when \(\vec{v}_1\) and \(\vec{v}_2\) are opposite (\(\theta = \pi\)), \(v_{12} = |v_1 - v_2|\) (minimum); when they're in the same direction (\(\theta = 0\)), \(v_{12} = v_1 + v_2\) (maximum)—in relativity it's slightly modified, but in any case if \(v_1, v_2 > 0\) the minimum and maximum differ). Within this range, \(a\) is constant—it takes only one value.
Next, repeating the same argument with different values of \(v_1\) or \(v_2\), the range swept by \(v_{12}\) changes. For example, fixing \(v_2 = 0.3c\) and varying \(v_1\) through \(0.1c, 0.5c, 0.9c, \ldots\), the range of \(v_{12}\) as \(\theta\) varies is different for each \(v_1\).
🔵 Kai: So by trying various values of \(v_1\), you can keep expanding the range of achievable \(v_{12}\).
🟡 Lina: Exactly. Concretely, when \(v_1 = 0.1c\), \(v_2 = 0.3c\), varying \(\theta\) makes \(v_{12}\) range approximately from \(0.2c\) to \(0.4c\); when \(v_1 = 0.9c\), \(v_2 = 0.3c\), \(v_{12}\) ranges approximately from \(0.8c\) to \(0.95c\)—thus changing \(v_1\) shifts the range of \(v_{12}\), and the union covers nearly all of \([0, c)\). The region near \(v_{12} = 0\) can also be reached by choosing \(v_1 \approx v_2\) in opposite directions (\(\theta = \pi\)), so the lower end of \([0, c)\) is covered too. In the overlapping parts, the value of \(a\) must agree—because \(a\) is "a function that returns one value for a given speed \(v\)," it cannot return two different values for the same \(v_{12}\). If \(a\) is found to be constant on one range, and also constant on a neighboring range, and the values agree on the overlap, then combining both ranges, \(a\) is the same constant. Repeating this, \(a\) is the same constant over the entire range \([0, c)\). Furthermore, when \(v = 0\) (the same inertial frame, i.e., no transformation), \(ds'^2 = ds^2\), so \(a(0) = 1\). A constant with \(a(0) = 1\) means \(a = 1\).
🟡 Lina: Therefore,
Including cases beyond light, the spacetime interval \(ds^2\) takes the same value in all inertial frames—it is an invariant. That's what we wanted to prove.
⚪ Mei: The same structure as "distance \(dx^2 + dy^2\) is invariant under spatial rotation" exists in spacetime. Except the minus sign on the time term is the decisive difference.
🟡 Lina: Exactly. This is the geometric heart of special relativity.
✅ Comprehension Check: In the proof that \(ds^2\) is invariant even beyond the case of light, what is the key that leads to the proportionality constant \(a(v) = 1\)?
Answer
Connecting three inertial frames \(S_1, S_2, S_3\) gives \(a(v_{12}) = a(v_1) \cdot a(v_2)\). The \(v_{12}\) on the left side depends on the angle \(\theta\) between \(\vec{v}_1\) and \(\vec{v}_2\), but the right side contains no \(\theta\). For this equation to hold for any \(\theta\), \(a\) must be constant, and from \(a(0) = 1\) (no transformation in the same frame), \(a = 1\) is concluded.
✅ Comprehension Check: In the three-fold classification by the sign of the spacetime interval \(ds^2\), what is the case \(ds^2 < 0\) called, and what does it mean physically?
Answer
It is called timelike. It means that one can travel between the two events at less than the speed of light, and a causal connection is possible.
Note on sign conventions: This chapter adopts the \((-,+,+,+)\) sign convention \(ds^2 = -c^2\,dt^2 + dx^2 + dy^2 + dz^2\). Some textbooks use the opposite \((+,-,-,-)\), but the physical conclusions are the same. Make a habit of always checking which convention the literature you're reading uses.
Sign conventions in references: Among the references for this General Relativity, Tong, Schutz, and Lancaster & Blundell use the same \((-,+,+,+)\) as this General Relativity. On the other hand, Hartle, Ishii's book, and Satō's book use the opposite \((+,-,-,-)\). When consulting these textbooks, note that the signs of \(ds^2\) and \(\eta_{\mu\nu}\) are inverted.
3.3 Derivation of the Lorentz Transformation¶
🟡 Lina: In Section 2, we obtained the invariant \(ds^2\)—a rank-0 tensor—of spacetime. At the end of Ch. 2, I previewed "next comes rank-1 tensors (4-vectors)."
🔵 Kai: Yes. Is rank-1 tensors next?
🟡 Lina: Before that, there's something I'd like to do. The invariant in Newtonian mechanics—distance \(d\ell^2 = dx^2 + dy^2 + dz^2\)—was invariant under Galilean transformations (switching to an inertial frame in uniform linear motion). Then under what transformation is the invariant \(ds^2\) derived in Section 2 invariant? Let me lay out the big picture in a table.
Table 3.3: Correspondence between invariants and coordinate transformations for each mechanical framework
| Newtonian mechanics | Special relativity (this chapter) | General relativity | ||
|---|---|---|---|---|
| Coordinate transformation | Galilean transformation | Lorentz transformation ← Section 3 | General coordinate transformation | |
| Invariant | Rank-0 tensor (scalar) | Distance \(d\ell^2 = dx^2+dy^2+dz^2\) | Spacetime interval \(ds^2\) ← introduced in Section 2 | \(ds^2 = g_{\mu\nu}\,dx^\mu dx^\nu\) |
| Rank-1 tensor (vector) | Position \(\vec{r}\), velocity \(\vec{v}\), force \(\vec{F}\) | 4-velocity \(U^\mu\) ← Ch. 4 | 4-vector \(V^\mu\) | |
| Rank-2 tensor (metric) | \(\delta_{ij}\) (Euclidean metric, 1 if \(i=j\), 0 if \(i\neq j\)) | Minkowski metric \(\eta_{\mu\nu}\) ← Ch. 4 | Metric \(g_{\mu\nu}\) (dynamical field) |
⚪ Mei: The Newtonian column is familiar, so comparing with it makes visible what changes in special relativity. And the general relativity column is the ultimate goal.
🟡 Lina: So let's formulate the Lorentz transformation—the transformation that keeps the spacetime interval \(ds^2\) invariant.
✅ Comprehension Check: What is the invariant-and-coordinate-transformation pair in Newtonian mechanics? How does it change in special relativity?
Answer
In Newtonian mechanics, the invariant is spatial distance \(d\ell^2 = dx^2 + dy^2 + dz^2\), and the coordinate transformation preserving it is the Galilean transformation. In special relativity, the invariant becomes the spacetime interval \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\), and the transformation preserving it becomes the Lorentz transformation.
Problem Setup — Expressing the Switch Between Inertial Frames¶
🟡 Lina: First, let's clarify what the Lorentz transformation physically represents.
Consider two inertial frames \(S\) and \(S'\). \(S'\) moves at constant velocity \(\vec{v}\) relative to \(S\). Assume their origins coincide at \(t = t' = 0\).
Fig. 3.7: Two inertial frames and the principle of constancy of the speed of light. Inertial frames \(S\) and \(S'\). \(S'\) moves at velocity \(v\) in the \(x\) direction relative to \(S\). At \(t=t'=0\) the origins coincide, and at that moment light is emitted from the origin. The light wavefront spreads spherically as seen from either frame (principle of the constancy of the speed of light).
The same single event (spacetime point) is recorded by the \(S\) frame observer as coordinates \((t, x, y, z)\) and by the \(S'\) frame observer as coordinates \((t', x', y', z')\). Finding the relationship between these two sets of coordinates is the goal of this section. This is the Lorentz transformation.
🔵 Kai: So it's the formula for "how a moving person and a stationary person re-describe the same occurrence."
🟡 Lina: Exactly. What's physically important here is that this transformation represents "switching between inertial frames." While 3-dimensional spatial rotation was "changing the orientation of coordinate axes," this is "switching to a different observer who is moving." It has a special name: boost.
⚪ Mei: Spatial rotation and boost are both transformations that change coordinates, but their physical meanings differ.
- Spatial rotation: The same observer changes the orientation of the coordinate axes
- Boost: Switching to an observer moving at a different velocity
🟡 Lina: Right. Now let's find the concrete form of the boost.
✅ Comprehension Check: What is the physical difference between spatial rotation and a boost?
Answer
Spatial rotation is a transformation where the same observer changes the orientation of the coordinate axes. A boost is a transformation that switches to an observer moving at a different velocity (a different inertial frame). Both change coordinates, but the essential difference with a boost is that it mixes the time axis and spatial axes.
Two Assumptions¶
🟡 Lina: I'll state two assumptions for the derivation. Both are physically natural.
Assumption 1 (Linearity): The Lorentz transformation can be written as a linear function (first-degree expression) of the coordinates.
Assumption 2 (Isotropy): We can assume without loss of generality that the relative velocity \(\vec{v}\) points only in the \(x\) direction.
🔵 Kai: Why a linear function?
🟡 Lina: The homogeneity of spacetime—physical laws are the same at every place and time—requires it. We used the same principle when narrowing down the form of the invariant in 3.2 "Invariance of the Spacetime Interval". Let's look at a concrete example. Suppose the transformation were quadratic, say \(x' = ax^2 + bt\). Shifting the origin by \(x_0\), i.e., replacing \(x \to x + x_0\):
A linear term \(2ax_0\,x\) that wasn't in the original appears. This means the transformation's form depends on the choice of origin \(x_0\)—physical laws would differ depending on location.
On the other hand, for a linear expression \(x' = ax + bt\), substituting \(x \to x + x_0\) gives \(x' = a(x + x_0) + bt = ax + bt + ax_0\)—only the constant term changes. The form of the transformation (the coefficients of \(x\) and \(t\)) is independent of the origin. So in homogeneous spacetime, the transformation must be linear.
⚪ Mei: Assumption 2 follows because space is isotropic (all directions are equivalent), so we can always re-orient the \(x\)-axis along the relative velocity direction.
🟡 Lina: Exactly. This means without loss of generality, we consider only the case where the relative velocity is in the \(x\) direction from here on. By Assumption 1, the transformation can be written as:
There are 16 coefficients total. Let's narrow them down step by step.
Narrowing Down Coefficients Using Symmetry¶
🟡 Lina: First, since the \(y\)-axis and \(z\)-axis are perpendicular to the direction of relative motion (the \(x\) direction), it's natural to assume these coordinates are unchanged by the transformation.
🔵 Kai: Why?
🟡 Lina: Since relative motion is only in the \(x\) direction, the \(y\) and \(z\) directions are "directions not involved in the motion." There's no reason for lengths or times in these directions to change—this is a symmetry argument. Strictly speaking, \(y' = y\), \(z' = z\) can be derived from "\(y \to -y\) and \(z \to -z\) reflection symmetry" and "spatial isotropy." I'll defer the detailed proof to references.
Reference: Rigorous derivation of \(y' = y\), \(z' = z\)
See Landau-Lifshitz The Classical Theory of Fields §4, or Sunakawa Theoretical Electrodynamics §12 for details. The key points are: (1) in a linear transformation, \(y, z\) can only be linked to linear combinations of \(y', z'\), (2) invariance under the reflection \(y \to -y\) means the proportionality coefficient between \(y\) and \(y'\) is \(\pm 1\), (3) continuity with the identity transformation (\(v = 0\)) selects \(+1\).
⚪ Mei: Then the remaining transformation is
🟡 Lina: Furthermore, it can be shown that \(t'\) and \(x'\) don't contain \(y, z\) either. The reason is the same—\(y\)-reflection and \(z\)-reflection symmetry. If \(t'\) contained \(y\), then under \(y \to -y\), \(t'\) would change, creating an asymmetry between positive and negative \(y\) directions for the flow of time. This violates isotropy. Similarly for \(x'\).
As a result, the transformation is narrowed to:
Let's check the dimensions of each coefficient. Since the left side of \(t' = a_1 t + a_2 x\) has dimensions of time, both \(a_1 t\) (time) and \(a_2 x\) (\(a_2\) × length) must also have dimensions of time. So \(a_1\) is dimensionless and \(a_2\) has dimensions \([\text{time}/\text{length}] = [1/\text{velocity}]\). Similarly, from \(x' = a_5 t + a_6 x\), \(a_5\) has dimensions \([\text{length}/\text{time}] = [\text{velocity}]\) and \(a_6\) is dimensionless.
🔵 Kai: The 16 coefficients have been reduced to just 4!
One Determined from the Motion of the \(S'\) Origin¶
🟡 Lina: From the \(S\) frame, the origin of \(S'\) (\(x' = 0\)) is at position \(x = vt\) at time \(t\). Substituting \(x' = 0\) and \(x = vt\) into \(x' = a_5\,t + a_6\,x\):
Therefore
⚪ Mei: With \(a_5 = -a_6 v\) eliminating \(a_5\), the unknowns are now \(a_1, a_2, a_6\)—just 3.
🔵 Kai: 16 down to 3 in a flash... symmetry is powerful.
The Remaining Determined from \(ds^2\) Invariance¶
🟡 Lina: Now we use the \(ds^2\) invariance established in Section 2.
Since \(y' = y\), \(z' = z\), we have \(dy'^2 + dz'^2 = dy^2 + dz^2\) canceling on both sides, leaving only the \(t\)-\(x\) relationship:
The infinitesimal displacements also follow the same linear transformation:
Substituting and rearranging:
We expand the left side and compare coefficients of \(dt^2\), \(dx^2\), and \(dt\,dx\) with the right side.
⚪ Mei: Let me expand. The first term on the left \(-(c\,a_1\,dt + c\,a_2\,dx)^2\) is
The second term \(a_6^2(dx - v\,dt)^2\) is
🔵 Kai: It's just using \((a + b)^2 = a^2 + 2ab + b^2\), but with so many terms it gets confusing...
🟡 Lina: It's fine. What we're doing is simple—expand the left side completely, organize by the three types \(dt^2\), \(dx^2\), \(dt\,dx\), and compare with the corresponding coefficients on the right side \(-(c\,dt)^2 + dx^2 = -c^2\,dt^2 + dx^2\). "Coefficients of like terms must be equal"—the same idea as polynomial identities.
Coefficient of \(dt^2\):
Coefficient of \(dx^2\):
Coefficient of \(dt\,dx\) (cross term):
⚪ Mei: We just need to solve these 3 simultaneous equations.
🟡 Lina: Right. Solving the cross-term equation \(-2c^2 a_1 a_2 - 2a_6^2 v = 0\) for \(a_2\) gives \(a_2 = -a_6^2 v/(c^2 a_1)\). Substituting into the \(dx^2\) equation \(-c^2 a_2^2 + a_6^2 = 1\):
🔵 Kai: Hmm, there are two unknowns \(a_1\) and \(a_6\) but only one equation, so we can't solve it yet, right?
🟡 Lina: Exactly. So we also use the other equation—the \(dt^2\) coefficient equation. From \(-c^2 a_1^2 + a_6^2 v^2 = -c^2\), rearranging gives \(c^2(a_1^2 - 1) = a_6^2 v^2\), i.e.,
From this, \(a_6^2 v^2 = c^2(a_1^2 - 1)\), so substituting into \(a_6^2 v^2/(c^2 a_1^2)\) from the equation above:
⚪ Mei: Then substituting into \(a_6^2\!\left(1 - \frac{a_6^2\,v^2}{c^2\,a_1^2}\right) = 1\) gives \(a_6^2\!\left(1 - \left(1 - \frac{1}{a_1^2}\right)\right) = a_6^2 \cdot \frac{1}{a_1^2} = 1\), so \(a_6^2 = a_1^2\), i.e., \(a_6 = \pm a_1\).
🟡 Lina: Which sign to choose is determined by physics. To recover the identity transformation (\(x' = x\)) when \(v \to 0\), we need \(a_6 = +a_1\). Putting \(a_6 = a_1\) back into the \(dt^2\) equation \(-c^2 a_1^2 + a_6^2 v^2 = -c^2\) gives \(-c^2 a_1^2 + a_1^2 v^2 = -c^2\). Factoring the left side by \(a_1^2\): \(a_1^2(-c^2 + v^2) = -c^2\), i.e., \(a_1^2(c^2 - v^2) = c^2\). Dividing both sides by \(c^2 - v^2\):
Therefore
(\(a_2\) is obtained by substituting \(a_6 = a_1\) into the cross-term equation \(a_2 = -a_6^2 v/(c^2 a_1)\) to get \(a_2 = -a_1 v/c^2\).) For detailed intermediate calculations, see also the exercise (→ Problem M-1. Detailed Calculation for Determining the Lorentz Transformation Coefficients).
🔵 Kai: How is the \(\pm\) sign of \(a_6\) determined?
🟡 Lina: Good question. We want the identity transformation (\(t' = t\), \(x' = x\)) to be recovered when \(v \to 0\), so we choose \(a_6 = +1/\sqrt{\cdots}\). Choosing minus would give a transformation that includes a spatial inversion.
Completion of the Lorentz Transformation¶
🟡 Lina: Introducing the Lorentz factor
and the dimensionless velocity (beta) \(\beta \equiv v/c\), the transformation can be written neatly as:
In matrix form:
This is the Lorentz transformation representing a boost in the \(x\) direction.
🔵 Kai: In Ch. 1, we had the Galilean transformation \(x' = x - vt\), \(t' = t\). When \(v \ll c\), \(\gamma \approx 1\), \(\beta \approx 0\), and the \(\beta\,x/c\) term in the \(t'\) equation is also negligible, so... it reduces to the Galilean transformation! But conversely, when \(v\) approaches \(c\), how much difference appears?
🟡 Lina: Good question. The Lorentz transformation is the "speed-of-light-aware correction" of the Galilean transformation. At everyday speeds the difference is invisible, but as \(v\) approaches \(c\), it becomes dramatic. Let me summarize the comparison of the two transformations in a table.
Table 3.4: Comparison of Galilean and Lorentz transformations
| Galilean transformation | Lorentz transformation | |
|---|---|---|
| Time transformation | \(t' = t\) (absolute time) | \(ct' = \gamma(ct - \beta\,x)\) |
| Space transformation | \(x' = x - vt\) | \(x' = \gamma(x - \beta\,ct)\) |
| Preserved invariant | Spatial distance \(dx^2 + dy^2 + dz^2\) | Spacetime interval \(-(cdt)^2 + dx^2 + dy^2 + dz^2\) |
| Relationship between time and space | Completely independent | Mix together |
| Velocity addition | \(v_{12} = v_1 + v_2\) | \(v_{12} = \dfrac{v_1 + v_2}{1 + v_1 v_2/c^2}\) (derivable by applying the Lorentz transformation twice; derivation in exercise → Problem M-5. Derivation of the Velocity Addition Formula. Reduces to the Galilean formula when \(v_1, v_2 \ll c\), and gives \(v_{12} = c\) even when \(v_1 = v_2 = c\)—never exceeds the speed of light) |
| Range of validity | \(v \ll c\) | Any \(v < c\) |
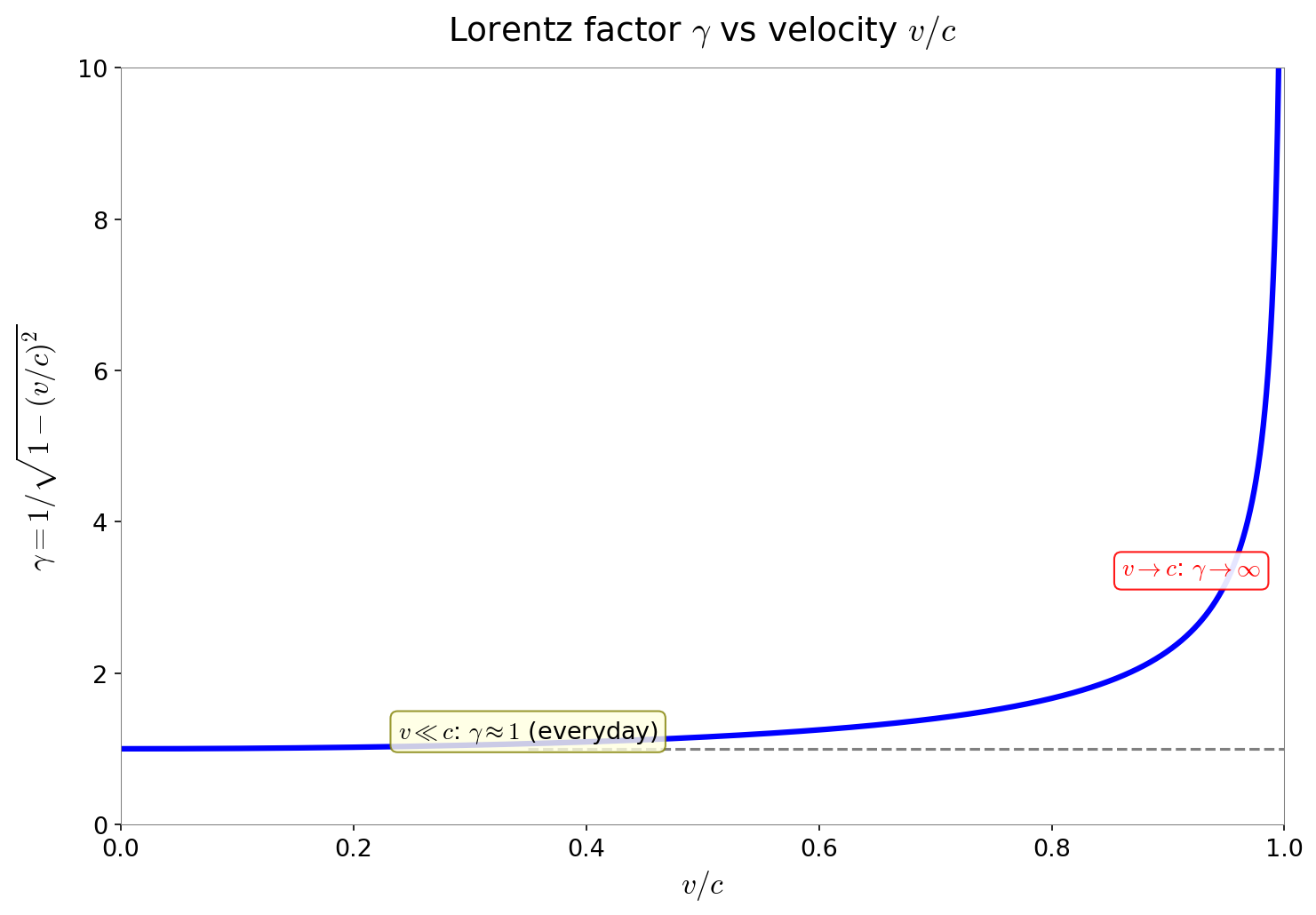
Fig. 3.8: Relationship between the Lorentz factor and velocity. The Lorentz factor \(\gamma = 1/\sqrt{1 - v^2/c^2}\) increases rapidly as velocity approaches the speed of light. At everyday speeds (\(v \ll c\)), \(\gamma \approx 1\), but \(\gamma \to \infty\) as \(v \to c\).
🔵 Kai: Looking at Fig. 3.8 "Relationship between the Lorentz factor and velocity", \(\gamma\) diverges to infinity as \(v \to c\). Does that mean you can't actually reach \(v = c\)?
🟡 Lina: Exactly. Accelerating a massive object to the speed of light would require infinite energy—we'll see this quantitatively in Ch. 4 when we derive the relationship between energy and momentum.
✅ Comprehension Check: In what limit does the Lorentz transformation reduce to the Galilean transformation?
Answer
In the limit \(v \ll c\) (velocity much smaller than the speed of light). Then \(\gamma \approx 1\), and \(t' \approx t\), \(x' \approx x - vt\), recovering the Galilean transformation.
Geometric Interpretation — A Boost Is a "Hyperbolic Rotation" in Spacetime¶
🟡 Lina: We've now obtained the explicit form of the Lorentz transformation. But looking at this matrix, a structure becomes visible—the form of the equations is very similar to 3-dimensional spatial rotations.
🔵 Kai: Spatial rotations and... boosts are similar?
🟡 Lina: Let's compare. A coordinate rotation in the \(xy\) plane (rotating the axes counterclockwise by angle \(\theta\)) is:
(In 3.2 "Invariance of the Spacetime Interval" we wrote the inverse transformation form "expressing \((x, y)\) using \((x', y')\)." Here, for comparison with the boost, we write the forward transformation form "finding \((x', y')\) from \((x, y)\)." Solving \(x = x'\cos\theta - y'\sin\theta\), \(y = x'\sin\theta + y'\cos\theta\) from Section 2 for \((x', y')\) gives \(x' = x\cos\theta + y\sin\theta\), \(y' = -x\sin\theta + y\cos\theta\). Check: \(x'^2 + y'^2 = (x\cos\theta + y\sin\theta)^2 + (-x\sin\theta + y\cos\theta)^2\). Expanding: \(x^2\cos^2\theta + 2xy\cos\theta\sin\theta + y^2\sin^2\theta + x^2\sin^2\theta - 2xy\sin\theta\cos\theta + y^2\cos^2\theta = x^2(\cos^2\theta + \sin^2\theta) + y^2(\sin^2\theta + \cos^2\theta) = x^2 + y^2\).)
This preserves the invariant \(x^2 + y^2\). On the other hand, the Lorentz transformation (boost) in the \(t\)-\(x\) direction is:
This preserves the invariant \(-(ct)^2 + x^2\). The matrix structures are similar—diagonal entries are equal, and off-diagonal entries have equal absolute values. However, the rotation matrix has off-diagonal entries with opposite signs (the \((1,2)\) entry is \(+\sin\theta\), the \((2,1)\) entry is \(-\sin\theta\)), while the boost matrix has off-diagonal entries with the same sign (both are \(-\sinh\varphi\)). This difference arises because rotation preserves the invariant \(x^2 + y^2\) (all positive), while the boost preserves \(-(ct)^2 + x^2\) (mixed signs)—this difference in sign structure is reflected in the matrix symmetry.
⚪ Mei: The difference is: spatial rotation uses \(\cos^2\theta + \sin^2\theta = 1\) (plus), while the boost preserves an invariant with mixed minus and plus signs, so... some different identity should be usable.
🟡 Lina: Exactly. Let me introduce new functions. The trigonometric functions \(\cos\theta, \sin\theta\) were the parametric representation of the unit circle \(x^2 + y^2 = 1\) (setting \(x = \cos\theta, y = \sin\theta\) automatically satisfies \(x^2 + y^2 = 1\)). Similarly, for the unit hyperbola \(x^2 - y^2 = 1\), there are functions that represent all points \((x, y)\) on the curve by varying a single parameter \(\varphi\)—these are the hyperbolic functions:
This definition may seem to come from nowhere, but the idea is simple. We want to represent \((x, y)\) satisfying \(x^2 - y^2 = 1\) with a single parameter \(\varphi\)—the same idea as how trigonometric functions automatically satisfy \(\cos^2\theta + \sin^2\theta = 1\).
🔵 Kai: Trigonometric functions are for the unit circle with \(+\), and these are for the hyperbola with \(-\). How do we arrive at this specific form?
🟡 Lina: First, factor \(x^2 - y^2\) as \((x+y)(x-y) = 1\). We need "the product of \(x+y\) and \(x-y\) to be 1." So we want to find a pair of functions whose product is 1. Recall the exponential law from high school \(e^a \cdot e^b = e^{a+b}\)—what if we choose \(a\) and \(b\) so their sum is zero?
🔵 Kai: If \(a = \varphi\), \(b = -\varphi\), then \(e^\varphi \cdot e^{-\varphi} = e^0 = 1\)! Indeed their product is 1.
🟡 Lina: Exactly! Setting \(x + y = e^\varphi\), \(x - y = e^{-\varphi}\), we get \((x+y)(x-y) = e^\varphi \cdot e^{-\varphi} = 1\), so \(x^2 - y^2 = 1\) is automatically satisfied. Solving these simultaneous equations for \(x, y\) gives \(x = (e^\varphi + e^{-\varphi})/2\), \(y = (e^\varphi - e^{-\varphi})/2\). Naming these \(\cosh\varphi\) and \(\sinh\varphi\) is the definition of hyperbolic functions.
🔵 Kai: I understand the definition, but what are the actual numerical values? I want the intuition like \(\cos 0 = 1\), \(\sin 0 = 0\).
🟡 Lina: Let's look at concrete values (\(e \approx 2.718\) is the base of the natural logarithm; \(e^\varphi\) increases rapidly as \(\varphi\) grows, with the properties \(e^0 = 1\) and \(e^{-\varphi} = 1/e^\varphi\)). For \(\varphi = 0\): \(\cosh 0 = (1+1)/2 = 1\), \(\sinh 0 = (1-1)/2 = 0\). For \(\varphi = 1\): \(\cosh 1 = (e + e^{-1})/2 \approx (2.72 + 0.37)/2 \approx 1.54\), \(\sinh 1 = (e - e^{-1})/2 \approx (2.72 - 0.37)/2 \approx 1.18\). As \(\varphi\) increases, \(\cosh\varphi\) grows rapidly like \(e^\varphi/2\), and \(\sinh\varphi\) similarly (though \(\cosh\) is always larger than \(\sinh\)).
⚪ Mei: At \(\varphi = 0\), \((\cosh, \sinh) = (1, 0)\)—the same starting point as \((\cos 0, \sin 0) = (1, 0)\) for trigonometric functions.
🟡 Lina: Right. Setting \(x = \cosh\varphi\), \(y = \sinh\varphi\), we have \(x^2 - y^2 = \cosh^2\varphi - \sinh^2\varphi = 1\)—that's why they're called "hyperbolic" functions. Just as setting \(x = \cos\theta\), \(y = \sin\theta\) gives \(x^2 + y^2 = 1\) (the unit circle), hyperbolic functions trace \(x^2 - y^2 = 1\) (the unit hyperbola). Let's verify:
Using \((a+b)^2 - (a-b)^2 = 4ab\) (a high school expansion formula), with \(a = e^\varphi/2\), \(b = e^{-\varphi}/2\):
(Using the exponential law \(e^a \cdot e^b = e^{a+b}\).) As \(\varphi\) varies, the point \((x, y)\) moves along the hyperbola \(x^2 - y^2 = 1\).
🔵 Kai: So it's defined using exponentials of \(e\). It looks similar to the trigonometric functions \(\cos\theta\) and \(\sin\theta\)—is there some relationship? The appearance of \(e^\varphi\) in the definition is intriguing...
🟡 Lina: Good intuition. There is indeed a deep mathematical connection between trigonometric and hyperbolic functions. However, understanding it requires knowledge of complex numbers, so I won't go into it now. At this stage, thinking of them as "relatives of trigonometric functions where the sign in the identity changes from \(+\) to \(-\)" is sufficient.
🔵 Kai: "Relatives where only the sign changes." Then I'll move on without going deeper for now.
🟡 Lina: Looking at Fig. 3.9 "Comparison of trigonometric and hyperbolic functions" makes the correspondence between the two immediately clear.
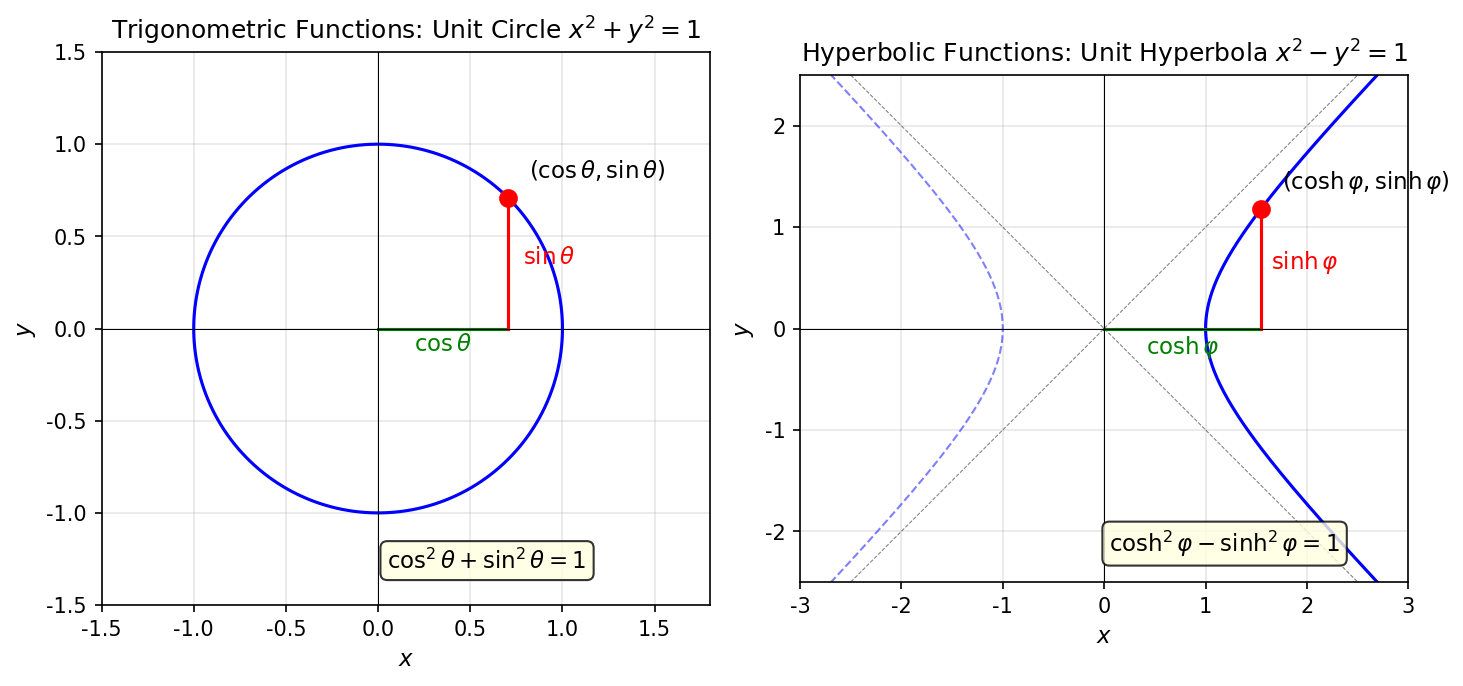
Fig. 3.9: Comparison of trigonometric and hyperbolic functions. Left: trigonometric functions \((\cos\theta, \sin\theta)\) move on the unit circle \(x^2 + y^2 = 1\). Right: hyperbolic functions \((\cosh\varphi, \sinh\varphi)\) move on the unit hyperbola \(x^2 - y^2 = 1\). The sign difference in the identities (\(+\) vs \(-\)) corresponds to the difference between Euclidean geometry and Minkowski spacetime.
🟡 Lina: And the key identity is
Compared to the trigonometric \(\cos^2\theta + \sin^2\theta = 1\) with plus, hyperbolic functions have minus. This corresponds exactly to the sign pattern of \(-(ct)^2 + x^2\).
🔵 Kai: So I can see that hyperbolic functions might be useful here. But I still don't quite grasp the motivation for replacing \(\gamma\) and \(\beta\) with \(\cosh, \sinh\).
🟡 Lina: The key is "wanting to rewrite the Lorentz transformation matrix with a single parameter." The spatial rotation matrix is determined by just one parameter—the angle \(\theta\) (\(\cos\theta, \sin\theta\) change in tandem). Similarly, the boost matrix should also be expressible with one parameter.
Looking at the boost matrix components \(\gamma\) and \(\gamma\beta\), we find the relation \(\gamma^2 - (\gamma\beta)^2 = \gamma^2(1 - \beta^2) = \frac{1}{1-\beta^2}\cdot(1-\beta^2) = 1\)—this is the same form as the hyperbolic identity \(\cosh^2\varphi - \sinh^2\varphi = 1\)! So setting \(\cosh\varphi = \gamma, \sinh\varphi = \gamma\beta\) automatically satisfies the identity. Using this \(\varphi\), we can express both \(\gamma\) and \(\beta\) simultaneously with one parameter.
🔵 Kai: Oh, \(\gamma^2 - (\gamma\beta)^2 = 1\) happens to have exactly the form of the hyperbolic identity!
🟡 Lina: Let's verify concretely. Identifying \(\gamma = 1/\sqrt{1-\beta^2}\) with \(\cosh\varphi\), from the identity \(\sinh\varphi = \sqrt{\cosh^2\varphi - 1} = \sqrt{\gamma^2 - 1} = \sqrt{1/(1-\beta^2) - 1} = \beta/\sqrt{1-\beta^2} = \gamma\beta\). And defining \(\tanh\varphi \equiv \sinh\varphi/\cosh\varphi\) (hyperbolic tangent) in the same spirit as \(\tan\theta = \sin\theta/\cos\theta\), we get \(\tanh\varphi = \gamma\beta/\gamma = \beta\). As for pronunciation, \(\cosh\) is often read "cosh," \(\sinh\) as "sinch," and \(\tanh\) as "tanch" (some also read them as "hyperbolic cosine," etc.). \(\tanh\) is zero at \(\varphi = 0\) and asymptotes to 1 as \(\varphi \to \infty\)—which perfectly corresponds to \(\beta = v/c\) going from 0 toward 1 (approaching the speed of light but never reaching it). Therefore:
This parameter \(\varphi\) is called the rapidity. The Lorentz transformation then becomes:
Nearly the same form as spatial rotation! \(\cos \to \cosh\), \(\sin \to \sinh\), and the sign pattern of the off-diagonal entries is slightly different (rotation has \(+\sin\) and \(-\sin\); boost has both \(-\sinh\)), but the structure of "equal diagonal entries and equal absolute values of off-diagonal entries" is shared.
🔵 Kai: So a boost is a kind of "rotation" in spacetime?
🟡 Lina: Yes. While spatial rotation is a transformation that mixes the \(x\)-\(y\) axes, a boost is a transformation that mixes the \(t\)-\(x\) axes. However, since the time and space axes have opposite signs in the invariant (\(-(ct)^2 + x^2\)), it's not an ordinary rotation (\(\cos, \sin\)) but a hyperbolic rotation.
⚪ Mei: That's why people say "the Lorentz transformation is a rotation in spacetime." Physically it's switching inertial frames, but geometrically it's the same as a hyperbolic rotation in the \(t\)-\(x\) plane.
🔵 Kai: By the way, how large can the rapidity \(\varphi\) get? For angle \(\theta\), it goes from \(0\) to \(2\pi\) and returns to the start.
🟡 Lina: Rapidity can freely take any value in the range \(-\infty < \varphi < \infty\). It's connected to velocity through \(\tanh\varphi = v/c\): as \(\varphi \to \infty\), \(v \to c\) (approaches the speed of light but never reaches it). So spatial rotation has a compact parameter space (\([0, 2\pi)\), periodic and finite range), while the boost is non-compact (extends to infinity).
⚪ Mei: The difference between rotation, which "goes around and returns to the start," and boosts, where "no matter how much you accelerate you never reach the speed of light," is directly reflected in the shape of the parameter space.
🟡 Lina: This difference is also important from a group-theoretic perspective, deeply related to the mathematical structure of the Lorentz group. For now, remember that "the two have similar forms, but the range of achievable parameters is fundamentally different." And the total of 6 transformations—3 types of spatial rotation (\(x\)-\(y\), \(y\)-\(z\), \(z\)-\(x\)) and 3 types of boost (\(t\)-\(x\), \(t\)-\(y\), \(t\)-\(z\))—are collectively called the Lorentz transformation in the broad sense.
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart TB
ds["Invariant ds² = -(cdt)² + dx² + dy² + dz²"]
ds -->|"Transformations preserving ds²"| LT["<b>Lorentz Transformation</b> (6 types)"]
LT --> rot["<b>Spatial Rotations</b> (3 types)<br/>Rotations between x-y, y-z, z-x axes<br/>Parameter: angle θ<br/>cos²θ + sin²θ = 1"]
LT --> boost["<b>Boosts</b> (3 types)<br/>Hyperbolic rotations between t-x, t-y, t-z axes<br/>Parameter: rapidity φ<br/>cosh²φ - sinh²φ = 1<br/>= Switching inertial frames"]
style ds fill:#fff3cd,stroke:#856404
style LT fill:#d1ecf1,stroke:#0c5460
style rot fill:#d4edda,stroke:#155724
style boost fill:#f8d7da,stroke:#721c24✅ Comprehension Check: Why is the boost part of the Lorentz transformation called a "hyperbolic rotation" despite being similar to spatial rotation?
Answer
Spatial rotation preserves the invariant \(x^2 + y^2\) and corresponds to the trigonometric identity \(\cos^2\theta + \sin^2\theta = 1\), while a boost preserves the invariant \(-(ct)^2 + x^2\) (which includes a minus sign) and corresponds to the hyperbolic identity \(\cosh^2\varphi - \sinh^2\varphi = 1\). The matrix form is the same with the replacements \(\cos \to \cosh\), \(\sin \to \sinh\).
Looking at Fig. 3.11 "Invariant hyperbolae and Lorentz boost", the locus of \(-(ct)^2 + x^2 = \text{const}\) traces a hyperbola—a boost moves points along this hyperbola. The tick marks on boosted coordinate axes are calibrated by their intersections with the invariant hyperbola.
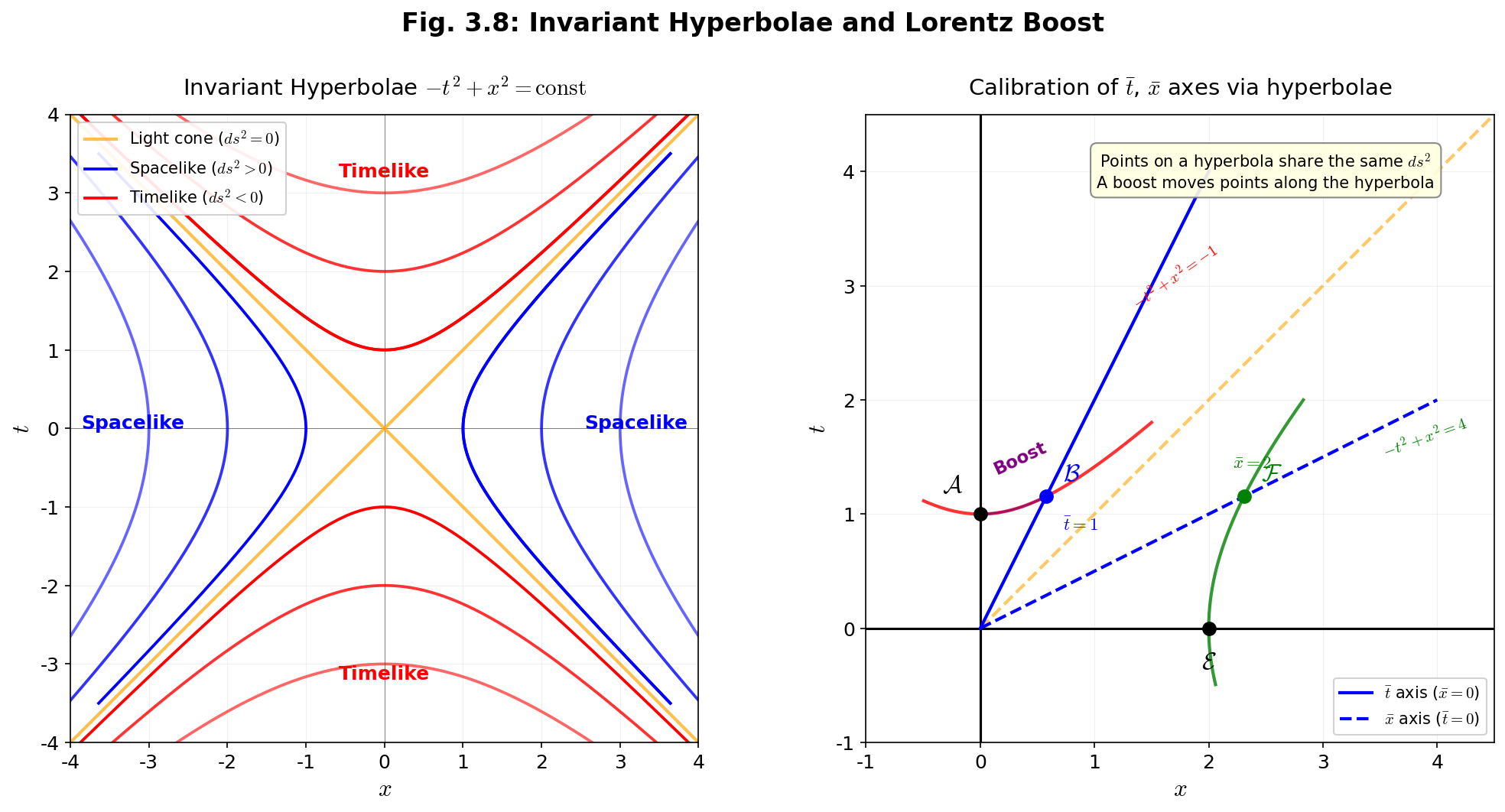
Fig. 3.11: Invariant hyperbolae and Lorentz boost. Left: The locus of \(-(ct)^2 + x^2 = \mathrm{const}\) traces hyperbolae (axes drawn in \(c = 1\) units). Timelike (\(ds^2 < 0\), red) and spacelike (\(ds^2 > 0\), blue) hyperbolae are separated by the light cone (orange). Right: The tick marks on boosted coordinate axes \(\bar{t}, \bar{x}\) are calibrated by intersections with invariant hyperbolae. Event \(\mathcal{A}\) (\(t=1\) in the \(S\) frame) and event \(\mathcal{B}\) (\(\bar{t}=1\) in the \(\bar{S}\) frame) lie on the same hyperbola and are connected by a boost.
📝 Exercises:
- Hyperbolic functions, rapidity, and Lorentz transformation derivation → Problem B-1. Derivation of the Hyperbolic Function Identity, Problem B-2. Relationship between Rapidity and the Lorentz Factor, Problem B-3. Contraction Calculation of the Lorentz Transformation Matrix, Problem M-1. Detailed Calculation for Determining the Lorentz Transformation Coefficients, Problem M-2. Metric Preservation Condition under Lorentz Transformation
3.4 Physical Consequences of the Lorentz Transformation¶
🟡 Lina: Now I'll derive three physical consequences. From the Lorentz transformation equations, we'll see that the concepts of simultaneity, time, and length change depending on the inertial frame.
Unit system in this section: In this chapter, we write \(c\) explicitly. The natural unit system \(c = 1\) will be introduced in the next Ch. 4, but when examining physical consequences, it's better to keep the dimensional correspondence clear, so we retain \(c\) in this chapter.
Relativity of Simultaneity¶
🟡 Lina: Look at the \(t'\) equation of the Lorentz transformation again.
Consider two events that are simultaneous (\(t_A = t_B\)) in the \(S\) frame but occur at different locations (\(x_A \neq x_B\)):
🔵 Kai: They're no longer simultaneous! If the locations differ, there's a time difference in another inertial frame. ...But \(-\gamma v(x_A - x_B)/c^2\)—the larger the spatial separation \(x_A - x_B\), the larger the time difference. At everyday scales—say 1 km apart—how much would the shift be?
🟡 Lina: For example, on a Shinkansen (\(v \approx 80\,\mathrm{m/s}\)) with \(x_A - x_B = 1\,\mathrm{km}\): \(\gamma v \Delta x / c^2 \approx 80 \times 1000 / (3 \times 10^8)^2 \approx 10^{-12}\,\mathrm{s}\)—one trillionth of a second. Undetectable in daily life, but for precision systems like GPS satellites, it cannot be ignored. This is the relativity of simultaneity. Newton's "absolute simultaneity" does not hold. Look at Fig. 3.12 "Relativity of simultaneity"—you can visually see that the simultaneity line in the \(S\) frame and in the \(S'\) frame are tilted relative to each other.
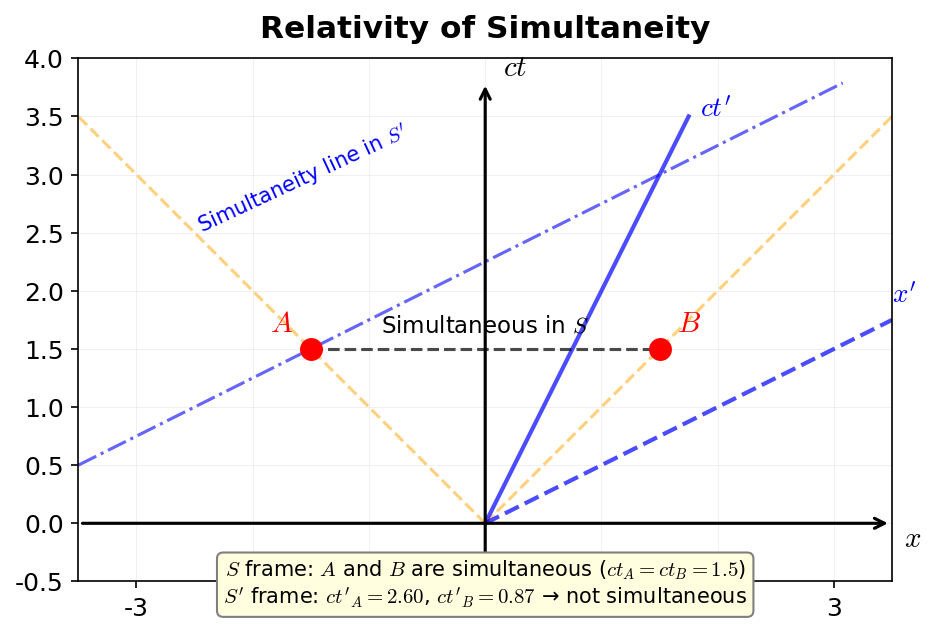
Fig. 3.12: Relativity of simultaneity. Two events A, B that are simultaneous in the \(S\) frame (black dotted line) are not simultaneous in the \(S'\) frame (\(v = 0.5c\)). The simultaneity line of the \(S'\) frame (blue dash-dot line) is tilted relative to that of the \(S\) frame.
Time Dilation¶
🟡 Lina: To build intuition for time dilation, I'll use a thought experiment called the "light clock" (Fig. 3.13 "Derivation of time dilation using a light clock").
Fig. 3.13: Derivation of time dilation using a light clock. The light clock thought experiment. Left: In the \(S'\) frame (light clock at rest), light bounces vertically between mirrors, and the round-trip time is \(\Delta t' = 2L/c\). Right: In the \(S\) frame (light clock moving at velocity \(v\)), light follows a diagonal path, and from the Pythagorean theorem, \(\Delta t = \gamma\,\Delta t'\) is derived.
🟡 Lina: Consider a "light clock" where light bounces back and forth between 2 mirrors separated by distance \(L\). In the \(S'\) frame (light clock at rest), light bounces vertically, so one round trip takes \(\Delta t' = 2L/c\). In the \(S\) frame (light clock moving sideways at velocity \(v\)), light travels diagonally so the path is longer. If the one-way distance light travels is \(d\), then light travels \(L\) vertically and \(v \cdot (\Delta t/2)\) horizontally, so by the Pythagorean theorem \(d = \sqrt{L^2 + (v\Delta t/2)^2}\). Since the speed of light is \(c\), \(d = c\Delta t/2\). Substituting: \((c\Delta t/2)^2 = L^2 + (v\Delta t/2)^2\), and solving gives \(\Delta t = 2L/(c\sqrt{1-v^2/c^2}) = \gamma\,\Delta t'\)—this is the intuitive understanding of time dilation.
🔵 Kai: You can derive it just from the Pythagorean theorem. The extra time comes from light traveling diagonally—simple but profound.
🟡 Lina: Here I'll derive the same result directly from the Lorentz transformation. Let \(\Delta t'\) be the time interval between two events at the same location (\(\Delta x' = 0\)) in the \(S'\) frame. The inverse Lorentz transformation—from \(S'\) to \(S\)—is obtained simply by replacing \(v \to -v\) in the forward transformation. Here's why: by the principle of relativity, the form of the Lorentz transformation equations is the same regardless of which inertial frame you take as the reference. Taking \(S\) as the reference, "\(S'\) moves at velocity \(+v\)" gives the forward transformation. Now taking \(S'\) as the reference, "\(S\) moves at velocity \(-v\)"—from \(S'\)'s perspective, \(S\) is receding in the opposite direction, so the sign of velocity flips. The same form of equations with only velocity changed to \(-v\) gives the inverse transformation. Since \(\gamma = 1/\sqrt{1 - v^2/c^2}\) depends only on \(v^2\), replacing \(v \to -v\) leaves \(\gamma\) unchanged—only the sign of \(\beta = v/c\) changes. Writing this explicitly, the forward transformation \(ct' = \gamma(ct - \beta x)\), \(x' = \gamma(x - \beta\,ct)\) with \(v \to -v\) (i.e., \(\beta \to -\beta\)) gives:
That is, \(t = \gamma(t' + vx'/c^2)\), \(x = \gamma(x' + vt')\).
(Verification—OK to skip: Substituting the inverse transformation \(t = \gamma(t' + vx'/c^2)\), \(x = \gamma(x' + vt')\) into the forward transformation \(ct' = \gamma(ct - \beta x)\) to verify \(ct'\) is recovered. \(ct = c\gamma(t' + vx'/c^2) = \gamma(ct' + vx'/c)\); \(\beta x = (v/c)\gamma(x' + vt') = \gamma(vx'/c + v^2t'/c)\). So \(\gamma(ct - \beta x) = \gamma\bigl[\gamma(ct' + vx'/c) - \gamma(vx'/c + v^2t'/c)\bigr] = \gamma^2\bigl(ct' - v^2t'/c\bigr) = \gamma^2 \cdot ct'(1 - v^2/c^2) = ct'\). The last step uses \(\gamma^2(1 - v^2/c^2) = 1\)—which follows directly from the definition \(\gamma = 1/\sqrt{1-v^2/c^2}\).) With \(\Delta x' = 0\):
Since \(\gamma > 1\), \(\Delta t > \Delta t'\). Represented on a spacetime diagram, this looks like Fig. 3.14 "Spacetime diagram representation of time dilation".
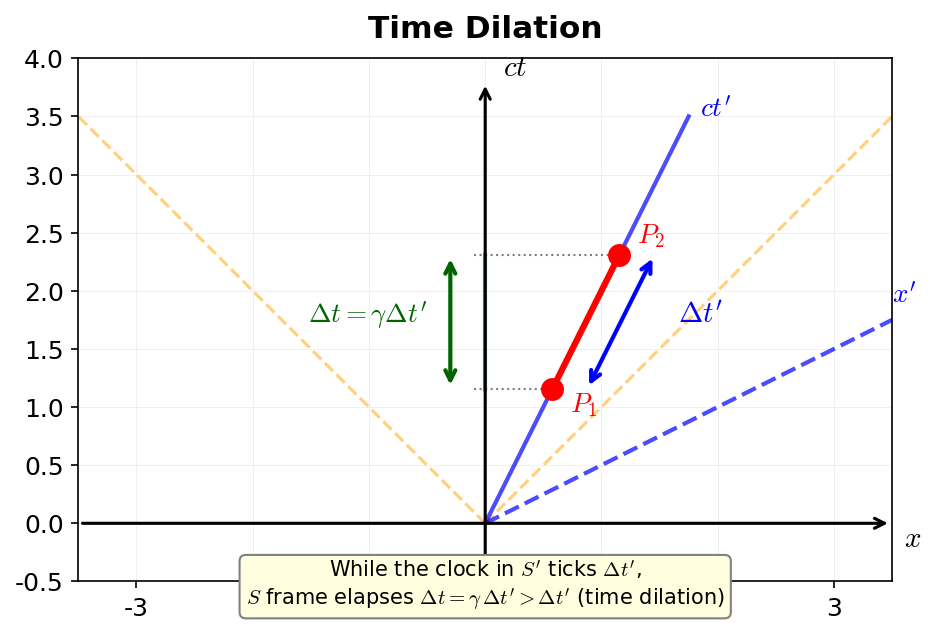
Fig. 3.14: Spacetime diagram representation of time dilation. The interval \(\Delta t'\) ticked by a clock at rest in \(S'\) is stretched to \(\Delta t = \gamma\,\Delta t'\) as seen from \(S\). An interval along the \(ct'\) axis, when projected onto the \(ct\) axis, becomes longer.
Since \(\gamma > 1\), \(\Delta t > \Delta t'\).
🔵 Kai: A moving clock runs slow! At \(v = 0.9c\), \(\gamma \approx 2.3\), so time is more than twice as slow... But wait—from the \(S\) frame, the \(S'\) clock is slow, but from the \(S'\) frame, \(S\) is the one moving, so from \(S'\)'s perspective, would \(S\)'s clock also be slow? Both claiming "the other is slow"—isn't that a contradiction?
🟡 Lina: The "both are slow" question is very important—this is the famous twin paradox, which I'll address in detail in the Dive Deep section just below. Let me give the conclusion first: there's no contradiction. "Both see the other as slow" is symmetric as long as both continue in uniform linear motion, and no experiment can determine which is "really slow." The apparent contradiction arises when one of them accelerates and returns—then the symmetry is broken, and the one who accelerated is definitively younger.
Experimental confirmation comes from muons produced by cosmic rays. Their rest lifetime is about \(2.2\,\mu\mathrm{s}\), but muons flying at near-light speed have extended lifetimes as seen by ground observers, allowing them to traverse the atmosphere and reach the surface.
🔵 Kai: \(2.2\,\mu\mathrm{s}\)—even at light speed that's only \(c \times 2.2 \times 10^{-6} \approx 660\,\mathrm{m}\) of travel distance. The atmosphere is tens of km thick, yet they reach the ground—\(\gamma\) must be quite large for that to work... how large is it actually?
🟡 Lina: Typical cosmic ray muons have high energy and fly at about \(v \approx 0.998c\). Then \(\gamma \approx 15\), and the lifetime as measured by ground clocks is \(15 \times 2.2\,\mu\mathrm{s} \approx 33\,\mu\mathrm{s}\). In that time they travel \(0.998c \times 33\,\mu\mathrm{s} \approx 10\,\mathrm{km}\)—sufficient to reach the ground from the upper atmosphere.
⚪ Mei: If at rest they could only travel \(660\,\mathrm{m}\), but thanks to time dilation they can travel over \(10\,\mathrm{km}\)—direct evidence of time dilation.
🔍 Dive Deep: The Twin Paradox — Why There's No Contradiction
🔵 Kai: Hold on. You say "a moving clock runs slow," but from the \(S\) frame, \(S'\) is moving, and from the \(S'\) frame, \(S\) is moving. If each claims "the other's clock is slow," isn't that contradictory? If one twin goes on a rocket trip and returns, which one is younger?
🟡 Lina: This is the famous twin paradox. The conclusion: the one who traveled by rocket is younger. There's no contradiction.
The key point is that the symmetry is broken. The twin who stays on Earth remains in an inertial frame (uniform motion, zero acceleration) the whole time. The twin who travels by rocket accelerates at departure, decelerates and reverses at the turnaround point, and decelerates upon return—in other words, experiences acceleration. This acceleration makes the two situations asymmetric.
Special relativity's "a moving clock runs slow" applies only to comparisons between inertial frames. Since the rocket twin switches inertial frames at the turnaround, you simply cannot say "from the traveling twin's perspective, the Earth twin is moving."
Quantitatively, think in terms of proper time \(\tau\) (time measured by the object's own clock). The time dilation formula \(\Delta t' = \Delta t/\gamma = \Delta t\sqrt{1 - v^2/c^2}\), applied to infinitesimal intervals when velocity varies and summed up, gives \(\tau = \int \sqrt{1 - v^2/c^2}\,dt\) (the formal definition of proper time will be given in Ch. 4). Computing this integral along each twin's worldline gives the answer. The Earth twin in an inertial frame has \(\tau_{\text{Earth}} = \Delta t\) (coordinate time directly). The rocket twin who accelerates and decelerates has intervals with \(v > 0\), so \(\sqrt{1 - v^2/c^2} < 1\), giving \(\tau_{\text{rocket}} < \Delta t = \tau_{\text{Earth}}\). The rocket twin has shorter proper time = is younger.
🔵 Kai: On the spacetime diagram, the Earth twin's worldline is straight and the rocket twin's is bent... In ordinary geometry, a detour makes the path longer. But here the rocket twin has shorter proper time—isn't it reversed?
🟡 Lina: Good observation. Exactly—in Minkowski spacetime, a straight worldline maximizes proper time—the opposite property from Euclidean geometry. This connects to the topic of "geodesics" in Ch. 8. The fundamental reason is the minus sign in the spacetime interval.
Length Contraction¶
🟡 Lina: Next is length contraction. Let's think while looking at Fig. 3.15 "Spacetime diagram representation of length contraction".
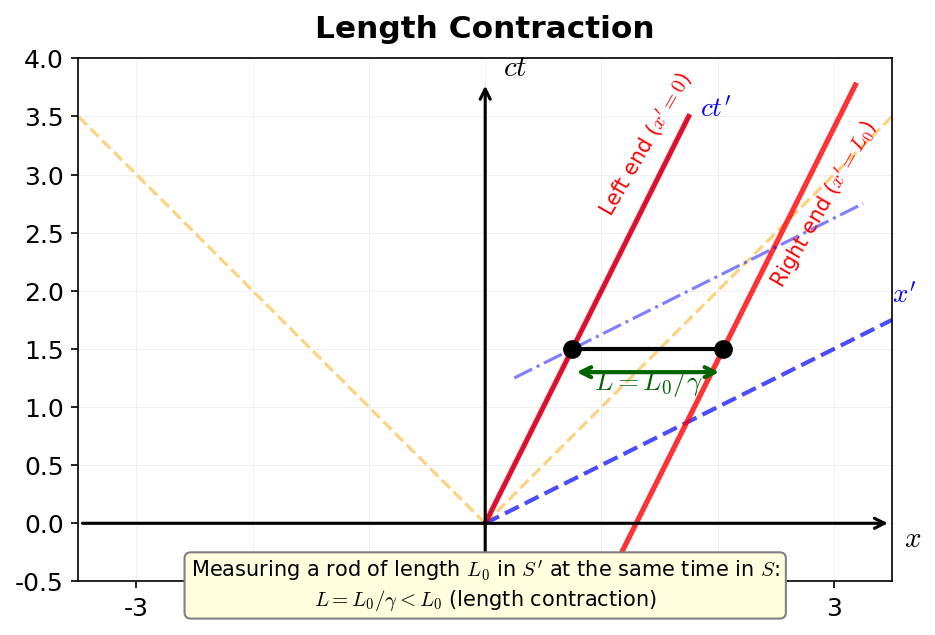
Fig. 3.15: Spacetime diagram representation of length contraction. A rod at rest in the \(S'\) frame (two red worldlines), when measured "simultaneously" in the \(S\) frame, has length \(L = L_0/\gamma\) shorter than its proper length \(L_0\). The cause is that the simultaneity lines of the \(S\) frame (horizontal) and \(S'\) frame (tilted blue dash-dot line) differ.
🟡 Lina: Suppose a rod at rest in the \(S'\) frame has length \(L_0\) (proper length). Measuring the coordinates of both ends simultaneously (\(\Delta t = 0\)) in the \(S\) frame, taking the difference of the Lorentz transformation \(x' = \gamma(x - vt)\):
Let me confirm why we can set \(\Delta x' = L_0\). Since the rod is at rest in the \(S'\) frame, the \(x'\) coordinates of both ends are constant in time—for example, the left end stays at \(x' = 0\) and the right end stays at \(x' = L_0\). When we measure both ends simultaneously (\(\Delta t = 0\)) in the \(S\) frame and convert the results to \(S'\) coordinates via the Lorentz transformation, in the \(S'\) frame the two measurement events may not be simultaneous. But since the rod is stationary, the right end is at \(x' = L_0\) and the left end at \(x' = 0\) regardless of when the measurements are taken. So even if they're not simultaneous in the \(S'\) frame, \(\Delta x' = L_0\) holds (concrete example: even if the right-end measurement event corresponds to \(t' = 3\) and the left-end to \(t' = 5\) in the \(S'\) frame, the rod isn't moving, so the difference is \(L_0 - 0 = L_0\)). Therefore with \(\Delta x' = L_0\) and \(\Delta x = L\):
🔵 Kai: A moving object appears contracted in the direction of motion... but is it really physically contracted? Or does it just "look that way"?
🟡 Lina: The result of the operation "measure the positions of both ends at the same time" gives \(L = L_0/\gamma\)—this is a real effect in terms of measurement outcomes. However, the material inside the rod is not being compressed by forces. Since the meaning of "measuring at the same time" differs between inertial frames, you're cutting a different cross-section of the same rod, and the length appears different—the difference in how you slice spacetime manifests as a difference in length.
⚪ Mei: The condition "measuring at the same time" is essential here. Recalling the relativity of simultaneity from earlier, a simultaneous measurement in the \(S\) frame is not simultaneous in the \(S'\) frame—that's exactly why the length changes.
🔵 Kai: It goes against intuition, but everything follows from the Lorentz transformation. ...But one thing puzzles me: time dilation and length contraction only differ in whether \(\gamma\) appears in the numerator or denominator. Why does time "stretch" while length "contracts"? Why doesn't it go the other way?
🟡 Lina: Good question. The key is "what's being held fixed." For time dilation, we fix \(\Delta x' = 0\) (same location) and compare times—the time in the \(S\) frame is stretched by a factor \(\gamma\) relative to \(S'\). For length contraction, we fix \(\Delta t = 0\) (simultaneous) and compare positions—the length in \(S'\) is contracted by \(1/\gamma\) relative to \(S\). Since which frame you fix and which you compare are swapped, \(\gamma\) appears on opposite sides.
⚪ Mei: So because the frame being fixed and the frame being compared are interchanged, \(\gamma\) ends up in the numerator in one case and the denominator in the other.
🔵 Kai: Ah, I see. Because "what you hold fixed" differs, the results go in opposite directions. It's the same Lorentz transformation, but changing the cross-section reveals stretching or contracting—you're just seeing different faces of one transformation.
🔵 Kai: So in the general case where \(\Delta t' \neq 0\) and \(\Delta x' \neq 0\)—nothing held fixed—do time dilation and length contraction get mixed together?
🟡 Lina: Good question. Exactly—in the general case you have no choice but to use the Lorentz transformation equations directly. Time dilation and length contraction are just "cross-sections" obtained when specific conditions are fixed. Relativity of simultaneity, time dilation, and length contraction—these are not separate phenomena but merely different aspects of the single transformation rule that is the Lorentz transformation.
🔵 Kai: I see... from one transformation, different faces appear depending on how you cut. Conversely, if you master the Lorentz transformation, everything comes out. But what about the accelerating case—if you leave inertial frames, the transformation itself becomes inapplicable, right?
🟡 Lina: Exactly. To handle accelerating frames, transformations between inertial frames alone aren't sufficient—you need a framework capable of handling "arbitrary coordinate transformations"—and that's precisely the stage of general relativity. We'll tackle it seriously from Ch. 5 onward. For now, let's organize what happens between inertial frames.
🔵 Kai: Special relativity is the "inertial-frames-only" theory, and general relativity lies beyond—I can see where it fits in the overall picture.
🟡 Lina: Right. Let me organize the three consequences from the Lorentz transformation at this stage.
Table 3.5: Comparison of the three physical consequences of the Lorentz transformation
| Consequence | Fixed condition | Result | Formula |
|---|---|---|---|
| Relativity of simultaneity | \(t_A = t_B\) (simultaneous in \(S\)) | Not simultaneous in \(S'\) | \(t'_A - t'_B = -\gamma v(x_A - x_B)/c^2\) |
| Time dilation | \(\Delta x' = 0\) (same location in \(S'\)) | Time stretches in \(S\) | \(\Delta t = \gamma\,\Delta t'\) |
| Length contraction | \(\Delta t = 0\) (measured simultaneously in \(S\)) | Contracts in direction of motion | \(L = L_0/\gamma\) |
✅ Comprehension Check: Explain time dilation in one sentence.
Answer
A moving clock runs slower than a stationary clock. A time interval \(\Delta t'\) measured at the same location in the \(S'\) frame is stretched to \(\Delta t = \gamma \Delta t'\) (\(\gamma > 1\)) as seen from the \(S\) frame.
📝 Exercises:
- Relativity of simultaneity, time dilation, velocity addition → Problem M-3. Quantitative Consequences of the Relativity of Simultaneity, Problem M-4. Relationship Between Proper Time and Coordinate Time, Problem M-5. Derivation of the Velocity Addition Formula, Problem M-6. Relativity of Simultaneity (Concrete Example)
Summary¶
In this chapter, we traced the path from the starting point of special relativity through the Lorentz transformation to its physical consequences. Key points:
- Two postulates — The principle of relativity (physical laws take the same form in all inertial frames) and the principle of the constancy of the speed of light (the speed of light \(c\) is the same for all observers). Everything below follows from just these two.
- Spacetime interval \(ds^2\) — From the constancy of the speed of light, \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\) is determined as a rank-0 tensor (scalar invariant) that is the same in all inertial frames. The minus sign on the time term is the decisive difference from Euclidean geometry.
- Lorentz transformation — The coordinate transformation that preserves \(ds^2\). It is the "speed-of-light-aware correction" of the Galilean transformation, reducing to the Galilean transformation in the limit \(v \ll c\). Geometrically it is a hyperbolic rotation in the \(t\)-\(x\) plane, sharing the same structure as spatial rotation (\(\cos \to \cosh\), \(\sin \to \sinh\)).
- Physical consequences — Relativity of simultaneity, time dilation \(\Delta t = \gamma \Delta t'\), length contraction \(L = L_0/\gamma\). All emerge inevitably once the constancy of the speed of light is accepted. Newton's "absolute time and absolute space" do not hold.
Preview of the Next Chapter¶
In Ch. 4, we rewrite the physical content obtained in this chapter in the language of mathematics needed to proceed toward general relativity. We will set up natural units (\(c = 1\)) and index notation, Einstein's summation convention, the Minkowski metric \(\eta_{\mu\nu}\), 4-vectors, covariant vectors, and the basics of tensors. The tools assembled there will directly serve us from Ch. 5 onward when we deal with "curved spacetime."
References¶
- Hartle, J. B. Gravity: An Introduction to Einstein's General Relativity, Chapters 4–5. Addison-Wesley, 2003.
- Schutz, B. F. A First Course in General Relativity, 3rd ed., Chapter 1. Cambridge University Press, 2022.
- Tong, D. General Relativity, Chapter 1. University of Cambridge lecture notes, 2019.
- Landau, L. D. and Lifshitz, E. M. The Classical Theory of Fields, 4th ed., §1–4. Butterworth-Heinemann, 1975.
- Sunakawa, S. Theoretical Electrodynamics, Chapter 12. Kinokuniya Shoten, 1999. (in Japanese)
- Satō, K. Relativity, Iwanami Fundamental Physics Series, Chapters 1–4. Iwanami Shoten, 1996. (in Japanese)
- Ishii, T. Understanding General Relativity Step by Step with Equations, Chapters 8–9. Beret Publishing, 2013. (in Japanese)
- Lancaster, T. and Blundell, S. J. General Relativity for the Gifted Amateur, Chapter 1. Oxford University Press, 2014.
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.