Capítulo 2 Repaso de la relatividad especial y la invariancia de Lorentz¶
Resumen de lo anterior:
En Cap. 1 confirmamos que al intentar satisfacer simultáneamente la mecánica cuántica y la relatividad especial, la creación y aniquilación de partículas se vuelven inevitables, y que para describir esto se necesita un nuevo marco llamado "teoría cuántica de campos". Revisamos las dificultades de la ecuación de Klein-Gordon y la ecuación de Dirac anticipadas en Mecánica Cuántica Cap. 27, y tendimos un puente hacia la visión del mundo en la que "los modos de vibración de los campos son partículas".
Objetivo de este capítulo
- Repasar los puntos esenciales de las herramientas matemáticas de la relatividad especial (transformaciones de Lorentz, métrica de Minkowski, 4-vectores, subir y bajar índices, convención de suma de Einstein) y adquirir 3 perspectivas particularmente importantes en la teoría cuántica de campos: (i) la convención de signos \((+,-,-,-)\), (ii) la clasificación del grupo de Lorentz y el grupo de Poincaré, (iii) la práctica de determinar la covariancia de Lorentz solo con el "balance de índices"
- Con esto quedará preparada la base para escribir lagrangianos y derivar ecuaciones de campo en los capítulos siguientes
2.1 Repaso rápido de la estructura matemática de la relatividad especial¶
🟡 Lina: En Cap. 1 hablamos de que la teoría cuántica de campos es "la teoría que fusiona la mecánica cuántica y la relatividad especial". Hoy el objetivo es preparar la estructura matemática de la relatividad especial en una forma utilizable para la teoría cuántica de campos.
🔵 Kai: En Relatividad General Cap. 3 y Relatividad General Cap. 4 ya estudiamos la matemática de la relatividad especial y el espacio-tiempo de Minkowski, ¿verdad? ¿No será repetitivo?
🟡 Lina: Buena pregunta. El núcleo del contenido físico es el mismo, así que en este capítulo tomaré como prerequisito los capítulos 3-4 de Relatividad General y solo confirmaré rápidamente los resultados. A cambio, dedicaré tiempo a las perspectivas que se necesitan nuevamente para la teoría cuántica de campos: la clasificación del grupo de Lorentz, el grupo de Poincaré y la práctica de determinar la covariancia con el "balance de índices".
⚪ Mei: Para quienes ya estudiaron los capítulos 3-4 de Relatividad General, basta con ojear los resultados de esta sección y avanzar al siguiente tema.
🟡 Lina: Exacto. Resumiré los puntos esenciales en una tabla.
Estructura matemática de la relatividad especial (resumen de los capítulos 3-4 de Relatividad General)
Transformación de Lorentz (boost en dirección \(x\)) — Relatividad General Cap. 3
Usando la rapidez \(\varphi\) (\(\tanh\varphi = v\)), se puede escribir como una "rotación hiperbólica" con la misma forma que una rotación — ver Relatividad General Cap. 3.
4-vectores e índices — Relatividad General Cap. 4
Los índices griegos \(\mu, \nu, \ldots\) van de \(0, 1, 2, 3\) (espacio-tiempo); los índices latinos \(i, j, \ldots\) van de \(1, 2, 3\) (solo espacio).
Convención de suma de Einstein — Cuando un mismo índice aparece una vez arriba y una vez abajo, se suma de \(0\) a \(3\). Se omite el símbolo \(\sum\).
Subir y bajar índices — Se bajan índices con el tensor métrico \(\eta_{\mu\nu}\) y se suben con la métrica inversa \(\eta^{\mu\nu}\).
4-momento y condición de capa de masa — Relatividad General Cap. 4
🔵 Kai: ¿Qué hacemos con el sistema de unidades naturales \(c = \hbar = 1\)?
🟡 Lina: En Relatividad General Cap. 4 introdujimos \(c = 1\). En la teoría cuántica de campos, como también fusionamos la mecánica cuántica, añadimos además \(\hbar = 1\) — esto se llama "sistema de unidades naturales de la física de partículas". Para los detalles de la convención, consulta la nota "Sistemas de unidades relacionados" al final de Relatividad General Relatividad General Cap. 4.
Al añadir \(\hbar = 1\), la energía, la masa y la frecuencia adquieren todas la misma dimensión. ¿Por qué también la frecuencia? Porque de \(E = \hbar\omega\) con \(\hbar = 1\) se obtiene \(E = \omega\) — es decir, la frecuencia se mide directamente en unidades de energía. Igualmente, de \(E = mc^2\) con \(c = 1\) se obtiene \(E = m\), así que la masa también tiene la misma dimensión que la energía.
🔵 Kai: Masa y frecuencia tienen la misma dimensión que la energía... ¿eso significa que podemos escribir la masa del electrón en MeV?
🟡 Lina: Exacto. Por ejemplo, la masa del electrón \(m_e \approx 0.511\,\text{MeV}\) se puede tratar como "energía directamente" sin escribir \(c\) ni \(\hbar\). En cuanto a la longitud y el tiempo, \(\hbar = 1\) significa \([\text{Energía}] \times [\text{Tiempo}] = 1\) (adimensional), por lo que \([\text{Tiempo}] = [\text{Energía}]^{-1}\). Además, \(c = 1\) significa \([\text{Longitud}] = [\text{Tiempo}]\), así que al final \([\text{Longitud}] = [\text{Tiempo}] = [\text{Energía}]^{-1}\). Es decir, a mayor energía corresponden distancias más cortas y tiempos más cortos — esta es la razón por la que en física de partículas se dice "experimentos de alta energía = explorar la física a cortas distancias". Resumo en Tabla 2.1「Unificación de dimensiones en el sistema de unidades naturales (\(c = \hbar = 1\))」 cómo cambian las dimensiones de cada magnitud física.
⚪ Mei: Como la longitud es el inverso de la energía, al aumentar la energía el tamaño observable se hace más pequeño — ahí está el significado de usar alta energía en los aceleradores.
Tabla 2.1: Unificación de dimensiones en el sistema de unidades naturales (\(c = \hbar = 1\))
| Magnitud física | Dimensión en unidades SI | Dimensión en unidades naturales | Ejemplo |
|---|---|---|---|
| Energía | \(\text{kg}\cdot\text{m}^2/\text{s}^2\) | \([\text{Energía}]\) | \(E = 0.511\,\text{MeV}\) |
| Masa | \(\text{kg}\) | \([\text{Energía}]\) | \(m_e = 0.511\,\text{MeV}\) |
| Momento | \(\text{kg}\cdot\text{m}/\text{s}\) | \([\text{Energía}]\) | \(p = 1\,\text{GeV}\) |
| Longitud | \(\text{m}\) | \([\text{Energía}]^{-1}\) | \(1\,\text{GeV}^{-1} \approx 0.2\,\text{fm}\) (\(1\,\text{fm} = 10^{-15}\,\text{m}\); escala menor que el radio del protón \(\approx 0.8\,\text{fm}\)) |
| Tiempo | \(\text{s}\) | \([\text{Energía}]^{-1}\) | \(1\,\text{GeV}^{-1} \approx 6.6 \times 10^{-25}\,\text{s}\) |
✅ Verificación de comprensión: En el sistema de unidades naturales adoptado en la teoría cuántica de campos, ¿qué constantes se igualan a 1? Además, ¿como magnitud de qué dimensión se puede tratar la masa como resultado?
Respuesta
Se ponen tanto \(c = 1\) como \(\hbar = 1\) (sistema de unidades naturales de la física de partículas). Como resultado, la masa, la energía y la frecuencia adquieren todas la misma dimensión, y por ejemplo la masa del electrón se puede expresar directamente en unidades de energía como \(m_e \approx 0.511\,\text{MeV}\).
2.2 Diferencia de convenciones de signos — Estilo QFT y estilo GR¶
🟡 Lina: Aquí voy a aclarar de antemano el primer punto de confusión al estudiar teoría cuántica de campos. Se trata de la convención de signos del tensor métrico. He resumido el panorama completo de las dos convenciones en Fig. 2.1「Diferencia de convenciones de signos (estilo QFT vs estilo GR)」, así que primero échenle un vistazo.
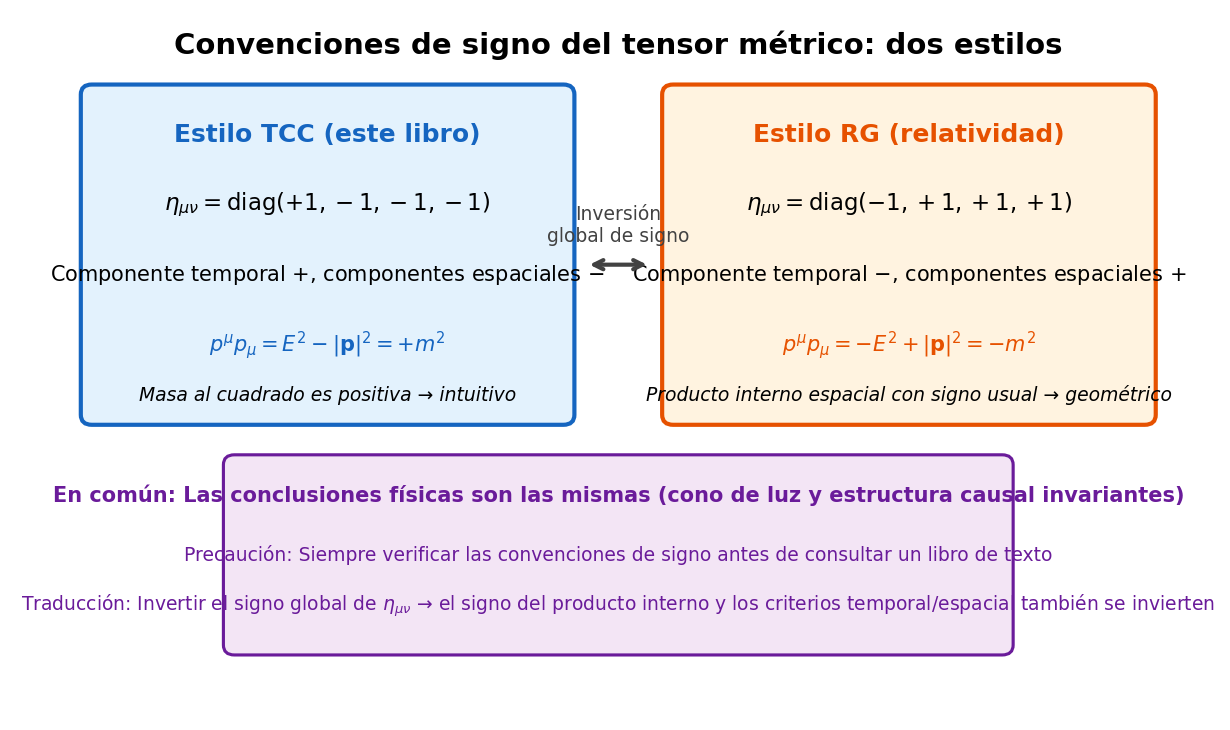
Fig. 2.1: Diferencia de convenciones de signos (estilo QFT vs estilo GR). Para la convención de signos del tensor métrico existen dos tipos: estilo QFT \((+,-,-,-)\) y estilo GR \((-,+,+,+)\). Las conclusiones físicas son las mismas, pero los signos de las expresiones intermedias difieren, por lo que al consultar libros de texto es imprescindible verificar la convención.
🔵 Kai: Convención de signos... En Relatividad General Relatividad General Cap. 4 teníamos \(\eta_{\mu\nu} = \text{diag}(-1, +1, +1, +1)\), ¿verdad?
🟡 Lina: Así es. Esa es la convención estilo GR (mostly-plus, \((-,+,+,+)\)). Sin embargo, en los libros de texto de física de partículas y teoría cuántica de campos, es estándar usar la convención opuesta
— estilo QFT (mostly-minus, \((+,-,-,-)\)). Este libro también adopta el estilo QFT.
⚪ Mei: ¿Por qué existen dos convenciones?
🟡 Lina: Razones históricas. Ambas dan las mismas conclusiones físicas, pero varios signos en las expresiones intermedias se invierten. Preparemos una tabla de correspondencia.
Tabla de correspondencia entre estilo GR \((-,+,+,+)\) y estilo QFT \((+,-,-,-)\)
| Cantidad | Estilo GR | Estilo QFT (este libro) |
|---|---|---|
| Métrica | \(\eta_{\mu\nu} = \text{diag}(-1,+1,+1,+1)\) | \(\eta_{\mu\nu} = \text{diag}(+1,-1,-1,-1)\) |
| Intervalo espacio-temporal | \(ds^2 = -dt^2 + d\mathbf{x}^2\) | \(ds^2 = dt^2 - d\mathbf{x}^2\) |
| Producto interno del 4-momento | \(p_\mu p^\mu = -m^2\) | \(p_\mu p^\mu = +m^2\) |
| Norma de la 4-velocidad (\(U^\mu = dx^\mu/d\tau\); ver Relatividad General Relatividad General Cap. 4) | \(U_\mu U^\mu = -1\) | \(U_\mu U^\mu = +1\) |
| Vector temporal \(V\) | \(V_\mu V^\mu < 0\) | \(V_\mu V^\mu > 0\) |
| Vector espacial \(V\) | \(V_\mu V^\mu > 0\) | \(V_\mu V^\mu < 0\) |
| Vector nulo (tipo luz) | \(V_\mu V^\mu = 0\) | \(V_\mu V^\mu = 0\) (igual) |
Para traducir las fórmulas de los capítulos 3-4 de Relatividad General al estilo QFT, basta con invertir el signo global de \(\eta_{\mu\nu}\). Como consecuencia, el valor del producto interno y la convención de signos de "temporal/espacial" se intercambian.
🔵 Kai: Entonces \(p^\mu p_\mu = m^2\) con signo positivo es el estilo QFT. Ciertamente es más intuitivo que "el cuadrado de la masa sea positivo"...
🟡 Lina: Así es. El estilo QFT tiene la ventaja de que "la componente temporal es positiva" y "la condición de capa de masa \(p^\mu p_\mu = m^2\) es directamente positiva". Por otro lado, el estilo GR tiene otra ventaja: "la métrica espacial es \(\eta_{ij} = +\delta_{ij}\), así que el producto interno de vectores espaciales coincide directamente con el \(\mathbf{A}\cdot\mathbf{B}\) que se aprende en el instituto". Es cuestión de preferencia, así que acostúmbrate a verificar siempre la convención de signos al consultar otros libros de texto — si descuidas esto, los signos de las expresiones intermedias no cuadrarán y te confundirás.
⚪ Mei: Este libro usa el estilo QFT. Al consultar los capítulos 3-4 de Relatividad General hay que tener cuidado con los signos.
🟡 Lina: Exacto. Reescribamos las fórmulas explícitamente en el estilo QFT.
Al bajar el índice:
La componente temporal queda igual, y el signo de las componentes espaciales se invierte (al revés que en el estilo GR). El producto interno de 4-vectores es:
La condición de capa de masa del 4-momento es:
✅ Verificación de comprensión: Con la convención QFT \(\eta_{\mu\nu} = \text{diag}(+1,-1,-1,-1)\), para el 4-vector \(A^\mu = (3, 1, 2, 0)\), calcula \(A_\mu\). Además, calcula \(A^\mu A_\mu\).
Respuesta
\(A_\mu = \eta_{\mu\nu} A^\nu = (3, -1, -2, 0)\) (la componente temporal queda igual, el signo de las componentes espaciales se invierte).
\(A^\mu A_\mu = A^0 A_0 + A^1 A_1 + A^2 A_2 + A^3 A_3 = 3 \cdot 3 + 1 \cdot (-1) + 2 \cdot (-2) + 0 \cdot 0 = 9 - 1 - 4 = 4\).
Como \(A^\mu A_\mu > 0\), en la convención de signos QFT este es un vector temporal.
📝 Ejercicios:
- Subir y bajar índices, producto interno, contracción → Problema B-1. Subida y bajada de índices, Problema B-2. Producto escalar de cuadrivectores, Problema B-3. Expansión de la convención de suma de Einstein
2.3 Estructura del grupo de Lorentz¶
🟡 Lina: Con la organización de la convención de signos completada, entremos ahora en un tema propio de la teoría cuántica de campos. Hasta aquí el contenido se solapaba con los capítulos 3-4 de GR, pero a partir de ahora es territorio nuevo. Vamos a examinar qué estructura tiene el conjunto completo de transformaciones de Lorentz. En la teoría cuántica de campos, es esta estructura de grupo la que determina "qué campos están permitidos" y "qué partículas pueden existir".
Definición general de la matriz de transformación de Lorentz¶
🟡 Lina: Para un 4-vector \(x^\mu\), escribimos la transformación de Lorentz general como
\(\Lambda^\mu{}_\nu\) es una matriz \(4 \times 4\), la matriz de transformación de Lorentz. Su propiedad definitoria es "preservar el intervalo invariante" — para cualquier \(x^\mu\), \(\eta_{\mu\nu}\, x'^\mu\, x'^\nu = \eta_{\mu\nu}\, x^\mu\, x^\nu\).
Organicemos esto. Sustituyendo \(x'^\mu = \Lambda^\mu{}_\alpha\, x^\alpha\) en la condición de intervalo invariante:
Como esto debe ser igual a \(\eta_{\alpha\beta}\, x^\alpha\, x^\beta\) para cualquier \(x^\alpha\), el contenido del paréntesis mismo debe ser igual:
🔵 Kai: Como "se cumple para cualquier \(x\)", las partes que no contienen \(x\) deben ser iguales entre sí.
🟡 Lina: Exacto. En forma matricial (definiendo las componentes de la matriz como \((\Lambda)^\mu{}_\nu = \Lambda^\mu{}_\nu\)):
Aquí \(\Lambda^T\) es la matriz transpuesta — aquella en la que se intercambian filas y columnas (para una matriz ordinaria \((A^T)_{ij} = A_{ji}\), es decir, el elemento de la fila \(i\) columna \(j\) de la transpuesta es igual al elemento de la fila \(j\) columna \(i\) de la matriz original). Confirmemos que (2.8) dice lo mismo que (2.7).
Verifiquemos con un ejemplo concreto de \(2 \times 2\). Si escribimos la componente "fila \(i\), columna \(j\)" de una matriz \(M\) como \(M^i{}_j\), entonces \(M = \begin{pmatrix} M^1{}_1 & M^1{}_2 \\ M^2{}_1 & M^2{}_2 \end{pmatrix}\). Aquí hay que tener cuidado — los superíndices y subíndices de \(M^i{}_j\) son una escritura de conveniencia para distinguir "número de fila y número de columna", y son algo distinto de contravariante/covariante en tensores. Sin embargo, en el caso de la matriz de transformación de Lorentz \(\Lambda^\mu{}_\nu\), como \(\Lambda\) es una matriz que "lleva un vector contravariante \(x^\mu\) a otro vector contravariante \(x'^\mu\)", el primer índice \(\mu\) (correspondiente al número de fila) es contravariante y el segundo índice \(\nu\) (correspondiente al número de columna) es covariante — es decir, la distinción fila/columna como matriz y la distinción contravariante/covariante como tensor coinciden naturalmente. Por eso esta notación se puede usar directamente. La transpuesta \(M^T\) intercambia filas y columnas, así que la componente "fila \(i\), columna \(j\)" de \(M^T\) es la componente "fila \(j\), columna \(i\)" de \(M\) — es decir \((M^T)^i{}_j = M^j{}_i\). Por tanto \(M^T = \begin{pmatrix} M^1{}_1 & M^2{}_1 \\ M^1{}_2 & M^2{}_2 \end{pmatrix}\).
🔵 Kai: Ah, los elementos diagonales quedan iguales y los no diagonales se intercambian.
🟡 Lina: Así es. Apliquemos esto a la matriz de transformación de Lorentz \(4 \times 4\). La componente "fila \(\mu\), columna \(\nu\)" de \(\Lambda\) es \(\Lambda^\mu{}_\nu\). Aplicando la fórmula de la transpuesta \((M^T)^i{}_j = M^j{}_i\), obtenemos \((\Lambda^T)^\alpha{}_\mu = \Lambda^\mu{}_\alpha\) — es decir, la "fila \(\alpha\), columna \(\mu\)" de la transpuesta \(\Lambda^T\) es la componente "fila \(\mu\), columna \(\alpha\)" de \(\Lambda\), que es \(\Lambda^\mu{}_\alpha\).
⚪ Mei: Es decir, igual que en el ejemplo \(2 \times 2\) de antes, al intercambiar filas y columnas queda \((\Lambda^T)^\alpha{}_\mu = \Lambda^\mu{}_\alpha\) — los números de fila y columna se han intercambiado.
🔵 Kai: Y con esto se calcula la componente del producto matricial \(\Lambda^T \eta\, \Lambda\). ¿Cómo se escribe el producto de tres matrices?
🟡 Lina: De la misma manera que el producto matricial ordinario \((AB)_{ij} = \sum_k A_{ik} B_{kj}\), se contrae por los índices adyacentes. Para el producto de tres matrices \(ABC\), se puede escribir directamente \((ABC)_{ij} = \sum_k \sum_l A_{ik} B_{kl} C_{lj}\) — da el mismo resultado si primero calculas \(AB\) y luego multiplicas por \(C\), o si multiplicas \(A\) por \(BC\).
Usando esto: la componente de fila \(\alpha\), columna \(\beta\) de \((\Lambda^T \eta\, \Lambda)\) es, por definición del producto matricial, \(\sum_{\mu}\sum_{\nu}(\Lambda^T)^\alpha{}_\mu\, \eta_{\mu\nu}\, \Lambda^\nu{}_\beta\) — donde las componentes "fila \(\mu\), columna \(\nu\)" de la matriz \(\eta\) se escriben como \(\eta_{\mu\nu}\) (simplemente expresamos los números de fila y columna con la notación de índices tensoriales). Sustituyendo \((\Lambda^T)^\alpha{}_\mu = \Lambda^\mu{}_\alpha\) obtenemos \(\sum_{\mu}\sum_{\nu}\Lambda^\mu{}_\alpha\, \eta_{\mu\nu}\, \Lambda^\nu{}_\beta\) — omitiendo los \(\sum\) con la convención de suma de Einstein queda \(\Lambda^\mu{}_\alpha\, \eta_{\mu\nu}\, \Lambda^\nu{}_\beta\). Que esto sea igual a \(\eta_{\alpha\beta}\) es exactamente (2.7).
🔵 Kai: Se parece a cómo las rotaciones satisfacen \(R^T R = \mathbf{1}\). Solo que la matriz identidad se reemplaza por la métrica \(\eta\).
🟡 Lina: Exactamente. Las rotaciones son transformaciones que preservan \(\delta_{ij}\); las transformaciones de Lorentz son transformaciones que preservan \(\eta_{\mu\nu}\). La estructura es paralela. La "rotación hiperbólica" de Relatividad General Cap. 3 es precisamente esta estructura.
Las 4 componentes conexas del grupo de Lorentz¶
🟡 Lina: Ahora tomemos el determinante de ambos lados de la condición (2.8). Aquí usaré dos propiedades importantes del determinante. La primera es que "el determinante del producto de matrices es igual al producto de los determinantes" — es decir, \(\det(ABC) = \det A \cdot \det B \cdot \det C\). Intuitivamente, el determinante representa "por cuánto se estira o encoge el volumen del espacio bajo esa transformación", así que la tasa de cambio de volumen al aplicar dos transformaciones seguidas es el producto de las tasas de cada una. En el caso \(2 \times 2\), para \(A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}\) tenemos \(\det A = ad - bc\), y se puede verificar por cálculo directo que \(\det(AB) = \det A \cdot \det B\) (ver también la expansión por cofactores en Relatividad General @chapter:gr/appendix_a). La segunda es que "el determinante no cambia al transponer" (\(\det\Lambda^T = \det\Lambda\)) — esto se demuestra porque la expansión por cofactores (Relatividad General @chapter:gr/appendix_a) da el mismo valor tanto si se hace por filas como por columnas. Intuitivamente, en el caso \(2 \times 2\): \(\det\begin{pmatrix} a & b \\ c & d \end{pmatrix} = ad - bc\) y la transpuesta da \(\det\begin{pmatrix} a & c \\ b & d \end{pmatrix} = ad - cb = ad - bc\) — efectivamente es igual. En el caso general también se cumple.
🔵 Kai: Entiendo, el producto de tasas de cambio de volumen y la invariancia bajo transposición — se usan estas dos propiedades.
🟡 Lina: Usando estas dos propiedades, el lado izquierdo es \(\det(\Lambda^T \eta\, \Lambda) = \det\Lambda^T \cdot \det\eta \cdot \det\Lambda = (\det\Lambda)^2\, \det\eta\). El lado derecho es \(\det\eta\). Como \(\det\eta = \det(\text{diag}(+1,-1,-1,-1)) = (+1)(-1)(-1)(-1) = -1 \neq 0\), dividiendo ambos lados por \(\det\eta\):
⚪ Mei: \(\det\Lambda\) solo puede ser \(+1\) o \(-1\) — no puede tomar valores intermedios.
🟡 Lina: Además, como (2.7) se cumple para cualesquiera \(\alpha, \beta\), sustituyendo en particular \(\alpha = \beta = 0\):
Expandamos el lado izquierdo con la métrica QFT \(\eta_{\mu\nu} = \text{diag}(+1,-1,-1,-1)\). Los índices \(\mu\) y \(\nu\) recorren independientemente de 0 a 3, así que en principio hay \(4 \times 4 = 16\) términos. Pero como \(\eta_{\mu\nu}\) es una matriz diagonal, \(\eta_{\mu\nu} = 0\) cuando \(\mu \neq \nu\) — es decir, solo sobreviven los 4 términos con \(\mu = \nu\):
Sustituyendo \(\eta_{00} = +1\), \(\eta_{11} = \eta_{22} = \eta_{33} = -1\):
Despejando:
(La igualdad se da cuando \(\Lambda^i{}_0 = 0\) (\(i = 1, 2, 3\)) — es decir, cuando todas las componentes espaciales de fila de la columna 0 de la matriz de transformación son cero. La transformación identidad o la inversión temporal pura corresponden a este caso.) Los números reales que satisfacen \(x^2 \geq 1\) son \(|x| \geq 1\), es decir \(x \geq 1\) o \(x \leq -1\) (si \(|x| < 1\) entonces \(x^2 < 1\), lo cual es una contradicción — imagina la gráfica de la función cuadrática \(y = x^2\) y la región donde \(y \geq 1\)). Por tanto \(\Lambda^0{}_0 \geq 1\) o \(\Lambda^0{}_0 \leq -1\). Por ejemplo, para la transformación identidad (no hacer nada, \(\Lambda^\mu{}_\nu = \delta^\mu{}_\nu\)) tenemos \(\Lambda^0{}_0 = 1\) (\(\det\Lambda = +1\)), y para la inversión temporal pura (\(t \to -t\), el espacio queda igual, es decir \(\Lambda = \text{diag}(-1, 1, 1, 1)\)) tenemos \(\Lambda^0{}_0 = -1\) (el determinante de una matriz diagonal es el producto de los elementos diagonales, así que \(\det\Lambda = (-1)(1)(1)(1) = -1\)).
✅ Verificación de comprensión: ¿Cuáles son los dos criterios de clasificación que dividen la matriz de transformación de Lorentz \(\Lambda\) en 4 componentes conexas? ¿Qué valores puede tomar cada uno?
Respuesta
(1) Si \(\det\Lambda = +1\) o \(-1\), y (2) si \(\Lambda^0{}_0 \geq 1\) o \(\Lambda^0{}_0 \leq -1\). Mediante las combinaciones de estos, el grupo de Lorentz se divide en 4 componentes conexas. Como estos valores no pueden saltar mediante cambios continuos de parámetros, no es posible ir continuamente de una componente conexa a otra.
🔵 Kai: Con las combinaciones de \(\det\Lambda = +1 / -1\) y \(\Lambda^0{}_0 \geq 1 / \leq -1\), el grupo de Lorentz se divide en 4 partes. Pero "se divide", ¿qué significa exactamente? ¿Por qué no se mezclan?
🟡 Lina: Buena pregunta. Aquí introduzco el término componente conexa (connected component). Al conjunto de transformaciones que se pueden alcanzar variando continua y gradualmente los parámetros de la transformación (ángulo de rotación, velocidad del boost) lo llamamos una componente conexa. La razón por la que \(\det\Lambda\) o \(\Lambda^0{}_0\) no pueden saltar a mitad de camino es que si cambias gradualmente los parámetros, las componentes de \(\Lambda\) también cambian gradualmente — es decir, \(\det\Lambda\) y \(\Lambda^0{}_0\) son funciones continuas, así que para ir de \(+1\) a \(-1\) tendrían que pasar por \(0\) en el camino. Pero cualquier \(\Lambda\) intermedia también es una matriz de transformación de Lorentz (satisface la condición (2.8)), así que por (2.9) \(\det\Lambda = 0\) es imposible, y por (2.10) \(|\Lambda^0{}_0| < 1\) tampoco es posible. Por eso el salto es imposible. La imagen es como 4 islas separadas por el mar — dentro de la misma isla puedes caminar (= variar continuamente los parámetros) a cualquier lugar, pero no puedes cruzar a otra isla ni siquiera nadando.
🔵 Kai: Ah, como no se puede pasar por "valores prohibidos" al variar continuamente, nunca se puede llegar a otra isla.
🟡 Lina: Déjame explicar la nomenclatura. "Propia (proper)" significa \(\det\Lambda = +1\) (preserva la orientación del espacio), y "ortócrona (orthochronous)" significa \(\Lambda^0{}_0 \geq 1\) (preserva la orientación del tiempo). "No propia" y "no ortócrona" son las negaciones respectivas. Con esta regla de nomenclatura en mente, mira Tabla 2.2「Las 4 componentes conexas del grupo de Lorentz」.
Tabla 2.2: Las 4 componentes conexas del grupo de Lorentz
| Componente conexa | Condición | Transformaciones incluidas |
|---|---|---|
| Propia ortócrona (proper orthochronous) \(L_+^\uparrow\) | \(\det\Lambda = +1\) y \(\Lambda^0{}_0 \geq 1\) | Rotaciones y boosts ordinarios |
| No propia ortócrona \(L_-^\uparrow\) | \(\det\Lambda = -1\) y \(\Lambda^0{}_0 \geq 1\) | Incluye la paridad \(P\) |
| Propia no ortócrona \(L_+^\downarrow\) | \(\det\Lambda = +1\) y \(\Lambda^0{}_0 \leq -1\) | Incluye \(PT\) (paridad × inversión temporal) |
| No propia no ortócrona \(L_-^\downarrow\) | \(\det\Lambda = -1\) y \(\Lambda^0{}_0 \leq -1\) | Incluye la inversión temporal \(T\) |
El panorama completo está resumido en Fig. 2.2「Estructura del grupo de Lorentz y del grupo de Poincaré」. En esa figura también aparece el grupo de Poincaré — que resulta de añadir las traslaciones espacio-temporales (1 dirección temporal + 3 direcciones espaciales = 4 parámetros) a las transformaciones de Lorentz, formando un grupo de 10 parámetros en total — pero eso lo trataremos en detalle en 2.4「Grupo de Poincaré — Transformaciones de Lorentz + traslaciones espacio-temporales」.
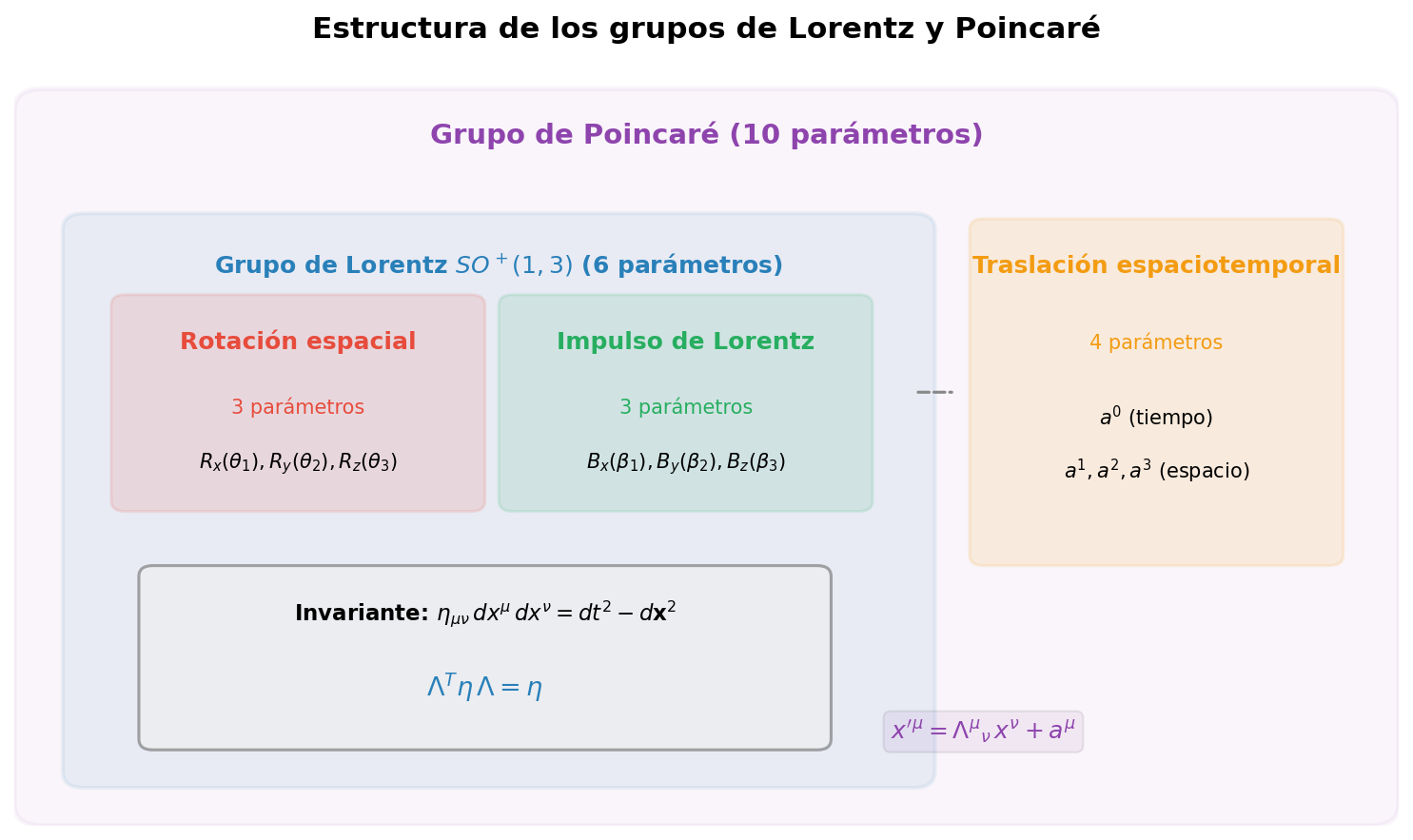
Fig. 2.2: Estructura del grupo de Lorentz y del grupo de Poincaré. El grupo de Lorentz se divide en 4 componentes conexas, y el grupo de Lorentz propio ortócrono \(SO^+(1,3)\) es un grupo continuo con 3 rotaciones + 3 boosts = 6 parámetros. El grupo de Poincaré (10 parámetros), que añade 4 parámetros de traslación espacio-temporal, se explica en detalle en 2.4「Grupo de Poincaré — Transformaciones de Lorentz + traslaciones espacio-temporales」.
🟡 Lina: Lo más importante en la teoría cuántica de campos es el grupo de Lorentz propio ortócrono \(SO^+(1,3)\) (\(L_+^\uparrow\)) — el conjunto de transformaciones que preservan tanto la orientación del espacio como la del tiempo. Descomponiendo el significado del símbolo: \(S\) es special (\(\det\Lambda = +1\)), \(O\) es la generalización de orthogonal — mientras que el grupo de rotaciones ordinario satisfacía \(R^T R = \mathbf{1}\) (preserva la métrica euclídea \(\delta_{ij}\)), aquí se extiende a \(\Lambda^T \eta\, \Lambda = \eta\) (preserva la métrica de Minkowski \(\eta_{\mu\nu}\)) —, \(+\) es orthochronous (preserva la orientación temporal), y \((1,3)\) indica 1 dimensión temporal y 3 espaciales. \(SO^+(1,3)\) tiene 3 parámetros de rotación + 3 parámetros de boost = 6 parámetros, y es un grupo cuyos parámetros varían continuamente (grupo continuo).
🔵 Kai: "Grupo continuo" es como el grupo de rotaciones donde puedes variar el ángulo gradualmente, ¿verdad? ¿Tiene algún nombre especial?
🟡 Lina: Sí. La definición de grupo — cerrado, asociativo, con elemento identidad e inverso — se trató en Relatividad General Relatividad General Cap. 4. En matemáticas, los grupos cuyos parámetros pueden variarse continuamente se llaman grupos de Lie. Concretamente, cuando cambias el ángulo de rotación \(\theta\), las componentes de la matriz de rotación \(\cos\theta\) y \(\sin\theta\) devuelven valores finitos sin importar cuántas veces las derives respecto a \(\theta\), ¿verdad? Los grupos en los que "al variar los parámetros de la transformación, las componentes de la matriz cambian suavemente (pueden derivarse cualquier número de veces)" se llaman grupos de Lie. En este capítulo puedes pensar que significa prácticamente lo mismo que "grupo cuyos parámetros pueden variarse continua y gradualmente". Solo recuerda el nombre — en las referencias es frecuente la expresión "el grupo de Lorentz es un grupo de Lie", y este término también aparecerá cuando tratemos transformaciones infinitesimales en capítulos posteriores.
⚪ Mei: Es decir, en el mismo sentido en que el grupo de rotaciones permite variar continuamente el ángulo, el grupo de Lorentz también permite variar continuamente sus parámetros y por eso es un grupo de Lie.
🟡 Lina: Exacto. Por cierto, las transformaciones con \(\det\Lambda = -1\) corresponden a la paridad (parity, inversión espacial) \(P\), y las que tienen \(\Lambda^0{}_0 \leq -1\) corresponden a la inversión temporal (time reversal) \(T\). Estas no se conectan con \(SO^+(1,3)\) mediante parámetros continuos — son transformaciones discretas (discrete transformations).
🔵 Kai: ¡Ah, las simetrías discretas que estudiamos en Mecánica Cuántica Mecánica Cuántica Cap. 26! La violación de paridad, la violación de CP... Pero, ¿por qué se tratan aparte solo las transformaciones discretas? ¿Qué es esencialmente diferente de las continuas?
🟡 Lina: Con la metáfora de las "islas" de antes, las transformaciones continuas te permiten caminar dentro de la misma isla, pero las transformaciones discretas son como saltar a otra isla — no se puede llegar variando gradualmente los parámetros, así que no hay más remedio que tratarlas como "cosas distintas". Y en la teoría cuántica de campos, "si la simetría \(P\) o \(T\) está rota o no" es una cuestión experimentalmente crucial — la violación de P en la interacción débil (1956, Lee-Yang), la violación de CP (1964, Cronin-Fitch) son ejemplos. Los detalles se tratarán en capítulos posteriores.
⚪ Mei: Es decir, las transformaciones continuas permiten moverse dentro de la misma componente conexa variando los parámetros, pero las discretas cruzan componentes conexas y no se alcanzan continuamente — por eso también físicamente es necesario tratarlas como simetrías distintas.
✅ Verificación de comprensión: ¿Cuántos parámetros continuos tiene el grupo de Lorentz propio ortócrono \(SO^+(1,3)\) en total? Indica también el desglose.
Respuesta
6 parámetros. Rotaciones espaciales: 3 (alrededor de los ejes \(x, y, z\)) + boosts de Lorentz: 3 (en las direcciones \(x, y, z\)).
2.4 Grupo de Poincaré — Transformaciones de Lorentz + traslaciones espacio-temporales¶
🟡 Lina: Lo que es verdaderamente importante en la física no es solo el grupo de Lorentz, sino el grupo que resulta de añadirle las traslaciones espacio-temporales (spacetime translations).
\(a^\mu\) es un 4-vector constante (la cantidad de traslación). El grupo formado por todas estas transformaciones se llama grupo de Poincaré (Poincaré group).
🔵 Kai: La traslación tiene 4 parámetros (\(a^0, a^1, a^2, a^3\)) y la transformación de Lorentz tiene 6 parámetros, así que en total son 10 parámetros.
🟡 Lina: Exacto. Y el requisito fundamental de la teoría cuántica de campos es el siguiente:
Las ecuaciones de la teoría cuántica de campos deben mantener su forma bajo las transformaciones del grupo de Poincaré.
Este requisito restringe la estructura de la teoría de manera sorprendentemente fuerte. Dicho de otra forma, la dificultad del punto de partida de Mecánica Cuántica Cap. 27 — que "la ecuación de Schrödinger no es covariante de Lorentz" — se puede evitar exigiendo la invariancia de Poincaré desde el principio. En Mecánica Cuántica Cap. 27 se partió de darse cuenta de que "las ecuaciones existentes no son covariantes de Lorentz" y luego se buscaron la ecuación de Klein-Gordon y la ecuación de Dirac, pero en la teoría cuántica de campos se construyen las ecuaciones tomando desde el inicio la invariancia de Poincaré como principio de diseño — el orden se invierte.
⚪ Mei: En lugar de corregir a posteriori, se toma la simetría como punto de partida desde el principio.
🟡 Lina: De hecho, Wigner (1939) llevó esta perspectiva al extremo y transformó la pregunta "¿qué es una partícula en la teoría cuántica de campos?" en una pregunta matemática.
🔵 Kai: ¿Se puede responder qué es una partícula con matemáticas?
🟡 Lina: Sí se puede. La idea es la siguiente — si la naturaleza posee simetría de Poincaré, entonces los estados cuánticos también deben "comportarse correctamente" bajo las transformaciones de Poincaré. Es decir, las reglas de cómo cambia un estado cuántico cuando se aplica una rotación o un boost deben estar determinadas.
Primero captemos la intuición con un ejemplo concreto. Al rotar un vector \((v_x, v_y)\) en el plano 2D un ángulo \(\theta\):
¿Ves? A la operación abstracta "rotación" le estamos asignando una matriz concreta.
🔵 Kai: Sí, para cada ángulo de rotación se determina una matriz.
🟡 Lina: Así es. Además, "rotar 30° y luego 45°" da el mismo resultado que "rotar 75°", y de la misma manera, el resultado de aplicar dos transformaciones seguidas coincide con el producto de las matrices correspondientes — a esta correspondencia que preserva esa propiedad la llamamos representación (representation). Dicho de forma más digerible, "asignar una matriz a cada elemento del grupo (aquí, a cada ángulo de rotación), de modo que la multiplicación del grupo (composición de transformaciones) se reproduzca con la multiplicación de matrices" es una representación.
🔵 Kai: Ya veo, es hacer que las matrices "representen" la operación de rotación. Pero, ¿qué pasa con la matriz para operaciones distintas a rotaciones — por ejemplo para cantidades escalares?
🟡 Lina: Buena pregunta. Incluso para la misma "rotación", si el objeto sobre el que actúa es diferente, el tamaño y contenido de la matriz cambian. Si actúa sobre un vector 3D, será una matriz \(3 \times 3\); si actúa sobre un escalar (un simple número), será "no hacer nada" (la matriz identidad \(1 \times 1\)). Una cantidad escalar como la temperatura no cambia al rotar, así que la "matriz" correspondiente es simplemente el número \(1\) — y eso también es una representación legítima. Es decir, para un mismo grupo pueden existir múltiples representaciones de diferentes tamaños.
⚪ Mei: Para el mismo grupo, la representación cambia según "sobre qué actúa" — si es un vector en el plano 2D es \(2 \times 2\), si es un vector 3D es \(3 \times 3\), si es un escalar es \(1 \times 1\).
🟡 Lina: Exacto. Por cierto, déjame dar primero el significado intuitivo de "irreducible": entre las representaciones hay algunas que "en realidad son una colección de representaciones más pequeñas que se pueden descomponer". Veamos un ejemplo concreto. Consideremos rotaciones en 3D y supongamos que agrupamos cuatro cantidades — la temperatura \(T\) y el vector velocidad \((v_x, v_y, v_z)\) — como un vector de 4 componentes. Al rotar, las 3 componentes de la velocidad se mezclan entre sí, pero la temperatura es un escalar y no cambia. Es decir, si escribimos la matriz de rotación como \(4 \times 4\):
tiene esta forma — el bloque \(1 \times 1\) superior izquierdo (temperatura) y el bloque \(3 \times 3\) inferior derecho (velocidad) se mueven independientemente y no se mezclan, ¿verdad? Cuando una matriz grande tiene la forma "un bloque cuadrado pequeño arriba a la izquierda y otro bloque cuadrado pequeño abajo a la derecha, con todo lo demás (arriba a la derecha y abajo a la izquierda) siendo cero", lo llamamos diagonal por bloques. En este ejemplo la representación \(4 \times 4\) se descompone en \(1 \times 1\) (escalar) y \(3 \times 3\) (vector) — esta es una representación reducible (reducible). Al contrario, la matriz de rotación \(3 \times 3\) no se puede dividir en bloques más pequeños sin importar cómo se elija la base (es decir, sin importar cómo se roten los ejes coordenados) — esta es una representación irreducible (irreducible), "la unidad mínima que ya no se puede descomponer más". En términos de química, sería como descomponer una molécula en los átomos que ya no se pueden dividir más.
🔵 Kai: Ya veo, como descomponer una molécula en átomos. Irreducible = unidad mínima que no se puede separar más.
🟡 Lina: Y en mecánica cuántica, los estados de un sistema físico se representan con "vectores de estado" (ver Mecánica Cuántica). Así que con la misma idea, buscamos una forma de escribir cada transformación de Poincaré (rotación, boost, traslación) como una operación concreta de "así cambia el estado cuántico" — ya que si un observador rota, el estado cuántico también debe cambiar correspondientemente. Y dentro de eso, "la unidad mínima que ya no se puede dividir en partes más pequeñas" — es decir, el conjunto mínimo de estados que se mezclan entre sí bajo cualquier transformación — lo llamamos representación irreducible. El punto clave aquí es que buscamos el "conjunto mínimo que se mezcla" bajo el grupo de Poincaré completo, incluyendo no solo rotaciones sino también boosts y traslaciones — por qué esto se conecta con solo dos etiquetas, masa y espín, lo explicaré después de ver el resultado de Wigner.
El resultado que encontró Wigner es sorprendentemente simple — primero enuncio la conclusión y luego explico por qué es así. El resultado está resumido en Fig. 2.3「Clasificación de Wigner: correspondencia entre representaciones irreducibles del grupo de Poincaré y partículas」.
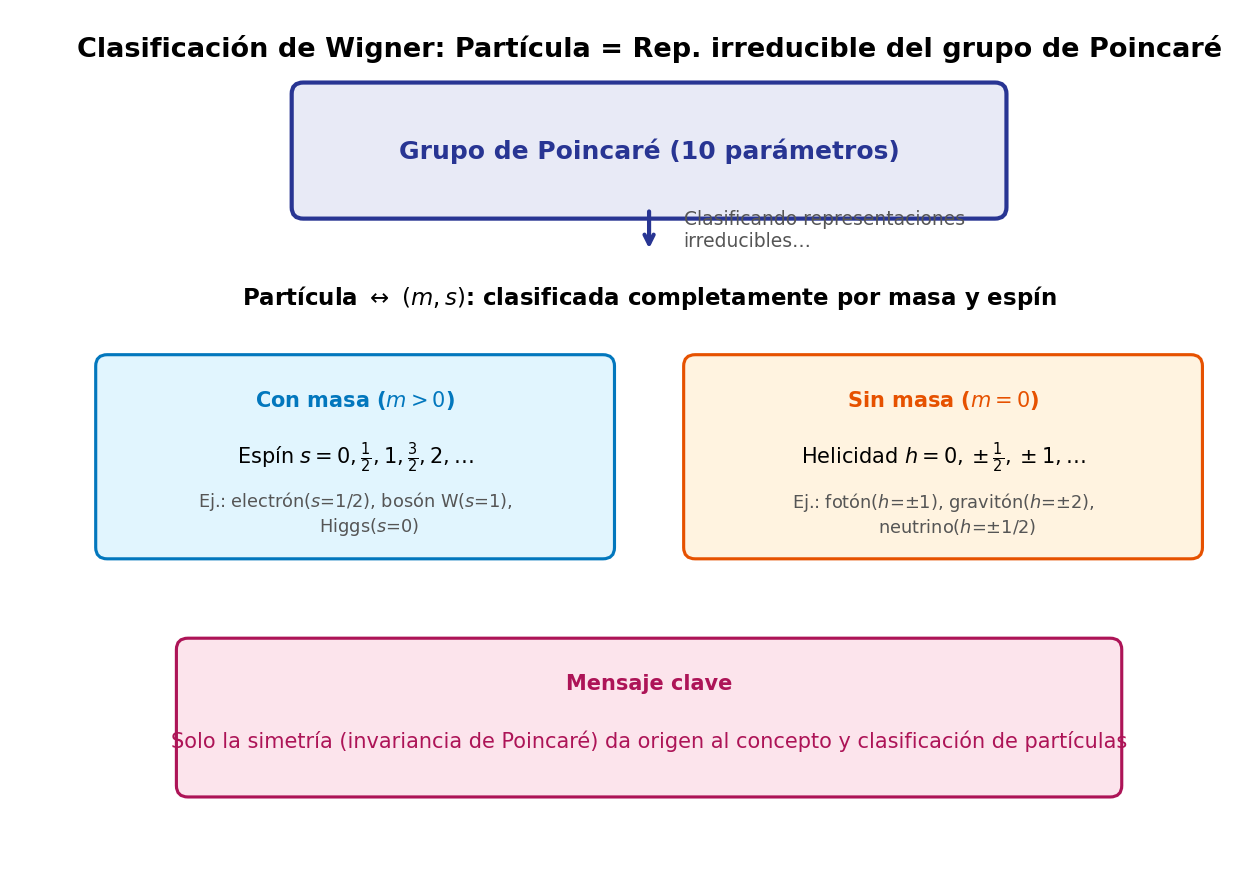
Fig. 2.3: Clasificación de Wigner: correspondencia entre representaciones irreducibles del grupo de Poincaré y partículas. Las partículas se clasifican completamente con solo dos etiquetas (masa \(m\), espín \(s\)). El concepto y la clasificación de partículas se derivan únicamente de la simetría de Poincaré.
Partícula = representación irreducible del grupo de Poincaré (representación mínima que no se puede descomponer más) = clasificada por las etiquetas (masa, espín)
Con solo dos números \((m, s)\) se determinan completamente las propiedades de un estado de una partícula. Este es el resultado conocido como clasificación de Wigner (Wigner's classification). "Por qué se determina con solo dos" lo explicaré enseguida respondiendo a la pregunta de Kai. Concretamente:
- \(m > 0\): espín \(s = 0, 1/2, 1, 3/2, \ldots\)
- \(m = 0\): helicidad \(h = 0, \pm 1/2, \pm 1, \ldots\)
⚪ Mei: Solo en el caso de masa cero se usa "helicidad" en vez de "espín". ¿Cuál es la diferencia?
🟡 Lina: La helicidad (helicity) es la proyección del espín en la dirección del movimiento de la partícula — es decir, una cantidad que indica "si el espín apunta en la dirección de movimiento o en la opuesta". Para una partícula con masa, un observador puede adelantarla y así la "dirección de movimiento" se invierte, por lo que la helicidad depende del observador. Pero una partícula de masa cero viaja a la velocidad de la luz y nadie puede adelantarla — por eso la helicidad se convierte en un invariante que no depende del observador, y se puede usar como etiqueta para clasificar partículas en lugar del espín.
Los detalles se tratan en Apéndice B, pero es importante retener que "el concepto de partícula emerge solo de la simetría de Poincaré".
✅ Verificación de comprensión: Según la clasificación de Wigner, ¿con qué etiquetas se clasifican las partículas en la teoría cuántica de campos? Además, ¿de qué simetría se deriva esta clasificación?
Respuesta
Las partículas se clasifican con las 2 etiquetas (masa \(m\), espín \(s\)). Esta clasificación se deriva de investigar las representaciones irreducibles del grupo de Poincaré. Es decir, el concepto y la clasificación de partículas emergen solo de la simetría de Poincaré (la simetría de transformaciones de Lorentz + traslaciones espacio-temporales).
🔵 Kai: Es impresionante... Pero tengo dos dudas. Primero, todavía no me queda claro lo de "representación irreducible". "La unidad mínima que no se puede dividir en partes más pequeñas", concretamente ¿en qué situación? Y además, ¿por qué una partícula queda completamente determinada con solo dos cantidades, masa y espín? Me parece que deberían necesitarse más números cuánticos...
🟡 Lina: Buenas preguntas. Para captar primero la intuición de "irreducible", empecemos con un ejemplo sencillo solo con el grupo de rotaciones. Considera un electrón de espín \(1/2\). Tiene dos estados: "hacia arriba" y "hacia abajo". Al rotar el espacio, estos dos estados se mezclan entre sí — en el lenguaje de la mecánica cuántica se convierten en superposiciones. Lo que era "hacia arriba" se convierte en un estado de superposición "un poco hacia arriba + un poco hacia abajo". Pero por mucho que combines rotaciones, nunca sales fuera de estos dos estados — jamás se necesita un tercer estado. Es decir, este conjunto de 2 estados es "la unidad mínima que no se puede dividir más" respecto al grupo de rotaciones — una representación irreducible.
🔵 Kai: Entiendo, los dos estados se mezclan con la rotación pero se cierran dentro de esos dos — eso es "irreducible".
🟡 Lina: Así es. Pero este es un ejemplo solo con el grupo de rotaciones. En el grupo de Poincaré hay que considerar también boosts y traslaciones. Al añadir traslaciones, el momento \(\mathbf{p}\) cambia; con boosts, el momento también cambia — es decir, estados con diferentes momentos se mezclan entre sí.
🔵 Kai: Entonces, ¿no se mezclarán todos los estados con todos los momentos posibles y será imposible clasificar?
🟡 Lina: Buena preocupación. Pero recuerda la condición de capa de masa \(E^2 - |\mathbf{p}|^2 = m^2\). Con boosts y traslaciones \(E\) y \(\mathbf{p}\) cambian, pero la combinación \(m^2 = E^2 - |\mathbf{p}|^2\) es un invariante de Lorentz y no cambia. Por eso "el conjunto de estados con la misma masa \(m\)" se cierra bajo la transformación. Además, dentro de ese conjunto, la magnitud del espín \(s\) también es invariante — al hacer un boost la dirección del espín puede cambiar, pero su magnitud (\(s = 0, 1/2, 1, \ldots\)) no cambia. Como resultado, "el conjunto de estados con la misma masa y el mismo espín" forma una representación irreducible — por eso las partículas se clasifican con \((m, s)\).
🔵 Kai: Con solo unir la relatividad y la teoría cuántica, hasta se determina qué es una partícula... Pero, ¿y la carga eléctrica? El electrón y el positrón tienen la misma masa y espín pero son partículas distintas, ¿no?
🟡 Lina: Buena observación. Los números cuánticos internos como la carga eléctrica o la carga de color provienen de una simetría diferente al grupo de Poincaré (la simetría gauge). La clasificación de Wigner nos dice "las etiquetas de partículas determinadas solo por la simetría del espacio-tiempo" — los números cuánticos internos son información adicional que se añade sobre eso. La simetría gauge se tratará en detalle en capítulos posteriores.
🟡 Lina: Resumo la discusión hasta aquí. La lógica de la clasificación de Wigner es: (1) Los estados cuánticos se mezclan bajo transformaciones de Poincaré → (2) La masa \(m\) es un invariante de Lorentz así que "los estados con el mismo \(m\)" se cierran → (3) Dentro de ellos, el comportamiento bajo rotaciones queda determinado por el espín \(s\) → (4) Al final \((m, s)\) se convierte en la etiqueta de la representación irreducible.
⚪ Mei: Primero se divide por la masa y luego se subdivide por el espín — una clasificación en dos etapas.
🔵 Kai: Entonces, ¿las partículas con espín \(3/2\) o \(2\) pueden existir en principio?
🟡 Lina: En principio sí. De hecho, se conocen partículas de espín \(3/2\) (como el barión \(\Delta\)) y partículas de espín \(2\) (el gravitón, si existe). Como representaciones del grupo de Poincaré cualquier espín está permitido, pero qué espines se realizan en la naturaleza está determinado por los detalles de las interacciones — eso es tema de capítulos posteriores.
✅ Verificación de comprensión: Explica que el número de parámetros del grupo de Poincaré es 10, indicando el desglose por tipo de transformación.
Respuesta
Rotaciones espaciales: 3 (alrededor de los ejes \(x, y, z\)) + boosts de Lorentz: 3 (en las direcciones \(x, y, z\)) + traslaciones espacio-temporales: 4 (en las direcciones \(t, x, y, z\)) = total 10 parámetros.
2.5 Covariancia de Lorentz y "balance de índices"¶
🟡 Lina: Ahora que hemos identificado el grupo de Poincaré como "la simetría que gobierna la teoría cuántica de campos", pasemos a un asunto práctico: cómo usarlo en los cálculos del día a día. Se trata de la técnica de determinar si una ecuación es covariante de Lorentz solo mirando la posición de los índices. Una vez que la domines, las cientos de fórmulas que aparecerán en los capítulos siguientes serán mucho más legibles.
Rango de tensores y reglas de transformación¶
🟡 Lina: Clasificamos las magnitudes físicas según "cómo cambian bajo transformaciones de Lorentz". Esto es una recapitulación del contenido de Relatividad General Cap. 4 — lo resumo en Tabla 2.3「Clasificación por rango tensorial y regla de transformación」.
Tabla 2.3: Clasificación por rango tensorial y regla de transformación
| Nombre | Número de índices | Comportamiento bajo transformación de Lorentz | Ejemplo |
|---|---|---|---|
| Escalar | 0 | No cambia | Masa \(m\), intervalo invariante \(s^2\) |
| Vector | 1 | \(V^\mu \to \Lambda^\mu{}_\nu\, V^\nu\) | Posición \(x^\mu\), momento \(p^\mu\) |
| Tensor de rango 2 | 2 | \(T^{\mu\nu} \to \Lambda^\mu{}_\alpha\, \Lambda^\nu{}_\beta\, T^{\alpha\beta}\) | Campo electromagnético \(F^{\mu\nu}\) |
A un tensor de rango \(n\) se le aplican \(n\) factores de \(\Lambda\) — esta es la regla de transformación tensorial.
🔵 Kai: Cuantos más índices, más compleja se vuelve la transformación, pero el patrón es el mismo. El número de \(\Lambda\) coincide con el número de índices.
El requisito de covariancia de Lorentz¶
🟡 Lina: Enuncio el principio más importante de la teoría cuántica de campos en términos prácticos.
Las ecuaciones de campo deben ser covariantes de Lorentz (Lorentz covariant).
Concretamente: la posición y el número de índices deben coincidir en ambos lados.
🔵 Kai: Es decir que ambos lados deben ser el mismo tipo de tensor, ¿verdad?
🟡 Lina: Exacto. Por ejemplo, si una ecuación tiene la forma
ambos lados son vectores. Bajo una transformación de Lorentz, a ambos lados se les aplica el mismo \(\Lambda^\mu{}_\nu\), así que si \(A^\nu = B^\nu\) se cumple, \(A'^\mu = B'^\mu\) también se cumple automáticamente. La forma de la ecuación es la misma en cualquier sistema de referencia inercial. Al contrario, si el lado izquierdo fuera un vector y el derecho un escalar, al hacer una transformación de Lorentz solo cambiaría el lado izquierdo mientras el derecho permanecería igual — tal ecuación no tiene sentido físico.
⚪ Mei: Es decir, una ecuación en la que los tipos de índices no coinciden se rompe en cuanto cambias de sistema de referencia inercial.
🟡 Lina: En los cálculos de la teoría cuántica de campos, cada vez que escribes una ecuación verificas si "el número y la posición de los índices coinciden en ambos lados". Esto es el balance de índices.
🔵 Kai: La notación de índices no es solo una abreviatura, sino un mecanismo que garantiza automáticamente la covariancia de Lorentz.
🟡 Lina: Exactamente así. Esta es la razón principal por la que se usa la notación de índices en la teoría cuántica de campos. He resumido los puntos clave de las reglas de verificación en Fig. 2.4「Verificación de covariancia de Lorentz mediante balance de índices」, revísalo. El punto es que los índices emparejados arriba y abajo (índices contraídos) desaparecen, y si la posición y el número de los índices libres restantes coinciden en ambos lados, entonces es covariante de Lorentz — esta es la regla básica de verificación.
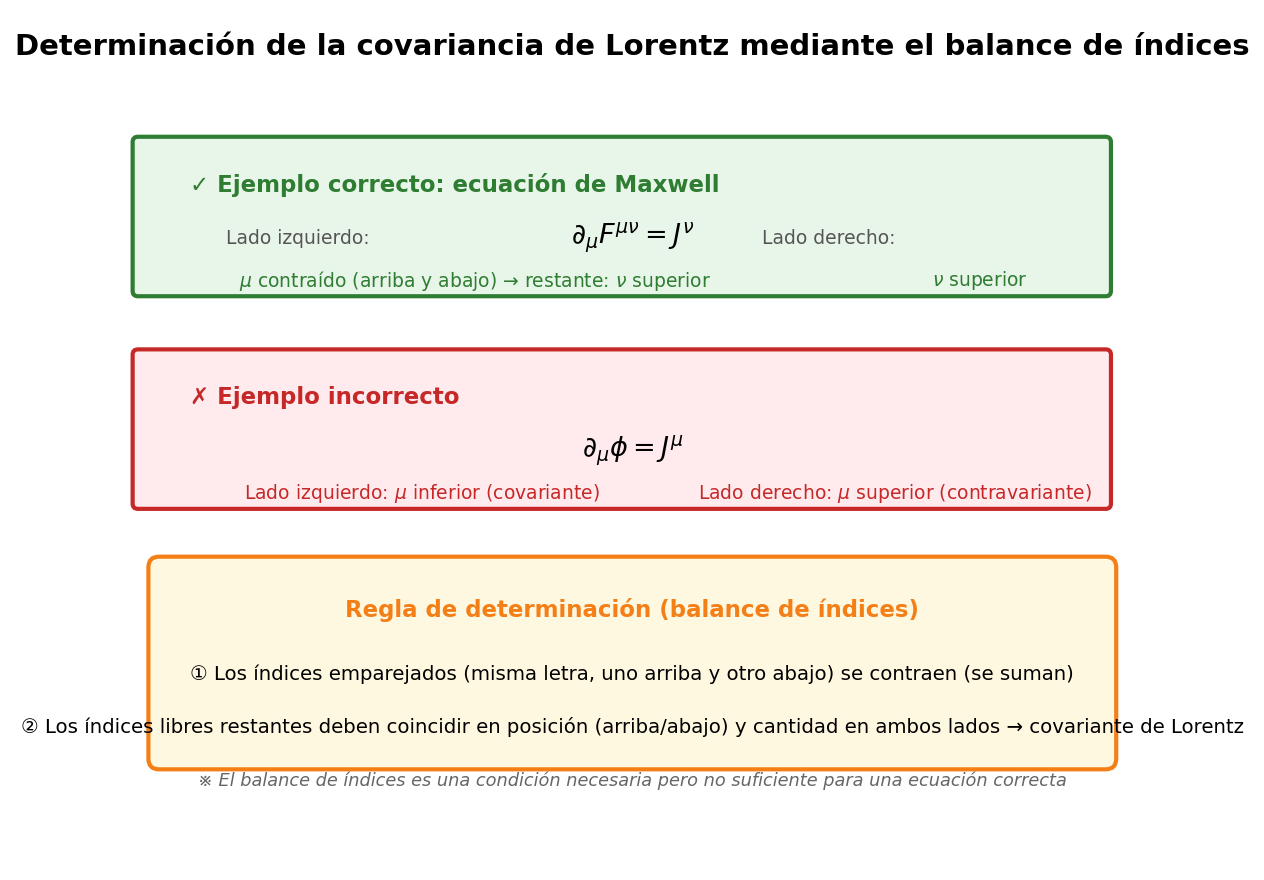
Fig. 2.4: Verificación de covariancia de Lorentz mediante balance de índices. Los índices emparejados arriba y abajo se contraen y desaparecen; si la posición y el número de los índices libres restantes coinciden en ambos lados, es covariante de Lorentz. Nótese que esta es una condición necesaria pero no suficiente.
El d'Alembertiano y la ecuación de Klein-Gordon¶
🟡 Lina: Hagamos un ejemplo concreto. Primero definamos el operador de derivación como un 4-vector.
🔵 Kai: Espera, \(\partial_\mu\) tiene el índice abajo (vector covariante). ¿Por qué?
🟡 Lina: Porque es la derivada respecto a \(x^\mu\) (índice arriba). Veámoslo concretamente. La transformación de Lorentz era \(x'^\mu = \Lambda^\mu{}_{\nu}\, x^\nu\). Escribiendo la transformación inversa — es decir, la que obtiene \(x\) a partir de \(x'\) — como \(\Lambda^{-1}\), tenemos \(x^\nu = (\Lambda^{-1})^\nu{}_{\mu}\, x'^\mu\) (lo que significa que aplicar \(\Lambda\) y luego \(\Lambda^{-1}\) devuelve al estado original). Aquí uso la regla de la cadena para varias variables. La regla de la cadena de una variable que aprendiste en el instituto era \(\frac{df}{dx} = \frac{df}{du}\frac{du}{dx}\). En el caso multivariable, como \(f\) depende de \(x'^\mu\) a través de las 4 variables \(x^0, x^1, x^2, x^3\), hay que sumar las contribuciones de cada camino: \(\frac{\partial f}{\partial x'^\mu} = \frac{\partial x^0}{\partial x'^\mu}\frac{\partial f}{\partial x^0} + \frac{\partial x^1}{\partial x'^\mu}\frac{\partial f}{\partial x^1} + \cdots = \sum_\nu \frac{\partial x^\nu}{\partial x'^\mu}\frac{\partial f}{\partial x^\nu}\). Esta es la regla de la cadena multivariable. El \(\frac{\partial}{\partial x^\mu}\) que estamos usando es la derivada parcial — la operación de derivar respecto a una sola variable manteniendo las demás fijas (introducida en Relatividad General Relatividad General Cap. 4). La regla de la cadena multivariable es la extensión natural de esa derivada parcial.
🔵 Kai: Se extiende la regla de la cadena de una variable a 4 variables y se suman todas las contribuciones.
🟡 Lina: Así es. Ahora, \(x^\nu = (\Lambda^{-1})^\nu{}_{\mu}\, x'^\mu\) es una expresión lineal en \(x'^\mu\) (\((\Lambda^{-1})^\nu{}_{\mu}\) es una constante), así que al derivar parcialmente respecto a \(x'^\mu\) obtenemos \(\frac{\partial x^\nu}{\partial x'^\mu} = (\Lambda^{-1})^\nu{}_{\mu}\) (igual que derivar \(ax\) respecto a \(x\) da \(a\)). Sustituyendo esto en la regla de la cadena y tratando el resultado como operador sin escribir \(f\): \(\frac{\partial}{\partial x'^\mu} = (\Lambda^{-1})^\nu{}_{\mu}\frac{\partial}{\partial x^\nu}\) (donde la suma es sobre \(\nu\)). Es decir, a \(\partial_\mu\) se le aplica no \(\Lambda\) sino la inversa \(\Lambda^{-1}\). Como aprendimos en Relatividad General Relatividad General Cap. 4, los vectores contravariantes (índice arriba) \(V^\mu\) se transforman como \(V'^\mu = \Lambda^\mu{}_\nu V^\nu\) con \(\Lambda\), y los vectores covariantes (índice abajo) \(W_\mu\) se transforman como \(W'_\mu = (\Lambda^{-1})^\nu{}_\mu W_\nu\) con \(\Lambda^{-1}\). \(\partial_\mu\) sigue precisamente esta regla de transformación covariante.
⚪ Mei: Entiendo, como \(\partial_\mu\) se transforma con \(\Lambda^{-1}\) lleva índice abajo — es un vector covariante.
🟡 Lina: Exacto. Intuitivamente, si haces más fina la escala de coordenadas, los valores de las coordenadas crecen pero las derivadas disminuyen — se aplica el "inverso" de la transformación.
Para subir el índice se usa la métrica inversa \(\eta^{\mu\nu}\). En el caso de la métrica de Minkowski, \(\eta^{\mu\nu}\) es la inversa de \(\eta_{\mu\nu}\). La inversa de una matriz diagonal es poner los recíprocos de cada elemento diagonal (\(\text{diag}(a,b,c,d)^{-1} = \text{diag}(1/a, 1/b, 1/c, 1/d)\)), así que \(1/(+1) = +1\), \(1/(-1) = -1\) y \(\eta^{\mu\nu} = \text{diag}(+1,-1,-1,-1)\) — numéricamente coincide con \(\eta_{\mu\nu}\). Usando esto:
El signo de las derivadas espaciales se invierte (esto es opuesto al estilo GR). Con esto definimos el d'Alembertiano (d'Alembertian).
🔵 Kai: Al subir el índice, las componentes espaciales adquieren un signo negativo. En el estilo QFT la componente temporal se mantiene positiva.
🟡 Lina: Usando la regla de contracción sumando \(\mu = 0, 1, 2, 3\):
De (2.12) y (2.13), \(\partial^0 = \partial_0 = \frac{\partial}{\partial t}\), \(\partial^i = -\frac{\partial}{\partial x^i}\), \(\partial_i = \frac{\partial}{\partial x^i}\), así que sustituyendo cada término:
Es decir, en las componentes espaciales el signo negativo de \(\partial^i\) (que viene de (2.13)) y el signo positivo de \(\partial_i\) (que viene de (2.12)) se multiplican entre sí, dando un signo negativo a cada término espacial.
⚪ Mei: La segunda derivada temporal es positiva y las segundas derivadas espaciales son negativas — exactamente la misma estructura de signos que el "intervalo espacio-temporal \(ds^2 = dt^2 - d\mathbf{x}^2\)".
🟡 Lina: Nota: en Relatividad General Relatividad General Cap. 19 de la parte de GR de este libro se usaba la métrica estilo GR \((-,+,+,+)\) y se definía \(\Box = \eta^{\mu\nu}\partial_\mu\partial_\nu\) (como \(\partial^\mu\partial_\mu = \eta^{\mu\nu}\partial_\mu\partial_\nu\), es la misma cosa). En el estilo GR \(\eta^{00} = -1\) así que \(\Box = -\partial^2/\partial t^2 + \nabla^2\). En el estilo QFT \((+,-,-,-)\) de este capítulo \(\eta^{00} = +1\), así que con la misma definición \(\Box = \partial^\mu\partial_\mu\) el resultado es \(\Box = \partial^2/\partial t^2 - \nabla^2\), con signo opuesto. El mismo símbolo \(\Box\) tiene contenido diferente según la convención de signos de la métrica. Además, algunos libros de texto definen \(\Box \equiv -\eta^{\mu\nu}\partial_\mu\partial_\nu\) (en el caso estilo GR) incluyendo un signo negativo en la definición misma, de modo que con ambas convenciones de métrica se obtiene la forma \(\Box = \partial^2/\partial t^2 - \nabla^2\). Al consultar otros libros de texto verifica la convención de signos.
🔵 Kai: \(\partial^\mu \partial_\mu\) contrae el mismo índice arriba y abajo. ¿Eso da un escalar?
🟡 Lina: Exacto. Cuando se contrae el mismo índice arriba y abajo, ese índice desaparece y el resultado es un escalar de Lorentz — el mismo mecanismo por el que \(A^\mu B_\mu\) era un escalar. Por eso \(\Box = \partial^\mu \partial_\mu\) es automáticamente un operador escalar de Lorentz. El resultado de aplicar un operador escalar a un campo escalar \(\phi\) también sigue siendo escalar — porque los índices no aumentan ni disminuyen.
⚪ Mei: Es decir, el operador \(\Box\), cuyos índices desaparecen todos por contracción, es un operador escalar, y al actuar sobre el campo escalar \(\phi\) los índices no aumentan — por eso \(\Box\phi\) también es escalar. Se puede determinar la transformación solo contando el número de índices.
🟡 Lina: Exacto. La ecuación de Klein-Gordon es:
🔵 Kai: En Mecánica Cuántica Cap. 27 estaba escrita como
¿Eso y la (2.15) de ahora son lo mismo? ¿Dónde desaparecieron \(c\) y \(\hbar\)...?
🟡 Lina: Prueba a sustituir las unidades naturales \(c = \hbar = 1\).
🔵 Kai: A ver, poniendo \(c = 1\) queda \(1/c^2 = 1\) así que el primer término es \(\frac{\partial^2 \phi}{\partial t^2}\), y poniendo \(\hbar = 1\) queda \(m^2 c^2/\hbar^2 = m^2\), entonces... \(\frac{\partial^2 \phi}{\partial t^2} - \nabla^2 \phi + m^2 \phi = 0\). ¡Ah, eso es exactamente \((\Box + m^2)\phi = 0\)!
⚪ Mei: Solo con usar unidades naturales, esa ecuación tan larga se vuelve así de compacta.
🟡 Lina: Es el poder de las unidades naturales + la notación de índices. Observando (2.15), ambos lados son escalares (\(\Box\) y \(m^2\) son operadores escalares, \(\phi\) es un campo escalar, y 0 también es escalar). El balance de índices se cumple → automáticamente es covariante de Lorentz — se puede verificar de un vistazo.
Aplicación: Práctica de verificación del balance de índices¶
🟡 Lina: Veamos algunas ecuaciones y determinemos su covariancia de Lorentz.
Ejemplo 1: Ecuaciones de Maxwell
Lado izquierdo: \(\partial_\mu\) tiene índice abajo \(\mu\), \(F^{\mu\nu}\) tiene índices arriba \(\mu, \nu\). \(\mu\) se contrae arriba y abajo y desaparece, quedando un solo índice arriba \(\nu\). Lado derecho: \(J^\nu\) también tiene un solo índice arriba \(\nu\). → Ambos lados son el mismo tipo de 4-vector → Covariante de Lorentz ✓
Ejemplo 2: Ejemplo de ecuación incorrecta
Lado izquierdo: un índice abajo \(\mu\) (vector covariante). Lado derecho: un índice arriba \(\mu\) (vector contravariante). → Las posiciones de los índices no coinciden → No es covariante de Lorentz ✗
🔵 Kai: ¡Vaya, solo mirando arriba y abajo se puede determinar! Pero, si el balance de índices se cumple, ¿es necesariamente una ecuación física correcta? También puede haber ecuaciones con buen balance pero que sean físicamente incorrectas, ¿no?
🟡 Lina: Muy perceptivo. El balance de índices es una condición necesaria pero no suficiente. Una ecuación sin balance de índices está claramente mal. Pero incluso con balance correcto, si los coeficientes o signos están equivocados, no es físicamente correcta. Piensa en el balance de índices como un "filtro que descarta los errores obvios".
✅ Verificación de comprensión: ¿El que el balance de índices se cumpla es condición suficiente o condición necesaria para que una ecuación sea covariante de Lorentz? Explica brevemente la razón.
Respuesta
Es condición necesaria pero no suficiente. Si el balance de índices no se cumple, con certeza no es covariante de Lorentz, pero aunque se cumpla, si los coeficientes o signos están equivocados la ecuación puede no ser físicamente correcta. El balance de índices funciona como un "filtro que descarta los errores obvios".
🟡 Lina: Así es. De aquí en adelante aparecerán cientos de fórmulas, pero solo verificando "si el balance de índices se cumple" podrás prevenir muchos errores de cálculo. Es una técnica que usarás toda la vida en la teoría cuántica de campos.
✅ Verificación de comprensión: Determina si la siguiente ecuación es covariante de Lorentz verificando el balance de índices: \(T^{\mu\nu} = \partial^\mu \phi\, \partial^\nu \phi - \eta^{\mu\nu}\left(\frac{1}{2}\partial_\alpha \phi\, \partial^\alpha \phi - \frac{1}{2}m^2 \phi^2\right)\)
Respuesta
Lado izquierdo: 2 índices libres arriba \(\mu, \nu\) → tensor contravariante de rango 2. Primer término del lado derecho: \(\partial^\mu \phi\) tiene índice arriba \(\mu\), \(\partial^\nu \phi\) tiene índice arriba \(\nu\) → su producto es un tensor de rango 2 con índices arriba \(\mu, \nu\). Segundo término del lado derecho: \(\eta^{\mu\nu}\) tiene índices arriba \(\mu, \nu\); dentro del paréntesis, \(\alpha\) se contrae arriba y abajo dando un escalar, y \(\phi^2\) también es escalar → en total es un tensor de rango 2 con índices arriba \(\mu, \nu\). Ambos lados son tensores contravariantes de rango 2 con índices arriba \(\mu, \nu\), por lo que es covariante de Lorentz ✓.
📝 Ejercicios:
- Condición de la matriz de transformación de Lorentz, transformación del tensor electromagnético → Problema M-1. Derivación de la condición sobre la matriz de transformación de Lorentz, Problema A-1. Reglas de transformación de tensores contravariantes y covariantes, y aplicación al tensor de campo electromagnético
2.6 Los 3 postulados de la teoría cuántica de campos¶
🟡 Lina: Al final de este capítulo, organicemos los 3 postulados que forman la base de la teoría cuántica de campos. El panorama completo está ilustrado en Fig. 2.5「Los 3 postulados de la teoría cuántica de campos y el teorema espín-estadística」.
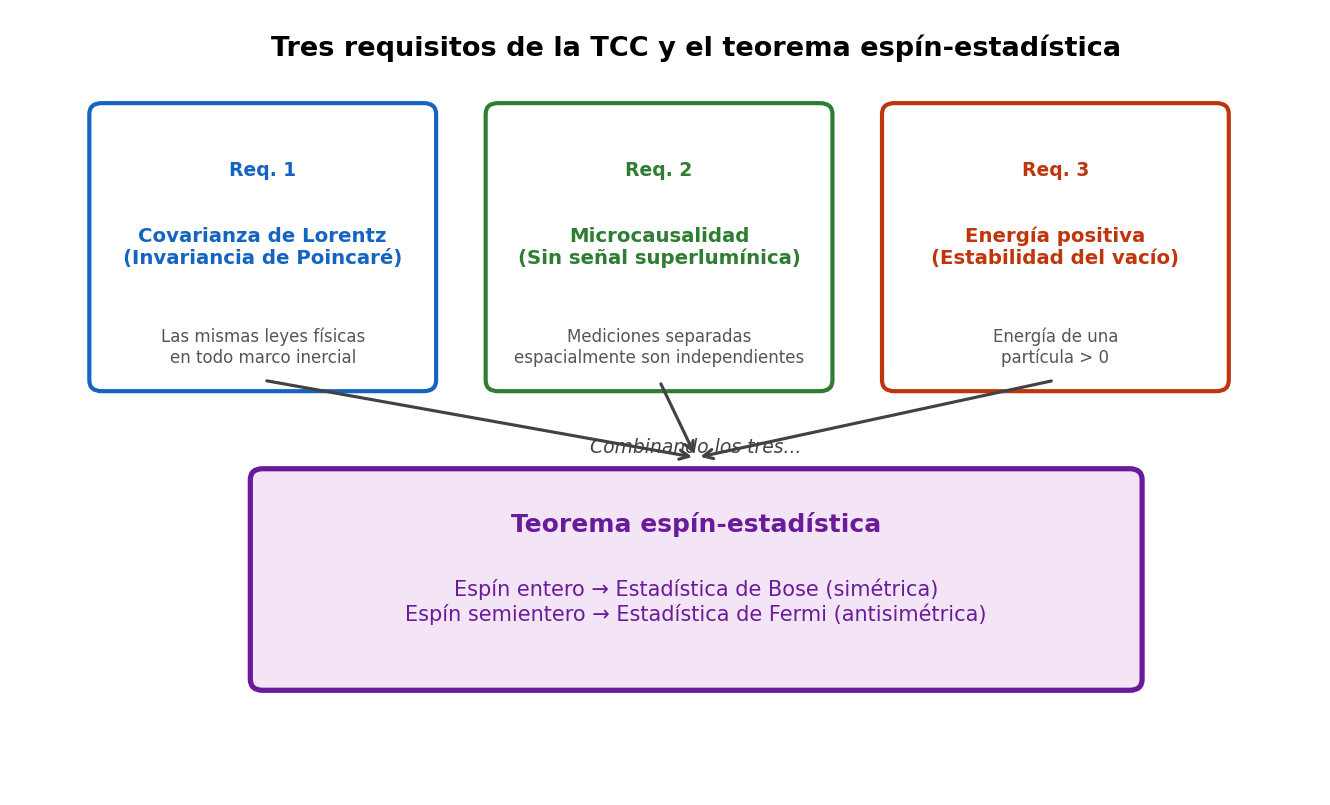
Fig. 2.5: Los 3 postulados de la teoría cuántica de campos y el teorema espín-estadística. Combinando los 3 postulados de covariancia de Lorentz, microcausalidad y energía positiva, se deriva el teorema espín-estadística (espín entero → estadística de Bose, espín semientero → estadística de Fermi).
- Covariancia de Lorentz (invariancia de Poincaré): Las ecuaciones de campo no cambian de forma bajo las transformaciones del grupo de Poincaré
- Causalidad (microcausalidad): La información no se propaga más rápido que la luz. Los resultados de medición en dos puntos fuera del cono de luz — es decir, tan separados que ni la luz puede ir de uno al otro (ver Relatividad General Relatividad General Cap. 3) — deben ser independientes entre sí. Intuitivamente significa que "experimentos realizados simultáneamente en dos lugares suficientemente alejados no se influyen mutuamente". La forma de formular esto precisamente en el lenguaje matemático de la teoría cuántica se introducirá en un capítulo posterior
- Energía positiva: La energía de los estados físicos de una partícula es positiva (el vacío es estable)
🔵 Kai: Lo de la causalidad, "los resultados de medición fuera del cono de luz son independientes entre sí", ¿puedes ser más concreto?
🟡 Lina: Por ejemplo, si ahora mismo haces un experimento en Tokio y otro experimento se realiza en la galaxia de Andrómeda — si los dos eventos están separados espacialmente (ni la luz puede ir de uno al otro), entonces es imposible que el resultado del experimento en Tokio influya en el de Andrómeda. Es decir, hagas lo que hagas en Tokio, la estadística (qué valores salen y con qué probabilidad) del experimento en Andrómeda no cambia en absoluto. Y viceversa. Este es el significado intuitivo de la causalidad.
⚪ Mei: En el caso del entrelazamiento cuántico (Mecánica Cuántica Mecánica Cuántica Cap. 23), solo se veían correlaciones pero no se podía enviar información — es el mismo espíritu.
🟡 Lina: Podrías pensar "pero, ¿no había correlaciones entre partículas alejadas en el entrelazamiento cuántico (Mecánica Cuántica Mecánica Cuántica Cap. 23)?", pero como confirmamos en ese momento, mirando solo los datos de un lado parecen completamente aleatorios — la correlación solo se ve al comparar los datos de ambos lados. Por eso no se puede cambiar la estadística del otro lado mediante una operación en un lado (no-signaling). La causalidad se preserva en este sentido. La formulación precisa en el lenguaje de la teoría cuántica — concretamente, la condición de que "los operadores de campo en dos puntos espacialmente separados conmutan" — se introducirá en un capítulo posterior.
🔵 Kai: Entiendo. Entonces, ¿con estos 3 postulados se determina bastante la forma de la teoría?
🟡 Lina: Se determina sorprendentemente. Solo de la covariancia de Lorentz (más precisamente, la invariancia de Poincaré) sale la clasificación de Wigner de 2.4「Grupo de Poincaré — Transformaciones de Lorentz + traslaciones espacio-temporales」 — "los campos se clasifican por (masa, espín)". Además, combinando la causalidad y la energía positiva, se puede demostrar el teorema espín-estadística (spin-statistics theorem):
Campos de espín entero → estadística de Bose, campos de espín semientero → estadística de Fermi
🔵 Kai: ¡¿Con solo 3 postulados sale la distinción entre bosones y fermiones?!
✅ Verificación de comprensión: ¿De cuáles 3 postulados de la teoría cuántica de campos se deriva el teorema espín-estadística? Además, explica brevemente el contenido de este teorema.
Respuesta
Se deriva de los 3 postulados: (1) Covariancia de Lorentz (invariancia de Poincaré), (2) Causalidad (microcausalidad), (3) Energía positiva (estabilidad del vacío). El contenido del teorema es "los campos de espín entero obedecen la estadística de Bose y los campos de espín semientero obedecen la estadística de Fermi"; la distinción entre bosones y fermiones que en mecánica cuántica se asumía sin demostración, en la teoría cuántica de campos se puede demostrar a partir de estos 3 principios.
⚪ Mei: Es decir, en mecánica cuántica se asumía de manera impuesta que "el electrón es un fermión y el fotón es un bosón", pero en la teoría cuántica de campos se puede derivar de los 3 postulados anteriores.
🟡 Lina: Así es. Este es uno de los ejemplos más dramáticos de que "la simetría determina la física". A partir del próximo capítulo, usaremos esta covariancia de Lorentz como arma para aprender la teoría clásica de campos — el lagrangiano y el teorema de Noether.
🔵 Kai: El teorema espín-estadística sale de solo 3 postulados... Pero sinceramente, todavía no puedo imaginar el contenido de la demostración.
🟡 Lina: La demostración requiere la herramienta de las relaciones de conmutación de campos, así que la haremos en un capítulo posterior cuando la hayamos aprendido. Espéralo con ilusión.
🔵 Kai: Lo espero con ganas. ...Ah, ¿puedo volver al tema de 2.5「Covariancia de Lorentz y "balance de índices"」? Antes dijiste que el balance de índices es "condición necesaria pero no suficiente". ¿No se parece al análisis dimensional? En el sentido de que aunque las dimensiones cuadren, la fórmula puede no ser correcta.
🟡 Lina: Buena intuición. Exactamente así — de la misma manera que el análisis dimensional descarta errores obvios con el "balance de unidades", la verificación de índices descarta errores con el "balance de transformación de Lorentz". Ambos son filtros de condición necesaria, no suficiente. Esa analogía es precisa.
🔵 Kai: Entonces, incluso si una ecuación pasa ambos filtros, puede estar equivocada — ¿cuál es la base definitiva para juzgar que es "correcta"?
🟡 Lina: Hay dos. Una es la concordancia con el experimento — al final es la naturaleza la que tiene la respuesta. La otra es la fundamentación lógica de que fue derivada del principio de acción — poder explicar "por qué esta ecuación" remontándose a un principio. Los filtros son solo herramientas para "descartar errores obvios"; la garantía de corrección viene de otro lugar — ese es el papel del lagrangiano que aprenderemos en el próximo capítulo. Es decir, con la verificación de índices se descartan los "claramente incorrectos", y entre los que quedan, con el principio de acción se seleccionan los "correctos" — es un mecanismo en dos etapas.
⚪ Mei: Con el filtro se eliminan "los que no sirven" y con el principio se seleccionan "los correctos" — un mecanismo en dos etapas.
🔵 Kai: Entiendo. Entonces en el próximo capítulo sobre el lagrangiano, ¿se parte de una cantidad escalar con balance de índices correcto y de ahí se derivan las ecuaciones?
🟡 Lina: Exactamente así. El lagrangiano debe ser un escalar — el balance de índices que aprendimos hoy se convierte en la directriz de diseño al construir el lagrangiano en el próximo capítulo. Con las herramientas adquiridas en este capítulo — la convención de signos QFT, la estructura del grupo de Lorentz y el grupo de Poincaré, la verificación de covariancia mediante balance de índices — en el próximo capítulo por fin pasaremos al lado de "derivar" las ecuaciones de campo.
🔵 Kai: Derivar ecuaciones a partir de la simetría — hasta ahora las ecuaciones venían primero y luego confirmábamos la simetría, pero ahora se invierte. Estoy deseando verlo.
Adelanto del próximo capítulo¶
Cap. 3 Teoría clásica de campos — Lagrangiano y teorema de Noether
En el próximo capítulo aprenderemos el método sistemático para derivar ecuaciones de campo covariantes de Lorentz. La clave será el lagrangiano (principio de acción) y el teorema de Noether — un teorema profundo que dice "si hay una simetría continua, hay una cantidad conservada". Veremos cómo las ecuaciones del campo de Klein-Gordon y del campo electromagnético se derivan de un único lagrangiano.
Referencias¶
- Quantum Field Theory and the Standard Model (Schwartz) capítulo 2 "Lorentz invariance and second quantization"
- Quantum Field Theory for the Gifted Amateur (Lancaster & Blundell) capítulo 10 "Transformations"
- 坂本眞人『場の量子論 — 不変性と自由場を中心にして』 capítulo 1 "Invitación a la teoría cuántica de campos", capítulo 14 "Álgebra de Poincaré y clasificación de estados de una partícula"
- Quantum Field Theory (David Tong, notas de clase) capítulo 1 "Classical Field Theory" (introducción)
- Wigner, E. P. "On Unitary Representations of the Inhomogeneous Lorentz Group," Ann. Math. 40, 149 (1939) (artículo original de la clasificación de Wigner)
- Lee, T. D. and Yang, C. N. "Question of Parity Conservation in Weak Interactions," Phys. Rev. 104, 254 (1956)
- Christenson, J. H., Cronin, J. W., Fitch, V. L. and Turlay, R. "Evidence for the \(2\pi\) Decay of the \(K_2^0\) Meson," Phys. Rev. Lett. 13, 138 (1964)
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.