Apéndice A Análisis vectorial y fundamentos de ecuaciones diferenciales en derivadas parciales¶
Resumen de lo anterior:
En el texto principal, hemos introducido paso a paso las herramientas matemáticas necesarias para comprender la teoría de la relatividad general. Tensores, derivada covariante, tensor de curvatura y demás —todo el lenguaje para describir el espaciotiempo curvado— son generalizaciones del "análisis vectorial en espacios planos". En este apéndice, organizamos con demostraciones las fórmulas básicas del análisis vectorial en el espacio euclídeo tridimensional, que sirvieron como fundamento del texto principal.
Objetivo de este capítulo
- Resumir de forma autocontenida, desde definiciones hasta demostraciones, las derivadas parciales, el producto vectorial (producto cruz), los operadores diferenciales (grad, div, rot, laplaciano) y los teoremas integrales (teorema de Gauss, teorema de Stokes) que hemos usado como "conocidos" en el texto principal
- Concentrar en un solo lugar las herramientas matemáticas utilizadas a lo largo de todo el texto principal y las posteriores ediciones de mecánica cuántica, teoría cuántica de campos y teoría de cuerdas
🟡 Lina: Este apéndice reúne en un solo lugar las herramientas que hemos citado una y otra vez en el texto principal diciendo "en el caso tridimensional era así". Casi no aparecen conceptos nuevos, así que úsalo como un diccionario. También será referenciado desde las ediciones de mecánica cuántica, teoría cuántica de campos y teoría de cuerdas como base de derivadas parciales y grad/div/rot.
🔵 Kai: Sinceramente, durante el texto principal hubo momentos en que me decían "por la antisimetría del producto vectorial…" y me sentía un poco inseguro. Me alivia poder verificarlo aquí.
⚪ Mei: Yo quiero verificar los detalles de las demostraciones. Especialmente la relación entre el producto triple escalar y el determinante.
🟡 Lina: Entonces vamos en orden. Primero las derivadas parciales —como también se usan en la mecánica cuántica y la teoría cuántica de campos que siguen, conviene repasarlas.
A.0 Derivadas parciales — Tasa de cambio de funciones de varias variables¶
¿Por qué necesitamos derivadas parciales?¶
🟡 Lina: La derivada del bachillerato trata funciones de una variable \(f(x)\). Pero en física aparecen constantemente funciones que dependen de múltiples variables: el potencial gravitatorio \(\Phi(x, y, z)\), el campo eléctrico \(\mathbf{E}(x, y, z, t)\), el tensor métrico \(g_{\mu\nu}(x)\)...
🔵 Kai: Cuando quiero saber "cuánto cambia en la dirección \(x\)", ¿qué hago con las demás variables?
🟡 Lina: Las fijas. Eso es todo.
Definición de la derivada parcial¶
Recordemos la derivada de una función de una variable \(f(x)\):
Esto es la razón de "cuánto cambia \(f\) al variar \(x\) un poquito" — la pendiente de la función. Para una función de varias variables \(f(x, y, z)\), "derivamos solo respecto a \(x\) manteniendo \(y\), \(z\) fijos":
El símbolo simplemente cambia de \(d\) a \(\partial\) (se lee "d parcial" o "round d"), y lo que se hace es lo mismo que una derivada ordinaria. Solo hay que derivar respecto a una variable tratando las demás como constantes.
Ejemplos de cálculo¶
🟡 Lina: Hagámoslo concretamente. Para \(f(x, y) = x^2 y + 3xy^2\):
\(\partial f / \partial x\) (tratando \(y\) como constante):
Sumando: \(\partial f/\partial x = 2xy + 3y^2\).
\(\partial f / \partial y\) (tratando \(x\) como constante):
Sumando: \(\partial f/\partial y = x^2 + 6xy\).
🔵 Kai: Es el mismo cálculo que una derivada normal, solo que se tratan las otras letras como constantes.
Derivadas parciales de segundo orden y teorema de Schwarz¶
Derivar parcialmente una vez más:
Derivadas parciales mixtas (derivar dos veces respecto a variables diferentes):
Verificándolo con el ejemplo anterior: derivamos \(\partial f/\partial y = x^2 + 6xy\) respecto a \(x\) y obtenemos \(\partial^2 f/(\partial x \partial y) = 2x + 6y\). En orden inverso, derivamos \(\partial f/\partial x = 2xy + 3y^2\) respecto a \(y\) y también obtenemos \(2x + 6y\).
⚪ Mei: ¡El resultado es el mismo aunque intercambiemos el orden!
🟡 Lina: Para funciones normales (suficientemente suaves), el resultado no cambia al intercambiar el orden de derivación:
Esto se llama teorema de Schwarz (teorema de simetría). En el texto principal siempre asumimos que se cumple. Esta propiedad la usamos constantemente para demostrar \(\operatorname{rot}(\operatorname{grad}\varphi) = 0\) y la simetría de los símbolos de Christoffel.
🔵 Kai: Esto no se cumple para cualquier función, ¿verdad? ¿Cuál es concretamente la condición de "suficientemente suave"?
🟡 Lina: Se cumple si las derivadas parciales mixtas de segundo orden son continuas — las funciones que manejamos en física normalmente satisfacen esta condición, así que en la práctica puedes pensar que siempre se puede usar.
✅ Verificación de comprensión: ¿Qué es el teorema de Schwarz?
Respuesta
Para funciones suficientemente suaves, el resultado no cambia al intercambiar el orden de las derivadas parciales mixtas: \(\partial^2 f/(\partial x \partial y) = \partial^2 f/(\partial y \partial x)\).
Regla de la cadena multivariable (Chain Rule)¶
🟡 Lina: Vamos a extender a varias variables la regla de la cadena del bachillerato \(\frac{d}{dx}f(g(x)) = f'(g(x))\cdot g'(x)\).
Si \(f(x, y)\) con \(x\) e \(y\) funciones de un parámetro \(t\): \(x = x(t)\), \(y = y(t)\), entonces:
Derivación: Cuando \(t\) cambia en \(\Delta t\), \(x\) cambia en \(\Delta x = (dx/dt)\Delta t\) e \(y\) cambia en \(\Delta y = (dy/dt)\Delta t\). La variación de \(f\) se obtiene aplicando a cada variable la analogía unidimensional "\(\Delta f \approx f'(x)\Delta x\)" y sumando:
¿Por qué podemos sumar simplemente? Porque los términos como \(\Delta x \cdot \Delta y\) (producto de dos cantidades infinitesimales) tienden a cero más rápido que los términos individuales \(\Delta x\), \(\Delta y\) cuando \(\Delta t \to 0\), así que se pueden ignorar. Dividiendo por \(\Delta t\) y tomando el límite \(\Delta t \to 0\) se obtiene la fórmula de arriba.
🔵 Kai: Esto es lo que se usa cuando se sigue la variación temporal de la fase de una onda electromagnética \(\phi(x, t) = kx - \omega t\), ¿verdad?
🟡 Lina: Exacto. En la solución de d'Alembert de la ecuación de ondas y en la derivación de la ecuación de geodésicas del texto principal, la regla de la cadena juega un papel esencial.
Diferencial total¶
Si escribimos la regla de la cadena "antes de dividir por \(dt\)", obtenemos la diferencial total:
"La variación infinitesimal de \(f\) es la suma de los productos de la derivada parcial en cada dirección por el desplazamiento infinitesimal en esa dirección". Esta expresión conecta con la derivación del gradiente en A.4.
✅ Verificación de comprensión: Al calcular la derivada parcial \(\partial f/\partial x\), ¿cómo se tratan \(y\) y \(z\)?
Respuesta
Se tratan como constantes y se deriva solo respecto a \(x\).
A.1 Producto vectorial (producto cruz)¶
Definición¶
🟡 Lina: Queremos representar como un solo vector "el área y la orientación del paralelogramo que forman dos vectores" — esa es la motivación que define el producto vectorial (producto cruz). El producto vectorial \(\boldsymbol{a} \times \boldsymbol{b}\) de dos vectores tridimensionales \(\boldsymbol{a} = (a_1,\, a_2,\, a_3)\) y \(\boldsymbol{b} = (b_1,\, b_2,\, b_3)\) se define así:
🔵 Kai: El producto escalar da un escalar como resultado, pero el producto vectorial da un vector, ¿no?
🟡 Lina: Así es. Y esta operación se define solo en 3 dimensiones. Ni en 2 ni en 4 dimensiones funciona tal cual. Cuando en el texto principal avanzamos a dimensiones generales y usamos la antisimetrización de tensores en lugar del producto cruz, fue precisamente para superar esta limitación.
✅ Verificación de comprensión: ¿En cuántas dimensiones se puede definir el producto vectorial (producto cruz)? Además, ¿cómo se superó esta limitación en el texto principal?
Respuesta
El producto vectorial tal cual solo se define en 3 dimensiones. En el texto principal se generalizó usando la antisimetrización de tensores, que funciona en cualquier dimensión.
🟡 Lina: Como método para recordarlo, se puede usar un determinante formal. Primero explico qué es un determinante. Para una tabla de números (matriz) \(2 \times 2\): \(\begin{pmatrix} a & b \\ c & d \end{pmatrix}\), la operación que le asocia un único número \(ad - bc\) (diferencia de los productos de las diagonales) se llama determinante \(2 \times 2\), y se escribe \(\begin{vmatrix} a & b \\ c & d \end{vmatrix} = ad - bc\). Para el caso \(3 \times 3\), veamos primero el procedimiento con un ejemplo concreto y luego generalizamos. Usando la base estándar \(\boldsymbol{e}_1 = (1,0,0)\), \(\boldsymbol{e}_2 = (0,1,0)\), \(\boldsymbol{e}_3 = (0,0,1)\):
🔵 Kai: El determinante parece un poco complicado de desarrollar.
🟡 Lina: Hagámoslo concretamente. Se desarrolla por cada elemento de la primera fila, alternando signos \(+, -, +\) (este patrón de signos proviene de la definición del determinante — recuérdalo como un "tablero de ajedrez": arriba a la izquierda es \(+\) y el signo se invierte al pasar al siguiente). Primero el término de \(\boldsymbol{e}_1\): eliminando la fila 1 y la columna 1 que contienen a \(\boldsymbol{e}_1\), queda \(\begin{vmatrix} a_2 & a_3 \\ b_2 & b_3 \end{vmatrix} = a_2 b_3 - a_3 b_2\). Signo: \(+\). Luego el término de \(\boldsymbol{e}_2\): eliminando fila 1 y columna 2, queda \(\begin{vmatrix} a_1 & a_3 \\ b_1 & b_3 \end{vmatrix} = a_1 b_3 - a_3 b_1\). Signo: \(-\). Finalmente el término de \(\boldsymbol{e}_3\): eliminando fila 1 y columna 3, queda \(\begin{vmatrix} a_1 & a_2 \\ b_1 & b_2 \end{vmatrix} = a_1 b_2 - a_2 b_1\). Signo: \(+\). Juntando todo:
Esto coincide con la definición. Como en la primera fila hay vectores, no es un determinante en sentido estricto, pero como procedimiento de cálculo es muy conveniente.
⚪ Mei: Es decir, si memorizas "el procedimiento de desarrollo del determinante \(3 \times 3\)", puedes escribir las componentes del producto cruz sin equivocarte.
📝 Ejercicios:
- Cálculo de componentes del producto vectorial → Problema B-1. Cálculo por componentes del producto vectorial, verificación de ortogonalidad → Problema B-2. Ortogonalidad del producto vectorial
Leyes de operación¶
🟡 Lina: El producto vectorial cumple las siguientes leyes:
🔵 Kai: El producto escalar sí se puede conmutar: \(\boldsymbol{a} \cdot \boldsymbol{b} = \boldsymbol{b} \cdot \boldsymbol{a}\), pero el producto vectorial cambia de signo al intercambiar el orden.
🟡 Lina: Así es. Esta "antisimetría" es el prototipo de los tensores antisimétricos que aparecieron una y otra vez en el texto principal. Que cada componente de \(\operatorname{rot}\) (rotacional) tenga forma de "resta" se debe precisamente a esto.
⚪ Mei: La distributividad se cumple, pero la conmutatividad lleva un "anti". ¿Y la asociatividad?
🟡 Lina: En general \(\boldsymbol{a} \times (\boldsymbol{b} \times \boldsymbol{c}) \neq (\boldsymbol{a} \times \boldsymbol{b}) \times \boldsymbol{c}\). La asociatividad no se cumple. Este es el trasfondo de la fórmula BAC-CAB que veremos más adelante.
Propiedades geométricas¶
🟡 Lina: Resumo en 3 puntos el significado geométrico del producto vectorial:
(1) \(\boldsymbol{a} \times \boldsymbol{a} = \boldsymbol{0}\)
(2) \(\boldsymbol{a} \times \boldsymbol{b}\) es perpendicular tanto a \(\boldsymbol{a}\) como a \(\boldsymbol{b}\)
(3) \(|\boldsymbol{a} \times \boldsymbol{b}|\) es igual al área del paralelogramo formado por \(\boldsymbol{a}\) y \(\boldsymbol{b}\)
🔵 Kai: La (1) sale de la anticonmutatividad, ¿no? \(\boldsymbol{a} \times \boldsymbol{a} = -(\boldsymbol{a} \times \boldsymbol{a})\), entonces \(2(\boldsymbol{a} \times \boldsymbol{a}) = \boldsymbol{0}\).
🟡 Lina: Exacto. Para la (2), lo más seguro es verificarlo calculando el producto escalar:
Al desarrollar: \(a_1 a_2 b_3 - a_1 a_3 b_2 + a_2 a_3 b_1 - a_1 a_2 b_3 + a_1 a_3 b_2 - a_2 a_3 b_1 = 0\). Cada término se cancela con su par de signo opuesto.
⚪ Mei: Ya veo, \(a_1 a_2 b_3\) y \(-a_1 a_2 b_3\) siempre tienen una contraparte que los cancela.
🟡 Lina: \((\boldsymbol{a} \times \boldsymbol{b}) \cdot \boldsymbol{b} = 0\) se demuestra de forma similar. Es decir, \(\boldsymbol{a} \times \boldsymbol{b}\) apunta en la dirección perpendicular al plano determinado por \(\boldsymbol{a}\) y \(\boldsymbol{b}\). La orientación se determina por la "regla de la mano derecha".
🟡 Lina: La demostración de (3) requiere un poco más de cálculo, pero se obtiene una identidad importante. Si \(\theta\) es el ángulo entre \(\boldsymbol{a}\) y \(\boldsymbol{b}\), el área del paralelogramo es:
Por tanto:
🔵 Kai: Aquí sustituiste \(|\boldsymbol{a}||\boldsymbol{b}|\cos\theta\) por el producto escalar \(\boldsymbol{a} \cdot \boldsymbol{b}\).
🟡 Lina: Por otro lado, calculando \(|\boldsymbol{a} \times \boldsymbol{b}|^2\) en componentes:
Desarrollando esto y verificando que coincide con \((a_1^2 + a_2^2 + a_3^2)(b_1^2 + b_2^2 + b_3^2) - (a_1 b_1 + a_2 b_2 + a_3 b_3)^2\), queda demostrado. La identidad así obtenida:
se llama identidad de Lagrange.
🔵 Kai: Entonces si sumas el cuadrado del producto escalar y el cuadrado del producto vectorial, obtienes el cuadrado del producto de las magnitudes. Es el reflejo de \(\cos^2\theta + \sin^2\theta = 1\).
🟡 Lina: Exactamente. Hermoso, ¿verdad?
✅ Verificación de comprensión: Describe el significado geométrico del producto vectorial \(\boldsymbol{a} \times \boldsymbol{b}\).
Respuesta
Es un vector perpendicular al paralelogramo formado por \(\boldsymbol{a}\) y \(\boldsymbol{b}\), cuya magnitud es el área de dicho paralelogramo \(|\boldsymbol{a}||\boldsymbol{b}|\sin\theta\). Su orientación se determina por la regla de la mano derecha.
A.2 Producto triple escalar¶
🟡 Lina: Existe una cantidad formada a partir de 3 vectores \(\boldsymbol{a}\), \(\boldsymbol{b}\), \(\boldsymbol{c}\) con la siguiente propiedad:
Esta cantidad se llama producto triple escalar (scalar triple product).
🔵 Kai: ¿El valor no cambia al permutar cíclicamente (\(\boldsymbol{a} \to \boldsymbol{b} \to \boldsymbol{c} \to \boldsymbol{a}\)) los tres vectores?
🟡 Lina: Así es. La demostración se hace escribiendo directamente las componentes:
⚪ Mei: Al desarrollar aparecen 6 términos: \(a_1 b_2 c_3 - a_1 b_3 c_2 + a_2 b_3 c_1 - a_2 b_1 c_3 + a_3 b_1 c_2 - a_3 b_2 c_1\). Cada término tiene los subíndices \(1, 2, 3\) repartidos uno a cada uno entre \(a\), \(b\), \(c\).
🔵 Kai: ¿Si hago la permutación cíclica realmente queda lo mismo?
🟡 Lina: Inténtalo. Si sustituyes \(a \to b,\, b \to c,\, c \to a\) obtienes \(b_1 c_2 a_3 - b_1 c_3 a_2 + \cdots\) — al reordenar resulta el mismo conjunto de 6 términos. Con determinantes la visión es aún más clara:
Los determinantes tienen la propiedad de que "intercambiar dos filas invierte el signo" (esto se puede verificar en el caso \(2 \times 2\): \(\begin{vmatrix} c & d \\ a & b \end{vmatrix} = cb - da = -(ad - bc) = -\begin{vmatrix} a & b \\ c & d \end{vmatrix}\). Para \(3 \times 3\) también se puede verificar por desarrollo en cofactores, pero aquí aceptaremos el resultado y lo usaremos). La permutación cíclica \((1 \to 2 \to 3 \to 1)\) se realiza con 2 intercambios de filas (por ejemplo 1↔2 y luego 2↔3), así que el signo es \((-1)^2 = +1\) — es decir, el valor no cambia. Esta es la esencia de la simetría cíclica del producto triple escalar.
🔵 Kai: ¿Qué significado geométrico tiene?
🟡 Lina: Es el volumen con signo del paralelepípedo formado por \(\boldsymbol{a}\), \(\boldsymbol{b}\), \(\boldsymbol{c}\). \(\boldsymbol{b} \times \boldsymbol{c}\) es un vector perpendicular a la base (el paralelogramo de \(\boldsymbol{b}\) y \(\boldsymbol{c}\)), con magnitud igual al área de la base. Al tomar el producto escalar con \(\boldsymbol{a}\), obtenemos área de la base \(\times\) altura \(=\) volumen. Si miras Fig. A.1「Producto triple escalar y volumen del paralelepípedo」, esta estructura se ve claramente.
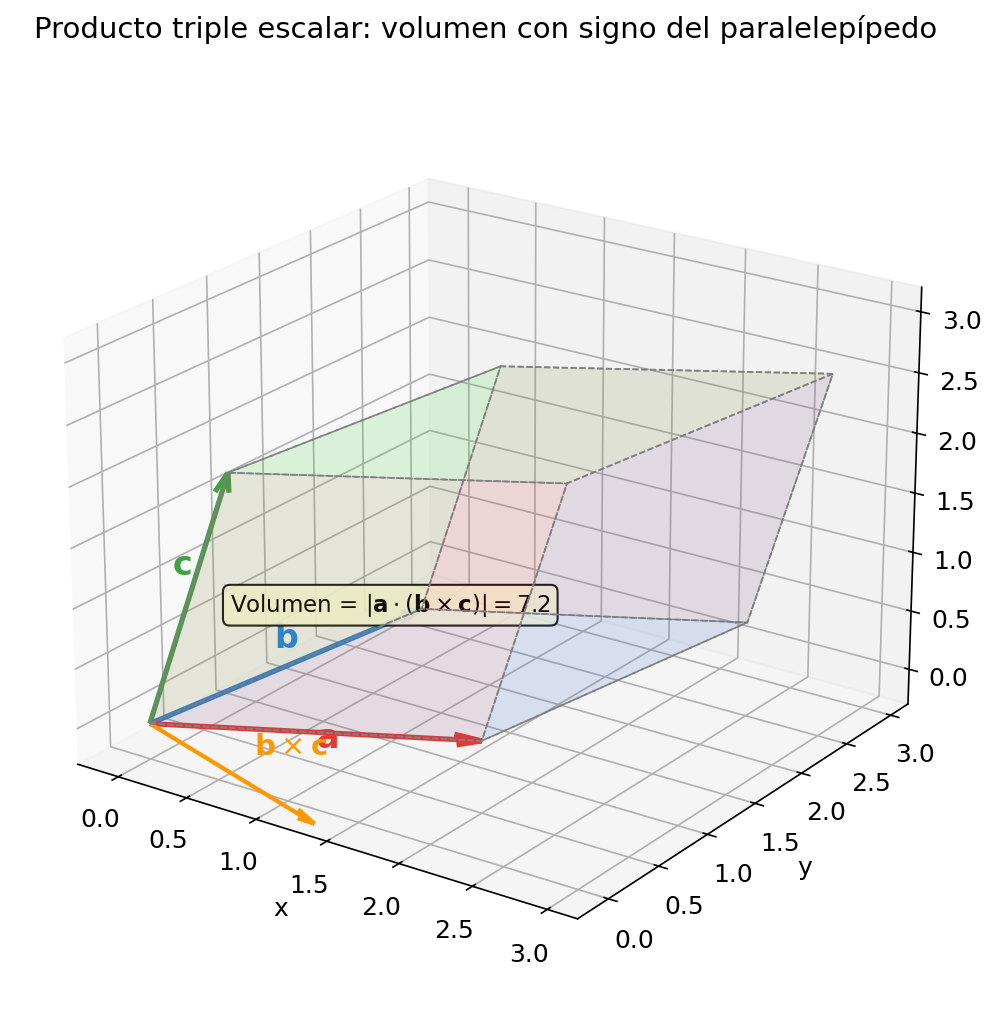
Fig. A.1: Producto triple escalar y volumen del paralelepípedo. El producto triple escalar \(\boldsymbol{a} \cdot (\boldsymbol{b} \times \boldsymbol{c})\) es igual al volumen con signo del paralelepípedo formado por los tres vectores. \(\boldsymbol{b} \times \boldsymbol{c}\) (naranja) es perpendicular a la base y tiene magnitud igual al área de la base. Su producto escalar con \(\boldsymbol{a}\) da el volumen.
⚪ Mei: Si el signo es positivo, \(\boldsymbol{a}\), \(\boldsymbol{b}\), \(\boldsymbol{c}\) forman un sistema de mano derecha; si es negativo, de mano izquierda.
✅ Verificación de comprensión: ¿Cuál es el significado geométrico del producto triple escalar \(\boldsymbol{a} \cdot (\boldsymbol{b} \times \boldsymbol{c})\)? Además, ¿qué propiedad tiene bajo permutaciones cíclicas?
Respuesta
Representa el volumen con signo del paralelepípedo formado por los tres vectores. Bajo permutaciones cíclicas \(\boldsymbol{a} \to \boldsymbol{b} \to \boldsymbol{c} \to \boldsymbol{a}\) el valor no cambia (simetría cíclica).
📝 Ejercicios:
- Cálculo del producto triple escalar con determinante → Problema B-3. Producto triple escalar
A.3 Producto escalar de dos productos vectoriales (preparación para la fórmula BAC-CAB)¶
🟡 Lina: Cuando discutimos el significado geométrico del tensor de curvatura en el texto principal, usamos la siguiente fórmula. Para cuatro vectores \(\boldsymbol{a}\), \(\boldsymbol{b}\), \(\boldsymbol{c}\), \(\boldsymbol{d}\):
🔵 Kai: La forma del lado derecho parece un determinante.
🟡 Lina: Se puede escribir como un determinante \(2 \times 2\):
⚪ Mei: La diferencia de productos de diagonales: \((\boldsymbol{a} \cdot \boldsymbol{c})(\boldsymbol{b} \cdot \boldsymbol{d}) - (\boldsymbol{a} \cdot \boldsymbol{d})(\boldsymbol{b} \cdot \boldsymbol{c})\).
🟡 Lina: La demostración es más clara usando el producto triple escalar. Si consideramos \(\boldsymbol{c} \times \boldsymbol{d}\) como un vector \(\boldsymbol{e}\), por la simetría cíclica del producto triple escalar de A.2:
Es decir, \((\boldsymbol{a} \times \boldsymbol{b}) \cdot (\boldsymbol{c} \times \boldsymbol{d}) = \boldsymbol{a} \cdot [\boldsymbol{b} \times (\boldsymbol{c} \times \boldsymbol{d})]\).
Aquí usamos la fórmula BAC-CAB (fórmula del triple producto vectorial). Esta fórmula se puede demostrar directamente con cálculo de componentes (la demostración está en el ejercicio Problema M-1. Demostración de la fórmula BAC-CAB):
Usando esto:
🔵 Kai: BAC-CAB tiene su propio nombre. Pero la fórmula de ahora es \(\boldsymbol{b} \times (\boldsymbol{c} \times \boldsymbol{d})\), las letras son distintas...
🟡 Lina: Históricamente se memoriza en la forma \(\boldsymbol{a} \times (\boldsymbol{b} \times \boldsymbol{c}) = \boldsymbol{b}(\boldsymbol{a} \cdot \boldsymbol{c}) - \boldsymbol{c}(\boldsymbol{a} \cdot \boldsymbol{b})\), y leyendo las iniciales del lado derecho: B-A-C menos C-A-B. Solo es un cambio de letras, la estructura es la misma.
🔵 Kai: Ya veo, el vector exterior "entra al medio" y forma productos escalares. Pero, ¿por qué el resultado es una combinación lineal de \(\boldsymbol{b}\) y \(\boldsymbol{c}\)? ¿No aparece ninguna componente en la dirección de \(\boldsymbol{a}\)?
🟡 Lina: Buena pregunta. \(\boldsymbol{b} \times \boldsymbol{c}\) es un vector perpendicular al plano que forman \(\boldsymbol{b}\) y \(\boldsymbol{c}\), ¿verdad? Al tomar el producto vectorial de eso con \(\boldsymbol{a}\), el resultado es perpendicular a \(\boldsymbol{b} \times \boldsymbol{c}\) — es decir, vuelve al plano formado por \(\boldsymbol{b}\) y \(\boldsymbol{c}\). Un vector en el plano se puede escribir como combinación lineal de \(\boldsymbol{b}\) y \(\boldsymbol{c}\) que generan ese plano. Por eso no aparece componente en la dirección de \(\boldsymbol{a}\).
⚪ Mei: Lo que geométricamente es obvio se refleja correctamente en la forma de la fórmula.
✅ Verificación de comprensión: En la fórmula BAC-CAB \(\boldsymbol{a} \times (\boldsymbol{b} \times \boldsymbol{c}) = \boldsymbol{b}(\boldsymbol{a} \cdot \boldsymbol{c}) - \boldsymbol{c}(\boldsymbol{a} \cdot \boldsymbol{b})\), ¿en qué forma se expresa el resultado del triple producto vectorial?
Respuesta
Se expresa como combinación lineal de los dos vectores \(\boldsymbol{b}\), \(\boldsymbol{c}\) que están dentro del producto cruz. Los coeficientes se determinan por los productos escalares con el vector exterior \(\boldsymbol{a}\).
📝 Ejercicios:
- Verificación numérica de la identidad de Lagrange → Problema B-8. Verificación de la identidad de Lagrange, verificación numérica de la fórmula BAC-CAB → Problema B-9. Verificación de la fórmula BAC-CAB, demostración general de la fórmula BAC-CAB → Problema M-1. Demostración de la fórmula BAC-CAB, producto escalar de dos productos vectoriales → Problema M-3. Fórmula del producto escalar entre productos vectoriales, derivación unificada con el símbolo de Levi-Civita → Problema A-1. Identidades con el símbolo de Levi-Civita
A.4 Operadores diferenciales¶
🟡 Lina: A partir de aquí definimos las operaciones de derivación sobre campos vectoriales y escalares. Esto es la "versión en espacio plano" de la derivada covariante que generalizamos al espaciotiempo curvado en el texto principal.
Operador nabla¶
🟡 Lina: Primero introduzco el operador nabla \(\nabla\), que es la base de todos los operadores diferenciales. En coordenadas cartesianas tridimensionales \((x, y, z)\):
Piensa en él como "un operador diferencial que se comporta como un vector".
🔵 Kai: ¿Es un vector pero su contenido son derivadas parciales...?
🟡 Lina: Sí, por eso es un "operador". Solo no tiene significado; adquiere significado cuando actúa sobre algo. Si actúa sobre un campo escalar da el grad, si se hace el producto escalar con un campo vectorial da la div, y si se hace el producto cruz con un campo vectorial da el rot.
Gradiente (gradient)¶
🟡 Lina: Si hacemos actuar \(\nabla\) sobre un campo escalar \(\varphi(x, y, z)\):
⚪ Mei: El resultado es un campo vectorial. Entra un escalar y sale un vector.
🟡 Lina: Así es. Y físicamente, \(\nabla\varphi\) apunta en "la dirección en que \(\varphi\) crece más rápidamente", y su magnitud da "el valor máximo de la tasa de cambio". Cada componente \(\partial\varphi/\partial x\), etc., representa la tasa de cambio en esa dirección. Recuerdas que en el texto principal derivamos el campo gravitatorio \(\boldsymbol{g} = -\nabla\varphi\) a partir del potencial gravitatorio \(\varphi\).
Divergencia (divergence)¶
🟡 Lina: Para un campo vectorial \(\boldsymbol{F} = (F_x,\, F_y,\, F_z)\), tomamos el "producto escalar" con \(\nabla\):
🔵 Kai: El resultado es un escalar.
🟡 Lina: Así es. Físicamente representa "cuánto campo vectorial emana desde ese punto". Si \(\operatorname{div}\boldsymbol{F} > 0\) hay una fuente (source), si \(< 0\) hay un sumidero (sink). La ecuación de Maxwell \(\operatorname{div}\boldsymbol{E} = \rho/\varepsilon_0\) del texto principal significaba que "el campo eléctrico emana desde donde hay densidad de carga \(\rho\)".
Derivación a partir de un volumen infinitesimal¶
🟡 Lina: Veamos por qué esta suma de derivadas parciales representa "emanación", derivándolo desde la imagen física.
Consideramos un paralelepípedo infinitesimal centrado en \((x_0, y_0, z_0)\) (lados \(\Delta x\), \(\Delta y\), \(\Delta z\)) — la imagen es investigar cuánto de \(\boldsymbol{F}\) sale o entra por cada cara, separando en 3 pares: cara derecha e izquierda, cara superior e inferior, cara frontal y trasera. Calculamos cuánto flujo neto sale del campo vectorial \(\boldsymbol{F}\) de esta caja. En Fig. A.2「Derivación de la divergencia mediante volumen infinitesimal」 he dibujado como ejemplo en la dirección \(x\) el flujo de entrada y salida de \(F_x\) a través de las caras derecha e izquierda; léelo mirando la figura (en las direcciones \(y\), \(z\) es lo mismo).
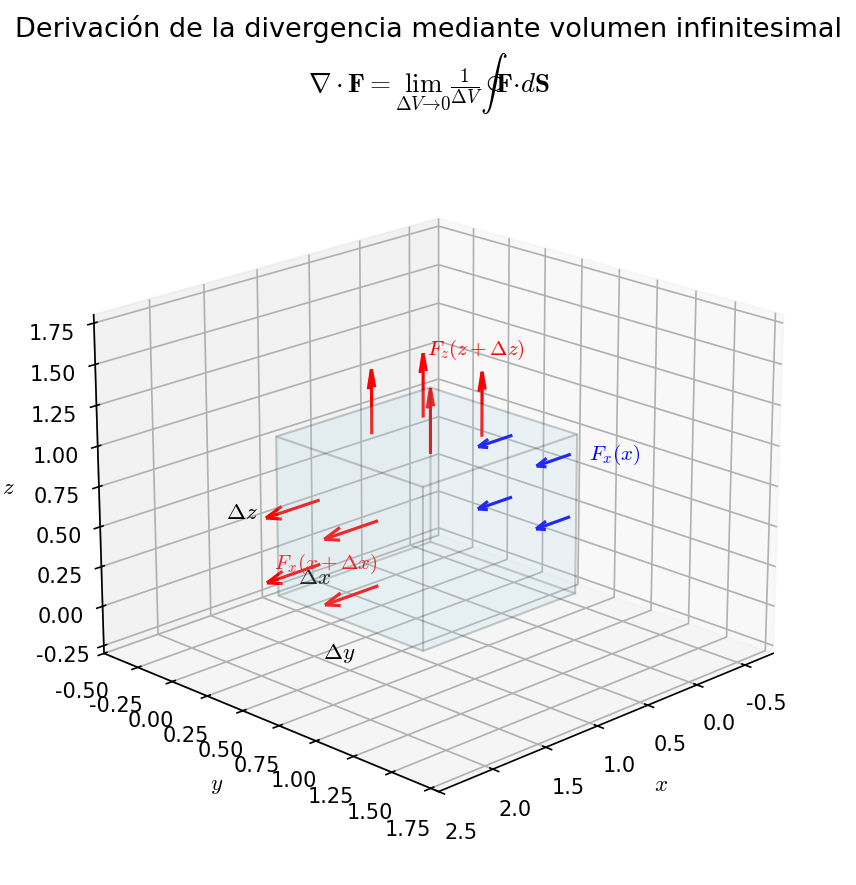
Fig. A.2: Derivación de la divergencia mediante volumen infinitesimal. Flujo de entrada y salida del campo vectorial a través de cada cara de un paralelepípedo infinitesimal centrado en \((x_0, y_0, z_0)\). La diferencia de \(F_x\) entre las caras derecha e izquierda da el flujo neto de salida en la dirección \(x\).
Flujo neto de salida en la dirección \(x\): La cantidad que sale por la cara derecha (\(x_0 + \Delta x/2\)) menos la que entra por la cara izquierda (\(x_0 - \Delta x/2\)):
🔵 Kai: Se resta lo que entra por la cara izquierda de lo que sale por la cara derecha.
🟡 Lina: Exacto. Aproximamos \(F_x\) linealmente alrededor de \(x_0\). De la definición de derivada parcial \(\partial F_x/\partial x = \lim_{h\to 0}[F_x(x_0+h) - F_x(x_0)]/h\), reordenando, cuando \(h\) es suficientemente pequeño se obtiene la aproximación \(F_x(x_0 + h) \approx F_x(x_0) + (\partial F_x/\partial x)\cdot h\) (este método de "aproximar una función usando su derivada" se llama en general desarrollo de Taylor — en A.7, en la derivación de la fórmula de Euler, explicaré en detalle la idea general del desarrollo de Taylor). Usando esto: \(F_x(x_0 \pm \Delta x/2) \approx F_x(x_0) \pm (\partial F_x/\partial x)(\Delta x/2)\). Restando queda \((\partial F_x/\partial x)\Delta x\). Por tanto, el flujo neto de salida en la dirección \(x\) es \((\partial F_x/\partial x)\,\Delta V\) (\(\Delta V = \Delta x \Delta y \Delta z\)).
Las direcciones \(y\) y \(z\) son análogas. El flujo neto de salida por unidad de volumen sumando las 3 direcciones es la divergencia:
Aquí, "el flujo neto de salida a través de la superficie cerrada" se escribe matemáticamente como \(\oint_S \boldsymbol{F} \cdot d\boldsymbol{S}\). Como probablemente es la primera vez que ves este símbolo, lo explico.
🔵 Kai: ¿\(\oint\) en qué se diferencia del símbolo de integral normal \(\int\)?
🟡 Lina: \(\oint\) es un símbolo de integral que indica que se suma sobre toda una superficie (o curva) cerrada (es un \(\int\) normal con un círculo encima). Y \(d\boldsymbol{S}\) es el vector de área de cada elemento infinitesimal de superficie — un vector que apunta en la dirección perpendicular a la superficie y cuya magnitud es igual al área de ese elemento infinitesimal. La "dirección perpendicular a la superficie" se llama dirección normal — así como en el bachillerato la "tangente" era la dirección a lo largo de la curva, la "normal" es la dirección que sale de la superficie. Se toma con orientación "hacia afuera" — es decir, desde el interior hacia el exterior de la superficie cerrada (como la de un globo). Con esta convención, el producto escalar \(\boldsymbol{F} \cdot d\boldsymbol{S}\) positivo indica salida y negativo indica entrada.
🔵 Kai: ¿La integral de superficie es como "sumar tiras" en la integral del bachillerato, pero hecho sobre una superficie?
🟡 Lina: Exacto, esa es precisamente la imagen. La integral definida del bachillerato es "sumar las tiras bajo la curva" — sumar a lo largo de 1 dimensión. La integral de superficie es "dividir la superficie en pequeñas baldosas, calcular para cada baldosa 'la componente normal de \(\boldsymbol{F}\) \(\times\) el área de la baldosa', y sumar todas las baldosas" — sumar sobre una superficie bidimensional.
🔵 Kai: "Componente normal" es la componente en la dirección perpendicular a la superficie. Pero, ¿cómo se extrae?
🟡 Lina: Usando el producto escalar. Como \(d\boldsymbol{S}\) es un vector de área que apunta perpendicular a la superficie, al tomar el producto escalar \(\boldsymbol{F} \cdot d\boldsymbol{S} = |\boldsymbol{F}||d\boldsymbol{S}|\cos\alpha\) (\(\alpha\) es el ángulo entre \(\boldsymbol{F}\) y \(d\boldsymbol{S}\)), automáticamente se extrae \(|\boldsymbol{F}|\cos\alpha\) = componente en la dirección normal. Esto es la integral de superficie. Y la relación entre esta "suma local de derivadas parciales" y el "flujo de salida a través de la superficie cerrada", extendida a un volumen finito, es el teorema de Gauss de A.6.
⚪ Mei: Es decir, "el límite del flujo de salida a través de la superficie cerrada dividido por el volumen" que Lina mostró al principio es la definición con significado, y la "suma de derivadas parciales" derivada de ahí es la fórmula que usamos para calcular en la práctica.
✅ Verificación de comprensión: ¿Cómo se define físicamente la divergencia \(\nabla \cdot \boldsymbol{F}\) usando un volumen infinitesimal?
Respuesta
Se define como el límite del flujo neto de salida del campo vectorial a través de una superficie cerrada infinitesimal que rodea el punto, dividido por ese volumen infinitesimal. Si es positivo significa fuente, si es negativo significa sumidero.
Rotacional (rotation / curl)¶
🟡 Lina: Para un campo vectorial \(\boldsymbol{F}\), tomamos el "producto cruz" con \(\nabla\):
En componentes:
🔵 Kai: Cada componente es una "resta". Eso viene de la antisimetría del producto vectorial.
🟡 Lina: Exacto. Físicamente representa "cuánto gira (forma remolinos) el campo vectorial alrededor de ese punto". \(\operatorname{rot}\boldsymbol{B} = \mu_0 \boldsymbol{j}\) significa "el campo magnético forma remolinos alrededor de donde fluye corriente eléctrica".
Derivación a partir de un lazo infinitesimal¶
🟡 Lina: Del mismo modo que derivamos la divergencia como "flujo de salida desde un volumen infinitesimal", el rotacional se puede derivar como "circulación a lo largo de un lazo infinitesimal".
Consideremos un lazo rectangular infinitesimal en el plano \(xy\) (centro \((x_0, y_0, z_0)\), lados \(\Delta x\), \(\Delta y\)) recorrido en sentido antihorario. Calculamos para cada lado "la componente de \(\boldsymbol{F}\) en la dirección del lado \(\times\) la longitud del lado", y la suma al dar una vuelta completa se llama circulación — se llama así porque "circulamos" por el lazo. El punto clave es que la diferencia de contribuciones entre lados opuestos (superior e inferior, derecho e izquierdo) da la componente del rotacional. En Fig. A.3「Derivación del rotacional mediante lazo infinitesimal」 he dibujado la relación entre cada lado del lazo infinitesimal y las componentes de \(\boldsymbol{F}\); léelo mirando la figura.
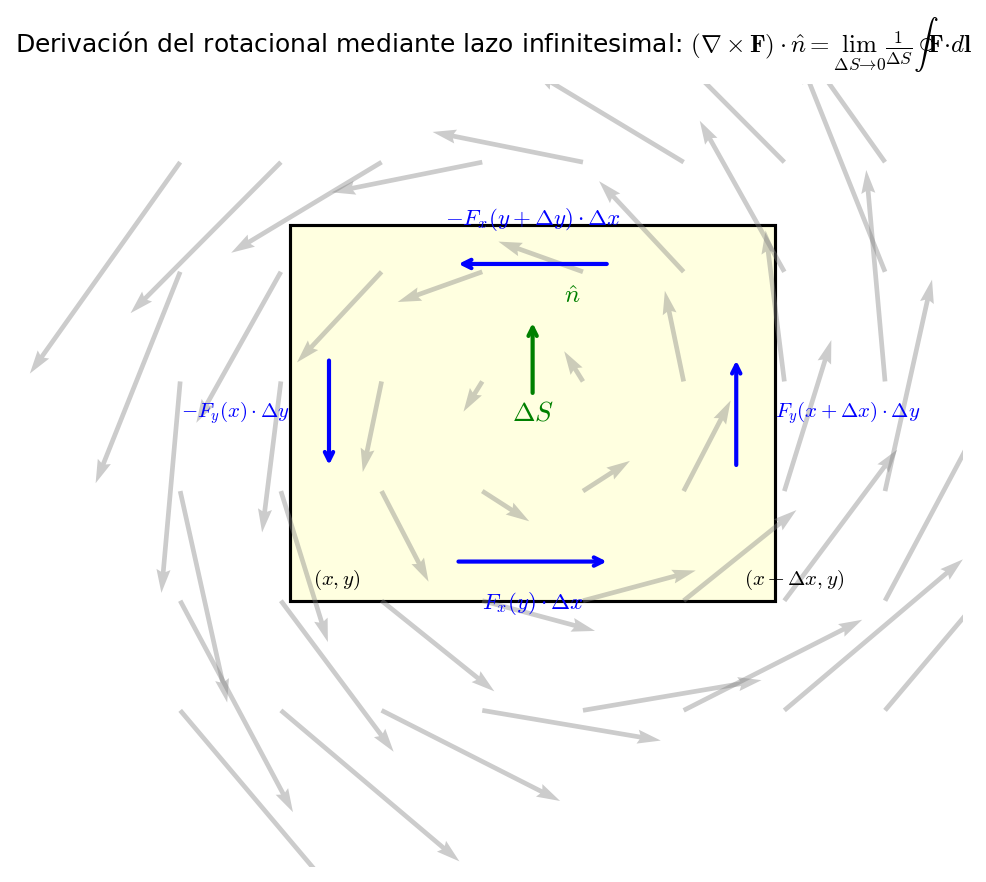
Fig. A.3: Derivación del rotacional mediante lazo infinitesimal. Se recorre en sentido antihorario un lazo rectangular infinitesimal en el plano \(xy\). La suma de las componentes de \(\boldsymbol{F}\) en la dirección de avance a lo largo de cada lado (circulación) da, como diferencia entre lados opuestos, la componente del rotacional.
Formalmente se escribe como la integral de línea \(\oint \boldsymbol{F} \cdot d\boldsymbol{r}\). La integral de línea es la operación de "dividir la curva en pequeños tramos, calcular para cada tramo la componente de \(\boldsymbol{F}\) en la dirección de avance \(\times\) la longitud del tramo, y sumar todos los tramos" — con la misma idea que la integral definida del bachillerato que "suma tiras a lo largo del eje \(x\)", pero sumando a lo largo de una curva arbitraria. \(d\boldsymbol{r}\) es el vector de desplazamiento infinitesimal a lo largo de la curva, y el producto escalar \(\boldsymbol{F} \cdot d\boldsymbol{r}\) significa "componente de \(\boldsymbol{F}\) en la dirección de avance \(\times\) distancia infinitesimal". Pero aquí, como se trata de un lazo infinitesimal, basta con calcular lado por lado. Concretamente:
- Lado inferior (\(y = y_0 - \Delta y/2\), en sentido antihorario se avanza en dirección \(+x\)): \(+F_x(x_0, y_0 - \Delta y/2)\,\Delta x\)
- Lado superior (\(y = y_0 + \Delta y/2\), en sentido antihorario se avanza en dirección \(-x\)): \(-F_x(x_0, y_0 + \Delta y/2)\,\Delta x\)
- Lado derecho (\(x = x_0 + \Delta x/2\), en sentido antihorario se avanza en dirección \(+y\)): \(+F_y(x_0 + \Delta x/2, y_0)\,\Delta y\)
- Lado izquierdo (\(x = x_0 - \Delta x/2\), en sentido antihorario se avanza en dirección \(-y\)): \(-F_y(x_0 - \Delta x/2, y_0)\,\Delta y\)
Criterio de signos: si la dirección de avance coincide con la dirección positiva del eje coordenado, \(+\); si es opuesta, \(-\). Al recorrer en sentido antihorario: el lado inferior va hacia la derecha (\(+x\)), el lado derecho va hacia arriba (\(+y\)), el lado superior va hacia la izquierda (\(-x\)) y el lado izquierdo va hacia abajo (\(-y\)) (verifica la dirección de las flechas en Fig. A.3「Derivación del rotacional mediante lazo infinitesimal」).
⚪ Mei: Para la divergencia mirábamos "el flujo de entrada y salida a través de las caras", pero para el rotacional miramos "la componente a lo largo de los lados".
🟡 Lina: Exacto. Entonces sumemos las contribuciones de los lados derecho e izquierdo (lados paralelos a la dirección \(y\)). Usando la aproximación lineal (el mismo desarrollo de Taylor que en la derivación de la divergencia), la diferencia entre el lado derecho y el izquierdo es \([F_y(x_0 + \Delta x/2) - F_y(x_0 - \Delta x/2)]\,\Delta y \approx (\partial F_y/\partial x)\Delta x\,\Delta y\). Análogamente, sumando las contribuciones de los lados superior e inferior (lados paralelos a la dirección \(x\)), la diferencia del lado inferior menos el superior es \(-[F_x(x_0, y_0 + \Delta y/2) - F_x(x_0, y_0 - \Delta y/2)]\,\Delta x \approx -(\partial F_x/\partial y)\Delta y\,\Delta x\). En total:
La circulación por unidad de área es la componente \(z\) del rotacional:
⚪ Mei: Haciendo lo mismo con lazos en los planos \(yz\) y \(zx\), se obtienen las componentes \(x\) e \(y\).
🟡 Lina: Así es. Y la relación entre esta "circulación del lazo infinitesimal" y la "integral de superficie del rotacional", extendida a una superficie finita, es el teorema de Stokes de A.6.
🔵 Kai: La divergencia es "flujo neto de salida desde un volumen infinitesimal", el rotacional es "circulación a lo largo de un lazo infinitesimal" — geométricamente queda muy claro. Pero la divergencia se divide por el volumen y el rotacional por el área — las dimensiones son distintas, y sin embargo ambos son "de la familia de \(\nabla\)".
🟡 Lina: Buena observación. Un solo operador \(\nabla\) genera cantidades físicas completamente distintas según actúe sobre un campo escalar (grad), tome el producto escalar con un campo vectorial (div) o tome el producto cruz (rot). Los tipos de entrada y salida son todos diferentes — grad es "escalar → vector", div es "vector → escalar", rot es "vector → vector". De hecho, usando las formas diferenciales y la derivada exterior \(d\) introducidas en Cap. 24, grad, div y rot se unifican en una sola operación: "aplicar \(d\)". Pero por ahora es suficiente con saber usar las 3 caras de \(\nabla\).
⚪ Mei: Ya veo, como los tipos de entrada y salida son todos distintos, si los combinas incorrectamente directamente no tiene sentido.
🔵 Kai: Entonces el laplaciano \(\nabla^2\) es "tomar el grad y luego la div", así que usa la cara de \(\nabla\) dos veces. ¿Hay otras combinaciones — por ejemplo "tomar la div y luego el grad" o "tomar el rot y luego el rot"?
🟡 Lina: Buena pregunta. "Tomar la div y luego el grad" es \(\nabla(\nabla \cdot \boldsymbol{F})\), y aparece en la fórmula "rot del rot" de la siguiente sección A.5. "Tomar el rot y luego el rot" es precisamente lo que trataremos en A.5. Vayamos por orden.
✅ Verificación de comprensión: ¿Cómo se define físicamente la componente \(z\) del rotacional \(\nabla \times \boldsymbol{F}\) usando un lazo infinitesimal?
Respuesta
Se define como el límite de la circulación del campo vectorial (integral de línea) a lo largo de un lazo infinitesimal en el plano \(xy\), dividida por el área infinitesimal que encierra el lazo. Esto representa "cuánto gira el campo vectorial alrededor de ese punto".
Laplaciano (Laplacian)¶
🟡 Lina: La operación de aplicar \(\nabla\) dos veces también es importante. Para un campo escalar \(\varphi\):
En algunos libros se escribe \(\Delta\) en lugar de \(\nabla^2\), pero en este libro usamos \(\nabla^2\) para el laplaciano y así evitar confusión con la variación infinitesimal \(\Delta x\).
⚪ Mei: Es una operación en dos pasos: tomar el grad y luego la div.
🟡 Lina: La ecuación del campo gravitatorio de Newton \(\nabla^2\varphi = 4\pi G\rho\) significa "la densidad de masa \(\rho\) determina la curvatura del potencial \(\varphi\)". Cuando explicamos en el texto principal que la ecuación de Einstein es una generalización de la ecuación de Newton, esta correspondencia fue la clave.
✅ Verificación de comprensión: ¿Qué se obtiene al aplicar el operador nabla \(\nabla\) a un campo escalar? ¿Y al tomar el producto escalar con un campo vectorial?
Respuesta
Al actuar sobre un campo escalar se obtiene el gradiente (gradient) — un campo vectorial que indica la dirección de máximo ascenso y la tasa de cambio. Al tomar el producto escalar con un campo vectorial se obtiene la divergencia (divergence) — un campo escalar que indica la intensidad de la fuente.
📝 Ejercicios:
- Cálculo del gradiente → Problema B-4. Gradiente de un campo escalar, cálculo de la divergencia → Problema B-5. Divergencia de un campo vectorial, cálculo del rotacional → Problema B-6. Rotacional de un campo vectorial, cálculo del laplaciano → Problema B-7. Laplaciano de un campo escalar
A.5 Identidades importantes de los operadores diferenciales¶
🟡 Lina: Las siguientes 2 identidades se usaron repetidamente en el texto principal.
Identidad 1: El rotacional del gradiente es cero¶
🔵 Kai: Intuitivamente tiene sentido... el gradiente es "la dirección cuesta arriba". Si avanzas en la dirección cuesta arriba, no puedes dar una vuelta completa y volver al punto de partida — ¿por eso no hay remolino?
🟡 Lina: Exacto. También se puede verificar físicamente. En componentes, por ejemplo la componente \(x\) es \(\frac{\partial^2\varphi}{\partial y\partial z} - \frac{\partial^2\varphi}{\partial z\partial y}\). Si \(\varphi\) es suficientemente suave, se puede intercambiar el orden de derivación parcial, así que esto es \(0\). Es decir, en campos de fuerza conservativos \(\boldsymbol{F} = -\nabla\varphi\), "campos derivados de un potencial", no hay remolinos.
⚪ Mei: Ya veo, por el teorema de Schwarz de A.0 las derivadas parciales mixtas se cancelan, y cada componente se anula.
🔵 Kai: ¿Y al revés, si \(\operatorname{rot}\boldsymbol{F} = \boldsymbol{0}\), necesariamente existe un potencial?
🟡 Lina: Buena pregunta. En regiones sin agujeros — por ejemplo el interior de una bola, donde cualquier goma elástica se puede encoger a un punto sin importar dónde la pongas — sí se puede afirmar (en matemáticas este tipo de región se llama "simplemente conexa"). En cambio, en la superficie de un donut, donde hay un agujero, una goma que rodee el agujero no se puede encoger a un punto sin cortarla — en ese caso se pueden construir contraejemplos donde \(\operatorname{rot}\boldsymbol{F} = \boldsymbol{0}\) pero la circulación a lo largo de ese lazo no es cero. Por ahora basta con tener esta intuición. Después de aprender el teorema de Stokes en A.6, piensa en cómo se deduce que "si \(\operatorname{rot}\boldsymbol{F} = \boldsymbol{0}\) entonces la circulación es cero para cualquier curva cerrada".
🔵 Kai: Ya veo, si no hay agujeros entonces funciona. Cuando aprenda el teorema de Stokes en A.6 seguro que se aclara más.
Identidad 2: La divergencia del rotacional es cero¶
🟡 Lina: Esto también se deduce exactamente con el mismo argumento — el teorema de Schwarz — que la identidad 1. Al desarrollar \(\nabla \cdot (\nabla \times \boldsymbol{F})\), por ejemplo \(\partial_x(\partial_y F_z - \partial_z F_y) + \cdots\), cada término toma la forma de una diferencia de derivadas parciales mixtas y se cancelan todos. La verificación detallada la dejo como ejercicio. Físicamente, \(\operatorname{div}\boldsymbol{B} = 0\) (no existen monopolos magnéticos) es también una consecuencia de que \(\boldsymbol{B} = \operatorname{rot}\boldsymbol{A}\).
🔵 Kai: La identidad 1 dice "si hay potencial, no hay remolino", y la identidad 2 dice "un campo nacido de remolinos no tiene fuentes" — están emparejadas.
Identidad 3: El rotacional del rotacional¶
🟡 Lina: Esta identidad es decisiva para derivar la ecuación de ondas electromagnéticas a partir de las ecuaciones de Maxwell. Verifiquémosla para la componente \(x\).
Definiendo \(\nabla \times \boldsymbol{F} = \boldsymbol{B}\) y escribiendo las componentes: \(B_x = \partial_y F_z - \partial_z F_y\), \(B_y = \partial_z F_x - \partial_x F_z\), \(B_z = \partial_x F_y - \partial_y F_x\).
La componente \(x\) de \(\nabla \times \boldsymbol{B}\) es \(\partial_y B_z - \partial_z B_y\). Sustituyendo:
⚪ Mei: Intercambiamos el orden de las derivadas con el teorema de Schwarz y reorganizamos.
🟡 Lina: Exacto. Con el teorema de Schwarz, \(\partial_y\partial_x = \partial_x\partial_y\), \(\partial_z\partial_x = \partial_x\partial_z\):
Aquí queremos construir \(\nabla \cdot \boldsymbol{F} = \partial_x F_x + \partial_y F_y + \partial_z F_z\), así que sumamos y restamos \(\partial_x^2 F_x\) (\(+\partial_x^2 F_x - \partial_x^2 F_x = 0\), así que el valor no cambia):
Las componentes \(y\), \(z\) son análogas, así que la identidad se cumple como vector.
🔵 Kai: Entonces, si \(\nabla \cdot \boldsymbol{F} = 0\), el término \(\nabla(\nabla \cdot \boldsymbol{F})\) desaparece y queda \(\nabla \times (\nabla \times \boldsymbol{F}) = -\nabla^2 \boldsymbol{F}\), solo queda el laplaciano. ¿La ecuación de ondas electromagnéticas apareció en el texto principal porque en regiones sin carga \(\nabla \cdot \boldsymbol{E} = 0\)?
🟡 Lina: Exactamente.
🔵 Kai: Entonces, ¿en una región con cargas no se obtiene una ecuación de ondas simple?
🟡 Lina: Así es. En una región con cargas, \(\nabla \cdot \boldsymbol{E} = \rho/\varepsilon_0 \neq 0\), así que el término \(\nabla(\nabla \cdot \boldsymbol{E})\) permanece y no resulta una ecuación de ondas pura. El gradiente de la distribución de carga aparece como "fuente" en el lado derecho.
⚪ Mei: Es decir, solo cuando \(\nabla \cdot \boldsymbol{F} = 0\) queda únicamente el laplaciano y se obtiene la ecuación de ondas — el que la divergencia sea cero o no cambia la forma de la ecuación.
🔵 Kai: Entonces, ¿las ondas gravitacionales también se convierten en ecuación de ondas porque estamos "en el vacío"? ¿Qué pasa en una región con materia?
🟡 Lina: Buena observación. Como vimos en el capítulo 19 del texto principal, en el vacío la ecuación de Einstein linealizada se convierte en ecuación de ondas y las ondas gravitacionales se propagan. En regiones con materia queda una "fuente" en el lado derecho, y se produce generación de ondas — la fórmula cuadrupolar se derivó precisamente de esa "ecuación con fuente".
⚪ Mei: Ya veo, según estemos en el vacío o no, la forma de la ecuación cambia, y se separan propagación y generación.
🟡 Lina: Exacto. Bien, hasta aquí tenemos las identidades importantes de los operadores diferenciales. Pasemos a los teoremas integrales.
📝 Ejercicios:
- Verificación de rot(grad φ) = 0 → Problema B-10. Verificación de rot(grad) = 0, demostración de div(rot F) = 0 → Problema M-2. Demostración de div(rot) = 0, fórmula de la divergencia de un producto → Problema M-4. Fórmula de la divergencia de un producto
A.6 Teoremas integrales¶
🟡 Lina: Finalmente, enuncio los 2 grandes teoremas que conectan derivación e integración. Omito las demostraciones, pero es importante captar el significado físico.
Teorema de Gauss (teorema de la divergencia)¶
Aquí \(V\) es la región encerrada por la superficie cerrada \(S\), \(d\boldsymbol{S}\) es el elemento de área en la dirección normal exterior. \(\int_V \cdots dV\) del lado derecho es una integral de volumen — se divide la región \(V\) en cubos infinitesimales, se calcula para cada cubo el valor de \(\operatorname{div}\boldsymbol{F}\) \(\times\) el volumen infinitesimal \(dV\), y se suman todos los cubos. Mientras que la integral de superficie "divide la superficie en baldosas y suma", la integral de volumen "divide el sólido en bloques y suma" — la misma idea con una dimensión más.
🔵 Kai: El lado izquierdo es "el flujo total que sale a través de la superficie", y el lado derecho es "el total de fuentes que hay dentro". Y nos dice que son iguales.
🟡 Lina: Exactamente. Cuando en el texto principal discutimos el significado físico de las ecuaciones de Einstein, usamos la analogía del teorema de Gauss como "la relación entre la curvatura local (análogo a div) y la desviación global de geodésicas (análogo a la integral de superficie)".
⚪ Mei: En A.4 vimos que la divergencia es "el flujo neto de salida del volumen infinitesimal dividido por el volumen", así que este teorema es la extensión a un volumen finito — un puente entre lo local y lo global.
✅ Verificación de comprensión: ¿Qué dos cantidades afirma que son iguales el teorema de Gauss (teorema de la divergencia)?
Respuesta
El flujo neto de salida del campo vectorial a través de la superficie cerrada \(S\) (integral de superficie \(\oint_S \boldsymbol{F} \cdot d\boldsymbol{S}\)) y la integral de volumen de la divergencia dentro de la región encerrada por esa superficie (\(\int_V \operatorname{div}\boldsymbol{F}\, dV\)) son iguales.
Teorema de Stokes¶
Aquí \(C\) es la curva cerrada que forma el borde de la superficie \(S\), \(d\boldsymbol{r}\) es el vector de desplazamiento infinitesimal a lo largo de la curva (el mismo símbolo de integral de línea introducido en A.4).
⚪ Mei: El lado izquierdo es "la circulación a lo largo de la curva cerrada", y el lado derecho es "el total de remolinos que atraviesan la superficie encerrada por esa curva".
🟡 Lina: En el texto principal, cuando discutimos la dependencia del camino del transporte paralelo (holonomía), hablamos de que "el desfase al transportar un vector a lo largo de una curva cerrada" es igual a "la integral de superficie de la curvatura sobre la superficie encerrada". Aquello era la versión en espacio curvo del teorema de Stokes.
🔵 Kai: Ah, por eso en el texto principal decían "generalización del teorema de Stokes". Todo vuelve aquí.
✅ Verificación de comprensión: ¿Qué dos cantidades afirma que son iguales el teorema de Stokes?
Respuesta
La circulación del campo vectorial a lo largo de la curva cerrada \(C\) (integral de línea \(\oint_C \boldsymbol{F} \cdot d\boldsymbol{r}\)) y la integral de superficie del rotacional sobre la superficie \(S\) cuyo borde es esa curva cerrada (\(\int_S (\operatorname{rot}\boldsymbol{F}) \cdot d\boldsymbol{S}\)) son iguales.
📝 Ejercicios:
- Aplicación del teorema de Gauss (campo de Coulomb) → Problema M-5. Teorema de Gauss y campo de Coulomb, teorema de Stokes y relación entre campos conservativos y curvatura → Problema A-2. Aplicaciones del teorema de Stokes
A.7 Ecuación de ondas — Clasificación de ecuaciones diferenciales en derivadas parciales de segundo orden y solución de d'Alembert¶
🟡 Lina: A partir de aquí clasifico las ecuaciones diferenciales en derivadas parciales de segundo orden que aparecen repetidamente en el texto principal. En el cap. 01 comparamos la ecuación de Poisson con la ecuación de ondas del electromagnetismo, y en el cap. 19 derivamos la ecuación de ondas de gravitacionales a partir de la linealización de las ecuaciones de Einstein. En la edición de teoría de cuerdas, la vibración de la cuerda también obedece una ecuación de ondas. Organizándolas juntas podemos comprender con mayor claridad el comportamiento de las soluciones.
¿Por qué es necesaria la clasificación?¶
Las ecuaciones en derivadas parciales que aparecen en física, aunque se parezcan en apariencia, tienen propiedades de solución completamente distintas. Las soluciones de la ecuación de ondas oscilan, las de la ecuación de difusión se amortiguan, y las de la ecuación de Poisson son estáticas. Identificando el tipo de ecuación podemos predecir el comportamiento de la solución.
Los 3 tipos¶
Tabla A.1: Los 3 tipos de ecuaciones diferenciales parciales de segundo orden y su significado físico
| Tipo | Forma estándar (1D) | Significado físico | Capítulos donde aparece |
|---|---|---|---|
| Ecuación de ondas (hiperbólica) | \(\partial_t^2 f = v^2 \partial_x^2 f\) | Propagación de ondas. La información se transmite a velocidad finita \(v\) | Cap. 1 (ondas EM), Cap. 19 (ondas gravitacionales), edición de teoría de cuerdas (vibración de cuerdas, se trata en la edición posterior) |
| Ecuación de difusión (parabólica) | \(\partial_t f = D \partial_x^2 f\) | Difusión de calor, difusión de partículas. Proceso irreversible | Ejemplo clásico: ecuación de conducción del calor |
| Ecuación de Poisson/Laplace (elíptica) | \(\nabla^2 f = \rho\) | Distribución estática del campo. No depende del tiempo | cap. 01 (potencial gravitatorio), campo electrostático |
Cómo identificarlas¶
- Hay derivada temporal de segundo orden → Ecuación de ondas (soluciones oscilantes)
- Hay derivada temporal de primer orden → Ecuación de difusión (soluciones que se amortiguan)
- No hay derivada temporal → Ecuación de Poisson/Laplace (soluciones estáticas)
⚪ Mei: Solo con mirar la "cara" de la ecuación se puede predecir el comportamiento de la solución.
Solución general de la ecuación de ondas unidimensional (solución de d'Alembert)¶
🟡 Lina: En el cap. 13 de la edición de teoría de cuerdas, al tratar la vibración de cuerdas, usaremos la solución general de la ecuación de ondas. Veamos aquí la derivación mediante cambio de variables. Punto de partida:
Paso 1: Cambio de variables Definimos \(\xi = x - ct\), \(\eta = x + ct\). Inversamente: \(x = (\xi + \eta)/2\), \(t = (\eta - \xi)/(2c)\).
🔵 Kai: ¿Cómo se le ocurre a uno este cambio de variables?
🟡 Lina: La ecuación de ondas debería contener "una onda que avanza hacia la derecha" y "una onda que avanza hacia la izquierda". \(x - ct\) es la fase de la onda que se propaga a la derecha, \(x + ct\) es la fase de la que se propaga a la izquierda, así que al tomarlas como nuevas coordenadas esperamos que la ecuación se simplifique.
Paso 2: Transformar las derivadas parciales con la regla de la cadena
Usamos la regla de la cadena de A.0. Como \(\xi = x - ct\), \(\eta = x + ct\): \(\partial\xi/\partial x = 1\), \(\partial\eta/\partial x = 1\), \(\partial\xi/\partial t = -c\), \(\partial\eta/\partial t = c\). Por tanto:
⚪ Mei: La regla de la cadena de A.0 se usa aquí inmediatamente.
Paso 3: Calcular las segundas derivadas
🟡 Lina: Aplicando una vez más \(\partial/\partial x = \partial/\partial\xi + \partial/\partial\eta\) del paso 2:
Análogamente, aplicando una vez más \(\partial/\partial t = c(-\partial/\partial\xi + \partial/\partial\eta)\):
Paso 4: Sustituir en la ecuación de ondas Reescribimos ambos lados de la ecuación de ondas \(\partial_t^2 u = c^2 \partial_x^2 u\) en las nuevas variables:
- Lado izquierdo: \(\partial_t^2 u = c^2(\partial_{\xi}^2 u - 2\partial_{\xi}\partial_{\eta} u + \partial_{\eta}^2 u)\)
- Lado derecho: \(c^2 \partial_x^2 u = c^2(\partial_{\xi}^2 u + 2\partial_{\xi}\partial_{\eta} u + \partial_{\eta}^2 u)\)
Al sustituir en la ecuación de ondas \(\partial_t^2 u = c^2 \partial_x^2 u\), \(c^2\) es un factor común en ambos lados. Dividiendo ambos lados por \(c^2 \neq 0\):
Restando \(\partial_{\xi}^2 u + \partial_{\eta}^2 u\) de ambos lados, solo quedan los términos de derivadas mixtas: \(-2\partial_{\xi}\partial_{\eta}u = +2\partial_{\xi}\partial_{\eta}u\). Reordenando: \(-4\partial_{\xi}\partial_{\eta}u = 0\). Es decir:
🔵 Kai: ¡Ooh, la ecuación de ondas que era tan complicada se simplifica tanto con solo un cambio de variables!
⚪ Mei: Los términos \(\partial_\xi^2\) y \(\partial_\eta^2\) desaparecen todos y solo queda la derivada mixta.
Paso 5: Solución general
🟡 Lina: Integramos \(\partial^2 u/(\partial\xi\partial\eta) = 0\) respecto a \(\eta\). En el caso de una variable, integrar \(df/dx = 0\) da \(f = C\) (constante). En el caso de derivadas parciales, "las variables distintas de \(\eta\) (es decir \(\xi\)) se tratan como constantes", así que integrar \(\partial(\partial u/\partial\xi)/\partial\eta = 0\) respecto a \(\eta\) da que \(\partial u/\partial\xi\) no depende de \(\eta\) — es decir \(\partial u/\partial\xi = h(\xi)\) (una función arbitraria solo de \(\xi\)).
🔵 Kai: Espera un momento. En una variable, "derivada cero → constante". ¿Por qué en derivadas parciales no es "constante" sino "función de \(\xi\)"?
🟡 Lina: Buena pregunta. Al integrar respecto a \(\eta\), \(\xi\) se trata como constante, así que cualquier cosa que "no dependa de \(\eta\)" vale. Piénsalo por analogía con una variable: la solución de \(df/dx = 0\) es \(f = C\) (constante) — algo que no depende de \(x\). Por la misma lógica, la solución de \(\partial(\cdots)/\partial\eta = 0\) es "algo que no depende de \(\eta\)" = una función arbitraria de \(\xi\). Es decir, la "constante de integración \(C\)" del caso unidimensional se "promueve" a "función arbitraria de la otra variable" en derivadas parciales.
⚪ Mei: Claro, "es constante visto desde \(\eta\)" pero "es libre respecto a \(\xi\)", por eso se convierte en función de \(\xi\).
🟡 Lina: Exacto. Ahora integramos \(\partial u/\partial\xi = h(\xi)\) respecto a \(\xi\). Si consideramos \(\eta\) como constante, esta ecuación tiene la misma forma que la ecuación diferencial ordinaria \(dF/dx = h(x)\), así que se puede integrar de la misma manera que una integral indefinida ordinaria.
Piénsalo por analogía con una variable. Al integrar \(dF/dx = h(x)\) se obtiene \(F(x) = \int h(x)\,dx + C\) (\(C\) es la constante de integración). En nuestro caso, al integrar \(\partial u/\partial\xi = h(\xi)\) respecto a \(\xi\): \(u = f(\xi) + (\text{lo que corresponde a la "constante de integración"})\). Aquí \(f(\xi)\) es la antiderivada de \(h(\xi)\) — \(f\) es una función solo de \(\xi\) que satisface \(df/d\xi = h(\xi)\). Como \(h\) era "una función arbitraria solo de \(\xi\)", \(f\) también es "una función arbitraria solo de \(\xi\)" (como la derivada de \(f\) respecto a \(\xi\) es \(h\), \(f\) es una función suave). Por ejemplo concreto, si \(h(\xi) = \xi^2\) entonces \(f(\xi) = \xi^3/3\), si \(h(\xi) = \sin\xi\) entonces \(f(\xi) = -\cos\xi\), ... según cambie \(h\) cambia \(f\), pero ambas siguen siendo "funciones solo de \(\xi\)".
¿Y la "constante de integración"? En una variable, \(C\) es "una constante que no depende de \(x\)". En el caso de derivadas parciales, solo necesita "no depender de \(\xi\)", así que \(C\) se promueve a una función arbitraria de \(\eta\): \(g(\eta)\).
En definitiva, \(u = f(\xi) + g(\eta)\), donde tanto \(f\) como \(g\) son funciones arbitrarias. Volviendo a las variables originales:
🔵 Kai: ¿Qué tipo de funciones son concretamente estas \(f\) y \(g\)? ¿No tienen que ser funciones trigonométricas?
🟡 Lina: \(f(x - ct)\) representa una onda que avanza hacia la derecha con velocidad \(c\), y \(g(x + ct)\) una que avanza hacia la izquierda. Y \(f\), \(g\) pueden ser ondas sinusoidales, pulsos, o cualquier función diferenciable — todas son soluciones. La forma concreta que toman se determina por las condiciones iniciales (la forma de la onda y la velocidad en \(t = 0\)). Esta es la base para descomponer la vibración de la cuerda en onda que avanza a la izquierda y onda que avanza a la derecha en el cap. 13 de la edición de teoría de cuerdas.
⚪ Mei: Es decir, una vez que se fijan las condiciones iniciales, \(f\) y \(g\) quedan unívocamente determinadas.
🔵 Kai: Me dicen "se determinan por las condiciones iniciales" pero no me imagino qué forma concreta tendrían... En la física del bachillerato las ondas siempre se escribían con \(\sin\) o \(\cos\), ¿eso es un caso particular de esta solución general?
🟡 Lina: Sí. Por ejemplo, si eliges \(f(s) = e^{-s^2}\) (un pulso gaussiano), entonces \(u = e^{-(x-ct)^2}\) es una solución de una onda con forma de montaña avanzando hacia la derecha con velocidad \(c\). \(\sin\) y \(\cos\) son ondas sinusoidales que se extienden infinitamente, pero un pulso localizado también es solución. En el bachillerato se usaba solo \(\sin\) porque se trataban frecuentemente ondas periódicas, pero la ecuación de ondas en sí admite soluciones mucho más generales.
Solución de onda plana y relación de dispersión¶
🟡 Lina: Buena pregunta. Entonces, dentro de la solución general de d'Alembert, consideremos el caso más básico: la "onda sinusoidal".
Primero organizamos cómo se escribe una onda sinusoidal, luego introducimos las herramientas para manejarla eficientemente (desarrollo de Taylor y fórmula de Euler), y finalmente la sustituimos en la ecuación de ondas para derivar la relación de dispersión — avanzamos en 3 pasos. Como estas herramientas son esenciales desde la mecánica cuántica en adelante, las derivamos aquí con cuidado.
Consideremos una onda sinusoidal de longitud de onda \(\lambda\) (longitud espacial de una onda completa) y frecuencia \(\nu\) (número de oscilaciones por segundo; en el bachillerato se suele escribir \(f\), pero en física también se usa mucho \(\nu\) (la letra griega nu)). \(\cos\theta\) completa un período cada vez que \(\theta\) aumenta en \(2\pi\). Así que para lograr "un período cuando \(x\) avanza \(\lambda\)", ponemos como argumento del \(\cos\): \(\theta = 2\pi x/\lambda\) — cuando \(x\) aumenta en \(\lambda\), el argumento aumenta en \(2\pi\), exactamente un período. De forma similar, para lograr "un período cuando \(t\) transcurre \(1/\nu\)" restamos \(2\pi\nu\, t\). Así la onda sinusoidal se escribe como \(\cos(2\pi x/\lambda - 2\pi\nu\, t)\).
🔵 Kai: Las combinaciones \(2\pi/\lambda\) y \(2\pi\nu\) aparecen una y otra vez. ¿No hay una notación abreviada?
🟡 Lina: Sí la hay. Es conveniente definir el número de onda \(k = 2\pi/\lambda\) y la frecuencia angular \(\omega = 2\pi\nu\). Aquí, la fase es el argumento del \(\cos\) — es decir, el valor de \(kx - \omega t\) en \(\cos(kx - \omega t)\). Cuando la fase cambia en \(2\pi\), el \(\cos\) da una vuelta completa y vuelve a su valor original. \(k\) es "cuánto aumenta la fase por cada metro avanzado" — cuanto menor es la longitud de onda \(\lambda\), mayor es \(k\). Por ejemplo, si \(\lambda = 2\) m entonces \(k = 2\pi/2 = \pi\) rad/m, y al avanzar 1 m la fase se desplaza \(\pi\) (= medio período). \(\omega\) es "cuánto aumenta la fase por segundo" — cuanto mayor es la frecuencia \(\nu\), mayor es \(\omega\). Ambos llevan el factor \(2\pi\) porque el cambio de fase en un período completo de onda es \(2\pi\) radianes (= 360° = lo que hace falta para que el \(\cos\) dé una vuelta y vuelva al inicio).
⚪ Mei: Con esto la onda sinusoidal se escribe como \(\cos(kx - \omega t)\).
🟡 Lina: Así es. Y si lo reescribimos como \(\cos[k(x - (\omega/k)t)]\), tiene la forma del \(f(x - ct)\) de d'Alembert — \(\omega/k\) corresponde a la velocidad de la onda. Ahora, queremos reescribir esta onda sinusoidal \(\cos(kx - \omega t)\) en una forma más manejable. Para ello, primero derivamos la relación entre la función exponencial y las funciones trigonométricas.
Desarrollo de Taylor¶
🟡 Lina: Aquí introduzco la herramienta llamada desarrollo de Taylor. Es "un método para representar una función como suma infinita de polinomios, usando el valor en un punto, su primera derivada, su segunda derivada, ...". En la derivación de la divergencia en A.4 usamos la aproximación lineal "\(f(x_0 + h) \approx f(x_0) + f'(x_0)h\)". Aquello era "aproximar la función por una recta alrededor de \(x_0\)". Si quieres más precisión, añades el término de segundo orden \(f''(x_0)h^2/2!\) y aproximas por una parábola. ¿Por qué se divide por \(2!\)? Porque al derivar \(h^2\) dos veces respecto a \(h\) aparece \(2! = 2\), y al dividir por eso el coeficiente queda exactamente como "el valor de la segunda derivada en \(x_0\)". En general, el término de orden \(n\) es \(f^{(n)}(x_0)h^n/n!\) — donde \(f^{(n)}(x_0)\) es la notación para "derivar \(f\) \(n\) veces y evaluar en \(x = x_0\)" (\(f^{(1)} = f'\), \(f^{(2)} = f''\), \(f^{(3)} = f'''\), ... es la generalización). Al derivar \(h^n\) \(n\) veces respecto a \(h\) aparece \(n!\), y al dividir por \(n!\) el coeficiente queda como \(f^{(n)}(x_0)\). Al añadir términos de tercer orden, cuarto orden, ... la aproximación mejora cada vez más. El límite de ese proceso es el desarrollo de Taylor. Aquí usaremos el caso \(x_0 = 0\) — el desarrollo de Taylor alrededor de \(x_0 = 0\) también se llama desarrollo de Maclaurin, pero es lo mismo.
🔵 Kai: Ya veo, la aproximación de primer orden es una recta, la de segundo orden es una parábola, y al añadir más términos la función original se aproxima cada vez mejor.
🟡 Lina: Exacto. Primero explico la notación — \(n!\) (se lee "n factorial") es el producto de todos los enteros desde \(1\) hasta \(n\): \(n! = 1 \times 2 \times \cdots \times n\). Por ejemplo \(2! = 1 \times 2 = 2\), \(3! = 1 \times 2 \times 3 = 6\), \(4! = 24\). Además se conviene \(0! = 1\) (para que el término \(n = 0\) resulte \(f(0)\)). Con esta notación, la fórmula general es:
Aquí "\(\cdots\)" indica que los términos del mismo patrón continúan infinitamente. \(\sum_{n=0}^{\infty}\) del lado derecho es el símbolo que significa "sumar para todos los enteros no negativos \(n = 0, 1, 2, 3, \ldots\)" (\(\sum\) es la letra griega mayúscula sigma, que representa "suma". Quizás en sucesiones del bachillerato usaste \(\sum_{k=1}^{N} a_k\); cuando el límite superior es \(\infty\) significa "el valor límite de sumar términos sin cesar"). El término \(n\)-ésimo es \(f^{(n)}(0)\,x^n / n!\).
Usemos esta fórmula general para obtener el desarrollo de Taylor de \(e^x\) (el número de Euler \(e \approx 2.718\) elevado a \(x\)). La propiedad más importante de \(e^x\) es "derivar y obtener uno mismo" — es decir, si \(f(x) = e^x\) entonces \(f'(x) = e^x\), \(f''(x) = e^x\), ... no importa cuántas veces derives, sigue siendo \(e^x\) (de hecho esta propiedad es la razón que define el número especial \(e\) — \(e\) se determina como "la base de la función exponencial que no cambia al derivar"). Por tanto, todos los valores en \(x = 0\) son \(f(0) = f'(0) = f''(0) = \cdots = e^0 = 1\). Sustituyendo en la fórmula general:
⚪ Mei: Como todos los valores de las derivadas son 1, los coeficientes de cada término son simplemente \(1/n!\) — una serie sorprendentemente simple.
🟡 Lina: La discusión rigurosa de por qué este desarrollo coincide con la función original para cualquier \(x\) la dejaremos para el apéndice de la edición de mecánica cuántica, pero se sabe que para \(e^x\), \(\cos x\), \(\sin x\) la serie converge y coincide con la función original para todo número real \(x\). Por ahora aceptamos este resultado y seguimos adelante.
🔵 Kai: Si sumas infinitamente, ¿de verdad da exactamente \(e^x\)? Si paras a medio camino es solo una aproximación, ¿no?
🟡 Lina: Buena duda. Si paras es ciertamente una aproximación — cuantos más términos, mayor precisión. Pero para \(e^x\), \(\cos x\), \(\sin x\) está demostrado matemáticamente que el límite de sumar infinitos términos coincide completamente con la función original. Intuitivamente, la aproximación de primer orden de \(e^x\) alrededor de \(x = 0\) es \(1 + x\), la de segundo orden es \(1 + x + x^2/2\) — cuanto más pequeño es \(x\), menos términos hacen falta para una buena aproximación, y para \(x\) grande basta con añadir suficientes términos. La prueba rigurosa la dejamos para después, pero por ahora aceptamos el hecho de que "para estas funciones la serie infinita converge" y avanzamos.
Sustituyamos formalmente \(x = i\theta\) en esta serie. Aquí \(i\) es la unidad imaginaria — un número que satisface \(i^2 = -1\) (lo aprendiste en Matemáticas II del bachillerato). Quizás pienses "¿se puede poner un número imaginario en una fórmula para reales?" — pero como el desarrollo de Taylor consiste solo en sumas y multiplicaciones de cada término, no hay problema en calcular cada término y sumarlos aunque \(x\) sea complejo (la discusión rigurosa de convergencia la dejamos para el apéndice de la edición de mecánica cuántica):
🔵 Kai: ¿Qué pasa al elevar \(i\) a distintas potencias?
🟡 Lina: En Matemáticas II del bachillerato aprendiste que \(i^2 = -1\). A partir de ahí, calculando en orden: \(i^3 = i^2 \cdot i = (-1) \cdot i = -i\), \(i^4 = i^3 \cdot i = (-i) \cdot i = -i^2 = -(-1) = 1\), \(i^5 = i^4 \cdot i = 1 \cdot i = i\), ... se repite con período 4: \(i, -1, -i, 1\). Es decir, las potencias pares de \(i\) son reales (\(\pm 1\)) y las impares son puramente imaginarias (\(\pm i\)). Usemos esto para escribir concretamente cada término:
- \(n=0\): \((i\theta)^0/0! = 1\) (real)
- \(n=1\): \((i\theta)^1/1! = i\theta\) (puramente imaginario)
- \(n=2\): \((i\theta)^2/2! = i^2\theta^2/2! = -\theta^2/2!\) (real)
- \(n=3\): \((i\theta)^3/3! = i^3\theta^3/3! = -i\theta^3/3!\) (puramente imaginario)
- \(n=4\): \((i\theta)^4/4! = i^4\theta^4/4! = +\theta^4/4!\) (real)
- \(n=5\): \((i\theta)^5/5! = i^5\theta^5/5! = +i\theta^5/5!\) (puramente imaginario)
Se ve el patrón — los términos de orden par son reales y los de orden impar llevan \(i\) (son puramente imaginarios). Por eso podemos separar el desarrollo de \(e^{i\theta}\) en parte real (términos sin \(i\)) y parte imaginaria (términos con \(i\)):
🔵 Kai: ¡Ah, como las potencias de \(i\) son periódicas, los términos de potencia par y los de potencia impar se separan naturalmente!
⚪ Mei: Los términos de potencia par van a la parte real y los de potencia impar a la parte imaginaria.
🟡 Lina: Así es. \(\cos\theta\) y \(\sin\theta\) también se pueden desarrollar en serie con el mismo método de Taylor. Apliquemos la fórmula general del desarrollo de Taylor \(f(\theta) = f(0) + f'(0)\theta + f''(0)\theta^2/2! + f'''(0)\theta^3/3! + \cdots\). Para \(\cos\theta\): \(\cos 0 = 1\), \((\cos\theta)' = -\sin\theta\) así que en \(\theta=0\) vale \(0\), \((\cos\theta)'' = -\cos\theta\) así que en \(\theta=0\) vale \(-1\), \((\cos\theta)''' = \sin\theta\) así que en \(\theta=0\) vale \(0\), \((\cos\theta)^{(4)} = \cos\theta\) así que en \(\theta=0\) vale \(1\), ... se repite con período 4: \(1, 0, -1, 0\). Sustituyendo: \(\cos\theta = 1 + 0 \cdot \theta + (-1)\theta^2/2! + 0 \cdot \theta^3/3! + 1 \cdot \theta^4/4! + \cdots\).
🔵 Kai: ¡Ah, que los valores de las derivadas de \(\cos\theta\) repitan \(1, 0, -1, 0, \ldots\) y que al tomar solo los términos de orden par del desarrollo de \(e^{i\theta}\) salga \(1, -1/2!, +1/4!, \ldots\) se corresponden! Por eso la parte real de \(e^{i\theta}\) es \(\cos\theta\).
🟡 Lina: Exactamente eso. Si miras solo los términos de orden par, los coeficientes de la parte real de \(e^{i\theta}\) son \(1, -1/2!, +1/4!, \ldots\) y coinciden completamente con el desarrollo de \(\cos\theta\). Los de orden impar coinciden igualmente con \(\sin\theta\).
⚪ Mei: Entiendo, la periodicidad de las potencias de \(i\) realiza automáticamente la separación en parte real e imaginaria.
🟡 Lina: Exacto. Verifiquemos también \(\sin\theta\): \(\sin 0 = 0\), \((\sin\theta)' = \cos\theta\) así que en \(\theta=0\) vale \(1\), \((\sin\theta)'' = -\sin\theta\) así que en \(\theta=0\) vale \(0\), \((\sin\theta)''' = -\cos\theta\) así que en \(\theta=0\) vale \(-1\), .... Sustituyendo: \(\sin\theta = 0 + 1 \cdot \theta + 0 \cdot \theta^2/2! + (-1)\theta^3/3! + \cdots\). Organizando:
Esto coincide exactamente con la parte real e imaginaria de arriba. Así se obtiene la fórmula de Euler:
⚪ Mei: Es decir, al separar el desarrollo de Taylor de \(e^{i\theta}\) en parte real e imaginaria, cada una coincide término a término con el desarrollo de Taylor de \(\cos\theta\) y \(\sin\theta\) — por eso son iguales. Ese es el argumento.
🔵 Kai: Increíble... la función exponencial y las trigonométricas se conectan a través de los números imaginarios, aunque parecen funciones totalmente distintas. Si ponemos \(\theta = \pi\), ¿sale \(e^{i\pi} = \cos\pi + i\sin\pi = -1\)?
🟡 Lina: Exacto. \(e^{i\pi} + 1 = 0\) — esta es la famosa identidad de Euler. Bien, usando esta fórmula, la onda sinusoidal \(A\cos(kx - \omega t)\) se puede representar como la parte real de: $$ u = Ae^{i(kx - \omega t)} $$
\(A\) es la amplitud (una constante real positiva). Verifiquémoslo: con la fórmula de Euler \(e^{i\theta} = \cos\theta + i\sin\theta\), poniendo \(\theta = kx - \omega t\), tenemos \(Ae^{i(kx-\omega t)} = A\cos(kx - \omega t) + iA\sin(kx - \omega t)\), así que la parte real es efectivamente \(A\cos(kx - \omega t)\). Aquí presento la interpretación geométrica de los números complejos. Un número complejo \(a + bi\) se puede representar como un punto \((a, b)\) en un plano con el eje horizontal para la parte real \(a\) y el eje vertical para la parte imaginaria \(b\) (llamado plano complejo). Entonces \(e^{i\theta} = \cos\theta + i\sin\theta\) tiene parte real \(\cos\theta\) y parte imaginaria \(\sin\theta\), así que corresponde al punto \((\cos\theta, \sin\theta)\) — un punto a distancia 1 del origen (\(\cos^2\theta + \sin^2\theta = 1\)) y a un ángulo \(\theta\) del eje horizontal. Es decir, \(e^{i\theta}\) representa "un punto en el círculo unitario rotado un ángulo \(\theta\)". De aquí en adelante, para los cálculos con la ecuación de ondas usaremos esta notación compleja.
🔵 Kai: ¿Por qué usar números complejos a propósito? ¿No se puede dejar en \(\cos\)?
🟡 Lina: Hay dos razones. Primero la práctica — al derivar \(e^{i\theta}\) sale \(ie^{i\theta}\) y ya está, sin ir y venir entre \(\cos\) y \(\sin\). Segundo la justificación — la ecuación de ondas es lineal (multiplicar una solución por una constante o sumar soluciones da otra solución). "Lineal" significa más concretamente que cada término de la ecuación consiste solo en \(u\) y sus derivadas parciales en primer grado, sin términos no lineales como \(u^2\) o \(u \cdot \partial_t u\). En ese caso, al sustituir \(u = u_1 + iu_2\) (\(u_1\), \(u_2\) funciones de valor real) en la ecuación, las derivadas parciales de cada término se separan en parte real e imaginaria — por ejemplo \(\partial_t^2(u_1 + iu_2) = \partial_t^2 u_1 + i\partial_t^2 u_2\). Entonces toda la ecuación toma la forma "(ecuación para \(u_1\)) \(+ i \times\) (ecuación para \(u_2\)) \(= 0\)". Aquí, para que un número complejo \(a + bi = 0\) se cumpla, debe ser \(a = 0\) y \(b = 0\) (la parte real y la imaginaria son "direcciones independientes", una sola no puede cancelar a la otra). Por tanto \(u_1\) y \(u_2\) satisfacen la ecuación independientemente. Así se justifica el procedimiento de "calcular con números complejos y al final tomar la parte real". En mecánica cuántica la función de onda misma es de valor complejo, así que esta notación se vuelve imprescindible.
🔵 Kai: Como es lineal se puede separar la parte real de la imaginaria — se usan los números complejos como herramienta de cálculo y al final tomar la parte real da la respuesta física. Pero si la ecuación fuera no lineal — por ejemplo si hubiera un término como \(u^2\) — ¿no se podría usar esta técnica?
🟡 Lina: Exacto, no se podría. En el caso no lineal, \((u_1 + iu_2)^2 = u_1^2 - u_2^2 + 2iu_1 u_2\): la parte real y la imaginaria se mezclan y no se pueden separar. Afortunadamente, la ecuación de ondas es lineal así que podemos usarla tranquilamente.
⚪ Mei: La linealidad es lo que garantiza "poder usar los números complejos como herramienta" — este es un punto importante.
🟡 Lina: Entonces sustituyamos concretamente en la ecuación de ondas \(\partial_t^2 u = c^2 \partial_x^2 u\). Usamos la propiedad que verificamos antes de que "\(e^x\) no cambia de forma al derivar". Derivando \(e^{ax}\) respecto a \(x\), por la regla de la cadena sale \(ae^{ax}\) — lo mismo vale si \(a\) es complejo. Es decir, al derivar \(e^{i\theta}\) respecto a \(\theta\) sale \(i\,e^{i\theta}\) — cada vez que derivamos simplemente sale un \(i\) delante, sin cambiar la forma de la función.
Concretamente, al derivar parcialmente \(u = Ae^{i(kx - \omega t)}\) respecto a \(t\): como \(x\) se trata como constante, la parte \(e^{ikx}\) queda igual, y de la derivada de \(e^{-i\omega t}\) sale \(-i\omega\) delante. Es decir \(\partial u/\partial t = -i\omega\, u\). Derivando una vez más respecto a \(t\), se multiplica por \((-i\omega)^2 = -\omega^2\), así que el lado izquierdo es \(-\omega^2 u\). Análogamente, derivando dos veces respecto a \(x\), se multiplica por \((ik)^2 = -k^2\), así que el lado derecho es \(-c^2 k^2 u\).
🔵 Kai: Ah, cada vez que derivas simplemente sale \(-i\omega\) o \(ik\) delante y la forma de \(e\) se mantiene. Así que el cálculo de derivadas se convierte en una simple multiplicación — qué conveniente.
🟡 Lina: Resumiendo, el resultado de sustituir en la ecuación de ondas \(\partial_t^2 u = c^2 \partial_x^2 u\) es \(-\omega^2 u = -c^2 k^2 u\).
🔵 Kai: Si divido por \(u \neq 0\), queda \(\omega^2 = c^2 k^2\). ¿Esto significa que hay varias combinaciones posibles de \(\omega\) y \(k\)?
🟡 Lina: Sí. Tomando la raíz cuadrada de \(\omega^2 = c^2 k^2\): \(|\omega| = c|k|\) (ya que \(c > 0\)). Aquí, por convención en física tomamos \(\omega > 0\) (la frecuencia es positiva). Entonces \(\omega = c|k|\), y la dirección de propagación de la onda la lleva el signo de \(k\).
🔵 Kai: Espera un momento. Antes definimos \(k = 2\pi/\lambda\). Como \(\lambda\) es positiva, \(k\) también debería ser positivo...
🟡 Lina: Buena observación. \(k = 2\pi/\lambda\) es la definición de la magnitud del número de onda. Pero cuando queremos incluir también la dirección de propagación, le ponemos signo a \(k\) — \(k > 0\) para una onda que avanza en la dirección \(+x\), \(k < 0\) para una que avanza en la dirección \(-x\). La magnitud es \(|k| = 2\pi/\lambda\) sin cambio. Es decir, \(k\) es una cantidad que lleva la información de dirección de propagación sobre el "cambio de fase por metro".
Cuando \(k > 0\): \(\omega = ck\), así que \(e^{i(kx - \omega t)} = e^{ik(x - ct)}\) — si seguimos un punto donde la fase \(k(x - ct)\) es constante, al aumentar \(t\) también debe aumentar \(x\). Es decir, la cresta de la onda se mueve en la dirección \(+x\) (derecha) con velocidad \(c\). Inversamente, si \(k < 0\): \(\omega = c(-k) = -ck\), así que \(e^{i(kx - \omega t)} = e^{ik(x + ct)}\) — si seguimos un punto donde la fase \(k(x + ct)\) es constante, como \(k < 0\) la dirección en que \(x + ct\) disminuye es la dirección en que \(x\) disminuye (izquierda) — es una onda que avanza hacia la izquierda.
⚪ Mei: Los \(f(x - ct)\) y \(g(x + ct)\) de la solución general de d'Alembert corresponden al signo de \(k\).
🟡 Lina: Resumiendo: bajo la convención \(\omega > 0\) se cumple \(\omega = c|k|\), y el signo de \(k\) determina la dirección de propagación. La expresión que relaciona \(\omega\) y \(k\) se llama relación de dispersión.
🔵 Kai: Ah, cuando \(k > 0\), \(\omega = c|k| = ck\) así que \(e^{i(kx - \omega t)} = e^{ik(x - ct)}\). ¡Esto tiene la forma del \(f(x - ct)\) de d'Alembert!
🟡 Lina: Bien observado. Análogamente, si \(k < 0\) resulta \(e^{ik(x + ct)}\), que corresponde a la onda que avanza a la izquierda \(g(x + ct)\). La solución de onda plana es la concretización de los \(f\) y \(g\) de la solución general de d'Alembert como ondas sinusoidales.
⚪ Mei: Es decir, la solución de onda plana es lo que se obtiene al restringir las "funciones arbitrarias" de la solución general a ondas sinusoidales.
🟡 Lina: Exacto. Aquí definimos la velocidad (y dirección) a la que se mueve la cresta de la onda como velocidad de fase: \(v_p = \omega/k\). Verifiquemos por qué esto es la "velocidad de la cresta". La cresta está en la posición donde la fase \(kx - \omega t = \text{const}\). Derivando esta condición respecto a \(t\): \(k(dx/dt) - \omega = 0\), es decir \(dx/dt = \omega/k\) — esa es la velocidad de la cresta. Si \(k > 0\): \(\omega = ck\) así que \(v_p = \omega/k = ck/k = c\) (avanza a la derecha). Si \(k < 0\): \(\omega = c|k| = c(-k) = -ck\) así que \(v_p = \omega/k = -ck/k = -c\) (avanza a la izquierda). En ambos casos la magnitud de la velocidad es \(|v_p| = c\). Verifiquemos también la correspondencia con \(v = \lambda\nu\) del bachillerato: \(\lambda = 2\pi/|k|\), \(\nu = \omega/(2\pi)\), así que \(\lambda\nu = \omega/|k| = c\), coincide. Es decir, para esta ecuación de ondas, la magnitud de la velocidad de fase es la misma \(c\) para cualquier número de onda \(k\) — la forma de la onda se propaga sin deformarse. Cuando esto ocurre se dice que "no hay dispersión".
⚪ Mei: Es decir, como \(\omega = c|k|\) y la magnitud de la velocidad de fase \(|\omega/k| = c\) es la misma para todo \(k\), todas las ondas avanzan a la misma velocidad — por eso la forma de la onda no se deforma.
🔵 Kai: ¿Y qué pasa cuando "hay dispersión"? ¿Qué es lo que se "dispersa"?
🟡 Lina: Si la velocidad es distinta para cada número de onda, las componentes que inicialmente estaban superpuestas se separan y dispersan — por eso se llama "dispersión". Por ejemplo, para las ondas en la superficie del agua la relación es \(\omega \propto \sqrt{k}\). La velocidad de fase es \(v_p = \omega/k \propto \sqrt{k}/k = 1/\sqrt{k}\), así que las ondas con mayor número de onda (menor longitud de onda) avanzan más lento. Entonces una onda que inicialmente tenía una forma bonita se deforma con el tiempo. La luz en el vacío y las ondas gravitacionales tienen \(\omega = c|k|\) sin dispersión, así que se propagan manteniendo su forma.
🔵 Kai: Ya veo, que un prisma descomponga la luz blanca en los colores del arcoíris también es porque en el vidrio la velocidad depende de la longitud de onda — es decir, hay dispersión. Entonces las ondas gravitacionales, como en el vacío no hay dispersión, la forma de onda se mantiene tal cual hasta llegar a la Tierra — ¡por eso LIGO puede leer la forma de onda!
🟡 Lina: Exacto. Si las ondas gravitacionales tuvieran dispersión, la forma de onda se deformaría en el camino desde un astro lejano y no se podría usar el filtrado adaptado. La ausencia de dispersión es una condición previa de la astronomía de ondas gravitacionales.
Conexión con el texto principal¶
🟡 Lina: Repasemos dónde influía esta clasificación de ecuaciones de ondas en el texto principal.
- Cap. 1 (Poisson vs ondas): La gravedad newtoniana es la ecuación de Poisson (elíptica) sin derivadas temporales — propagación instantánea. El electromagnetismo es la ecuación de ondas (hiperbólica) que se propaga a velocidad \(c\). En Cap. 1 contrastamos esta diferencia con el postulado de la relatividad especial "la información no supera la velocidad de la luz", y eso motivó la relatividad general. La clasificación aquí (elíptica = propagación instantánea vs hiperbólica = propagación a velocidad finita) es el trasfondo matemático de esa discusión.
- Cap. 19 (ondas gravitacionales): La ecuación de Einstein linealizada \(\Box \bar{h}_{\mu\nu} = -(16\pi G/c^4)T_{\mu\nu}\) toma la forma de ecuación de ondas. Pequeñas perturbaciones de la curvatura del espaciotiempo se propagan a la velocidad de la luz — la predicción teórica de las ondas gravitacionales.
- Edición de teoría de cuerdas (se trata en edición posterior): La vibración de la cuerda obedece una ecuación de ondas bidimensional, y su solución general se descompone en onda que avanza a la izquierda y onda que avanza a la derecha para luego cuantizar.
🔵 Kai: Todo se puede determinar preguntando "¿tiene la forma de ecuación de ondas o no?". Con esta clasificación, al encontrar una ecuación nueva se puede predecir inmediatamente el comportamiento de la solución.
✅ Verificación de comprensión: Si una ecuación en derivadas parciales contiene la segunda derivada temporal, ¿a qué tipo se clasifica?
Respuesta
Se clasifica como ecuación de ondas (tipo hiperbólico), y la solución oscila (se propaga como onda).
✅ Verificación de comprensión: En la solución general de la ecuación de ondas unidimensional \(u(x, t) = f(x - ct) + g(x + ct)\), ¿qué representa \(c\)?
Respuesta
La velocidad de propagación de la onda. \(f(x - ct)\) es una onda que avanza a la derecha, \(g(x + ct)\) es una onda que avanza a la izquierda.
A.8 Tabla resumen¶
🟡 Lina: Finalmente, resumo el contenido de este apéndice en una tabla.
Tabla A.2: Resumen de operaciones y conceptos del Apéndice A
| Operación/Concepto | Símbolo | Entrada → Salida | Significado físico |
|---|---|---|---|
| Derivada parcial | \(\partial f/\partial x\) | Función multivariable → Función multivariable | Tasa de cambio con las demás variables fijas |
| Gradiente | \(\nabla\varphi\) | Escalar → Vector | Dirección de máximo ascenso y tasa de cambio |
| Divergencia | \(\nabla \cdot \boldsymbol{F}\) | Vector → Escalar | Intensidad de la fuente |
| Rotacional | \(\nabla \times \boldsymbol{F}\) | Vector → Vector | Intensidad y dirección del remolino |
| Laplaciano | \(\nabla^2\varphi\) | Escalar → Escalar | Divergencia del gradiente (curvatura del potencial) |
| Ecuación de ondas | \(\partial_t^2 f = v^2 \nabla^2 f\) | Ecuación que satisface un campo escalar/vectorial | Propagación de ondas a velocidad \(v\) |
Avance del próximo capítulo¶
En el siguiente Apéndice B se introducen el producto tensorial y la convención de suma de Einstein. Comprenderemos la operación de "aumentar índices" de un vector —el producto tensorial— y dominaremos la notación de contracción indispensable para los cálculos en relatividad general.
Problemas de práctica¶
📝 Ejercicios:
- Cálculo de componentes del producto vectorial → Problema B-1. Cálculo por componentes del producto vectorial
- Verificación de ortogonalidad → Problema B-2. Ortogonalidad del producto vectorial
- Cálculo del producto triple escalar con determinante → Problema B-3. Producto triple escalar
- Verificación numérica de la identidad de Lagrange → Problema B-8. Verificación de la identidad de Lagrange
- Verificación numérica de la fórmula BAC-CAB → Problema B-9. Verificación de la fórmula BAC-CAB
- Demostración general de la fórmula BAC-CAB → Problema M-1. Demostración de la fórmula BAC-CAB
- Producto escalar de dos productos vectoriales → Problema M-3. Fórmula del producto escalar entre productos vectoriales
- Derivación unificada con el símbolo de Levi-Civita → Problema A-1. Identidades con el símbolo de Levi-Civita
- Cálculo del gradiente → Problema B-4. Gradiente de un campo escalar
- Cálculo de la divergencia → Problema B-5. Divergencia de un campo vectorial
- Cálculo del rotacional → Problema B-6. Rotacional de un campo vectorial
- Cálculo del laplaciano → Problema B-7. Laplaciano de un campo escalar
- Verificación de rot(grad φ) = 0 → Problema B-10. Verificación de rot(grad) = 0
- Demostración de div(rot F) = 0 → Problema M-2. Demostración de div(rot) = 0
- Fórmula de la divergencia de un producto → Problema M-4. Fórmula de la divergencia de un producto
- Aplicación del teorema de Gauss (campo de Coulomb) → Problema M-5. Teorema de Gauss y campo de Coulomb
- Teorema de Stokes y relación entre campos conservativos y curvatura → Problema A-2. Aplicaciones del teorema de Stokes
Referencias¶
- 石井俊全『一般相対性理論を一歩一歩数式で理解する』ベレ出版, 第 1 章「数学の準備」
- 太田浩一『電磁気学の基礎 I』東京大学出版会(Maxwell 方程式とベクトル解析の関係について)
- H. M. Schey, Div, Grad, Curl, and All That, W. W. Norton(直感的な理解のための入門書)
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.