Apéndice D Caja de herramientas para cálculos de loops — Análisis dimensional, parámetros de Feynman y rotación de Wick¶
Resumen de los capítulos anteriores:
En Apéndice C organizamos la integral gaussiana (una variable y varias variables) y el álgebra de números de Grassmann e integral de Berezin, dejando clara la comparación entre las integrales de camino de bosones (\((\det A)^{-1/2}\)) y fermiones (\(\det A\)).
Objetivo de este capítulo
- Preparar la "caja de herramientas de cálculo" necesaria para los cálculos concretos de loops en teoría cuántica de campos
- Resumir como referencia consultable en cualquier momento: el sistema de unidades naturales y la dimensión de masa, las convenciones de signos, la transformada de Fourier y los factores de \(2\pi\), la unificación de denominadores mediante parámetros de Feynman, la transición al espacio euclídeo mediante rotación de Wick, y las fórmulas de evaluación de integrales de momento
- Servir como lugar de referencia cuando en los capítulos 13–14 sobre renormalización se indique "consultar Apéndice D"
Sistema de unidades naturales y dimensión de masa¶
🟡 Lina: Vamos a organizar de una vez por todas el sistema de unidades naturales que hemos usado muchas veces en los capítulos anteriores. Cuando haces cálculos de loops, si te equivocas en "¿cuál es la dimensión de esta cantidad?", la respuesta puede diferir en órdenes de magnitud.
🔵 Kai: Es lo de \(c = 1\), \(\hbar = 1\), ¿verdad? Es conveniente, pero a veces cuando quiero volver a las "unidades reales" me confundo.
🟡 Lina: Precisamente organizar eso es el objetivo de hoy. El punto de partida son dos igualdades:
🟡 Lina: Al poner \(c = 1\), "longitud" y "tiempo" tienen la misma dimensión. Al poner \(\hbar = 1\), "energía" e "inverso del tiempo" tienen la misma dimensión. Como resultado, todas las cantidades físicas se caracterizan únicamente por la dimensión de masa (mass dimension) — "¿a qué potencia de la masa equivale?". Por ejemplo, una distancia \(x\) se puede escribir como \(\hbar c / E\), así que si \(\hbar = c = 1\) entonces \(x \sim 1/E \sim 1/m\). Es decir, la dimensión de masa de la distancia es \(-1\).
⚪ Mei: Ya veo, la distancia tiene dimensión de "masa a la potencia \(-1\)". Esto es consistente con la intuición de que a mayor energía se pueden explorar distancias más cortas.
🟡 Lina: Exacto. Escribiré la dimensión de masa de una cantidad \(X\) como \([X]\). Las reglas básicas resumidas son:
Tabla D.1: Dimensión de masa de cantidades físicas básicas
| Cantidad | Dimensión de masa | Razón |
|---|---|---|
| Coordenada \(x^\mu\), tiempo \(t\) | \(-1\) | \(x \sim 1/m\) |
| Derivada \(\partial_\mu\), momento \(p_\mu\) | \(+1\) | \(\partial_\mu = \partial/\partial x^\mu\) es el inverso de la coordenada |
| Velocidad \(v = x/t\) | \(0\) | Adimensional porque \(c = 1\) |
| Medida de integración 4-dimensional \(d^4x\) | \(-4\) | \((-1) \times 4\) |
| Acción \(S = \int d^4x\,\mathcal{L}\) | \(0\) | El exponente de \(e^{iS/\hbar}\) es adimensional |
| Densidad lagrangiana \(\mathcal{L}\) | \(+4\) | De \([S] = [d^4x] + [\mathcal{L}] = 0\) |
🔵 Kai: Que la acción sea adimensional viene de \(e^{iS}\) en la integral de camino. Es lo que vimos en los capítulos 10–11.
🟡 Lina: Sí. Como \(\hbar = 1\), tenemos \(e^{iS/\hbar} = e^{iS}\), y el argumento del exponente debe ser adimensional.
Dimensión de masa de los campos¶
🟡 Lina: A partir de la condición \([\mathcal{L}] = 4\), se determina la dimensión de masa de los campos.
Para el campo escalar \(\phi\), el lagrangiano libre es
Fijándonos en el término cinético:
🔵 Kai: Solo con que la dimensión del lagrangiano sea 4, la dimensión del campo queda determinada unívocamente. Qué simple.
🟡 Lina: Así es. Con el mismo razonamiento se puede obtener la dimensión de masa del campo de Dirac \(\psi\). El lagrangiano de Dirac era \(\mathcal{L} = \bar{\psi}(i\gamma^\mu\partial_\mu - m)\psi\). Si nos fijamos en el término cinético \(\bar{\psi}\,i\gamma^\mu\partial_\mu\,\psi\), ¿qué obtienes?
⚪ Mei: \([\bar{\psi}] + [\partial_\mu] + [\psi] = 2[\psi] + 1 = 4\), así que \([\psi] = 3/2\).
🟡 Lina: Correcto. Resumiendo:
Tabla D.2: Dimensión de masa de cada campo
| Campo | Dimensión de masa |
|---|---|
| Campo escalar \(\phi\) | \(1\) |
| Campo de Dirac \(\psi\) | \(3/2\) |
| Campo de gauge \(A_\mu\) | \(1\) |
El campo de gauge se deduce de \(-\frac{1}{4}F_{\mu\nu}F^{\mu\nu}\). Como \(F_{\mu\nu} = \partial_\mu A_\nu - \partial_\nu A_\mu\), tenemos \([F_{\mu\nu}] = [\partial] + [A] = 1 + [A]\). De \([F^2] = 2(1 + [A]) = 4\) se obtiene \([A_\mu] = 1\).
🔵 Kai: ¿Con esto también se determina la dimensión de las constantes de acoplamiento?
🟡 Lina: Buena pregunta. Por ejemplo, la dimensión del término de interacción de QED \(e\bar{\psi}\gamma^\mu\psi A_\mu\) es:
Como \([\mathcal{L}] = 4\), tenemos \([e] = 0\). Es decir, la constante de acoplamiento \(e\) de QED es adimensional. Esto es uno de los indicadores de que la teoría es "renormalizable". Es lo que aprendimos en los capítulos 14–16.
Verificación de comprensión: ¿Cuál es la dimensión de masa de la constante de acoplamiento \(\lambda\) en la teoría \(\phi^4\)?
De \(\mathcal{L}_{\text{int}} = -\frac{\lambda}{4!}\phi^4\) se obtiene \([\lambda] + 4[\phi] = [\lambda] + 4 = 4\). Por lo tanto \([\lambda] = 0\) (adimensional).
📝 Ejercicios:
- Dimensión de masa de la constante de acoplamiento \(g\) en la teoría \(\phi^3\) → Problema B-1. Determinación de la dimensión de masa (interacción de Yukawa)
Restauración de \(\hbar\) y \(c\)¶
🟡 Lina: Cuando se compara con experimentos, es necesario volver a las unidades físicas. Los factores de conversión que hay que recordar:
En unidades naturales, \(\text{GeV}^{-2}\) tiene dimensión de área. Para convertir a unidades SI se usa \(\hbar c = 0.1973\ \text{GeV}\cdot\text{fm}\) (\(1\ \text{fm} = 10^{-15}\ \text{m}\)):
Por lo tanto, para convertir una sección eficaz escrita como "\(1/\text{GeV}^2\)" en unidades naturales a unidades de \(\text{fm}^2\), se usa el factor de conversión \(\hbar c = 0.1973\ \text{GeV}\cdot\text{fm}\). Concretamente:$$ 1\ \text{GeV}^{-2} \longrightarrow (\hbar c)^2 \times 1\ \text{GeV}^{-2} = 0.03893\ \text{GeV}^2!\cdot!\text{fm}^2 \times \text{GeV}^{-2} = 0.03893\ \text{fm}^2 = 0.3893\ \text{mb} = 3.893 \times 10^{-28}\ \text{cm}^2 \tag{D.6b} $$
Aquí \(1\ \text{mb}\ (\text{millibarn}) = 10^{-27}\ \text{cm}^2 = 10^{-31}\ \text{m}^2\), \(1\ \text{pb}\ (\text{picobarn}) = 10^{-40}\ \text{m}^2\). Es decir, \(1\ \text{GeV}^{-2} = 3.893 \times 10^{8}\ \text{pb}\). Para comparar una sección eficaz escrita como "\(1/\text{GeV}^2\)" en unidades naturales con valores experimentales, se multiplica por \((\hbar c)^2\) para convertir a \(\text{m}^2\) o barn.
🔵 Kai: "Barn" es un nombre raro.
🟡 Lina: Viene de que en experimentos donde se lanzan partículas contra núcleos atómicos, el núcleo parecía un blanco "tan grande como un granero (barn)". \(1\ \text{barn} = 10^{-28}\ \text{m}^2\) es del orden de la sección eficaz nuclear.
Convenciones de signos¶
🟡 Lina: A continuación, resumo las convenciones de signos adoptadas en todo Teoría Cuántica de Campos. Como las convenciones varían según el libro de texto, asegúrate de verificarlas siempre que consultes otra referencia.
Tensor métrico¶
🟡 Lina: La métrica de Minkowski es:
Esto se llama convención "mostly minus". Con esta convención, la condición de capa de masas es:
⚪ Mei: Es la misma convención de relatividad especial que repasamos en Cap. 2. \(p^2\) es positivo e igual al cuadrado de la masa.
Convención de signos del lagrangiano¶
🟡 Lina: Resumo los lagrangianos libres de cada campo. Los signos se fijan de modo que la densidad de energía sea positiva.
Campo escalar real:
Campo escalar complejo:
🔵 Kai: ¿Por qué el escalar real tiene un \(\frac{1}{2}\) pero el escalar complejo no?
🟡 Lina: Al variar el término cinético \((\partial\phi)^2\) del campo escalar real respecto a \(\phi\), como \(\phi\) aparece en dos lugares, la regla del producto de derivadas produce un factor 2. El \(\frac{1}{2}\) está ahí para cancelarlo y dar la ecuación de movimiento correcta. En cambio, para el escalar complejo se tratan \(\phi\) y \(\phi^*\) como variables independientes (como aprendimos en Cap. 3). Al variar \((\partial\phi^*)(\partial\phi)\) respecto a \(\phi^*\), \(\phi\) aparece solo en un lugar, así que no sale factor 2 — por eso no se necesita el \(\frac{1}{2}\).
Campo de gauge:
Fermión de Dirac: 🟡 Lina: Aquí confirmemos la notación slash (notación de Feynman) (que introdujimos en Cap. 5). Para cualquier 4-vector \(a\) se define \(\not\!a \equiv \gamma^\mu a_\mu\). Por ejemplo, \(\not\!\partial \equiv \gamma^\mu\partial_\mu\), \(\not\!p \equiv \gamma^\mu p_\mu\). Usando esta notación, el lagrangiano de Dirac se escribe: $$ \mathcal{L} = \bar{\psi}(i!\not!\partial - m)\psi \tag{D.12} $$
de forma concisa.
Derivada covariante¶
🟡 Lina: La derivada covariante (covariant derivative) de una teoría de gauge no abeliana — es decir, una teoría donde al aplicar dos transformaciones de gauge sucesivas, el resultado cambia si se invierte el orden — es:
Aquí \(g\) es la constante de acoplamiento, \(T^a_R\) son los generadores del grupo de gauge (el subíndice \(R\) es la inicial de "representación (representation)", una etiqueta que distingue el tipo de campo), y \(A^a_\mu\) son las componentes del campo de gauge (el índice \(a\) distingue los generadores del grupo; por ejemplo, para \(SU(3)\) hay \(a = 1, 2, \ldots, 8\), es decir 8). Para más detalles consulta Cap. 17.
🔵 Kai: Sinceramente, "representación", "generadores"... solo leyendo esto no me queda claro...
🟡 Lina: No te preocupes, como esto es una confirmación de convenciones, por ahora basta con que te quedes con que "el signo de la derivada covariante es \(-ig\)". \(T^a_R\) es "la matriz que determina cómo actúa la transformación de gauge sobre el campo", y el tamaño de la matriz cambia según el tipo de campo — por ejemplo, para el campo del quark es una matriz \(3 \times 3\), para el campo del gluón es \(8 \times 8\). Pero por ahora no te preocupes por estos detalles. El significado físico lo aprenderás cuidadosamente en Cap. 17; por ahora solo recuerda la forma de la ecuación.
⚪ Mei: Es decir, en esta etapa solo necesitamos llevarnos la información de catálogo de que "se adopta el signo \(-ig\)".
🟡 Lina: Exacto. QED es una teoría de gauge \(U(1)\), con un solo generador (no se necesita el índice \(a\)), y esa "matriz" es simplemente el número de la carga de la partícula \(Q\). Así que sustituyendo \(g \to e\), \(T^a_R \to Q\) en la ecuación (D.13):
La carga del electrón es \(-e\) (\(e > 0\)), así que medida en unidades de la carga elemental \(e\), tenemos \(Q = -1\). Sustituyendo en la ecuación (D.14): \(D_\mu = \partial_\mu - ie(-1)A_\mu = \partial_\mu + ieA_\mu\):
Propagador de Feynman¶
🟡 Lina: Las convenciones del propagador de Feynman (Feynman propagator) que usamos en Teoría Cuántica de Campos:
Campo escalar:
Aquí \(T\{\cdots\}\) es el producto ordenado en el tiempo (time-ordered product), la operación de colocar a la izquierda el campo con tiempo posterior (introducido en Cap. 10).
Aquí \(\varepsilon > 0\) es una cantidad positiva infinitesimal, llamada prescripción \(i\varepsilon\). Su papel es desplazar ligeramente los polos del eje real en el camino de integración de \(p_0\), seleccionando la propagación causal (que sigue el orden temporal). Volverá a ser importante en la sección de rotación de Wick, así que recuérdalo.
🔵 Kai: Pensaba que \(i\varepsilon\) era una especie de "conjuro" para preservar la causalidad, pero resulta que también es importante en la rotación de Wick.
🟡 Lina: Así es. Que podamos rotar el camino al eje imaginario en la rotación de Wick es precisamente gracias a que \(i\varepsilon\) desplaza la posición de los polos.
Campo de gauge (gauge covariante — nombre genérico para fijaciones de gauge que preservan la covariancia de Lorentz, caracterizadas por el parámetro \(\xi\)):
\(\xi = 1\) es el gauge de Feynman, \(\xi = 0\) es el gauge de Landau.
Fermión de Dirac:
🔵 Kai: Oye, la exponencial del propagador, ¿\(e^{-ip(x-y)}\) o \(e^{+ip(x-y)}\)? He visto que varía según el libro de texto. ¿Aquí se unifica todo con \(e^{-ip(x-y)}\)?
🟡 Lina: Buena observación. En resumen, la elección del signo de la exponencial y la forma del numerador del propagador se determinan como un conjunto, así que el resultado físico es el mismo con cualquiera de las dos convenciones. En la práctica, al usar las reglas de Feynman se emplea directamente el propagador en espacio de momentos \(i/(\not\!p - m)\), así que casi nunca hay situaciones donde te preocupe el signo de la exponencial.
El mecanismo, dicho brevemente, es que \(p\) es una variable de integración, así que si haces la sustitución \(p \to -p\), la exponencial \(e^{-ip(x-y)}\) se convierte en \(e^{+ip(x-y)}\). La medida de integración es \(d^4p \to d^4p\) (el jacobiano es \((-1)^4 = 1\)) e invariante. El denominador también se reescribe como función de \(p\), pero al reorganizar el todo, el propagador en espacio de coordenadas da el mismo resultado. Es decir, es una diferencia que se absorbe simplemente renombrando la variable de integración. Así que si ves \(e^{+ip(x-y)}\) en otro libro de texto, puedes estar tranquilo porque el resultado físico no cambia.
🔵 Kai: Ya veo, se absorbe con un cambio de nombre de la variable de integración.
🟡 Lina: Eso es. En Teoría Cuántica de Campos adoptamos \(e^{-ip(x-y)}\), lo cual corresponde a la elección natural donde el operador de aniquilación va acompañado de \(e^{-ipx}\) en la expansión de Fourier de \(\psi(x)\).
⚪ Mei: ¿Que el numerador del escalar sea \(+i\) y el del campo de gauge sea \(-i\) tiene alguna razón?
🟡 Lina: Buen punto. El propagador es la función de Green de la ecuación de movimiento, así que el signo del término cinético del lagrangiano se refleja directamente. El campo escalar tiene \(+\frac{1}{2}(\partial\phi)^2\) con signo positivo, y el campo de gauge tiene \(-\frac{1}{4}F^2\) con signo negativo — esa diferencia se convierte en la diferencia entre \(+i\) y \(-i\) en el numerador.
Verificación de comprensión: ¿Cuál es el numerador del propagador del campo de gauge en el gauge de Feynman (\(\xi = 1\))?
Al sustituir \(\xi = 1\) se tiene \((1-\xi) = 0\), así que el numerador es simplemente \(-i\eta_{\mu\nu}\). Es el gauge que simplifica más los cálculos.
✅ Verificación de comprensión: ¿Cuál es el papel físico de la prescripción \(i\varepsilon\) que aparece en el propagador de Feynman del campo escalar?
Respuesta
\(i\varepsilon\) (cantidad infinitesimal con \(\varepsilon > 0\)) tiene el papel de desplazar ligeramente los polos del propagador del eje real en el plano complejo de \(p_0\). Esto selecciona la propagación causal (que sigue el orden temporal) y además garantiza que al rotar el camino de integración del eje real al eje imaginario en la rotación de Wick posterior, no se crucen los polos.
Los factores de \(2\pi\)¶
🟡 Lina: Uno de los errores más frecuentes en cálculos de loops es olvidar los \(2\pi\). Vamos a dejar claras las reglas.
🔵 Kai: ¿Por qué los \(2\pi\) son tan problemáticos?
🟡 Lina: Tienen su origen en la definición de la transformada de Fourier. La representación integral de la función delta:
Extendiendo a 4 dimensiones:
La convención de transformada de Fourier en Teoría Cuántica de Campos:
Esta convención es consistente con el \(e^{-ip(x-y)}\) del propagador (ecuación (D.16)).
⚪ Mei: Es decir, la integral en espacio de momentos lleva \(1/(2\pi)^4\) y la integral en espacio de coordenadas no. Basta con recordar esta asimetría.
🟡 Lina: Sí. Cuando en las reglas de Feynman se integra sobre el momento interno del loop, siempre se escribe
y esto viene de esta convención.
✅ Verificación de comprensión: En la convención de transformada de Fourier de este libro, ¿a cuál de las integrales — en espacio de momentos o en espacio de coordenadas — se le añade el factor \(2\pi\)?
Respuesta
A la integral en espacio de momentos se le añade \(1/(2\pi)^4\), y a la integral en espacio de coordenadas no. Es decir, \(f(x) = \int \frac{d^4p}{(2\pi)^4}\tilde{f}(p)e^{-ipx}\) y \(\tilde{f}(p) = \int d^4x\,f(x)e^{+ipx}\).
La correspondencia entre momento y derivada es:
Esto se verifica actuando con \(i\partial_\mu\) sobre la onda plana \(e^{-ipx}\): \(i(-ip_\mu)e^{-ipx} = p_\mu e^{-ipx}\). Como complemento sobre las componentes espaciales: \(p_0 = E \leftrightarrow i\partial_t\) es la componente temporal. Para las componentes espaciales \(p_i \leftrightarrow i\partial_i\), pero en la convención mostly minus \(p^i = -p_i\), así que en componentes contravariantes \(p^i \leftrightarrow -i\partial_i\). Como \(\vec{p} = (p^1, p^2, p^3)\) es el vector formado por las componentes contravariantes espaciales, \(\vec{p} \longleftrightarrow -i\vec{\nabla}\). La relación familiar de mecánica cuántica.
Parámetros de Feynman¶
🟡 Lina: Aquí comienza la técnica central del cálculo de loops. Como vimos en Cap. 13, en los diagramas de Feynman cada línea interna (el propagador de la partícula virtual que forma el loop) da un factor como \(i/(k^2 - m^2 + i\varepsilon)\), y se integra sobre el momento \(k\) que recorre el loop. Si hay varias líneas internas, los propagadores se multiplican entre sí y aparecen integrales que contienen "productos de varios denominadores diferentes".
🔵 Kai: O sea, ¿en el denominador se alinean varios propagadores multiplicados?
🟡 Lina: Sí. El \(i\) del numerador se puede factorizar como coeficiente global, y el \(i\varepsilon\) no afecta la estructura algebraica de la integral en la etapa de introducción de parámetros de Feynman o completación de cuadrados (aunque será importante en la rotación de Wick, eso lo explico después). Por ahora, fijándonos en la forma del denominador, por ejemplo en la autoenergía a 1 loop aparece
El denominador es un producto de 2 factores. (En adelante, se sobreentiende que \(i\varepsilon\) acompaña a cada factor y lo omitiré.)
🔵 Kai: ¿Y cómo se integra esto? Si los denominadores son diferentes no sé qué hacer.
🟡 Lina: Para eso se usa la técnica llamada parámetros de Feynman (Feynman parameter). Se introduce una variable auxiliar para unificar los denominadores en uno solo.
Fórmula básica¶
🟡 Lina: La fórmula más básica es esta. La idea es "formar el promedio ponderado \(xA + (1-x)B\) de \(A\) y \(B\), y al mover el parámetro \(x\) de 0 a 1, empaquetar la información de ambos \(A\) y \(B\) en una sola expresión". Cuando los dos factores \(A\) y \(B\) son números reales positivos (o números complejos con parte imaginaria positiva):
🔵 Kai: ¿Eh? ¿Por qué se cumple esto? Parece que sale de la nada.
🟡 Lina: Vamos a demostrarlo. Lo muestro para el caso \(A \neq B\) (si \(A = B\), ambos lados son \(1/A^2\) y se cumple trivialmente). Integro la función integranda del lado derecho respecto a \(x\). Definiendo \(D = xA + (1-x)B = x(A-B) + B\), tenemos \(dD = (A-B)\,dx\):
⚪ Mei: Integración por sustitución. Cuando \(x = 0\) entonces \(D = B\), cuando \(x = 1\) entonces \(D = A\), así que los límites de integración van de \(B\) a \(A\).
🟡 Lina: Sí. Continuando:
🔵 Kai: ¡Oh! ¡Sale limpiamente \(1/(AB)\)!
🟡 Lina: Esta es la demostración de la fórmula básica de parámetros de Feynman. \(x\) es una variable auxiliar que va de 0 a 1 y no aparece en la cantidad física final.
Generalización: \(n\) factores¶
🟡 Lina: También escribo la generalización para 3 o más factores:
La función delta \(\delta(1 - x_1 - \cdots - x_n)\) impone la restricción "la suma de los parámetros es 1".
✅ Verificación de comprensión: ¿Cuál es el papel de la función delta \(\delta(1 - x_1 - \cdots - x_n)\) que aparece en la fórmula general de parámetros de Feynman (D.25)?
Respuesta
Impone la restricción de que la suma de los parámetros de Feynman \(x_1, x_2, \ldots, x_n\) sea 1. Con esto, el contenido del denominador \(x_1 A_1 + \cdots + x_n A_n\) se expresa como combinación convexa (promedio ponderado) de cada \(A_i\). En el caso \(n=2\) se tiene \(x_2 = 1 - x_1\) y se reduce a la fórmula básica (D.24).
⚪ Mei: En el caso \(n = 2\), usando \(\delta(1 - x_1 - x_2)\) se pone \(x_2 = 1 - x_1\) y se recupera la ecuación (D.24). \((n-1)! = 1! = 1\) así que el coeficiente también coincide.
🟡 Lina: Además, el caso en que las potencias de los denominadores son diferentes también es importante. En esta fórmula aparece una función que extiende el "factorial" a valores no enteros. Quizás te preguntes "¿por qué no basta con el factorial de enteros?" — te doy la motivación antes. Hay dos razones. Primera, en la ecuación (D.34) que viene enseguida, al escribir la integral básica en forma cerrada, la función gamma aparece naturalmente — porque al evaluar la integral de la función beta, el resultado se escribe en términos de funciones gamma. Segunda, en la regularización dimensional que aprenderás en Cap. 14, se toma la dimensión del espacio como \(d = 4 - 2\epsilon\), "un poco menos que 4, no entero", para capturar las divergencias de las integrales de loop como polos en \(\epsilon \to 0\). Entonces el "4" de las fórmulas se reemplaza por "\(d\)", y aparecen cosas como \(\Gamma(d/2)\) con argumento no entero, haciendo indispensable una función que extienda el factorial a no enteros.
🔵 Kai: Ya veo, como se trabaja con dimensiones no enteras, no basta con el factorial de enteros.
🟡 Lina: Exacto. Entonces escribo la fórmula:
Aquí \(\Gamma\) es la función gamma (gamma function). Su representación integral es \(\Gamma(z) = \int_0^\infty t^{z-1}e^{-t}\,dt\) (\(z > 0\)), y para enteros positivos \(n\) se tiene \(\Gamma(n) = (n-1)!\), siendo así una generalización del factorial. "¿Qué significa \(t^{z-1}\) cuando \(z\) no es entero?" — para \(t > 0\) se puede definir el logaritmo natural \(\ln t\), así que se define \(t^{z-1} = e^{(z-1)\ln t}\), lo cual tiene sentido para cualquier real \(z\) (por ejemplo \(t^{1/2} = e^{(1/2)\ln t} = \sqrt{t}\)). Sin embargo, la integral \(\int_0^\infty t^{z-1}e^{-t}dt\) converge solo para \(z > 0\). La extensión a \(z \leq 0\) usa la relación de recurrencia que explico enseguida. Por ejemplo, \(\Gamma(1) = 1\), \(\Gamma(2) = 1\), \(\Gamma(3) = 2\). Está definida también para no enteros; \(\Gamma(1/2) = \sqrt{\pi}\) es famoso.
⚪ Mei: ¿\(\Gamma(1/2) = \sqrt{\pi}\) está relacionado con la integral gaussiana \(\int_{-\infty}^{\infty} e^{-x^2}dx = \sqrt{\pi}\)?
🟡 Lina: ¡Exactamente! \(\Gamma(1/2) = \int_0^\infty t^{-1/2}e^{-t}dt\) y sustituyendo \(t = x^2\) se obtiene \(\int_0^\infty \frac{2}{2x}\,x\,2x\,e^{-x^2}dx = 2\int_0^\infty e^{-x^2}dx = \sqrt{\pi}\). La propiedad importante es la relación de recurrencia \(\Gamma(z+1) = z\,\Gamma(z)\). Reescribiéndola:
Esta expresión define el lado izquierdo siempre que el lado derecho esté definido, así que permite extender el dominio de \(z > 0\) a \(z \leq 0\) (excepto \(z \neq 0, -1, -2, \ldots\)). Considera el límite \(z \to 0\). El numerador es \(\Gamma(0+1) = \Gamma(1) = 1\), finito, pero el denominador \(z\) se acerca a \(0\), así que \(\Gamma(z) \approx 1/z \to \infty\) diverge (exactamente, tiene un polo tipo \(1/z\) en \(z = 0\)). Esta divergencia se conectará después con la divergencia de las integrales de loop.
🔵 Kai: Pero una confirmación — entiendo que \(\Gamma(z) = \Gamma(z+1)/z\) diverge cuando \(z \to 0\) porque el denominador es cero. Pero ¿también diverge en \(z = -1\) o \(z = -2\)?
🟡 Lina: Buena pregunta. \(\Gamma(-1) = \Gamma(0)/(-1)\), pero el numerador \(\Gamma(0)\) ya es infinito, así que \(\Gamma(-1)\) también diverge. Igualmente \(\Gamma(-2) = \Gamma(-1)/(-2)\) también diverge. Es decir, tiene polos en todos los \(z = 0, -1, -2, \ldots\). Pero para otros reales negativos — como \(z = -1/2\) — tiene valores finitos. Para los cálculos de loops lo importante es solo el polo en \(z = 0\), así que por ahora basta con recordar eso.
También presento aquí la función beta (beta function) que usaremos después. Su definición es \(B(a,b) = \int_0^1 t^{a-1}(1-t)^{b-1}\,dt\), y su relación con la función gamma es:
Por ejemplo, \(B(1,1) = \int_0^1 1\,dt = 1\), \(B(2,2) = \int_0^1 t(1-t)\,dt = \int_0^1 (t - t^2)\,dt = \frac{1}{2} - \frac{1}{3} = \frac{1}{6}\). Recuérdalo porque lo usaremos en la derivación de la integral básica.
Uso práctico¶
🟡 Lina: Te muestro un ejemplo concreto. La integral de antes:
(En adelante, se sobreentiende que \(i\varepsilon\) acompaña a cada factor y lo omitiré.)
Tomando \(A = k^2 - m_1^2\), \(B = (k-p)^2 - m_2^2\) e introduciendo el parámetro de Feynman:
🔵 Kai: ¿Hay que desarrollar el denominador?
🟡 Lina: Sí. Ordeno el contenido del denominador:
🟡 Lina: Aquí se hace la completación de cuadrados. Con el cambio de variable \(\ell = k - (1-x)p\), es decir \(k = \ell + (1-x)p\), sustituye en cada término.
⚪ Mei: Lo intento. Sustituyendo \(k = \ell + (1-x)p\):
Sumando:
🟡 Lina: Perfecto. Así que el denominador es:
Definiendo \(\Delta \equiv xm_1^2 + (1-x)m_2^2 - x(1-x)p^2\), entonces \(-\Delta = x(1-x)p^2 - xm_1^2 - (1-x)m_2^2\), así que la expresión anterior es \(\ell^2 + x(1-x)p^2 - xm_1^2 - (1-x)m_2^2 = \ell^2 - \Delta\):
🔵 Kai: ¡Oh! ¡El denominador se convirtió en una función solo de \(\ell\)! ¿Y los términos con potencias impares de \(\ell\) también desaparecieron?
🟡 Lina: Muy perspicaz. El rango de integración de \(\ell\) es todo el espacio de \(-\infty\) a \(+\infty\), y el denominador depende solo de \(\ell^2\) (función par). Así que si en el numerador hay una potencia impar como \(\ell^\mu\), al hacer \(\ell \to -\ell\) el signo de la función integranda se invierte y la integral total es cero. Es la misma lógica que \(\int_{-\infty}^{\infty} x\,f(x^2)\,dx = 0\) en una dimensión. Este es el poder de los parámetros de Feynman y el cambio de variable — cualquier integral de loop se puede reducir a una forma estándar esféricamente simétrica.
✅ Verificación de comprensión: Después de introducir los parámetros de Feynman y hacer el cambio de variable (completación de cuadrados), ¿por qué desaparecen los términos con potencias impares de \(\ell^\mu\)?
Respuesta
El rango de integración del nuevo momento de loop \(\ell\) después del cambio de variable es todo el espacio \((-\infty, +\infty)\), y el denominador depende solo de \(\ell^2\) (función par). Si en el numerador hay una potencia impar de \(\ell^\mu\), al sustituir \(\ell \to -\ell\) el signo de la función integranda se invierte, y por simetría la integral es cero.
Verificación de comprensión: Describe en una frase el objetivo de los parámetros de Feynman
Unificar el producto de múltiples propagadores (producto de denominadores) en un solo denominador, y mediante un cambio de variable del momento (completación de cuadrados) reducir a una integral de forma estándar esféricamente simétrica.
📝 Ejercicios:
- Aplicación de parámetros de Feynman con masas iguales y derivación de \(\Delta\) → Problema B-3. Cálculo directo de parámetros de Feynman
Rotación de Wick¶
🟡 Lina: Bien, hemos logrado reducir a la forma de la ecuación (D.28), pero todavía hay un problema.
🔵 Kai: ¿Qué problema?
🟡 Lina: \(\ell^2 = \ell_0^2 - \vec{\ell}^{\,2}\) es la métrica de Minkowski, así que existe la posibilidad de que haya singularidades (polos) sobre el camino de integración de \(\ell_0\). Realizar la integral directamente en espacio de Minkowski es matemáticamente complicado.
🔵 Kai: Entonces, ¿hay algún método para evitar las singularidades?
🟡 Lina: Buena pregunta. Para eso se usa la idea llamada rotación de Wick (Wick rotation). Si nos movemos al espacio euclídeo, \(\ell_E^2 = \ell_0^2 + \vec{\ell}^{\,2}\) es siempre positivo, así que el problema de las singularidades desaparece.
⚪ Mei: Ya veo, como todos los signos de la métrica son positivos, el denominador no se anula.
Procedimiento de la rotación de Wick¶
🟡 Lina: Veámoslo concretamente. Consideremos la integral de \(\ell_0\) en el plano complejo. Primero confirmemos la posición de los polos:
🔵 Kai: Los polos están ligeramente desplazados del eje real.
🟡 Lina: Sí. Veámoslo con más detalle. Cuando \(\varepsilon > 0\) es pequeño, queremos encontrar el valor de \(\sqrt{a - i\varepsilon}\). Quizás te preguntes "¿qué es la raíz cuadrada de un número complejo?" — aquí es "el número que al elevarse al cuadrado da \(a - i\varepsilon\)". Hay dos tales números (con signos opuestos), y adoptamos la convención de elegir el de parte real positiva (valor principal). Para \(a > 0\) y \(\varepsilon\) suficientemente pequeño, se puede escribir \(\sqrt{a - i\varepsilon} = \sqrt{a(1 - i\varepsilon/a)}\). Aquí, usando la expansión de Taylor \(\sqrt{1+x} \approx 1 + x/2\) (para \(|x| \ll 1\)) con \(x = -i\varepsilon/a\) — esta fórmula vale también para \(x\) complejo si \(|x| \ll 1\) — se aproxima como \(\sqrt{a}\,(1 - i\varepsilon/(2a)) = \sqrt{a} - i\varepsilon/(2\sqrt{a})\). Con \(a = \vec{\ell}^{\,2} + \Delta\), tenemos \(\sqrt{\vec{\ell}^{\,2} + \Delta - i\varepsilon} \approx \sqrt{\vec{\ell}^{\,2} + \Delta} - i\frac{\varepsilon}{2\sqrt{\vec{\ell}^{\,2} + \Delta}}\), así que el polo positivo \(\ell_0 \approx +\sqrt{\vec{\ell}^{\,2}+\Delta}\) tiene parte imaginaria negativa — está ligeramente debajo del eje real (cuarto cuadrante), y el polo negativo \(\ell_0 \approx -\sqrt{\vec{\ell}^{\,2}+\Delta}\) tiene parte imaginaria positiva — está ligeramente encima del eje real (segundo cuadrante).
🔵 Kai: Es decir, visto en el plano complejo de \(\ell_0\), en el primer y tercer cuadrante no hay polos.
🟡 Lina: ¡Exacto! Mira la Fig. D.1「Plano complejo de \(\ell_0\) en la rotación de Wick」. El camino de integración original de Minkowski está sobre el eje real (línea azul en la figura), y el camino de integración euclídeo tras la rotación de Wick está sobre el eje imaginario (línea roja). El camino del semi-eje real positivo rota a través del primer cuadrante hacia el semi-eje imaginario positivo, y el del semi-eje real negativo rota a través del tercer cuadrante hacia el semi-eje imaginario negativo. Como no hay polos en la región barrida por la rotación (cuadrantes 1 y 3), el camino se puede deformar sin cruzar polos y el valor de la integral se conserva.
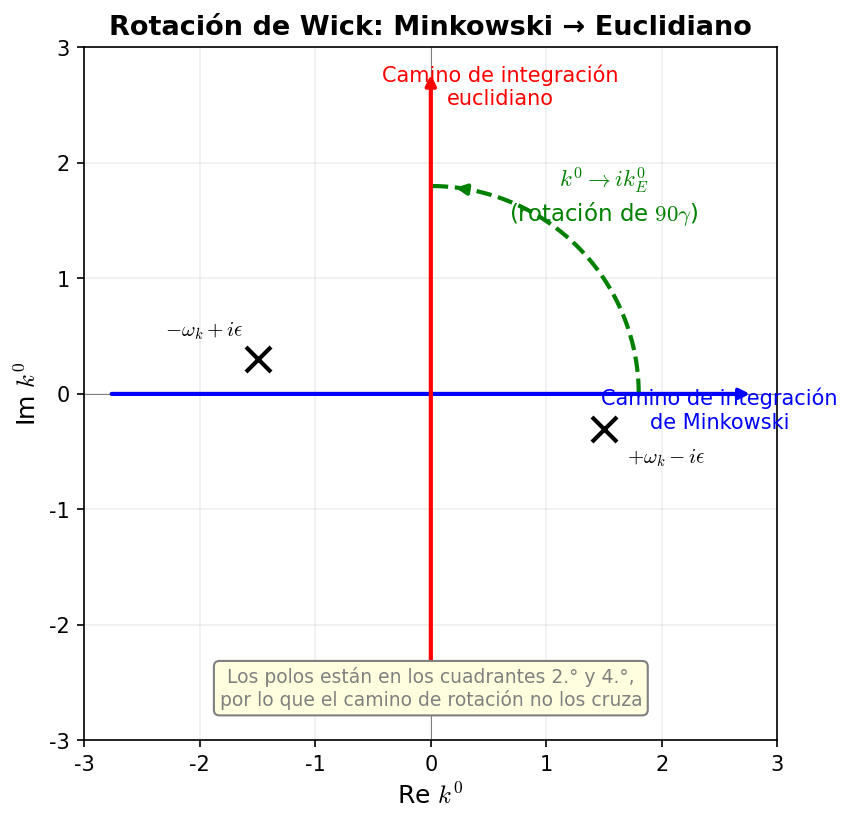
Fig. D.1: Plano complejo de \(\ell_0\) en la rotación de Wick. Se rota el camino de integración de Minkowski (azul, eje real) 90° en sentido antihorario hasta el camino de integración euclídeo (rojo, eje imaginario). Gracias a la prescripción \(i\varepsilon\), los polos (marcas ×) están en el segundo cuadrante (parte real negativa, parte imaginaria positiva) y el cuarto cuadrante (parte real positiva, parte imaginaria negativa), por lo que durante la rotación a través del primer y tercer cuadrante no se cruzan polos y el valor de la integral se conserva.
Lo que se usa aquí es el "principio de deformación de caminos" que se deriva del teorema de Cauchy del análisis complejo. Dicho sencillamente: "al deformar continuamente un camino de integración en el plano complejo, si no se cruzan singularidades (polos) entre tanto, el valor de la integral no cambia".
¿Por qué se cumple esto? Lo explico intuitivamente. Cuando una función \(f(z)\) en el plano complejo se comporta suavemente en cierta región sin tener explosiones como \(1/z\) (es decir, sin polos) — en regiones sin polos se puede deformar libremente el camino de integración sin cambiar el valor de la integral. Esto se llama teorema de Cauchy (la demostración rigurosa la dejamos para los libros de análisis complejo, pero aquí solo usamos el hecho de que "en regiones sin polos la deformación del camino es libre").
🔵 Kai: ¿Se puede comparar con algo, como el flujo de agua, para hacerse una imagen?
🟡 Lina: Buena analogía (es solo una metáfora, no una correspondencia estricta, pero es útil para captar la intuición). Imagina que en una piscina plana hay algunos agujeros de los que brota agua (= polos). Piensa en tender un hilo del punto A al punto B dentro de la piscina y medir el caudal de agua que cruza el hilo. Si cambias la trayectoria del hilo pero entre las trayectorias no hay agujeros, el caudal no cambiará, ¿verdad? Pero si hay un agujero entre las trayectorias, el caudal cambiará por la cantidad de agua que brota de ese agujero. En la integración compleja ocurre algo similar — mientras no se rodee un polo, no importa cómo deformes el camino, el valor de la integral no cambia.
⚪ Mei: Mientras muevas el hilo evitando los agujeros = polos, el caudal = valor de la integral es constante. Es una metáfora clara.
🟡 Lina: Siendo un poco más concreto, cuando se forma un camino cerrado conectando el camino original (eje real) con el nuevo camino (eje imaginario) en sus extremos, si no hay polos en su interior, la integral a lo largo del camino cerrado es cero (teorema de la integral de Cauchy). Aquí "conectar en los extremos" se refiere a unir los extremos del eje real (\(\pm R\)) con los del eje imaginario (\(\pm iR\)) mediante arcos de cuarto de círculo. Cuando \(R \to \infty\), si la función integranda decrece suficientemente rápido, la integral sobre los arcos es cero, así que integral cerrada = integral sobre eje real + integral sobre eje imaginario (en sentido opuesto) = 0. Es decir, la integral sobre el eje real y la integral sobre el eje imaginario son iguales. En nuestro caso, como el denominador crece con alta potencia de \(\ell_0\), la función integranda se acerca rápidamente a cero como \(1/|\ell_0|^{2n}\) cuando \(|\ell_0| \to \infty\) — así que la contribución de los arcos efectivamente se anula. La demostración rigurosa la dejamos para los libros de análisis complejo, pero aquí usamos el hecho de que "se puede rotar el camino evitando los polos".
Concretamente:
se hace esta sustitución. Aquí \(\ell_0^E\) es real. Entonces:
Donde \(\ell_E^2 = (\ell_0^E)^2 + \vec{\ell}^{\,2}\) es el cuadrado de la norma en espacio euclídeo 4-dimensional.
⚪ Mei: ¿Y la medida de integración?
🟡 Lina: \(d\ell_0 = i\,d\ell_0^E\), así que:
Aplicación a la forma estándar¶
🟡 Lina: Apliquemos la rotación de Wick a la ecuación (D.28):
El denominador es \((-\ell_E^2 - \Delta)^2 = [-(\ell_E^2 + \Delta)]^2 = (-1)^2(\ell_E^2 + \Delta)^2 = (\ell_E^2 + \Delta)^2\), así que:
🔵 Kai: ¡\((-1)^2 = 1\) y el signo del denominador desapareció! Y como \(\ell_E^2 + \Delta\) es siempre positivo, se puede integrar con tranquilidad.
🟡 Lina: Exacto. En espacio euclídeo la integral es esféricamente simétrica, así que se pueden usar coordenadas esféricas 4-dimensionales.
Integración en coordenadas esféricas 4-dimensionales¶
🟡 Lina: La integración de una función integranda esféricamente simétrica \(f(\ell_E^2)\) en espacio euclídeo 4-dimensional se entiende por analogía con 3 dimensiones. En 3 dimensiones se puede escribir \(\int d^3x\,f(r^2) = 4\pi\int_0^\infty r^2\,dr\,f(r^2)\), ¿verdad? Se multiplica por el área superficial \(4\pi r^2\) y se integra en la dirección radial. En 4 dimensiones es igual, se integra con "área superficial de la esfera 4-dimensional" \(\times\) \(\ell_E^3\,d\ell_E\):
Aquí \(2\pi^2\) es el área superficial de la esfera unitaria 4-dimensional (lo derivo enseguida). \(\ell_E^3\) es la parte radial del elemento de volumen; en \(d\) dimensiones en general es \(\ell_E^{d-1}\). La razón es que, así como en 3 dimensiones se puede escribir \(d^3x = r^2\sin\theta\,dr\,d\theta\,d\phi\), en \(d\) dimensiones el elemento de volumen también se descompone en "dirección radial \(d\ell_E\)" \(\times\) "elemento de área angular". Al integrar toda la parte angular, sale el área superficial de la esfera \((d-1)\)-dimensional de radio \(\ell_E\): \(S_d \cdot \ell_E^{d-1}\). Así que el elemento de volumen es \(S_d \cdot \ell_E^{d-1}\,d\ell_E\). En 4 dimensiones es la parte \(\ell_E^3\,d\ell_E\).
🔵 Kai: En 3 dimensiones es \(r^2\,dr\), en 4 dimensiones es \(\ell_E^3\,d\ell_E\) — o sea que cada vez que la dimensión sube en 1, la potencia sube en 1.
🟡 Lina: Exacto. En general, en \(d\) dimensiones:
⚪ Mei: Quiero verificar con el caso 3-dimensional. Sustituyendo \(d = 3\), \(S_3 = 2\pi^{3/2}/\Gamma(3/2)\), pero ¿cuánto es \(\Gamma(3/2)\)?
🟡 Lina: Basta usar la relación de recurrencia de antes. \(\Gamma(3/2) = \frac{1}{2}\Gamma(1/2) = \sqrt{\pi}/2\). Así que \(S_3 = 2\pi^{3/2}/(\sqrt{\pi}/2) = 4\pi\). El área superficial de la esfera que todos conocemos.
⚪ Mei: Ya veo, efectivamente sale \(4\pi\). Queda confirmado que la fórmula es consistente.
🔵 Kai: Que el área superficial en 4 dimensiones sea \(2\pi^2\) es curioso. En 3 dimensiones \(4\pi\) y en 4 dimensiones \(2\pi^2\)...
🟡 Lina: Aquí \(S_d\) representa "el área superficial de la esfera unitaria en espacio \(d\)-dimensional" — es decir, el área de la esfera \((d-1)\)-dimensional. \(S_d = 2\pi^{d/2}/\Gamma(d/2)\) se puede derivar de la versión \(d\)-dimensional de la integral gaussiana. Sustituyendo \(d = 4\) se obtiene \(S_4 = 2\pi^2/\Gamma(2) = 2\pi^2\), coincidiendo con el coeficiente de la ecuación (D.32). Es decir, la ecuación (D.32) es el caso especial \(d = 4\) de la ecuación (D.33).
La idea es que al reescribir la integral gaussiana \(d\)-dimensional \(\int d^d x\,e^{-|\vec{x}|^2} = \pi^{d/2}\) en coordenadas esféricas, se obtiene \(S_d \int_0^\infty r^{d-1}e^{-r^2}dr\).
🔵 Kai: Un momento. ¿Por qué \(\int d^d x\,e^{-|\vec{x}|^2} = \pi^{d/2}\)?
🟡 Lina: Buena pregunta. Como \(|\vec{x}|^2 = x_1^2 + x_2^2 + \cdots + x_d^2\), tenemos \(e^{-|\vec{x}|^2} = e^{-x_1^2}\cdot e^{-x_2^2}\cdots e^{-x_d^2}\), que se descompone en producto de exponenciales para cada eje. La integral también se descompone \(\int d^d x = \int dx_1 \int dx_2 \cdots \int dx_d\), así que el todo es el producto de \(d\) integrales gaussianas unidimensionales independientes \(\int_{-\infty}^{\infty} e^{-x_i^2}dx_i = \sqrt{\pi}\) (este valor \(\sqrt{\pi}\) corresponde al caso \(a = 2\) en la ecuación (C.1) de Apéndice C). Así que \(\sqrt{\pi}^{\,d} = \pi^{d/2}\). Tomando \(a = 2\) en la ecuación (C.1) de Apéndice C se obtiene \(\int e^{-q^2}dq = \sqrt{\pi}\), y es la forma de multiplicar eso \(d\) veces.
⚪ Mei: Como cada eje es independiente, la integral gaussiana \(d\)-dimensional es la potencia \(d\)-ésima de la unidimensional. Qué elegante.
🔵 Kai: Ah, como el contenido de la exponencial es la suma de cuadrados de cada variable, se puede descomponer en producto. La integral radial \(\int_0^\infty r^{d-1}e^{-r^2}dr\) no parece tener forma de función gamma así directamente...
🟡 Lina: Buen punto. Se hace la sustitución \(t = r^2\). Entonces \(r = \sqrt{t}\), \(dr = dt/(2\sqrt{t})\), \(r^{d-1} = t^{(d-1)/2}\). Multiplicando: \(r^{d-1}dr = t^{(d-1)/2} \cdot dt/(2\sqrt{t}) = \frac{1}{2}t^{d/2-1}dt\). Así que \(\int_0^\infty r^{d-1}e^{-r^2}dr = \frac{1}{2}\int_0^\infty t^{d/2-1}e^{-t}dt = \Gamma(d/2)/2\), que es exactamente la definición de la función gamma.
Con esto podemos igualar ambos resultados:
Despejando \(S_d\): \(S_d = 2\pi^{d/2}/\Gamma(d/2)\). Para \(d = 4\): \(S_4 = 2\pi^2/\Gamma(2) = 2\pi^2\). Con esto la derivación está completa.
⚪ Mei: Es decir, con una sola fórmula \(S_d = 2\pi^{d/2}/\Gamma(d/2)\) se obtienen de forma unificada tanto \(4\pi\) para \(d = 3\) como \(2\pi^2\) para \(d = 4\). Y cuando en la regularización dimensional se toma \(d\) no entero, esta fórmula se puede usar directamente.
Fórmulas básicas de integrales de momento¶
🟡 Lina: Usando la rotación de Wick y coordenadas esféricas, se pueden evaluar las integrales estándar que aparecen en cálculos de loops. Resumo los resultados.
Integral básica en espacio euclídeo¶
🟡 Lina: Con \(\Delta > 0\), la integral básica en espacio euclídeo 4-dimensional:
🔵 Kai: ¿Cómo se deriva esto?
🟡 Lina: Usando la ecuación (D.32):
Sustituyendo \(u = \ell_E^2\): \(du = 2\ell_E\,d\ell_E\), \(\ell_E^3\,d\ell_E = \frac{1}{2}u\,du\):
(Aquí ordeno el coeficiente. \(\frac{2\pi^2}{(2\pi)^4} = \frac{2\pi^2}{16\pi^4} = \frac{2}{16\pi^2} = \frac{1}{8\pi^2}\). Multiplicando por el \(\frac{1}{2}\) de la sustitución en \(u\): \(\frac{1}{8\pi^2} \times \frac{1}{2} = \frac{1}{16\pi^2} = \frac{1}{(4\pi)^2}\).)
🔵 Kai: Ya veo, el coeficiente \(1/(4\pi)^2\) viene de aquí. Es un factor que se ve mucho en cálculos de loops.
🟡 Lina: Sí, a veces se le llama "factor de loop \(1/(4\pi)^2\)". Ahora quiero llevar esta integral a la forma de la función beta que presenté antes, así que busco una sustitución que mapee el intervalo \([0,\infty)\) a \([0,1]\). Si tomo \(t = u/(u + \Delta)\), cuando \(u = 0\) tenemos \(t = 0\) y cuando \(u \to \infty\) tenemos \(t \to 1\), así que es perfecta. \(u = \Delta t/(1-t)\), \(du = \Delta/(1-t)^2\,dt\), \(u + \Delta = \Delta/(1-t)\). Reescribiendo la función integranda:
Multiplicando por \(du = \Delta/(1-t)^2\,dt\):
Cuando \(u: 0 \to \infty\), \(t: 0 \to 1\):
⚪ Mei: Ah, esto es exactamente la forma \(B(2, n-2) = \int_0^1 t^{2-1}(1-t)^{(n-2)-1}dt\).
🟡 Lina: Exacto. Es la función beta \(B(a,b) = \int_0^1 t^{a-1}(1-t)^{b-1}dt = \frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}\) que presenté antes. Aquí \(a = 2\), \(b = n-2\):
Sustituyendo:
Como \(\Gamma(2) = 1! = 1\), con esto se obtiene la ecuación (D.34).
⚪ Mei: Para el caso \(n = 2\), \(\Gamma(0)\) diverge. ¿Eso significa que la integral es infinita?
🟡 Lina: ¡Muy perspicaz! Exactamente. Cuando \(n = 2\), \(\Gamma(n-2) = \Gamma(0) = \infty\) y la integral diverge logarítmicamente. Esta es la identidad del "infinito que aparece dentro del loop" — la divergencia ultravioleta que vimos en Cap. 13. En la regularización dimensional se captura esta divergencia como un polo \(1/\epsilon\) tomando \(d = 4 - 2\epsilon\). Los detalles están en Cap. 14.
✅ Verificación de comprensión: ¿Por qué surge la divergencia en la fórmula de integral básica en espacio euclídeo (D.34) cuando \(n = 2\)? ¿A la propiedad de qué función se debe matemáticamente?
Respuesta
Porque \(\Gamma(n-2) = \Gamma(0)\) que aparece en la fórmula cuando \(n = 2\) diverge. La función gamma tiene un polo en \(z = 0\) y \(\Gamma(0) = \infty\). Físicamente esto corresponde a la divergencia ultravioleta (divergencia logarítmica) de la integral de loop, y en regularización dimensional se captura como un polo \(1/\epsilon\) tomando \(d = 4 - 2\epsilon\).
📝 Ejercicios:
- Cálculo explícito de la ecuación (D.34) para \(n = 3\) y verificación dimensional → Problema B-7. Fórmula general de parámetros de Feynman (\(n = 3\))
- Integral de momento en espacio euclídeo 2-dimensional y comparación con 4 dimensiones → Problema M-1. Organización completa de integrales a un loop usando parámetros de Feynman
Caso \(n = 2\) (divergencia logarítmica)¶
🟡 Lina: El caso \(n = 2\) es el más importante, así que veamos también cómo se manifiesta la divergencia por otro método. En la ecuación (D.34) apareció \(\Gamma(0) = \infty\) y la fórmula no se podía usar directamente. Así que cortamos el límite superior de la integral en un valor finito \(\Lambda^2\) — es decir, hacemos la aproximación de "ignorar las contribuciones de momentos mayores que \(\Lambda\)". A este \(\Lambda\) se le llama corte ultravioleta (cutoff). Físicamente corresponde a la imagen de "la escala de energía máxima hasta la que la teoría es válida".
🔵 Kai: Se pone a mano un límite superior de energía "hasta aquí confío", ¿no?
🟡 Lina: Eso es. Reescribo el numerador \(u\) como \((u+\Delta) - \Delta\) — esto es una transformación idéntica, simplemente sumar y restar \(\Delta\). Así aparece una forma que puede simplificarse con el \((u+\Delta)\) del denominador:
Integro cada término. El primer término: \(\int_0^{\Lambda^2} \frac{du}{u+\Delta} = [\ln(u+\Delta)]_0^{\Lambda^2} = \ln(\Lambda^2+\Delta) - \ln\Delta = \ln\frac{\Lambda^2+\Delta}{\Delta}\). El segundo término: \(\int_0^{\Lambda^2} \frac{\Delta\,du}{(u+\Delta)^2} = \Delta\left[-\frac{1}{u+\Delta}\right]_0^{\Lambda^2} = \Delta\left(-\frac{1}{\Lambda^2+\Delta} + \frac{1}{\Delta}\right) = 1 - \frac{\Delta}{\Lambda^2+\Delta} = \frac{\Lambda^2}{\Lambda^2+\Delta}\). Juntando:
Cuando \(\Lambda \gg \sqrt{\Delta}\):
🔵 Kai: Ah, apareció \(\ln\Lambda^2\). Al hacer el corte más grande, diverge logarítmicamente.
🟡 Lina: Ten cuidado — como vimos en la derivación de la ecuación (D.34), a la integral de loop completa se le multiplica el coeficiente \(\frac{1}{(4\pi)^2}\). Es decir, el resultado tras la rotación de Wick de la ecuación (D.28) con \(n = 2\) es \(\frac{i}{(4\pi)^2}\left(\ln\frac{\Lambda^2}{\Delta} - 1 + \cdots\right)\).
🔵 Kai: Diverge logarítmicamente con respecto al corte \(\Lambda\). Es mejor que divergir como \(\Lambda^2\) u otra potencia, pero aun así es infinito...
🟡 Lina: Sí. Pero esta divergencia logarítmica se puede tratar con renormalización. Como aprendimos en Cap. 14.
Caso con \(\ell\) en el numerador¶
🟡 Lina: Las fórmulas para cuando el numerador contiene \(\ell_E^\mu\) o \(\ell_E^\mu \ell_E^\nu\) también son importantes:
Potencias impares:
Evidente por simetría.
Potencias pares:
🔵 Kai: ¿Por qué aparece \(\delta^{\mu\nu}/4\)?
🟡 Lina: En espacio euclídeo la integral es simétrica bajo rotaciones 4-dimensionales, así que el resultado debe ser un tensor invariante bajo rotaciones. El único tensor simétrico de rango 2 invariante bajo rotaciones es \(\delta^{\mu\nu}\). Así que se puede escribir \(\int \ell_E^\mu \ell_E^\nu (\cdots) = C\,\delta^{\mu\nu}\). Para determinar el coeficiente \(C\), se toma \(\mu = \nu\) y se suma: el lado izquierdo es \(\int \ell_E^2 (\cdots)\), el derecho es \(C \cdot \delta^{\mu\mu} = 4C\) (porque en 4 dimensiones \(\delta^{\mu\mu} = 4\)). Comparando: \(C = \frac{1}{4}\int \ell_E^2 (\cdots)\).
⚪ Mei: Es decir, el "4" es el número de dimensiones. En 4 dimensiones se divide por 4. Si fuera una integral en 3 dimensiones sería \(\delta^{\mu\nu}/3\).
🟡 Lina: Exacto. En general, en \(d\) dimensiones con el mismo argumento sale \(\delta^{\mu\nu}/d\). Es un hecho que se usa en regularización dimensional con \(d = 4 - 2\epsilon\). Calculemos ahora el lado derecho de la ecuación (D.38). Escribiendo \(\ell_E^2\) en el numerador como \((\ell_E^2 + \Delta) - \Delta\):
Aplicando la ecuación (D.34):
🔵 Kai: Aunque haya \(\ell_E^2\) en el numerador, solo con sumar y restar \(\Delta\) se reduce a la fórmula básica. Es la misma técnica que el cálculo con corte de \(n = 2\) de antes.
⚪ Mei: Usando repetidamente la relación de recurrencia \(\Gamma(z+1) = z\,\Gamma(z)\) que nos enseñó Lina: \(\Gamma(n-1) = (n-2)\Gamma(n-2) = (n-2)(n-3)\Gamma(n-3)\), así que \(\frac{\Gamma(n-3)}{\Gamma(n-1)} = \frac{1}{(n-2)(n-3)}\). Igualmente \(\Gamma(n) = (n-1)(n-2)\Gamma(n-2)\), así que \(\frac{\Gamma(n-2)}{\Gamma(n)} = \frac{1}{(n-1)(n-2)}\).
🟡 Lina: Muy bien. Tomando la diferencia (con denominador común):
🔵 Kai: Usando la relación de recurrencia 3 veces: \(\Gamma(n) = (n-1)(n-2)(n-3)\Gamma(n-3)\), así que el denominador es directamente \(\Gamma(n)/\Gamma(n-3)\).
🟡 Lina: Exacto. \(\frac{2}{(n-1)(n-2)(n-3)} = \frac{2\,\Gamma(n-3)}{\Gamma(n)}\). Combinando con el \(\delta^{\mu\nu}/4\) de antes: \(\frac{\delta^{\mu\nu}}{4} \times \frac{2\,\Gamma(n-3)}{\Gamma(n)} = \frac{\delta^{\mu\nu}}{2}\cdot\frac{\Gamma(n-3)}{\Gamma(n)}\):
Resultado devuelto al espacio de Minkowski¶
🟡 Lina: En los cálculos prácticos, a menudo se quiere el resultado en espacio de Minkowski antes de la rotación de Wick. Incluyendo el factor \(i\) de la ecuación (D.31):
🔵 Kai: ¿De dónde viene el \((-1)^n\)?
🟡 Lina: Al pasar la integral del espacio de Minkowski al euclídeo, se combinan dos efectos:
- De \(d^4\ell = i\,d^4\ell_E\) (ecuación (D.30)) sale un factor \(i\)
- \(\ell^2 - \Delta \to -\ell_E^2 - \Delta = -(\ell_E^2 + \Delta)\)
⚪ Mei: Es decir, de la medida de integración sale \(i\) y del denominador sale \((-1)^n\).
🟡 Lina: Exacto. La potencia \(n\) del denominador cambia como \((\ell^2 - \Delta + i\varepsilon)^n = [-(\ell_E^2 + \Delta - i\varepsilon)]^n = (-1)^n(\ell_E^2 + \Delta - i\varepsilon)^n\). En espacio euclídeo \(\ell_E^2 + \Delta > 0\), así que no hay preocupación de que el denominador se anule, y \(\varepsilon\) ya no es necesario — se puede tomar con seguridad \(\varepsilon \to 0^+\):
Aquí \(n\) es un entero positivo, así que \((-1)^n = \pm 1\). El inverso de \(\pm 1\) es él mismo: \(1/(-1)^n = (-1)^n\) (verificación: \((-1)^n \times (-1)^n = (-1)^{2n} = 1\)). Por lo tanto \(\frac{i}{(-1)^n} = i \cdot (-1)^n\), y el coeficiente total es \(i\,(-1)^n\). La ecuación (D.31) era el caso \(n = 2\) con \((-1)^2 = 1\), así que solo quedaba \(i\), pero para \(n\) general queda este \((-1)^n\).
⚪ Mei: Verificación: para \(n = 2\), \((-1)^2 = 1\) así que el coeficiente es de la forma \(i/(4\pi)^2 \cdot \Gamma(0)/\Gamma(2) \cdot 1/\Delta^0\), pero \(\Gamma(0)\) diverge así que la fórmula no se puede usar tal cual — esa es la divergencia ultravioleta. Para \(n = 3\), \((-1)^3 = -1\) y \(-i/(4\pi)^2 \cdot \Gamma(1)/\Gamma(3) \cdot 1/\Delta = -i/(32\pi^2\Delta)\). Este es finito.
🟡 Lina: Correcto. Con esto queda confirmada la ecuación (D.40).
Verificación de comprensión: Indica dos efectos esenciales de la rotación de Wick
- Cambia la métrica de Minkowski \(\ell^2 = \ell_0^2 - \vec{\ell}^{\,2}\) a la métrica euclídea \(-\ell_E^2 = -(\ell_0^E)^2 - \vec{\ell}^{\,2}\), evitando los polos de la función integranda.
- La integral se vuelve esféricamente simétrica en 4 dimensiones, haciendo posible la integración angular.
Resumen: catálogo de la caja de herramientas¶
🟡 Lina: Finalmente, presento una lista de las fórmulas principales de este Apéndice. Cuando te pierdas en un cálculo de loops, vuelve aquí.
Tabla D.3: Lista de fórmulas principales del Apéndice D
| Número | Fórmula | Uso |
|---|---|---|
| (D.3)–(D.4) | \([\phi] = 1\), \([\psi] = 3/2\) | Determinación de dimensiones de campos y constantes de acoplamiento |
| (D.7) | \(\eta^{\mu\nu} = (+,-,-,-)\) | Convención de la métrica |
| (D.21)–(D.22) | Convención de transformada de Fourier | Seguimiento de factores \(2\pi\) |
| (D.24) | Parámetro de Feynman (2 factores) | Unificación de denominadores |
| (D.25) | Parámetro de Feynman (\(n\) factores) | Unificación de múltiples propagadores |
| (D.26) | Caso con potencias diferentes | Unificación de denominadores con potencias desiguales |
| (D.29)–(D.30) | \(\ell_0 \to i\ell_0^E\), \(d^4\ell = i\,d^4\ell_E\) | Rotación de Wick |
| (D.34) | Integral básica en espacio euclídeo | Integrales de loop de tipo escalar |
| (D.37)–(D.39) | Caso con \(\ell\) en el numerador | Integrales de loop de tipo tensorial |
| (D.40) | Resultado final en espacio de Minkowski | Cálculo de amplitudes físicas |
🔵 Kai: Con todo esto, parece que ya se pueden hacer concretamente los cálculos de renormalización de los capítulos 13–14. Pero una cosa que me preocupa: cuando hay 2 loops o más, aparecen muchos parámetros de Feynman, y la integral final en \(x\) se vuelve muy complicada, ¿no?
🟡 Lina: Buena duda. Efectivamente, con 2 loops o más quedan integrales múltiples de parámetros de Feynman que a menudo no se pueden realizar analíticamente. En esos casos se recurre a integración numérica o funciones especiales (como polilogaritmos). Pero el procedimiento para ejecutar las integrales de momento — unificar denominadores, completar cuadrados, hacer rotación de Wick, integrar en coordenadas esféricas — es el mismo.
🔵 Kai: Entendido, el procedimiento es el mismo y solo la integral final en parámetros de Feynman se hace difícil. Pero con 2 loops hay dos momentos de loop, ¿verdad? ¿Se hace la rotación de Wick dos veces? ¿O se rotan las dos componentes temporales simultáneamente?
🟡 Lina: Sí, para cada momento de loop \(k_1\), \(k_2\) se hace la rotación de Wick \(k_{1,0} \to ik_{1,0}^E\), \(k_{2,0} \to ik_{2,0}^E\). El flujo es: primero se integra uno de los momentos de loop (usando las fórmulas de 1 loop), y para el que queda se sigue el mismo procedimiento una vez más.
🔵 Kai: Es una estructura anidada. Se fija el loop exterior y se resuelve primero el interior — como un doble bucle en programación. Pero si el resultado de integrar el loop interior depende del momento del loop exterior, la integral exterior se vuelve complicada también, ¿no? ¿Al final no se llega a algo intratable?
🟡 Lina: Buena preocupación. Efectivamente, el resultado de la integral del loop interior queda como función del momento del loop exterior y de los parámetros de Feynman, así que la integral exterior es generalmente más complicada que a 1 loop. A menudo no se puede escribir en forma cerrada analítica. Pero como el procedimiento — parámetros de Feynman → completación de cuadrados → rotación de Wick → coordenadas esféricas — es el mismo, en principio siempre se puede plantear el cálculo.
🔵 Kai: Ya veo. Entonces dicho al revés: con las herramientas de este apéndice se puede plantear el marco de cálculo para cualquier orden de loops en principio, pero si se puede escribir la respuesta en forma cerrada o no es otra cuestión.
⚪ Mei: Resumiendo, la estructura del cálculo de loops tiene 4 pasos: "①Unificar denominadores con parámetros de Feynman → ②Completación de cuadrados para forma estándar → ③Euclideanización por rotación de Wick → ④Integración en coordenadas esféricas". Con 2 loops o más se aplican repetidamente estos 4 pasos para cada momento de loop, y al final queda la integral múltiple en parámetros de Feynman.
🔵 Kai: Memorizado los 4 pasos. Pero una última cosa — esta caja de herramientas es para cuando "la integral converge", ¿verdad? Para cuando diverge (como \(n = 2\)), al final se necesita otro tratamiento con corte o regularización dimensional. La caja de herramientas sola no basta.
🟡 Lina: Exacto. Este apéndice es una caja de herramientas hasta "llevar la integral a forma estándar"; el tratamiento de las divergencias — es decir, regularización y renormalización — es trabajo de Cap. 14. Pero sin estos 4 pasos, ni siquiera se podría identificar "qué es lo que diverge". Por eso es indispensable como base.
🔵 Kai: Identificar con la caja de herramientas "qué diverge" y dejar el tratamiento al capítulo 14 — la división de roles está bien clara.
Referencias¶
- Quantum Field Theory and the Standard Model (M. Schwartz) Appendix B "Regularization"
- An Introduction to Quantum Field Theory (Peskin & Schroeder) Apéndice A "Some Useful Formulas"
- Quantum Field Theory (Srednicki) Capítulo 14 "Loop Integrals in Vacuum"
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.