Apéndice B: Fundamentos de álgebra lineal y espacios de Hilbert¶
Resumen de lo anterior:
En Apéndice A organizamos los fundamentos de los números complejos indispensables para la mecánica cuántica: operaciones aritméticas, forma polar, fórmula de Euler, conjugado complejo, etc. En este Apéndice construimos el mundo de los vectores y matrices que tienen esos números complejos como "componentes" —el álgebra lineal— y lo conectamos con el espacio de Hilbert, el escenario de la mecánica cuántica.
Objetivo de este Apéndice:
- Entender el álgebra lineal, el lenguaje matemático de la mecánica cuántica, como extensión natural de los "vectores" y "matrices" del bachillerato
- Cubrir espacios vectoriales, producto interno, bases ortonormales, operadores lineales, problemas de valores propios, matrices hermitianas, matrices unitarias y producto tensorial, y comprender qué cambia al extender a espacios de Hilbert de dimensión infinita
- Todo esto constituye la "gramática" de la mecánica cuántica: estados, observables, evolución temporal y sistemas compuestos se describen con las herramientas que desarrollamos aquí
B.1 Espacios vectoriales — Si puedes "sumar" y "multiplicar por un escalar", todo es un vector¶
🟡 Lina: En el bachillerato, un vector era una "flecha". Pero en mecánica cuántica usamos vectores en un sentido mucho más amplio. Vamos a definir "qué es un espacio vectorial" de la forma más concreta posible.
🔵 Kai: ¿Qué significa un vector que no es una flecha?
🟡 Lina: Buena pregunta. Resumiendo: todo aquello que admita "suma" y "multiplicación por un escalar" y satisfaga ciertas reglas naturales puede llamarse vector. Las flechas lo son, las tuplas de números también, y de hecho ¡las funciones también pueden ser vectores!
🟡 Lina: Más precisamente, decimos que un conjunto \(V\) es un espacio vectorial si, para cualesquiera elementos (que llamamos vectores) \(\mathbf{u}, \mathbf{v}, \mathbf{w}\) de \(V\) y escalares \(c, c_1, c_2\) (reales o complejos), se satisfacen los siguientes 8 axiomas.
Tabla B.1: Los 8 axiomas de un espacio vectorial
| Núm. | Axioma | Significado |
|---|---|---|
| 1 | \(\mathbf{u} + \mathbf{v} \in V\) | El resultado de la suma está en \(V\) (cerradura) |
| 2 | \(\mathbf{u} + \mathbf{v} = \mathbf{v} + \mathbf{u}\) | Se puede intercambiar el orden de la suma |
| 3 | \((\mathbf{u} + \mathbf{v}) + \mathbf{w} = \mathbf{u} + (\mathbf{v} + \mathbf{w})\) | Asociatividad de la suma |
| 4 | \(\exists\, \mathbf{0}:\ \mathbf{u} + \mathbf{0} = \mathbf{u}\) | Existe el vector cero |
| 5 | \(\exists\, (-\mathbf{u}):\ \mathbf{u} + (-\mathbf{u}) = \mathbf{0}\) | Existe el vector opuesto |
| 6 | \(c\mathbf{u} \in V\) | El resultado de multiplicar por un escalar está en \(V\) |
| 7 | \(c_1(c_2 \mathbf{u}) = (c_1 c_2)\mathbf{u}\), \(1 \cdot \mathbf{u} = \mathbf{u}\) | Asociatividad del producto escalar y elemento neutro escalar |
| 8 | \(c_1(\mathbf{u}+\mathbf{v}) = c_1\mathbf{u} + c_1\mathbf{v}\), \((c_1+c_2)\mathbf{u} = c_1\mathbf{u} + c_2\mathbf{u}\) | Distributividad (dos leyes) |
🔵 Kai: ¡Vaya, son 8!
⚪ Mei: Pero si miras uno por uno, son cosas que dábamos por obvias con los vectores del bachillerato. "Se puede cambiar el orden de la suma", "existe el vector cero"...
🟡 Lina: Exacto. Solo estamos haciendo explícito lo evidente. Pero el punto clave es que cualquier cosa que satisfaga estos axiomas puede llamarse espacio vectorial. Cuando los escalares son números complejos \(\mathbb{C}\), lo llamamos en particular espacio vectorial complejo. Es el que usamos en mecánica cuántica.
🟡 Lina: Voy a dar 3 ejemplos concretos.
Ejemplo 1: \(N\) números complejos dispuestos en columna — \(\mathbb{C}^N\)
La suma es componente a componente, y la multiplicación por escalar también. Es la extensión natural de los vectores del bachillerato.
Ejemplo 2: El caso \(N = 2\) — \(\mathbb{C}^2\)
Este aparece como el espacio de estados del espín 1/2 en Cap. 5. Tiene solo 2 dimensiones, pero como las componentes son complejas, los "grados de libertad" reales son 4.
🔵 Kai: Vaya, con solo 2 componentes hay 4 grados de libertad.
🟡 Lina: Ejemplo 3: El conjunto de funciones de cuadrado integrable — \(L^2\)
"De cuadrado integrable" significa que al integrar \(|f(x)|^2\) desde \(-\infty\) hasta \(+\infty\) se obtiene un valor finito — es decir, la función tiende a cero suficientemente rápido en el infinito. Por ejemplo, \(f(x) = e^{-x^2}\) tiende rápidamente a cero en el infinito, así que pertenece a \(L^2\). En cambio, \(f(x) = \sin x\) sigue oscilando en el infinito. \(|\sin x|^2 = \sin^2 x\) toma valores entre 0 y 1 indefinidamente, así que al ampliar el intervalo de integración el área se acumula sin límite. Más cuantitativamente, usando la fórmula del ángulo doble \(\sin^2 x = (1 - \cos 2x)/2\) se obtiene \(\int_0^{2\pi} \sin^2 x\, dx = \pi\), por lo que en cada periodo se añade un área de \(\pi\). Como esta contribución se repite indefinidamente, \(\int_{-\infty}^{\infty} |\sin x|^2\, dx = \infty\) y no pertenece a \(L^2\). Con la suma de funciones \((f+g)(x) = f(x) + g(x)\) y la multiplicación por escalar \((cf)(x) = c\,f(x)\) se satisfacen los 8 axiomas. En particular, verifiquemos la "cerradura bajo la suma" — es decir, que si \(f, g \in L^2\) entonces \(f + g \in L^2\).
La clave es la siguiente desigualdad:
Te la demuestro en 3 pasos.
Paso 1 (desigualdad triangular): En cada punto \(x\), los valores \(f(x)\) y \(g(x)\) son números complejos, por lo que se cumple la desigualdad triangular para números complejos \(|f(x)+g(x)| \leq |f(x)| + |g(x)|\). Esto expresa la propiedad geométrica de que "al sumar dos números complejos como flechas, la longitud del rodeo \(|f(x)| + |g(x)|\) es mayor o igual que la longitud directa \(|f(x)+g(x)|\)". En adelante omitimos que la desigualdad es en cada punto \(x\) y escribimos \(|f+g| \leq |f| + |g|\).
Paso 2 (elevar al cuadrado): Elevando ambos lados al cuadrado: \(|f+g|^2 \leq (|f|+|g|)^2 = |f|^2 + 2|f||g| + |g|^2\).
Paso 3 (acotar el término cruzado): Usamos \(2|f||g| \leq |f|^2 + |g|^2\). Esto sale inmediatamente de expandir \((|f|-|g|)^2 \geq 0\): \(|f|^2 - 2|f||g| + |g|^2 \geq 0\).
⚪ Mei: Basta con desarrollar \((|f|-|g|)^2 \geq 0\) para obtener la cota del término cruzado. Simple.
🟡 Lina: Combinando los pasos 2 y 3 obtenemos \(|f+g|^2 \leq 2(|f|^2 + |g|^2)\). Integrando ambos lados:
y queda demostrado que \(f+g \in L^2\). Este es el espacio donde vive la función de onda.
🔵 Kai: ¡¿Las funciones son vectores?!
🟡 Lina: Así es. Como admiten "suma" y "multiplicación por escalar" y satisfacen los axiomas, forman un espacio vectorial legítimo. Sin embargo, hay una gran diferencia: \(\mathbb{C}^N\) es de dimensión finita y \(L^2\) es de dimensión infinita. En este Apéndice trabajamos principalmente en dimensión finita y al final resumimos qué cambia en dimensión infinita.
✅ Verificación de comprensión: ¿Por qué el conjunto de funciones \(L^2\) puede considerarse un espacio vectorial?
Respuesta
Porque se puede definir la suma de funciones \((f+g)(x) = f(x) + g(x)\) y la multiplicación por escalar \((cf)(x) = c\,f(x)\), y se satisfacen los 8 axiomas de espacio vectorial. No solo las flechas o las tuplas de números: las funciones también pueden tratarse como vectores si admiten "suma" y "multiplicación por escalar".
✅ Verificación de comprensión: ¿Cuáles son las 2 operaciones más esenciales en la definición de "espacio vectorial"?
Respuesta
La suma (adición entre vectores) y la multiplicación por escalar (producto de un vector por una constante). Un conjunto en el que estas dos operaciones están cerradas y satisfacen los 8 axiomas es un espacio vectorial.
Dimensión y base¶
🟡 Lina: Dentro de un espacio vectorial, el número máximo de vectores linealmente independientes se llama dimensión.
🔵 Kai: ¿Qué era eso de linealmente independiente?
🟡 Lina: Los vectores \(\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_n\) son linealmente independientes si
solo se satisface cuando \(c_1 = c_2 = \cdots = c_n = 0\). Es decir, "ningún vector puede expresarse como combinación lineal de los demás". Al contrario, si alguno puede construirse como combinación de los otros, se dice que son linealmente dependientes.
⚪ Mei: Independencia lineal es "ninguno sobra"; dependencia lineal es "alguno puede sustituirse por los demás".
🟡 Lina: Exacto. En un espacio vectorial de dimensión \(N\), si elegimos un conjunto de \(N\) vectores linealmente independientes \(\{\mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_N\}\), cualquier vector \(\mathbf{v}\) del espacio se escribe de forma única como
A \(\{\mathbf{e}_k\}\) lo llamamos base y a los \(v_k\) componentes (coeficientes de expansión).
✅ Verificación de comprensión: ¿Qué significa "linealmente independiente"?
Respuesta
Un conjunto de vectores \(\mathbf{v}_1, \ldots, \mathbf{v}_n\) es linealmente independiente si \(c_1 \mathbf{v}_1 + \cdots + c_n \mathbf{v}_n = \mathbf{0}\) solo se satisface con \(c_1 = c_2 = \cdots = c_n = 0\). Es decir, ningún vector puede expresarse como combinación lineal de los demás.
📝 Ejercicios:
- Determinar si 3 vectores de \(\mathbb{C}^3\) son linealmente independientes → Problema B-8. Determinación de independencia lineal
B.2 Producto interno — Definir "longitud" y "ángulo" en el mundo de los números complejos¶
🟡 Lina: Solo con un espacio vectorial no tenemos conceptos de "longitud" ni "ortogonalidad". Para definirlos introducimos el producto interno.
🟡 Lina: A partir de aquí introduzco la notación de Dirac, que es la estándar en mecánica cuántica. ¿Por qué necesitamos una nueva notación? Porque de aquí en adelante escribimos constantemente "vectores", "productos internos" y "acción de operadores", y con la notación \(\mathbf{v}\) o \(\mathbf{v} \cdot \mathbf{w}\) no queda claro dónde actúa el conjugado complejo ni de qué lado actúa un operador. La notación de Dirac hace todo eso visible de un vistazo: es un sistema de "taquigrafía" muy conveniente.
🔵 Kai: Entiendo, así la posición del conjugado complejo queda clara por la propia notación.
🟡 Lina: Un vector se escribe \(|\psi\rangle\) y se llama ket. La parte \(\psi\) es una etiqueta (nombre) para distinguir vectores; puede ser \(|v\rangle\), \(|\alpha\rangle\) o lo que sea — es el mismo vector que antes escribíamos \(\mathbf{v}\), solo con otra notación. De aquí en adelante usaré esta notación de Dirac \(|\psi\rangle\) como estándar en lugar de la negrita \(\mathbf{v}\). Y para calcular productos internos necesitamos un "compañero que va a la izquierda": se escribe \(\langle\psi|\) y se llama bra. En el caso de \(\mathbb{C}^N\), si el ket es el vector columna \(\begin{pmatrix} z_1 \\ \vdots \\ z_N \end{pmatrix}\), el bra correspondiente es el vector fila con las componentes conjugadas \(\begin{pmatrix} z_1^* & \cdots & z_N^* \end{pmatrix}\). Es decir, la conversión "ket → bra" consiste en "transponer el vector columna a fila y tomar el conjugado complejo de cada componente". Al juntar bra y ket, \(\langle\psi|\psi'\rangle\) representa el producto interno — el nombre viene de separar "bracket" (paréntesis) en bra-c-ket.
🔵 Kai: Entonces, ¿simplemente reescribo \(\mathbf{v}\) como \(|v\rangle\)? Y al juntar \(\langle\psi|\) con \(|\psi'\rangle\) en \(\langle\psi|\psi'\rangle\) se forma un bracket (paréntesis) — por eso bra-ket. ¿Y como el conjugado complejo queda incorporado en la propia notación, es más difícil equivocarse al escribir?
🟡 Lina: Exacto. Ahora paso a la definición del producto interno. Para dos vectores \(|\psi\rangle\) y \(|\psi'\rangle\), una regla que asigna un número complejo \(\langle\psi|\psi'\rangle\) se llama producto interno. Pero debe satisfacer las siguientes 3 propiedades.
(1) Positividad definida (no-negatividad):
(2) Hermiticidad (simetría conjugada):
(3) Linealidad en el segundo argumento:
🔵 Kai: ¿La "positividad definida" (1) significa básicamente que "el producto interno de un vector consigo mismo es siempre no negativo, y solo es cero cuando el propio vector es cero"?
🟡 Lina: Exactamente. Si el "cuadrado de la longitud" pudiera ser negativo, sería un problema, ¿no? Por eso exigimos al producto interno la condición de que "al tomar el producto interno consigo mismo siempre sea no negativo". Y la (2), "hermiticidad" —
🔵 Kai: ¿La (2) significa que al intercambiar izquierda y derecha aparece el conjugado complejo?
🟡 Lina: Sí. Con vectores reales \(\mathbf{a} \cdot \mathbf{b} = \mathbf{b} \cdot \mathbf{a}\), intercambiar da lo mismo, pero en el mundo complejo al intercambiar aparece el conjugado complejo. Esta es la diferencia decisiva entre el espacio real y el complejo.
🔵 Kai: Oye, si combino (2) y (3), ¿qué pasa cuando hay una constante multiplicando el primer argumento (lado izquierdo)?
🟡 Lina: Buena pregunta. Vamos a derivarlo. Consideremos \(\langle c\psi|\phi\rangle\). Primero, usando la hermiticidad (2) intercambiamos izquierda y derecha:
Luego, por la linealidad en el segundo argumento (3): \(\langle\phi|c\psi\rangle = c\langle\phi|\psi\rangle\), así que
En el último paso usé de nuevo (2). Es decir, respecto al primer argumento es antilineal — al sacar la constante aparece su conjugado complejo. La misma lógica se aplica a una combinación lineal de dos términos. Considerando \(\langle c_1\psi_1 + c_2\psi_2|\psi\rangle\): primero intercambiamos con hermiticidad (B.7) para obtener \(\langle\psi|c_1\psi_1 + c_2\psi_2\rangle^*\), luego con linealidad en el segundo argumento (B.8) queda \(\bigl(c_1\langle\psi|\psi_1\rangle + c_2\langle\psi|\psi_2\rangle\bigr)^*\), y tomando el conjugado de cada término:
Simplemente usamos \(\langle c_i\psi_i|\psi\rangle = c_i^*\langle\psi_i|\psi\rangle\) en cada término. Esto se usa constantemente en los cálculos de mecánica cuántica, así que asegúrate de recordarlo bien.
⚪ Mei: Del lado derecho la constante sale directamente, pero del lado izquierdo aparece el conjugado complejo — el tratamiento izquierda-derecha es asimétrico.
✅ Verificación de comprensión: Cuando un escalar \(c\) multiplica al primer argumento (lado del bra) del producto interno, ¿qué ocurre al sacarlo fuera?
Respuesta
Aparece el conjugado complejo \(c^*\). Es decir, \(\langle c\psi|\phi\rangle = c^*\langle\psi|\phi\rangle\). Esto se llama "antilinealidad" respecto al primer argumento, y es asimétrico respecto a la linealidad del segundo argumento (donde \(c\) sale tal cual).
Ejemplo concreto: producto interno en \(\mathbb{C}^N\)¶
🟡 Lina: En el caso de \(\mathbb{C}^N\), el producto interno se define de forma natural. Para dos vectores
tenemos
🔵 Kai: Se parece al producto escalar del bachillerato \(\mathbf{a} \cdot \mathbf{b} = a_1 b_1 + a_2 b_2 + \cdots\), pero con el conjugado complejo \(z_k^*\) del lado izquierdo.
🟡 Lina: Así es. Si los números son reales, \(z_k^* = z_k\) y coincide con el producto escalar del bachillerato. Al extender a complejos se necesita el conjugado complejo para garantizar \(\langle\psi|\psi\rangle \geq 0\).
Cada término \(|z_k|^2\) es no negativo, por lo que la suma también lo es. Si no pusiéramos el conjugado complejo, \(z_k^2\) podría ser negativo o imaginario y no serviría como "cuadrado de la longitud".
Norma, ortogonalidad y normalización¶
🟡 Lina: Una vez definido el producto interno, automáticamente obtenemos 3 conceptos importantes.
Norma (longitud):
Ortogonalidad:
Normalización:
🔵 Kai: ¿Entonces lo que en el bachillerato llamábamos "vector unitario" es un "vector normalizado"?
🟡 Lina: Exactamente. Cualquier vector no nulo \(|\psi\rangle\) se puede normalizar dividiendo por:
🟡 Lina: Y hay otra desigualdad importante. La desigualdad de Schwarz (Cauchy–Schwarz):
Es la versión compleja de la desigualdad de Cauchy–Schwarz que aprendiste en el bachillerato. La igualdad se cumple solo cuando \(|\psi\rangle\) y \(|\psi'\rangle\) son paralelos (uno es múltiplo escalar del otro).
✅ Verificación de comprensión: ¿Por qué el conjugado complejo aparece en el primer argumento de la definición del producto interno?
Respuesta
Para garantizar \(\langle\psi|\psi\rangle = \sum_k |z_k|^2 \geq 0\). Sin el conjugado complejo, \(\langle\psi|\psi\rangle\) podría ser negativo o imaginario y no tendría sentido como "cuadrado de la longitud".
📝 Ejercicios:
- Calcular la norma del vector \(|\psi\rangle = \begin{pmatrix} 1+i \\ 2 \end{pmatrix}\) en \(\mathbb{C}^2\) y normalizarlo → Problema B-1. Cálculo de la norma de un vector en \(\mathbb{C}^2\)
B.3 Base ortonormal y relación de completitud — "Descomponer en componentes" cualquier vector¶
🟡 Lina: Entre todas las bases, la más conveniente es la base ortonormal (orthonormal basis).
🟡 Lina: Una base \(\{|e_1\rangle, |e_2\rangle, \ldots, |e_N\rangle\}\) es ortonormal si satisface
donde \(\delta_{jk}\) es la delta de Kronecker:
🔵 Kai: Es decir, una base con "longitud 1 y mutuamente ortogonal".
🟡 Lina: Exacto. Con una base ortonormal, calcular las componentes se vuelve muy sencillo. Expandiendo un vector arbitrario \(|\psi\rangle\):
Los coeficientes de expansión \(c_k\) se obtienen simplemente multiplicando por la izquierda con \(\langle e_j|\):
⚪ Mei: Gracias a la ortonormalidad, de toda la suma solo sobrevive el término con \(k = j\).
🟡 Lina: Así es. Por lo tanto
Como esto vale para cualquier \(|\psi\rangle\), el contenido del paréntesis es igual al operador identidad \(\hat{1}\):
🔵 Kai: ¡Ah, como vale para cualquier vector, se convierte en \(\hat{1}\)!
🟡 Lina: Esto se llama relación de completitud (completeness relation). Es una de las identidades que más se usan en mecánica cuántica. Es la expresión matemática de que "cualquier vector puede expandirse en la base ortonormal".
🔵 Kai: \(|e_k\rangle\langle e_k|\) es un ket junto a un bra, ¿verdad? ¿Qué es eso?
🟡 Lina: Buena pregunta. \(|e_k\rangle\langle e_k|\) se llama operador de proyección (projection operator), y es un operador que "proyecta" un vector en la dirección de \(|e_k\rangle\). Lo trataremos en detalle en la siguiente sección, pero por ahora recuerda que "la relación de completitud descompone \(\hat{1}\) como suma de operadores de proyección".
✅ Verificación de comprensión: Con una base ortonormal, ¿cómo se obtiene el coeficiente de expansión \(c_j\) del vector \(|\psi\rangle\)?
Respuesta
\(c_j = \langle e_j|\psi\rangle\). Gracias a la ortonormalidad \(\langle e_j|e_k\rangle = \delta_{jk}\), basta multiplicar ambos lados de \(|\psi\rangle = \sum_k c_k |e_k\rangle\) por la izquierda con \(\langle e_j|\) para extraer \(c_j\).
Ortogonalización de Gram–Schmidt¶
🟡 Lina: Incluso si la base dada no es ortonormal, se puede convertir en una base ortonormal mediante el método de ortogonalización de Gram–Schmidt. El procedimiento es el siguiente.
A partir de vectores linealmente independientes \(\{|v_1\rangle, |v_2\rangle, \ldots, |v_N\rangle\}\) construimos un sistema ortonormal \(\{|e_1\rangle, |e_2\rangle, \ldots, |e_N\rangle\}\):
Paso 1: Normalizar \(|v_1\rangle\).
Paso 2: Restar de \(|v_2\rangle\) la componente en la dirección de \(|e_1\rangle\) y normalizar.
Paso \(k\): Restar de \(|v_k\rangle\) las componentes en las direcciones de \(|e_1\rangle, \ldots, |e_{k-1}\rangle\) ya construidos, y normalizar.
🔵 Kai: O sea, en cada paso "resto la proyección sobre los vectores ortonormales ya construidos". Pero, ¿no podría ocurrir que \(|w_k\rangle\) sea el vector cero?
🟡 Lina: Buena pregunta. \(|w_k\rangle = \mathbf{0}\) ocurre cuando \(|v_k\rangle\) puede escribirse como combinación lineal de los vectores anteriores \(|v_1\rangle, \ldots, |v_{k-1}\rangle\) — es decir, cuando el conjunto original no es linealmente independiente. Si partimos de un conjunto linealmente independiente, en cada paso se garantiza que \(|w_k\rangle \neq \mathbf{0}\).
⚪ Mei: Así, en cada paso el nuevo vector es ortogonal a todos los anteriores, y al normalizar al final su norma es 1.
✅ Verificación de comprensión: ¿Cuál es el significado físico de la relación de completitud \(\sum_k |e_k\rangle\langle e_k| = \hat{1}\)?
Respuesta
Que la base ortonormal \(\{|e_k\rangle\}\) "genera" todo el espacio, y cualquier vector puede expandirse completamente en esta base. No hay "fugas" en la expansión.
📝 Ejercicios:
- Realizar la ortogonalización de Gram–Schmidt en \(\mathbb{C}^2\) → Problema M-1. Método de ortogonalización de Gram–Schmidt
B.4 Operadores lineales y representación matricial — Transformar un vector en otro¶
🟡 Lina: Lo siguiente son los operadores lineales (linear operators). Son "reglas de transformación" que toman un vector como entrada y devuelven otro vector.
🟡 Lina: Un operador \(\hat{A}\) es lineal si para cualesquiera vectores \(|\psi_1\rangle, |\psi_2\rangle\) y números complejos \(c_1, c_2\) se cumple
"Transforma una combinación lineal de entradas en la combinación lineal de las salidas" — eso es la linealidad.
🔵 Kai: ¿El "sombrerito" en \(\hat{A}\) es para distinguirlo de los vectores?
🟡 Lina: Sí. Los vectores son \(|\psi\rangle\), los operadores son \(\hat{A}\). Aunque cuando el contexto lo deja claro, a veces se omite el sombrerito.
Representación matricial¶
🟡 Lina: Si elegimos una base ortonormal \(\{|e_1\rangle, \ldots, |e_N\rangle\}\), un operador lineal \(\hat{A}\) se representa como una matriz de \(N \times N\).
Definimos los elementos de matriz (matrix elements) de \(\hat{A}\) como
Entonces \(\hat{A}\) se representa por la matriz
El símbolo \(\doteq\) se usa con el significado de "es la representación matricial en esta base". Uso \(\doteq\) en lugar del signo de igualdad ordinario \(=\) porque un mismo operador tiene valores numéricos diferentes en la matriz si se cambia la base — el "operador en sí" y "su representación matricial en una base elegida" son cosas distintas. Algunos libros usan \(=\) o \(\leftrightarrow\), pero en este libro unificaremos con \(\doteq\).
🔵 Kai: Nunca había visto \(\doteq\). Entonces significa "si fijas la base, te da esta matriz". ¿Y si cambias la base, cambia la matriz?
🟡 Lina: Cambia. Por ejemplo, en el bachillerato aprendiste que si rotas el sistema de coordenadas xyz 45°, las componentes numéricas de un mismo vector cambian, ¿verdad? Es lo mismo: al cambiar la base, cambian los valores numéricos de la matriz.
🔵 Kai: Ah, ¿es como las proyecciones cartográficas? En la proyección de Mercator y en la de Mollweide los continentes se ven diferentes, pero la Tierra en sí no cambia.
🟡 Lina: Exactamente así. El operador en sí es una entidad abstracta que no depende de la base — la matriz es solo una "representación en una base particular". Cómo cambia concretamente lo veremos en B.7 como "transformación unitaria". Este \(\doteq\) lo usaremos también en el texto principal al escribir representaciones matriciales, así que recuérdalo.
⚪ Mei: Es decir, la apariencia de la matriz depende de la base, pero el operador como entidad abstracta es único.
✅ Verificación de comprensión: ¿Cuál es la relación entre la "representación matricial" y "el operador en sí" de un operador lineal?
Respuesta
La representación matricial es la "representación" del operador al elegir una base ortonormal particular; si se cambia la base, cambia la matriz. Sin embargo, el operador en sí es una entidad abstracta que no depende de la base. Es lo mismo que un vector no cambia aunque se cambie el sistema de coordenadas.
Producto de operadores y relaciones de conmutación¶
🟡 Lina: El producto de dos operadores \(\hat{A}\) y \(\hat{B}\), \(\hat{A}\hat{B}\), significa "primero actúa \(\hat{B}\), luego actúa \(\hat{A}\)". En la representación matricial corresponde al producto de matrices.
🔵 Kai: ¿Cómo se calcula el producto de matrices?
🟡 Lina: Primero vamos a tomar intuición con valores numéricos concretos. Sean \(A = \begin{pmatrix} 1 & 2 \\ 0 & 3 \end{pmatrix}\), \(B = \begin{pmatrix} 1 & 0 \\ 1 & 1 \end{pmatrix}\); calculemos cada componente de \(AB\). La regla es: "la componente \((j, k)\) del resultado es el producto componente a componente de la fila \(j\) de la matriz izquierda con la columna \(k\) de la matriz derecha, sumados". Por ejemplo, la componente superior izquierda es el producto escalar de la fila 1 de \(A\), \((1, 2)\), con la columna 1 de \(B\), \(\begin{pmatrix} 1 \\ 1 \end{pmatrix}\): \(1 \cdot 1 + 2 \cdot 1 = 3\). La componente \((1,2)\) es el producto escalar de la fila 1 de \(A\), \((1, 2)\), con la columna 2 de \(B\), \(\begin{pmatrix} 0 \\ 1 \end{pmatrix}\): \(1 \cdot 0 + 2 \cdot 1 = 2\).
🔵 Kai: Ah, ya veo el patrón. \((2,1)\) es la fila 2 de \(A\), \((0, 3)\), con la columna 1 de \(B\), \(\begin{pmatrix} 1 \\ 1 \end{pmatrix}\): \(0 \cdot 1 + 3 \cdot 1 = 3\); \((2,2)\) es la fila 2 de \(A\) con la columna 2 de \(B\): \(0 \cdot 0 + 3 \cdot 1 = 3\). Entonces \(AB = \begin{pmatrix} 3 & 2 \\ 3 & 3 \end{pmatrix}\).
🟡 Lina: Correcto. Para el caso general \(2 \times 2\): \(\begin{pmatrix} a & b \\ c & d \end{pmatrix}\begin{pmatrix} e & f \\ g & h \end{pmatrix} = \begin{pmatrix} ae+bg & af+bh \\ ce+dg & cf+dh \end{pmatrix}\), y para matrices \(N \times N\) \(A\) y \(B\), la componente \((j, k)\) es \(\sum_{l=1}^N A_{jl} B_{lk}\).
🔵 Kai: Entiendo, es calcular el producto escalar de fila y columna en cada posición. Pero, ¿por qué tiene que ser esta regla? Me parece que viene de la nada.
🟡 Lina: Buena pregunta. En realidad esta regla no viene de la nada, sino que surge naturalmente al representar con matrices el concepto abstracto de "producto de operadores". Piensa: el operador \(\hat{A}\hat{B}\) es la operación "primero aplica \(\hat{B}\), luego aplica \(\hat{A}\)", ¿verdad? Queremos calcular esta operación como elemento de matriz \(\langle e_j|\hat{A}\hat{B}|e_k\rangle\). Pero con \(\hat{A}\) y \(\hat{B}\) pegados directamente no podemos descomponer. Ahí es donde usamos la relación de completitud de B.3. Insertamos \(\hat{1} = \sum_l |e_l\rangle\langle e_l|\) entre \(\hat{A}\) y \(\hat{B}\). \(\hat{1}\) es el operador identidad — es decir, no cambia nada cuando actúa — por lo que \(\hat{A}\hat{B} = \hat{A}\,\hat{1}\,\hat{B}\). Es como en el mundo de los números: \(a \times 1 \times b = ab\). "Insertar 1 en medio no cambia el valor, pero al reescribir \(\hat{1}\) como \(\sum_l |e_l\rangle\langle e_l|\) se descompone en una suma" — esa es la esencia del truco de insertar la relación de completitud. Veámoslo explícitamente:
Esto es precisamente la forma general del "producto escalar de la fila \(j\) con la columna \(k\)". Es decir, la regla del producto de matrices se deduce naturalmente de la relación de completitud.
🔵 Kai: ¡Ah, la regla del producto de matrices no viene de la nada, sale de la relación de completitud! Al sumar sobre todos los \(|e_l\rangle\) insertados, el "producto escalar de fila y columna" aparece naturalmente... Pero espera un momento. Si la base no generara todo el espacio — es decir, si la relación de completitud no se cumpliera — entonces el \(\hat{1}\) que insertamos no sería el verdadero operador identidad, y toda esta derivación se derrumbaría, ¿no?
🟡 Lina: Muy agudo. Exacto. La relación de completitud es la expresión de que "la base agota el espacio", así que si eso falla, el \(\hat{1}\) insertado no es el verdadero operador identidad. Por eso usar un sistema ortonormal completo es un prerrequisito.
⚪ Mei: Es decir, insertar \(\hat{1}\) no cambia el valor, pero al reescribirlo como \(\sum_l |e_l\rangle\langle e_l|\) se descompone en una suma — y por eso la regla del producto de matrices surge naturalmente.
🔵 Kai: Por cierto, ¿\(\hat{A}\hat{B}\) y \(\hat{B}\hat{A}\) dan el mismo resultado? En la multiplicación de números \(3 \times 5 = 5 \times 3\), pero con matrices parece que el "camino" cambia si se invierte el orden.
🟡 Lina: Buena pregunta. En general \(\hat{A}\hat{B} \neq \hat{B}\hat{A}\). El producto de operadores depende del orden. Lo que cuantifica esta "diferencia de orden" es el conmutador (commutator):
Cuando \([\hat{A}, \hat{B}] = 0\) decimos que "\(\hat{A}\) y \(\hat{B}\) conmutan".
🔵 Kai: Con números la multiplicación es \(ab = ba\) y se puede cambiar el orden, pero con matrices u operadores no siempre es así. Aunque todavía no entiendo bien qué significa físicamente que no conmuten.
🟡 Lina: Buena intuición. En mecánica cuántica, los pares de operadores que no conmutan juegan un papel esencial. El principio de incertidumbre — "no se pueden medir dos magnitudes físicas simultáneamente con precisión arbitraria" — se deduce precisamente de las relaciones de conmutación (lo veremos en detalle en Cap. 8).
✅ Verificación de comprensión: ¿Qué significa que dos operadores \(\hat{A}, \hat{B}\) "conmuten"?
Respuesta
\([\hat{A}, \hat{B}] = \hat{A}\hat{B} - \hat{B}\hat{A} = 0\), es decir, que al intercambiar el orden de aplicación el resultado no cambia.
Conjugado hermitiano (operador adjunto)¶
🟡 Lina: Los operadores tienen una operación análoga a "darle la vuelta". Así como en el mundo de los números existe el conjugado complejo \(z \to z^*\), en el mundo de los operadores también hay un "conjugado". Es el conjugado hermitiano.
🟡 Lina: Para un operador \(\hat{A}\), el operador \(\hat{A}^\dagger\) que satisface, para cualesquiera vectores \(|\psi\rangle, |\phi\rangle\),
se llama conjugado hermitiano (Hermitian conjugate) u operador adjunto (adjoint) de \(\hat{A}\). En palabras: "el producto interno con \(\langle\phi|\) a la izquierda, \(|\psi\rangle\) a la derecha y \(\hat{A}^\dagger\) en medio" es igual al "conjugado complejo del producto interno con \(\langle\psi|\) a la izquierda, \(|\phi\rangle\) a la derecha y \(\hat{A}\) en medio" — es decir, en vez de poner la daga al operador, puedes intercambiar bra y ket y tomar el conjugado complejo y obtienes el mismo valor.
🔵 Kai: Poner la daga \(\dagger\) intercambia los vectores izquierdo y derecho y añade conjugado complejo — tiene una estructura similar a la hermiticidad del producto interno (B.7).
🟡 Lina: En representación matricial, el conjugado hermitiano corresponde a "transponer y tomar conjugado complejo":
⚪ Mei: Se intercambian filas y columnas (transposición) y además se toma el conjugado complejo de cada componente.
🟡 Lina: Resumo las propiedades importantes del conjugado hermitiano.
🔵 Kai: ¡En la última ecuación el orden se invierte!
🟡 Lina: Así es. Es como ponerse y quitarse calcetines y zapatos: el orden se invierte. El conjugado hermitiano de un producto invierte el orden. Esto se usa muchísimo, así que recuérdalo bien.
✅ Verificación de comprensión: ¿Cuál es el conjugado hermitiano del producto de operadores \(\hat{A}\hat{B}\), \((\hat{A}\hat{B})^\dagger\)?
Respuesta
\((\hat{A}\hat{B})^\dagger = \hat{B}^\dagger \hat{A}^\dagger\). En el conjugado hermitiano de un producto, el orden se invierte.
📝 Ejercicios:
- Hallar el conjugado hermitiano \(\hat{A}^\dagger\) de \(\hat{A} = \begin{pmatrix} 1 & 2+i \\ 3 & 4i \end{pmatrix}\) → Problema B-6. Cálculo del conjugado hermítico
B.5 Valores propios y vectores propios — Encontrar las "direcciones especiales" de un operador¶
🟡 Lina: Cuando se aplica un operador lineal (transformación lineal) \(\hat{A}\), en general cambian tanto la dirección como la magnitud de un vector. Pero para vectores especiales, la dirección no cambia y la magnitud simplemente se multiplica por el valor propio \(a\). En fórmulas:
A \(a\) lo llamamos valor propio (eigenvalue) y a \(|a\rangle\) vector propio (eigenvector). Mira Fig. B.1「Significado geométrico del vector propio en una transformación lineal」. Un vector general \(|v\rangle\) al aplicarle \(\hat{A}\) cambia tanto su dirección como su magnitud. Pero el vector propio \(|a\rangle\) es especial: conserva su dirección y solo su magnitud se multiplica por \(a\).
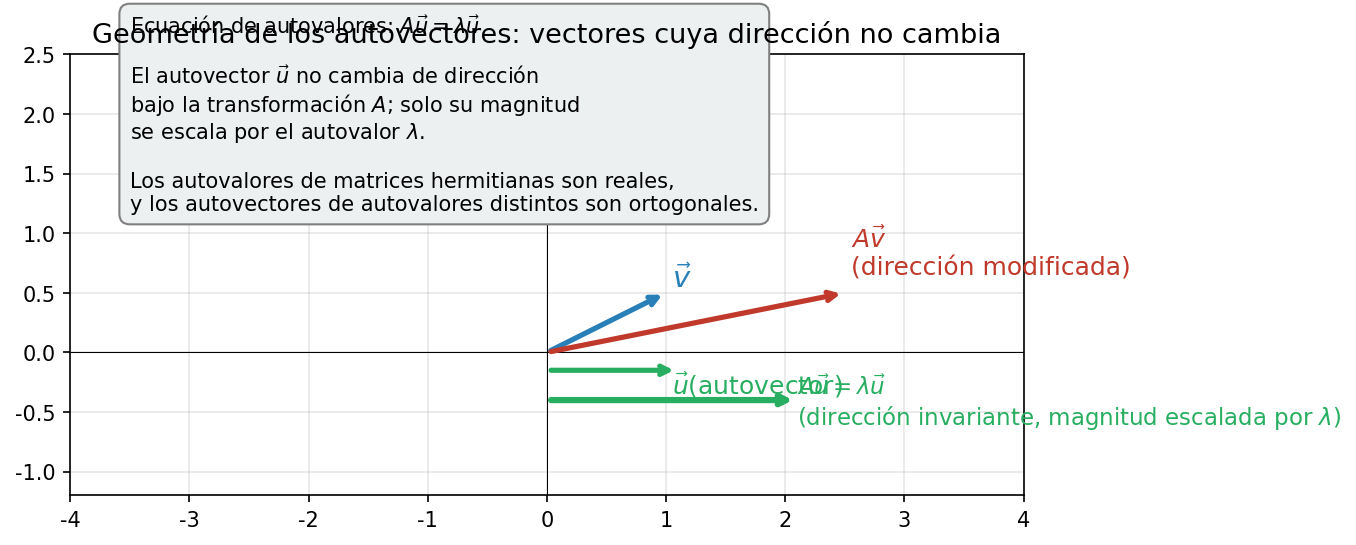
Fig. B.1: Significado geométrico del vector propio en una transformación lineal. Para la transformación lineal \(\hat{A}\), un vector general \(|v\rangle\) cambia tanto en dirección como en magnitud. Sin embargo, el vector propio \(|a\rangle\) conserva su dirección y solo su magnitud cambia por un factor \(a\) (el valor propio).
🔵 Kai: Mirando Fig. B.1「Significado geométrico del vector propio en una transformación lineal」, un vector general cambia de dirección y magnitud, pero el vector propio solo se estira o contrae manteniendo su dirección. Pero si el valor propio \(a\) es negativo, la dirección se invierte, ¿no? ¿Se puede seguir diciendo que "la dirección no cambia"?
🟡 Lina: Observación aguda. Hablando con precisión, si el valor propio es negativo la orientación se invierte — pero decimos "la dirección no cambia" en el sentido de que "permanece sobre la misma recta". Un vector general es lanzado a una dirección completamente distinta, pero el vector propio permanece sobre su recta original. Es la propiedad de "misma recta" lo que es esencial.
🟡 Lina: Exacto. Al aplicar \(\hat{A}\) solo se multiplica por \(a\). En mecánica cuántica, los valores propios corresponden a los "valores que se obtienen en una medición" y los vectores propios al "estado tras la medición" (lo veremos en detalle en Cap. 12).
Cómo encontrar los valores propios — Ecuación característica¶
🟡 Lina: La ecuación de valores propios (B.36) puede reescribirse como
Este es un sistema de ecuaciones lineales con \(|a\rangle\) como incógnita y el lado derecho todo cero — lo que se llama un sistema lineal homogéneo. \(|a\rangle = \mathbf{0}\) (todas las componentes cero) es siempre solución, pero lo que tiene sentido como vector propio es el caso \(|a\rangle \neq \mathbf{0}\).
🔵 Kai: ¿Hay alguna condición para que exista una solución no nula?
🟡 Lina: Buena pregunta. Aquí hay un teorema importante: un sistema homogéneo tiene solución no nula si y solo si el determinante de la matriz de coeficientes es cero. Te lo explico paso a paso. Primero introduzco el concepto de matriz inversa. En el mundo de los números, para el 3 existe \(\frac{1}{3}\) tal que \(3 \times \frac{1}{3} = 1\) — ese "compañero que al multiplicar da 1". Lo llamamos inverso. Con matrices es igual: para una matriz \(M\), si existe una matriz \(M^{-1}\) tal que \(M^{-1}M = MM^{-1} = \hat{1}\), llamamos a \(M^{-1}\) la matriz inversa (inverse matrix) de \(M\). Aquí \(\hat{1}\) es el operador identidad — el mismo de la relación de completitud de B.3; en representación matricial se escribe también como matriz identidad (identity matrix) \(I_N\). Para \(2 \times 2\) es \(\begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix}\); para \(N \times N\) general tiene todos los 1 en la diagonal y 0 fuera. Es la matriz que no cambia ningún vector al actuar — es decir, \(I_N \begin{pmatrix} v_1 \\ \vdots \\ v_N \end{pmatrix} = \begin{pmatrix} v_1 \\ \vdots \\ v_N \end{pmatrix}\).
🔵 Kai: ¿La matriz inversa es como "la división de matrices"?
🟡 Lina: Sí, buena imagen. Si la matriz inversa existe, multiplicando ambos lados de \(M|a\rangle = \mathbf{0}\) por la izquierda con \(M^{-1}\) obtenemos \(|a\rangle = M^{-1}\mathbf{0} = \mathbf{0}\) (¿por qué \(M^{-1}\mathbf{0} = \mathbf{0}\)? Porque en la definición del producto matricial \((AB)_{jk} = \sum_l A_{jl}B_{lk}\), las componentes del vector cero son todas 0, así que el producto escalar con cualquier fila da 0). Es decir, si existe la inversa "solo hay solución trivial".
🔵 Kai: Entonces, para que exista un vector propio no nulo, ¡la matriz inversa no debe existir!
🟡 Lina: Correcto. Y lo que determina "si la inversa existe o no" es el determinante (determinant). Primero explico qué es el determinante. Para una matriz \(2 \times 2\) \(M = \begin{pmatrix} a & b \\ c & d \end{pmatrix}\), el determinante se define como
Geométricamente, es igual al área con signo del paralelogramo formado por los dos vectores columna \(\begin{pmatrix} a \\ c \end{pmatrix}\) y \(\begin{pmatrix} b \\ d \end{pmatrix}\) de \(M\).
🔵 Kai: ¿Que el área sea cero significa que los dos vectores apuntan en la misma dirección?
🟡 Lina: Exacto. Los dos vectores columna son paralelos — es decir, uno es múltiplo escalar del otro. En ese caso la matriz \(M\) aplasta todos los vectores del plano sobre una sola recta. Una vez aplastados no se puede "recuperar de dónde venían", por lo que la matriz inversa no existe. Y la dirección que se aplasta — la dirección donde aplicar \(M\) da cero — existe, por lo que \(M|a\rangle = \mathbf{0}\) admite una solución no nula \(|a\rangle\).
⚪ Mei: "Área cero ⇔ se aplasta ⇔ no hay inversa" — todo se conecta con la imagen geométrica.
🟡 Lina: Resumiendo, determinante cero ⇔ no existe la inversa ⇔ se admiten soluciones no nulas. Por lo tanto, la condición para que la ecuación de valores propios \((\hat{A} - a\hat{1})|a\rangle = 0\) tenga solución no nula es
Esto corresponde, en la geometría del bachillerato, al "área con signo del paralelogramo formado por los dos vectores columna \(\begin{pmatrix} p \\ r \end{pmatrix}\) y \(\begin{pmatrix} q \\ s \end{pmatrix}\) de la matriz". Área cero = los dos vectores son paralelos = la matriz se aplasta.
Para \(3 \times 3\) es un poco más largo, pero explico el método de expansión por la primera fila. Así como el determinante \(2 \times 2\) era "el área del paralelogramo formado por las 2 columnas", el determinante \(3 \times 3\) corresponde al "volumen del paralelepípedo formado por las 3 columnas". Si el volumen es cero, los 3 vectores están en un mismo plano — es decir, la matriz aplasta el espacio 3D a 2D — y por la misma lógica del caso \(2 \times 2\) no existe la inversa. Como método de cálculo: para cada componente \(a, b, c\) de la primera fila, se calcula "el determinante de la submatriz \(2 \times 2\) que queda al eliminar la fila y columna de esa componente", multiplicado con signos alternados \(+, -, +\). Concretamente:
- Contribución de \(a\): eliminando la fila de \(a\) (fila 1) y su columna (columna 1) queda \(\begin{pmatrix} e & f \\ h & i \end{pmatrix}\) → \(+a(ei - fh)\)
- Contribución de \(b\): eliminando la fila de \(b\) (fila 1) y su columna (columna 2) queda \(\begin{pmatrix} d & f \\ g & i \end{pmatrix}\) → \(-b(di - fg)\)
- Contribución de \(c\): eliminando la fila de \(c\) (fila 1) y su columna (columna 3) queda \(\begin{pmatrix} d & e \\ g & h \end{pmatrix}\) → \(+c(dh - eg)\)
En resumen:
Los signos alternan \(+, -, +\) porque el signo de la componente \((j,k)\) viene dado por \((-1)^{j+k}\) (para la fila 1: \((-1)^{1+1} = +\), \((-1)^{1+2} = -\), \((-1)^{1+3} = +\)). Este procedimiento se llama expansión por cofactores (cofactor expansion) (también apareció en el apéndice A de Relatividad General). Para el alcance de este libro, basta con saber calcular determinantes \(2 \times 2\) y \(3 \times 3\).
🟡 Lina: A la ecuación (B.38) la llamamos ecuación característica (characteristic equation).
🔵 Kai: A ver, la razón por la que el determinante tiene que ser cero es... si no es cero existe la inversa y \(|a\rangle = (\hat{A} - a\hat{1})^{-1} \mathbf{0} = \mathbf{0}\) es la única solución, ¿no? Pero, ¿siempre se puede encontrar un valor de \(a\) que haga el determinante cero?
🟡 Lina: La primera parte es correcta. Si existe la inversa, la solución se restringe a \(\mathbf{0}\). Por eso, para que "exista un vector propio no nulo" la inversa no debe existir — es decir, el determinante debe ser cero. La segunda pregunta también es buena. Para una matriz \(N \times N\), \(\det(\hat{A} - a\hat{1}) = 0\) es una ecuación de grado \(N\) en \(a\), así que en el campo de los complejos siempre existen \(N\) soluciones (valores propios). Esto es consecuencia de un teorema matemático llamado teorema fundamental del álgebra — en el bachillerato aprendiste que "una ecuación de segundo grado siempre tiene 2 soluciones en los complejos incluso cuando el discriminante es negativo", ¿verdad? Es la generalización a grado \(N\); la demostración es avanzada pero basta con usar el resultado. Es decir, recuerda que "una matriz \(N \times N\) tiene siempre \(N\) valores propios contando multiplicidades".
Ejemplo concreto: la matriz de Pauli \(\sigma_z\)¶
🟡 Lina: Practiquemos con un ejemplo concreto en 2 dimensiones. Una de las matrices de Pauli que aparecen en Cap. 5 y Cap. 17:
Encuentra sus valores propios y vectores propios.
🔵 Kai: La ecuación característica es
así que \(a = +1\) y \(a = -1\).
🔵 Kai: Para \(a = +1\), resolviendo \((\hat{\sigma}_z - \hat{1})|a\rangle = 0\):
entonces \(\eta = 0\). Normalizando: \(|+\rangle = \begin{pmatrix} 1 \\ 0 \end{pmatrix}\). Para \(a = -1\) hago lo mismo... \(\begin{pmatrix} 2 & 0 \\ 0 & 0 \end{pmatrix}\begin{pmatrix} \xi \\ \eta \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix}\), entonces \(\xi = 0\) y \(|-\rangle = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\).
🔵 Kai: Ah, si calculo el producto interno de los dos vectores propios: \(\langle +|-\rangle = 1 \cdot 0 + 0 \cdot 1 = 0\), son ortogonales. ¿Los vectores propios de valores propios distintos siempre son ortogonales?
🟡 Lina: Buena observación. De hecho, para matrices hermitianas se puede demostrar que siempre son ortogonales. Lo demostraremos en la siguiente sección. Y estos \(|+\rangle\) y \(|-\rangle\) corresponden a los estados "arriba" y "abajo" del espín 1/2.
🔵 Kai: ¿Y para matrices que no son hermitianas podría no haber ortogonalidad?
🟡 Lina: Así es. Para matrices no hermitianas los valores propios pueden ser complejos y no hay garantía de ortogonalidad entre vectores propios. Por eso la condición "ser hermitiana" es tan importante físicamente. Veámoslo en detalle en la siguiente sección.
✅ Verificación de comprensión: ¿Cuántos valores propios tiene como máximo una matriz \(N \times N\)?
Respuesta
\(N\) (contando multiplicidades). Porque la ecuación característica es de grado \(N\) en \(a\).
B.6 Matrices hermitianas — Por qué los valores de medición son reales¶
🟡 Lina: La clase de matrices más importante en mecánica cuántica es la de las matrices hermitianas (Hermitian matrices).
🟡 Lina: Un operador \(\hat{A}\) es hermitiano (o autoadjunto) si
Es decir, al tomar el conjugado hermitiano se recupera el mismo operador. En elementos de matriz:
Las componentes diagonales son reales, y las no diagonales son conjugadas complejas entre sí.
🔵 Kai: ¿Por qué las matrices hermitianas son tan importantes en mecánica cuántica?
🟡 Lina: Hay 2 razones decisivas.
Teorema 1: Los valores propios de un operador hermitiano son reales¶
🟡 Lina: Vamos a demostrarlo. Sea \(\hat{A}|a\rangle = a|a\rangle\); multiplicamos por la izquierda con \(\langle a|\):
Por otro lado, en la definición del conjugado hermitiano (B.30) ponemos \(|\psi\rangle = |\phi\rangle = |a\rangle\) (en el lado izquierdo de (B.30), \(\langle\phi|\hat{A}^\dagger|\psi\rangle\), y en el derecho, \(\langle\psi|\hat{A}|\phi\rangle^*\), ambos con \(|\psi\rangle = |\phi\rangle = |a\rangle\)):
Usando la hermiticidad \(\hat{A}^\dagger = \hat{A}\) en el lado izquierdo:
Por lo tanto \(\langle a|\hat{A}|a\rangle\) es real (es igual a su propio conjugado complejo). De (B.42): \(\langle a|\hat{A}|a\rangle = a\langle a|a\rangle\); el lado izquierdo es real, \(\langle a|a\rangle > 0\) también es real, por lo que \(a\) es real. \(\square\)
🔵 Kai: ¡Solo con usar la hermiticidad se demuestra que los valores propios son reales!
🟡 Lina: Es decir, como los valores de medición deben ser siempre reales, los operadores que representan observables deben ser hermitianos — esa es la razón física para exigir hermiticidad.
⚪ Mei: Ya veo: "valor propio = valor de medición", y si es hermitiano se garantiza que los valores propios son reales — esa es la lógica.
Teorema 2: Los vectores propios de valores propios distintos son ortogonales¶
🟡 Lina: Sean \(\hat{A}|a\rangle = a|a\rangle\) y \(\hat{A}|a'\rangle = a'|a'\rangle\) con \(a \neq a'\).
Por otro lado, tomamos el conjugado hermitiano de \(\hat{A}|a'\rangle = a'|a'\rangle\). "Tomar el conjugado hermitiano de una igualdad" es la operación de reescribir ambos lados en la forma que puede colocarse "a la izquierda de un producto interno" — es decir, en forma de bra (también se dice "convertir una igualdad de kets en una igualdad de bras"). La regla es: en general, el conjugado hermitiano de la igualdad \(\hat{X}|\alpha\rangle = c|\beta\rangle\) es \(\langle\alpha|\hat{X}^\dagger = c^*\langle\beta|\). Lo que ocurre es: el ket \(|\alpha\rangle\) se convierte en bra \(\langle\alpha|\), al operador \(\hat{X}\) se le pone la daga \(\dagger\), y el escalar \(c\) se conjuga a \(c^*\) — esto es la combinación de (B.33) y (B.35). Intuitivamente puedes pensarlo como la versión para operadores de "al intercambiar izquierda y derecha en un producto interno aparece el conjugado complejo" (B.7).
🔵 Kai: Un momento. "Convertir una igualdad de kets en una igualdad de bras", concretamente, ¿qué operación es? ¿Es como transponer ambos lados y tomar conjugado complejo?
🟡 Lina: Buena pregunta. En representación matricial es exactamente eso — reescribir una igualdad de vectores columna como igualdad de vectores fila es transponer y conjugar. Pero en el lenguaje abstracto de operadores se verifica así: considera el producto interno con un vector arbitrario \(|\gamma\rangle\). Multiplicando ambos lados de \(\hat{X}|\alpha\rangle = c|\beta\rangle\) por la izquierda con \(\langle\gamma|\): \(\langle\gamma|\hat{X}|\alpha\rangle = c\langle\gamma|\beta\rangle\). Por la definición del conjugado hermitiano (B.30): \(\langle\gamma|\hat{X}|\alpha\rangle = \langle\alpha|\hat{X}^\dagger|\gamma\rangle^*\), así que tomando el conjugado: \(\langle\alpha|\hat{X}^\dagger|\gamma\rangle = c^*\langle\beta|\gamma\rangle\). Como esto vale para todo \(|\gamma\rangle\), se obtiene \(\langle\alpha|\hat{X}^\dagger = c^*\langle\beta|\).
Aplicando esto a \(\hat{A}|a'\rangle = a'|a'\rangle\) obtenemos \(\langle a'|\hat{A}^\dagger = a'^*\langle a'|\). Por la hermiticidad \(\hat{A}^\dagger = \hat{A}\) y el teorema 1 (\(a'\) es real, así que \(a'^* = a'\)):
Haciendo actuar por la derecha sobre \(|a\rangle\):
Restando (B.44) y (B.45):
Como \(a \neq a'\), se deduce \(\langle a'|a\rangle = 0\). \(\square\)
🔵 Kai: ¡Si los valores propios son diferentes, automáticamente son ortogonales! Pero, ¿qué pasa si hay varios vectores con el mismo valor propio? ¿También son ortogonales?
🟡 Lina: Buena pregunta. Múltiples vectores propios con el mismo valor propio — esto se llama degeneración (degeneracy) — no son automáticamente ortogonales. Pero usando el método de ortogonalización de Gram–Schmidt se pueden ortogonalizar, así que al final siempre se puede construir una base ortonormal con los vectores propios de un operador hermitiano.
✅ Verificación de comprensión: En la demostración de que los vectores propios de un operador hermitiano con distintos valores propios son ortogonales, ¿cuál es el paso clave?
Respuesta
Calcular \(\langle a'|\hat{A}|a\rangle\) de dos formas (haciendo actuar a la derecha: \(a\langle a'|a\rangle\); haciendo actuar a la izquierda: \(a'\langle a'|a\rangle\)), y restando se obtiene \((a - a')\langle a'|a\rangle = 0\). Como \(a \neq a'\), se deduce \(\langle a'|a\rangle = 0\) (ortogonalidad).
Teorema 3 (diagonalización): Toda matriz hermitiana es diagonalizable mediante una transformación unitaria¶
🟡 Lina: Si elegimos como base los vectores propios ortonormales \(\{|a_1\rangle, |a_2\rangle, \ldots, |a_N\rangle\}\) de una matriz hermitiana \(\hat{A}\), la representación matricial de \(\hat{A}\) es
Los valores propios aparecen en la diagonal. Esto se llama diagonalización (diagonalization).
🟡 Lina: En mecánica cuántica, este teorema se escribe frecuentemente en la forma de descomposición espectral (spectral decomposition):
Es la misma forma que la relación de completitud (B.21) con \(|e_k\rangle\langle e_k|\), pero con los valores propios \(a_k\) como "pesos" delante.
⚪ Mei: Es decir, se descompone el operador en una suma de "valor propio × operador de proyección".
🟡 Lina: Exactamente. Esto constituye la base matemática de la medición en mecánica cuántica.
✅ Verificación de comprensión: ¿Qué es la descomposición espectral de un operador hermitiano?
Respuesta
Escribir el operador hermitiano \(\hat{A}\) como \(\hat{A} = \sum_k a_k |a_k\rangle\langle a_k|\). Es la representación que descompone en suma de valores propios \(a_k\) y sus correspondientes operadores de proyección \(|a_k\rangle\langle a_k|\), y constituye la base matemática de la teoría de la medición en mecánica cuántica.
Ejemplo concreto: todas las matrices de Pauli son hermitianas¶
🟡 Lina: Verifiquémoslo.
🔵 Kai: \(\hat{\sigma}_x\) al transponer queda igual y sus componentes son reales, así que \(\hat{\sigma}_x^\dagger = \hat{\sigma}_x\). \(\hat{\sigma}_y\) al transponer la componente \((1,2)\) se vuelve \(i\) y la \((2,1)\) se vuelve \(-i\), pero al tomar además el conjugado complejo vuelve al original. \(\hat{\sigma}_z\) es diagonal con componentes reales, así que es obvio. Todas son hermitianas.
🟡 Lina: Perfecto. Los valores propios son todos \(\pm 1\), reales. Esto se corresponde con que los valores propios del momento angular de espín \(S_i = (\hbar/2)\sigma_i\) son \(\pm\hbar/2\), que son reales.
✅ Verificación de comprensión: ¿Cuál es la ecuación que define la hermiticidad y que se usa al demostrar que los valores propios de un operador hermitiano son reales?
Respuesta
\(\hat{A}^\dagger = \hat{A}\). Gracias a esto, \(\langle a|\hat{A}|a\rangle = a\langle a|a\rangle\) también puede escribirse como \(a^*\langle a|a\rangle\) por el lado izquierdo, de donde se deduce \(a = a^*\) (real).
B.7 Matrices unitarias — Transformaciones que conservan la probabilidad¶
🟡 Lina: Lo siguiente importante son las matrices unitarias (unitary matrices).
Es decir, \(\hat{U}^\dagger = \hat{U}^{-1}\) (la inversa es igual al conjugado hermitiano).
🔵 Kai: Una matriz hermitiana cumple \(\hat{A}^\dagger = \hat{A}\), y una unitaria \(\hat{U}^\dagger = \hat{U}^{-1}\). Se parecen pero son diferentes.
🟡 Lina: Buena comparación. Hermitiana es "igual a sí misma", unitaria es "igual a su inversa". Sus roles físicos también son distintos. Los operadores hermitianos representan observables, y los operadores unitarios representan transformaciones de estados (evolución temporal, cambios de base).
Propiedades importantes de la transformación unitaria¶
🟡 Lina: La razón por la que las transformaciones unitarias son importantes en física es que conservan el producto interno.
Sean \(|\psi'\rangle = \hat{U}|\psi\rangle\), \(|\phi'\rangle = \hat{U}|\phi\rangle\):
⚪ Mei: Si el producto interno no cambia, la norma también se conserva. \(\langle\psi'|\psi'\rangle = \langle\psi|\psi\rangle\).
🟡 Lina: Exacto. Es decir, la condición de normalización \(\langle\psi|\psi\rangle = 1\) se mantiene después de la transformación.
🔵 Kai: Entiendo que la normalización se conserva, pero ¿qué significa eso físicamente?
🟡 Lina: Buena pregunta. En mecánica cuántica, \(|\langle\phi|\psi\rangle|^2\) está relacionado con la probabilidad (lo veremos en detalle en Cap. 5). Que el producto interno se conserve significa que una transformación unitaria es una transformación que conserva la probabilidad.
La matriz unitaria como cambio de base¶
🟡 Lina: La transformación de una base ortonormal \(\{|e_k\rangle\}\) a otra base ortonormal \(\{|e'_k\rangle\}\) se escribe con una matriz unitaria \(\hat{U}\):
Tomando el conjugado hermitiano de (B.52):
Los elementos de matriz del operador \(\hat{A}\) en la nueva base son:
donde sustituimos (B.53) y (B.52). En lenguaje matricial esto es la transformación de semejanza (similarity transformation):
Aquí \(\hat{A}'\) denota la representación matricial del operador \(\hat{A}\) en la nueva base \(\{|e'_k\rangle\}\).
🔵 Kai: Para ver un operador en otra base, lo "envolvemos" con la matriz unitaria por ambos lados.
🟡 Lina: Hay cantidades que no cambian bajo la transformación de semejanza. La traza (trace, suma de los elementos diagonales), el determinante y los valores propios.
🔵 Kai: Es tranquilizador que los valores propios no dependan de la base. Sería un problema si los resultados de medición cambiaran según la elección del sistema de coordenadas.
🟡 Lina: Exacto. Los resultados de medición de una magnitud física no dependen de la "elección de base" del observador — ese es el significado físico de la transformación unitaria.
✅ Verificación de comprensión: Nombre 3 cantidades de una matriz que no cambian bajo una transformación unitaria (de semejanza).
Respuesta
Traza (suma de elementos diagonales), determinante y valores propios. Estos son invariantes que no dependen de la elección de base, y garantizan que los resultados de medición no dependen de la elección de base del observador.
Ejemplo concreto: transformación de la base de \(S_z\) a la base de \(S_x\)¶
🟡 Lina: Adelanto un ejemplo de espín que veremos en Cap. 5. De los vectores propios de \(S_z\), \(|+\rangle = \begin{pmatrix} 1 \\ 0 \end{pmatrix}\), \(|-\rangle = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\), a los vectores propios de \(S_x\):
la matriz de transformación es
🔵 Kai: Voy a verificar. Como todas las componentes son reales, el conjugado complejo no cambia nada. Y al intercambiar filas y columnas da la misma forma... ¿entonces \(\hat{U}^\dagger = \hat{U}\)?
🟡 Lina: Sí. Esta matriz tiene componentes reales y además es simétrica (igual a su transpuesta), por lo que \(\hat{U}^\dagger = \hat{U}\). Entonces la condición de unitariedad \(\hat{U}^\dagger \hat{U} = \hat{1}\) es lo mismo que \(\hat{U}^2 = \hat{1}\). Calculando: \(\frac{1}{2}\begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}\begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix} = \frac{1}{2}\begin{pmatrix} 2 & 0 \\ 0 & 2 \end{pmatrix} = \hat{1}\). Efectivamente es unitaria.
⚪ Mei: Que al elevar al cuadrado dé la matriz identidad significa que aplicando la transformación dos veces se vuelve al estado original.
🟡 Lina: Por cierto, esta matriz es un caso especial donde resulta ser hermitiana y unitaria a la vez. Las matrices unitarias en general tienen \(\hat{U}^\dagger \neq \hat{U}\), así que no pienses que "unitaria = hermitiana". Y ser hermitiana y unitaria a la vez significa que es una transformación que al aplicarla dos veces devuelve al estado original.
🔵 Kai: También se verifica que \(\hat{U}|+\rangle = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 \\ 1 \end{pmatrix} = |+\rangle_x\). Pero, ¿por qué "colocar los nuevos vectores de base como columnas" da la matriz de transformación?
🟡 Lina: Buena pregunta. Recuerda el producto de una matriz por un vector. Si multiplicas la matriz \(\hat{U}\) por \(|e_1\rangle = \begin{pmatrix} 1 \\ 0 \end{pmatrix}\), el resultado es exactamente la primera columna de \(\hat{U}\), ¿verdad? Igualmente, multiplicar por \(|e_2\rangle = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\) da la segunda columna. Así que la definición \(\hat{U}|e_k\rangle = |e'_k\rangle\) (B.52) dice que "la columna \(k\) de \(\hat{U}\) = las componentes del \(k\)-ésimo vector de la nueva base \(|e'_k\rangle\)". Es decir, los nuevos vectores de base aparecen como columnas.
🔵 Kai: Ah, claro. Al multiplicar por \(\begin{pmatrix} 1 \\ 0 \end{pmatrix}\) solo se "selecciona" la primera columna, por eso la base destino está en las columnas.
✅ Verificación de comprensión: ¿Qué significa que una transformación unitaria "conserva la probabilidad"?
Respuesta
Una transformación unitaria conserva el producto interno (\(\langle\phi'|\psi'\rangle = \langle\phi|\psi\rangle\)). En mecánica cuántica, \(|\langle\phi|\psi\rangle|^2\) corresponde a la probabilidad de transición, por lo que la probabilidad no cambia antes y después de una transformación unitaria.
📝 Ejercicios:
- Calcular \(\hat{U}^\dagger \hat{\sigma}_x \hat{U}\) usando el \(\hat{U}\) de la ecuación (B.57) y verificar que el resultado es la matriz diagonal \(\begin{pmatrix} 1 & 0 \\ 0 & -1 \end{pmatrix}\) (Pista: este \(\hat{U}\) satisface \(\hat{U} = \hat{U}^\dagger = \hat{U}^{-1}\). Los vectores columna de \(\hat{U}\) son los vectores propios de \(\hat{\sigma}_x\), por lo que \(\hat{U}^\dagger \hat{\sigma}_x \hat{U}\) es la matriz que representa \(\hat{\sigma}_x\) en su base propia — es decir, la matriz con los valores propios \(+1, -1\) en la diagonal) → Problema A-1. Cambio de base mediante matrices unitarias y reglas de transformación de representaciones matriciales
B.8 Producto tensorial — Combinar dos sistemas¶
🟡 Lina: En mecánica cuántica es frecuente tratar con "sistemas compuestos" que combinan dos sistemas independientes. Por ejemplo, los espines de dos electrones, o la posición y el espín de una partícula. Para esto usamos el producto tensorial (tensor product).
🔵 Kai: ¿Qué es el producto tensorial?
🟡 Lina: Intuitivamente, es la operación de emparejar "el estado del sistema 1" y "el estado del sistema 2" para formar un solo estado. Por ejemplo, si consideras simultáneamente cara/cruz de una moneda (2 posibilidades) y el resultado de un dado (6 posibilidades), las combinaciones son \(2 \times 6 = 12\), ¿verdad? El producto tensorial formaliza esta "combinación" en el lenguaje de espacios vectoriales.
⚪ Mei: El número de combinaciones se multiplica.
🟡 Lina: Matemáticamente, escribimos el espacio vectorial (con producto interno — lo llamamos espacio de Hilbert; en B.9 lo definiremos formalmente; por ahora piensa en "espacio vectorial con producto interno definido") donde viven los estados del sistema 1 como \(\mathcal{H}_1\) (dimensión \(N_1\)). \(\mathcal{H}\) es el símbolo estándar para un espacio de Hilbert. Similarmente, el del sistema 2 es \(\mathcal{H}_2\) (dimensión \(N_2\)). El espacio de Hilbert del sistema compuesto es
y su dimensión es \(N_1 \times N_2\). El símbolo \(\otimes\) representa el "producto tensorial".
🟡 Lina: Cuando el sistema 1 está en el estado \(|\psi\rangle \in \mathcal{H}_1\) y el sistema 2 en el estado \(|\phi\rangle \in \mathcal{H}_2\), el estado del sistema compuesto se escribe
Abreviadamente también se escribe \(|\psi\rangle|\phi\rangle\) o \(|\psi, \phi\rangle\).
Reglas de cálculo del producto tensorial¶
🟡 Lina: El producto tensorial obedece las siguientes reglas.
(1) Linealidad:
(2) Producto interno:
Se calculan los productos internos de cada sistema por separado y se multiplican.
Producto tensorial de matrices (producto de Kronecker)¶
🟡 Lina: En representación matricial, el producto tensorial se expresa como el producto de Kronecker. El producto de Kronecker de una matriz \(m \times n\) \(A\) con una matriz \(p \times q\) \(B\) es una matriz \(mp \times nq\):
🟡 Lina: Veamos un ejemplo concreto. Con \(\mathcal{H}_1 = \mathcal{H}_2 = \mathbb{C}^2\):
🔵 Kai: 2 dimensiones × 2 dimensiones = 4 dimensiones.
⚪ Mei: Al combinar dos sistemas de espín 1/2, se obtiene un espacio de 4 dimensiones.
Estados entrelazados¶
🟡 Lina: Dentro del espacio producto tensorial existen vectores que no pueden escribirse en la forma \(|\psi\rangle \otimes |\phi\rangle\). Por ejemplo:
🔵 Kai: ¿Esto no se puede descomponer en la forma \(|\psi\rangle \otimes |\phi\rangle\)?
🟡 Lina: No se puede. Lo demostraremos por reducción al absurdo. Supongamos que \(|\Psi\rangle = (a|+\rangle + b|-\rangle) \otimes (c|+\rangle + d|-\rangle)\). Expandiendo:
Compara los coeficientes con (B.65).
🔵 Kai: A ver, el coeficiente de \(|+\rangle|+\rangle\) en (B.65) es cero, así que \(ac = 0\). El de \(|+\rangle|-\rangle\) es \(1/\sqrt{2}\), así que \(ad = 1/\sqrt{2}\). El de \(|-\rangle|+\rangle\) es \(-1/\sqrt{2}\), así que \(bc = -1/\sqrt{2}\). El de \(|-\rangle|-\rangle\) es cero, así que \(bd = 0\).
🔵 Kai: De \(ac = 0\) se deduce \(a = 0\) o \(c = 0\). Pero si \(a = 0\) entonces \(ad = 0\) y no coincide con \(1/\sqrt{2}\)... Si \(c = 0\) entonces \(bc = 0\) y no coincide con \(-1/\sqrt{2}\)... ¿Eh? ¡En ambos casos hay contradicción!
🟡 Lina: Exacto. En ambos casos hay contradicción, así que no puede escribirse como producto tensorial — es un estado entrelazado. "No se puede asignar un estado independiente a cada subsistema" es la esencia del entrelazamiento.
⚪ Mei: Con la reducción al absurdo mostramos que "si suponemos que se puede descomponer, inevitablemente se llega a una contradicción".
🟡 Lina: Los estados que no pueden descomponerse en forma de producto tensorial se llaman estados entrelazados (entangled states). Los trataremos en detalle en los capítulos 23–24, pero son una de las características más sorprendentes de la mecánica cuántica.
✅ Verificación de comprensión: ¿Qué es un estado entrelazado?
Respuesta
Un estado del sistema compuesto cuyo vector de estado no puede descomponerse como producto tensorial de vectores de estado de cada subsistema \(|\psi\rangle \otimes |\phi\rangle\). Por ejemplo, \(\frac{1}{\sqrt{2}}(|+\rangle \otimes |-\rangle - |-\rangle \otimes |+\rangle)\) es un estado entrelazado.
✅ Verificación de comprensión: ¿Cuál es la dimensión del espacio producto tensorial de dos espacios de Hilbert de dimensión 2?
Respuesta
\(2 \times 2 = 4\) dimensiones.
📝 Ejercicios:
- Demostrar que \(|\Psi\rangle = \frac{1}{\sqrt{2}}(|+\rangle \otimes |+\rangle + |-\rangle \otimes |-\rangle)\) es un estado entrelazado → Problema A-2. Espacio producto tensorial y construcción de la base de Bell
B.9 Extensión al espacio de Hilbert de dimensión infinita — Las funciones también son vectores¶
🟡 Lina: Hasta aquí hemos trabajado en \(\mathbb{C}^N\) de dimensión finita, pero a partir de Cap. 7, donde tratamos con funciones de onda, necesitamos un espacio de Hilbert de dimensión infinita. Definámoslo formalmente: un espacio de Hilbert es "un espacio vectorial con producto interno definido y que además es completo".
🔵 Kai: ¿Qué es "completo"?
🟡 Lina: Intuitivamente significa que "el destino de toda sucesión de puntos que se acercan indefinidamente está contenido en el propio espacio". Por ejemplo, la sucesión de racionales \(1, 1.4, 1.41, 1.414, \ldots\) se acerca a \(\sqrt{2}\), pero \(\sqrt{2}\) no es racional, así que el conjunto de los racionales "no es completo". El conjunto de los reales sí contiene \(\sqrt{2}\), así que es completo. En espacios vectoriales es igual: "la completitud" es que el límite de cualquier sucesión de vectores que se acercan cada vez más pertenece al espacio. \(\mathbb{C}^N\) de dimensión finita es automáticamente completo, así que cuando definimos el producto interno en B.2 ya era un espacio de Hilbert. En dimensión infinita "si es completo o no" se vuelve no trivial, pero está demostrado que \(L^2\) es completo y por tanto es un espacio de Hilbert.
⚪ Mei: En dimensión finita la completitud es automática, pero en dimensión infinita requiere demostración — ahí está el punto delicado.
🟡 Lina: Finalmente, voy a organizar "qué cambia" al pasar de dimensión finita a infinita.
El espacio de funciones \(L^2\) es un espacio de Hilbert¶
🟡 Lina: Formulemos de nuevo el espacio de funciones de cuadrado integrable \(L^2\) que mencionamos en B.1, ahora como espacio de Hilbert.
El producto interno de dos funciones \(f(x)\) y \(g(x)\) se define como
Esto satisface las 3 propiedades (B.6)–(B.8).
🔵 Kai: Es como si \(\sum_k z_k^* z'_k\) de dimensión finita se reemplazara por \(\int f^* g\, dx\).
🟡 Lina: Esa intuición es correcta. La suma \(\sum\) se reemplaza por la integral \(\int\), y la componente \(z_k\) por el valor funcional \(f(x)\). Pero este "reemplazo" trae consigo algunos problemas sutiles.
Tabla de correspondencia entre dimensión finita e infinita¶
🟡 Lina: Resumo la correspondencia en una tabla.
Tabla B.2: Correspondencia entre dimensión finita e infinita
| Dimensión finita \(\mathbb{C}^N\) | Dimensión infinita \(L^2\) |
|---|---|
| Vector \(\lvert\psi\rangle = \sum_k c_k \lvert e_k\rangle\) | Función \(f(x) = \sum_n c_n f_n(x)\) o \(\int c(k) f_k(x)\, dk\) |
| Componente \(c_k = \langle e_k\lvert\psi\rangle\) | Coeficiente de expansión \(c_n = \langle f_n\lvert f\rangle = \int f_n^* f\, dx\) |
| Producto interno \(\sum_k z_k^* z'_k\) | Producto interno \(\int f^* g\, dx\) |
| Delta de Kronecker \(\delta_{jk}\) | Función delta de Dirac \(\delta(x - x')\) |
| Completitud \(\sum_k \lvert e_k\rangle\langle e_k\rvert = \hat{1}\) | Completitud \(\sum_n \lvert f_n\rangle\langle f_n\rvert = \hat{1}\) o \(\int \lvert x\rangle\langle x\rvert\, dx = \hat{1}\) |
| Matriz \(A_{jk}\) | Núcleo integral \(A(x, x')\) |
Observación 1: Espectro discreto y continuo¶
🟡 Lina: En dimensión finita los valores propios eran siempre discretos (valores aislados), pero en dimensión infinita puede aparecer un espectro continuo.
🔵 Kai: ¿Qué es el espectro continuo?
🟡 Lina: Por ejemplo, los valores propios del operador de momento de una partícula libre \(\hat{p} = -i\hbar\, d/dx\) toman cualquier valor real \(p\). No son discretos sino continuos. La ecuación de valores propios \(\hat{p}\,f_p(x) = p\,f_p(x)\) se escribe como \(-i\hbar\, df_p/dx = p\,f_p\), es decir \(df_p/dx = (ip/\hbar)\,f_p\). Esto es la pregunta "¿qué función, al derivar, da un múltiplo constante de sí misma?". En el bachillerato aprendiste que la derivada de \(e^x\) es \(e^x\) misma. En general, la derivada de \(e^{\alpha x}\) es \(\alpha e^{\alpha x}\) — es decir, un múltiplo \(\alpha\) de sí misma. Y se puede demostrar que "la única función cuya derivada es un múltiplo constante de sí misma" es la exponencial. Por tanto la solución de \(df_p/dx = (ip/\hbar)f_p\) es necesariamente \(f_p(x) \propto e^{ipx/\hbar}\).
🔵 Kai: Entonces la función propia es \(e^{ipx/\hbar}\) y \(p\) es cualquier real. ¡Eso es una onda que se extiende infinitamente!
🟡 Lina: Así es. La constante de normalización debe elegirse para que se cumpla la normalización con delta (B.68). El resultado es:
Esta función no puede normalizarse en el sentido usual (\(\int |f_p|^2\, dx = \infty\)). En su lugar se usa la normalización con función delta de Dirac \(\delta(p - p')\). La función delta es, intuitivamente, "una función con un pico infinitamente estrecho en \(x = 0\) y cero en cualquier otro punto", que satisface \(\int_{-\infty}^{\infty} \delta(x)\, dx = 1\) — piensa en ella como la versión continua de la delta de Kronecker \(\delta_{jk}\). Como imagen, considera un rectángulo de anchura \(\epsilon\) y altura \(1/\epsilon\): el área es siempre 1, pero al hacer \(\epsilon \to 0\) la anchura se reduce a cero y la altura diverge a infinito — ese límite es la función delta. \(\delta(p - p')\) es la versión que "tiene pico solo en \(p = p'\)".
Lo importante es que la esencia del uso de la función delta es "usarla dentro de una integral multiplicada por otra función": \(\int f(x)\,\delta(x - a)\,dx = f(a)\) — es decir, "la función delta extrae el valor de la función en \(x = a\) dentro de la integral". Esto es la versión continua de la delta de Kronecker \(\sum_k f_k\,\delta_{jk} = f_j\). La definición rigurosa se trata en Apéndice C, pero por ahora entiéndelo por analogía con el caso discreto: "si \(p = p'\) equivale a 1, si \(p \neq p'\) equivale a 0". La normalización con delta se escribe como
Es la versión continua de \(\langle e_j|e_k\rangle = \delta_{jk}\) para bases discretas. Puede parecer extraño que se llame "normalización" cuando para \(p = p'\) da \(\delta(0) = \infty\), pero no es una normalización en el sentido de "norma igual a 1", sino una condición que expresa que "funciones propias de distintos valores propios son ortogonales" y que "el solapamiento entre funciones propias del mismo valor propio está ajustado según una convención fija". Es el mismo papel que \(\delta_{jk}\) ("1 si \(j = k\), 0 si \(j \neq k\)") jugaba en el caso discreto, ahora desempeñado por \(\delta(p - p')\) en el caso continuo. Y la constante de normalización \(1/\sqrt{2\pi\hbar}\) es el valor elegido para que (B.68) se cumpla exactamente. Por qué toma este valor se derivará naturalmente cuando aprendamos la transformada de Fourier en Apéndice C.
🔵 Kai: Hmm, que me digan "con esta constante se cumple (B.68)" sin calcular realmente \(\int f_{p'}^* f_p\, dx\) y ver que sale \(\delta(p - p')\) me deja intranquilo...
🟡 Lina: Entiendo perfectamente. El cálculo real requiere la fórmula de la transformada de Fourier, que desarrollamos en Apéndice C. Allí derivaremos la identidad "al multiplicar ondas planas de distintos momentos e integrar sobre todo el espacio sale una función delta", y con eso podrás verificar (B.68). Por ahora piensa que "la verificación se pospone al Apéndice C".
🔵 Kai: Entendido. Si puedo verificarlo con un cálculo, me quedo tranquilo.
⚪ Mei: Para espectro discreto la delta de Kronecker \(\delta_{jk}\); para espectro continuo la delta de Dirac \(\delta(p - p')\). El mismo patrón de reemplazar la suma \(\sum\) por la integral \(\int\).
Observación 2: Completitud de los sistemas de funciones propias¶
🟡 Lina: En dimensión finita, que los vectores propios de una matriz hermitiana formen un sistema completo puede demostrarse como teorema. Pero en dimensión infinita, esto en general no puede demostrarse.
🔵 Kai: ¿Por qué en dimensión infinita no se puede demostrar?
🟡 Lina: Intuitivamente: en dimensión finita la ecuación característica es una ecuación de grado \(N\) en \(a\), ¿verdad? En el campo complejo, una ecuación de grado \(N\) siempre tiene \(N\) raíces — eso es el "teorema fundamental del álgebra". Es como lo que aprendiste en el bachillerato: "una ecuación de segundo grado siempre tiene 2 soluciones con la fórmula", generalizado a grado \(N\). Para matrices hermitianas, además se garantiza que "los vectores propios forman un sistema ortonormal completo" (lo vimos en el Teorema 3 de B.6). Por eso en dimensión finita la completitud es automática.
🔵 Kai: Ah, ya veo: en dimensión finita "ecuación de grado \(N\) tiene \(N\) soluciones" y así se encuentran todas, así que no hay problema.
🟡 Lina: Pero en dimensión infinita ya no existe el concepto de "grado de la ecuación", y hay problemas con el dominio de definición de los operadores, por lo que hay que verificar caso por caso si los vectores propios generan todo el espacio. Para los operadores "bien comportados" que aparecen en física suele cumplirse, pero como resultado general no está garantizado.
🔵 Kai: ¿Entonces qué se hace?
🟡 Lina: En mecánica cuántica se adopta como axioma (postulado) que las funciones propias de un operador hermitiano correspondiente a un observable forman un sistema completo. No es algo que se demuestre matemáticamente, sino una hipótesis que se acepta como punto de partida del modelo físico.
⚪ Mei: Lo que en dimensión finita podía demostrarse como teorema, en dimensión infinita hay que postularlo — eso muestra lo difícil que es manejar la dimensión infinita.
✅ Verificación de comprensión: En un espacio de Hilbert de dimensión infinita, ¿cómo se garantiza que las funciones propias de un operador hermitiano formen un sistema completo?
Respuesta
A diferencia de la dimensión finita, en general no puede demostrarse matemáticamente. En mecánica cuántica se adopta como axioma (postulado) que "las funciones propias de un operador hermitiano correspondiente a un observable forman un sistema completo".
Observación 3: Dominio de definición de los operadores¶
🟡 Lina: En dimensión infinita, no siempre un operador "puede actuar sobre todos los vectores". Por ejemplo, el operador diferencial \(\hat{p} = -i\hbar\, d/dx\) no puede actuar sobre funciones no diferenciables. Al conjunto de vectores sobre los que un operador puede actuar lo llamamos dominio (domain).
🔵 Kai: ¿En dimensión finita no había que preocuparse por eso?
🟡 Lina: En dimensión finita una matriz puede actuar sobre cualquier vector, así que no surge el problema del dominio. Pero en dimensión infinita, al determinar si un operador "es hermitiano o no", hay que especificar cuidadosamente el dominio. Estrictamente hablando, autoadjunto (self-adjoint) y hermitiano (Hermitian) son conceptos diferentes en dimensión infinita, y el físicamente correcto es el autoadjunto.
🔵 Kai: ¿Entonces cuál usamos en este libro?
🟡 Lina: Como en la mayoría de los libros de física, en Mecánica Cuántica no distinguimos entre "hermitiano" y "autoadjunto" cuando no causa problemas en los cálculos físicos habituales. Pero ten en la cabeza que existe esta sutileza.
Resumen: lo aprendido en dimensión finita también se usa en dimensión infinita¶
🟡 Lina: Lo que quiero que te quede tranquilo es que los conceptos aprendidos en dimensión finita — producto interno, base ortonormal, relación de completitud, operador hermitiano, operador unitario — se usan básicamente con la misma forma en dimensión infinita. Las diferencias son:
- La suma \(\sum\) a veces se reemplaza por la integral \(\int\)
- Para espectro continuo se usa la normalización con función delta
- Hay que tener cuidado con el dominio de definición de los operadores
Si tienes presentes estos 3 puntos, podrás entrar sin problemas en la discusión de funciones de onda de Cap. 7 en adelante.
🔵 Kai: Si solo hay 3 cosas a tener en cuenta, creo que me las arreglo.
✅ Verificación de comprensión: ¿Cuáles son las mayores diferencias entre un espacio de Hilbert de dimensión finita y uno de dimensión infinita? Menciona 3.
Respuesta
(1) Puede aparecer espectro continuo, no solo discreto. (2) Las funciones propias del espectro continuo no pueden normalizarse en el sentido usual; se usa la normalización con función delta de Dirac. (3) Hay que tener cuidado con el dominio de definición de los operadores, y puede surgir la distinción entre "hermitiano" y "autoadjunto".
Resumen de este Apéndice¶
🟡 Lina: Organizo el contenido de este Apéndice en correspondencia con la mecánica cuántica.
Tabla B.3: Resumen de la correspondencia entre conceptos matemáticos y mecánica cuántica
| Concepto matemático | Papel en mecánica cuántica | Capítulo donde aparece |
|---|---|---|
| Espacio vectorial complejo | Espacio donde viven los estados cuánticos | Cap. 4– |
| Producto interno \(\langle\phi\lvert\psi\rangle\) | Amplitud de probabilidad | Cap. 4– |
| Base ortonormal | Base de medición | Cap. 5– |
| Relación de completitud | Expansión de estados, la suma de probabilidades es 1 | Cap. 5– |
| Operador hermitiano | Observables (posición, momento, energía, etc.) | Cap. 8, Cap. 11– |
| Valores propios / vectores propios | Valores de medición / estado tras la medición | Cap. 5, Cap. 12 |
| Operador unitario | Evolución temporal, cambio de base | Cap. 6, Cap. 13 |
| Producto tensorial | Espacio de estados de sistemas compuestos | Cap. 18, Cap. 23–Cap. 24 |
🔵 Kai: Todo está conectado.
🟡 Lina: Así es. El álgebra lineal es la "gramática" de la mecánica cuántica. Lee el texto principal consultando este Apéndice según lo necesites.
Adelanto del próximo capítulo¶
🟡 Lina: En Apéndice C trataremos el análisis de Fourier y la función \(\delta\). En este Apéndice dijimos "la suma \(\sum\) se reemplaza por la integral \(\int\)", y el mecanismo concreto de eso es la transformada de Fourier. Desarrollaremos las herramientas indispensables para la expansión en funciones propias del espectro continuo y para el puente entre la representación de posición y la de momento.
🔵 Kai: ¿También se aclarará la verdadera naturaleza de la función delta?
🟡 Lina: Sí. La función delta "no es una función ordinaria", pero se entiende naturalmente en el lenguaje de la transformada de Fourier. ¡Espéralo con ganas!¶
Problemas de práctica¶
📝 Ejercicios:
- Norma y normalización de un vector en \(\mathbb{C}^2\) → Problema B-1. Cálculo de la norma de un vector en \(\mathbb{C}^2\)
- Cálculo del conjugado hermitiano → Problema B-6. Cálculo del conjugado hermítico
- Determinación de independencia lineal → Problema B-8. Determinación de independencia lineal
- Ortogonalización de Gram–Schmidt → Problema M-1. Método de ortogonalización de Gram–Schmidt
- Diagonalización mediante transformación unitaria → Problema A-1. Cambio de base mediante matrices unitarias y reglas de transformación de representaciones matriciales
- Demostración de estado entrelazado → Problema A-2. Espacio producto tensorial y construcción de la base de Bell
Bibliografía¶
- J. J. Sakurai, J. Napolitano, Modern Quantum Mechanics (3rd ed.), Cambridge University Press — Parte del marco matemático del Cap.1. Se consultó la formulación de la notación de Dirac, operadores, problemas de valores propios y cambios de base.
- D. J. Griffiths, D. F. Schroeter, Introduction to Quantum Mechanics (3rd ed.), Cambridge University Press — Cap.3 (formalismo): se consultaron la definición de espacio de Hilbert, las demostraciones de los teoremas sobre operadores hermitianos y el tratamiento del espectro continuo.
- 清水明『新版 量子論の基礎——その本質のやさしい理解のために』サイエンス社 — Cap.3: se consultaron la construcción del espacio de Hilbert complejo, los axiomas del producto interno, los problemas de valores propios de las matrices de Pauli y el concepto de rayo.
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.