Apéndice G Derivación de las ecuaciones de Einstein¶
Resumen de los capítulos anteriores: En Cap. 6 presentamos la ecuación de Einstein \(G_{\mu\nu} = 8\pi G\, T_{\mu\nu}\) de forma axiomática como "curvatura del espaciotiempo = energía de la materia". Sin embargo, ¿de dónde viene esta ecuación? Así como en la mecánica newtoniana se puede derivar \(F = ma\) a partir de \(L = T - V\), la ecuación de Einstein también puede derivarse del principio de acción.
Objetivo de este apéndice
- Seguir línea por línea la variación de la acción de Einstein-Hilbert y derivar completamente las ecuaciones de Einstein
- Como ejemplo práctico del cálculo variacional, servir de puente hacia la acción de Polyakov de la teoría de cuerdas (Cap. 13)
G.1 Motivación — ¿Por qué derivar desde el principio de acción?¶
🟡 Lina: Si repasamos la historia de la física, las ecuaciones fundamentales siempre se han obtenido por dos rutas.
Tabla G.1: Comparación de rutas de derivación de ecuaciones fundamentales
| Campo | Razonamiento directo | Principio de acción |
|---|---|---|
| Mecánica | Ecuación de movimiento de Newton \(F = ma\) | Variación del lagrangiano \(L = T - V\) |
| Electromagnetismo | Ecuaciones de Maxwell | Acción del campo electromagnético \(S = -\frac{1}{4}\int F_{\mu\nu}F^{\mu\nu}\sqrt{-g}\,d^4x\) |
| Relatividad general | Razonamiento físico de Einstein (1915) | Variación de la acción de Einstein-Hilbert |
🔵 Kai: En el caso de Newton, \(F = ma\) vino primero, y después se pudo rederivarlo con el lagrangiano. ¿Con la ecuación de Einstein es igual?
🟡 Lina: Sí. Einstein llegó a la ecuación a partir del principio de equivalencia, la covariancia general y la consistencia con el límite newtoniano. Casi simultáneamente, Hilbert trabajaba en la formulación usando el principio de acción. Históricamente fue "primero la ecuación, después la acción". Pero el principio de acción tiene ventajas decisivas.
🔵 Kai: ¿Qué ventajas tiene?
🟡 Lina: Tres:
- Las simetrías se garantizan automáticamente — Si la acción es un escalar, las ecuaciones que se derivan son automáticamente covariantes bajo transformaciones generales de coordenadas
- Marco unificado — Tanto la gravedad como la materia se incluyen en la misma acción \(S = S_{EH} + S_M\), y todo se obtiene de \(\delta S = 0\)
- Camino hacia la cuantización — Como vimos en la teoría cuántica de campos (Teoría Cuántica de Campos capítulos 10–11), es el punto de partida de la integral de camino \(\int \mathcal{D}[g]\,e^{iS/\hbar}\)
🔵 Kai: ¿En la teoría de cuerdas se usa el mismo espíritu?
🟡 Lina: Exactamente. La acción de Polyakov de Cap. 13 también tiene la misma estructura: "variar una acción escalar sobre la hoja de mundo". Por eso, si dominas la técnica variacional aquí, la derivación en teoría de cuerdas se lee con mucha más fluidez.
Las bases del cálculo variacional están en Relatividad General Relatividad General Apéndice C, y la variación del lagrangiano de campos en Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3.
G.2 La acción de Einstein-Hilbert¶
G.2.1 Requisitos que determinan la forma de la acción¶
🟡 Lina: Para determinar la acción del campo gravitatorio \(S_{EH}\), imponemos los siguientes requisitos:
- Invariancia bajo transformaciones generales de coordenadas — La acción es un escalar (su valor no cambia bajo transformaciones de coordenadas)
- Construida únicamente con el tensor métrico \(g_{\mu\nu}\) y sus derivadas — Los grados de libertad del campo gravitatorio están en la métrica
- Ecuaciones de movimiento de segundo orden — Queremos que la solución quede determinada al especificar posición y velocidad como condiciones iniciales. En general, si el lagrangiano contiene derivadas de orden \(n\) de la variable, la ecuación de Euler-Lagrange es una ecuación diferencial de orden \(2n\) (porque se integra por partes \(n\) veces en la variación). \(R\) contiene derivadas de segundo orden de la métrica, así que ingenuamente las ecuaciones de movimiento parecerían ser de cuarto orden. Sin embargo, gracias a la estructura especial de \(R\), los términos que contienen \(\delta R_{\mu\nu}\) se convierten en una derivada total (término de frontera) y desaparecen, resultando finalmente en ecuaciones de segundo orden (lo confirmaremos en G.3.3)
- Máxima simplicidad — Términos del orden más bajo posible
🔵 Kai: ¿Qué escalar concreto satisface todas esas condiciones?
🟡 Lina: Exactamente el escalar de Ricci \(R\) que estudiamos en Relatividad General Relatividad General Cap. 13. \(R = g^{\mu\nu}R_{\mu\nu}\) es el escalar más simple que contiene derivadas de segundo orden de la métrica. Combinándolo con el elemento de volumen \(\sqrt{-g}\,d^4x\) en 4 dimensiones:
Aquí usamos unidades naturales \(c = 1\) (restaurando \(c\) se tiene \(1/(16\pi G) \to c^4/(16\pi G)\)).
🔵 Kai: ¿Por qué es necesario \(\sqrt{-g}\)?
🟡 Lina: Con solo \(d^4x\) aparecería un jacobiano bajo transformaciones de coordenadas. \(\sqrt{-g}\,d^4x\) es el elemento de volumen invariante bajo transformaciones generales de coordenadas. Esto lo estudiamos en Relatividad General Relatividad General Cap. 7.
⚪ Mei: Es decir, \(\sqrt{-g}\) es el factor de corrección para "medir el volumen correctamente independientemente de la elección de coordenadas".
✅ Verificación de comprensión: ¿Cuáles son los 4 requisitos que determinan la forma de la acción de Einstein-Hilbert?
Respuesta
(1) Invariancia bajo transformaciones generales de coordenadas (la acción es un escalar), (2) construida únicamente con el tensor métrico y sus derivadas, (3) hasta derivadas de segundo orden (ecuaciones de movimiento de segundo orden), (4) máxima simplicidad (términos del orden más bajo posible).
G.2.2 Adición del término de constante cosmológica¶
🟡 Lina: Existe otro término que satisface los requisitos. El volumen multiplicado por una constante \(\Lambda\) (constante cosmológica):
Este también es un escalar invariante bajo transformaciones generales de coordenadas, construido con derivadas de orden 0 de la métrica (sin derivadas). Como es el término más simple, no hay razón de principio para excluirlo.
✅ Verificación de comprensión: ¿Por qué se permite incluir el término de constante cosmológica \(S_\Lambda\) en la acción gravitatoria?
Respuesta
El término de constante cosmológica es un escalar invariante bajo transformaciones generales de coordenadas, construido con derivadas de orden 0 de la métrica (no contiene derivadas), siendo el término más simple posible. Por lo tanto, satisface los requisitos de simetría y no hay razón de principio para excluirlo.
🟡 Lina: Combinando esto con el \(S_{EH}\) anterior, la acción gravitatoria total es:
El coeficiente \(-2\Lambda\) es una convención, elegida para que en la ecuación de Einstein final aparezca \(\Lambda g_{\mu\nu}\).
⚪ Mei: Es decir, se combinan el término de \(R\) y el término constante en una sola integral.
G.2.3 Acción total¶
Si la acción de los campos de materia es \(S_M\), la acción total es:
El principio de mínima acción:
Esto da las ecuaciones de Einstein. A continuación, ejecutamos esta variación.
✅ Verificación de comprensión: ¿Cuáles son las cantidades escalares contenidas en el integrando de la acción de Einstein-Hilbert?
Respuesta
La curvatura escalar \(R\) (y la constante cosmológica \(\Lambda\)).
✅ Verificación de comprensión: En el principio de mínima acción, ¿con respecto a qué se varía la acción total \(S\) igualándola a cero?
Respuesta
Se varía con respecto al tensor métrico \(g^{\mu\nu}\) y se iguala a cero.
G.3 Ejecución de la variación — 3 contribuciones¶
🟡 Lina: Como \(R = g^{\mu\nu}R_{\mu\nu}\), la variación del integrando \(\sqrt{-g}\,R = \sqrt{-g}\,g^{\mu\nu}R_{\mu\nu}\) se descompone en 3 partes por la regla del producto:
Llamaremos a cada término Término 1, Término 2 y Término 3. La estructura global se muestra en Fig. G.1「Descomposición de la variación de la acción de Einstein–Hilbert」.
🔵 Kai: Como es un producto de 3 factores, por la regla del producto se descompone en 3 partes.
🟡 Lina: Exacto. En la figura están ordenados numéricamente, pero a continuación avanzaremos por orden de dificultad de cálculo: primero el Término 3 (cálculo de \(\delta\sqrt{-g}\)) que es técnicamente independiente, luego el Término 1 que es trivial (se queda tal cual), y finalmente el Término 2 que es el núcleo del cálculo (identidad de Palatini).
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart TD
A["δ(√-g · g^μν R_μν)"] --> B["Término 1<br>√-g R_μν δg^μν"]
A --> C["Término 2<br>√-g g^μν δR_μν"]
A --> D["Término 3<br>R · δ√-g"]
B --> E["Se queda tal cual<br>→ R_μν δg^μν"]
C --> F["Identidad de Palatini<br>∇_α V^α (derivada total)"]
F --> G["Término de frontera → 0"]
D --> H["Fórmula de δ√-g<br>→ -½ R g_μν δg^μν"]
E --> I["Suma: (R_μν - ½ g_μν R) δg^μν"]
H --> IFig. G.1: Descomposición de la variación de la acción de Einstein–Hilbert
G.3.1 Término 3: Cálculo de \(\delta\sqrt{-g}\)¶
🟡 Lina: Empecemos por el Término 3, que es técnicamente independiente. Con \(g \equiv \det(g_{\mu\nu})\), queremos obtener la variación de \(\sqrt{-g}\).
Paso 1: Variación del determinante (fórmula de Jacobi)
Para el determinante de una matriz \(A\), en general:
Esto se derivó en Relatividad General Relatividad General Apéndice C. Aplicándolo al tensor métrico:
🔵 Kai: \(\delta g_{\mu\nu}\) y \(\delta g^{\mu\nu}\) son cosas distintas, ¿verdad? ¿Cuál es la relación?
🟡 Lina: Buena pregunta. Variando ambos lados de \(g^{\mu\alpha}g_{\alpha\nu} = \delta^\mu_\nu\):
Multiplicando por \(g^{\nu\beta}\) y reorganizando:
Por lo tanto:
⚪ Mei: Al subir y bajar índices el signo se invierte. Es la misma estructura que la derivada de una matriz inversa.
🟡 Lina: Así es.
Paso 2: Escribir \(\delta g\) en términos de \(\delta g^{\mu\nu}\)
Usando la relación anterior:
Paso 3: Obtener \(\delta\sqrt{-g}\)
La variación de \(\sqrt{-g}\) por la regla de la cadena:
Sustituyendo \(\delta g = -g\,g_{\mu\nu}\,\delta g^{\mu\nu}\):
Como \(g < 0\), entonces \(-g > 0\) y \(\sqrt{-g}\) está bien definido como número real. De la definición de \(\sqrt{-g}\) se tiene \((\sqrt{-g})^2 = -g\), así que \(g = -(\sqrt{-g})^2\). Sustituyendo esto en el numerador:
La última igualdad es simplemente cancelar un \(\sqrt{-g}\) entre numerador y denominador.
Por lo tanto:
⚪ Mei: ¡Qué forma tan elegante! \(g_{\mu\nu}\,\delta g^{\mu\nu}\) es una contracción de índices, así que es un escalar.
🟡 Lina: Así es. Con esto, el Término 3 queda:
📝 Ejercicios:
- Derivación de \(\delta\sqrt{-g}\) → Problema M-1. Derivación de \(\delta\sqrt{-g}\)
G.3.2 Término 1: \(\sqrt{-g}\,R_{\mu\nu}\,\delta g^{\mu\nu}\)¶
🟡 Lina: El Término 1 se queda tal cual:
No hay nada que calcular. \(R_{\mu\nu}\) se comporta como una "constante" respecto a la variación de \(g^{\mu\nu}\).
G.3.3 Término 2: \(\sqrt{-g}\,g^{\mu\nu}\,\delta R_{\mu\nu}\) — Identidad de Palatini¶
🟡 Lina: Aquí está el núcleo de la derivación. El tensor de Ricci \(R_{\mu\nu}\) se escribe en términos de derivadas de los símbolos de Christoffel \(\Gamma^\alpha_{\mu\nu}\), así que al cambiar \(g^{\mu\nu}\), \(\Gamma\) cambia y \(R_{\mu\nu}\) también cambia.
Paso 1: \(\delta\Gamma^\alpha_{\mu\nu}\) es un tensor
🔵 Kai: \(\Gamma^\alpha_{\mu\nu}\) no es un tensor por sí mismo, pero ¿su variación sí lo es?
🟡 Lina: Sí. Recuerda que la ley de transformación de \(\Gamma\) tiene un término extra con la "derivada segunda de la transformación de coordenadas"——es decir, al realizar una transformación de coordenadas \(x \to x'\), aparecen términos como \(\partial^2 x^\mu / \partial x'^\alpha \partial x'^\beta\) (ver Relatividad General Relatividad General Cap. 7). "Transformarse como un tensor" significa que al cambiar de coordenadas, cada componente cambia según una regla regular (multiplicando por una matriz de transformación por cada índice). \(\Gamma\) tiene términos extra que se desvían de esa regla, por eso "no es un tensor".
Sin embargo, estos términos extra dependen únicamente de la elección del sistema de coordenadas y no dependen del valor de la métrica. Concretamente, la ley de transformación de \(\Gamma\) tiene la estructura "parte que se transforma tensorialmente + término extra proporcional a la derivada segunda de la transformación de coordenadas \(\partial^2 x/\partial x'^2\)". Este término extra está determinado solo por la transformación de coordenadas y no depende en absoluto de qué valor tiene la métrica \(g_{\mu\nu}\). Por eso, aunque \(\Gamma\) no es un tensor, cuando variamos la métrica en el mismo sistema de coordenadas como \(g_{\mu\nu} \to g_{\mu\nu} + \delta g_{\mu\nu}\), y consideramos la diferencia \(\delta\Gamma = \Gamma[g + \delta g] - \Gamma[g]\) entre la conexión antes y después de la variación, los términos extra al transformar coordenadas aparecen de forma idéntica en ambos y se cancelan.
🔵 Kai: Ah, ya entiendo. Los términos extra dependen solo de "la elección del sistema de coordenadas", así que no cambian al variar la métrica. Por eso al tomar la diferencia se cancelan——igual que cuando una parte común desaparece al restar.
🟡 Lina: Exacto. Como resultado, \(\delta\Gamma^\alpha_{\mu\nu}\) se transforma como un tensor.
Paso 2: Definición del tensor de Ricci y su variación
El tensor de Ricci es la contracción del tensor de Riemann (ver Relatividad General Relatividad General Cap. 13):
Calculamos su variación. "Variar" significa encontrar el cambio que se produce cuando la métrica cambia infinitesimalmente como \(g_{\mu\nu} \to g_{\mu\nu} + \delta g_{\mu\nu}\), lo que conlleva \(\Gamma \to \Gamma + \delta\Gamma\). Como \(\delta\Gamma\) es infinitesimal, ignoramos términos de segundo orden o superior en \(\delta\Gamma\) (como \((\delta\Gamma)^2\)) y solo retenemos los de primer orden——es la misma operación que quedarse con el término de primer orden en una expansión de Taylor. Los términos con derivadas parciales \(\partial_\alpha\Gamma^\alpha_{\mu\nu}\) son lineales (de primer grado) en \(\Gamma\), así que directamente dan \(\partial_\alpha(\delta\Gamma^\alpha_{\mu\nu})\). A los términos \(\Gamma\Gamma\) se les aplica la regla del producto (\((fg)' = f'g + fg'\)). Por ejemplo, la variación de \(\Gamma^\alpha_{\alpha\beta}\Gamma^\beta_{\mu\nu}\) da \(\delta(\Gamma^\alpha_{\alpha\beta})\cdot\Gamma^\beta_{\mu\nu} + \Gamma^\alpha_{\alpha\beta}\cdot\delta(\Gamma^\beta_{\mu\nu})\), dos términos. De forma similar, la variación de \(-\Gamma^\alpha_{\nu\beta}\Gamma^\beta_{\mu\alpha}\) da \(-\delta(\Gamma^\alpha_{\nu\beta})\cdot\Gamma^\beta_{\mu\alpha} - \Gamma^\alpha_{\nu\beta}\cdot\delta(\Gamma^\beta_{\mu\alpha})\), otros dos términos. Sumando todo:
⚪ Mei: Esto es tremendamente complicado…
🟡 Lina: En realidad, como \(\delta\Gamma\) es un tensor, podemos reemplazar las derivadas parciales \(\partial_\alpha\) por derivadas covariantes \(\nabla_\alpha\). Verifiquémoslo concretamente. Expandiendo \(\nabla_\alpha(\delta\Gamma^\rho_{\mu\nu})\) según la definición de derivada covariante (ver Relatividad General Relatividad General Cap. 7):
De forma similar, expandiendo \(\nabla_\nu(\delta\Gamma^\rho_{\mu\alpha})\):
🔵 Kai: Solo estoy aplicando la definición de derivada covariante, pero hay muchos términos… ¿De verdad esto coincide con la expresión complicada de arriba?
🟡 Lina: Coincide. Al tomar la diferencia \(\nabla_\alpha(\delta\Gamma^\rho_{\mu\nu}) - \nabla_\nu(\delta\Gamma^\rho_{\mu\alpha})\) y luego contraer poniendo \(\rho = \alpha\) (\(\rho\) era hasta ahora un índice libre, pero lo igualamos a \(\alpha\) y sumamos), aparecen como términos de derivadas parciales \(\partial_\alpha(\delta\Gamma^\alpha_{\mu\nu}) - \partial_\nu(\delta\Gamma^\alpha_{\mu\alpha})\). Veamos concretamente los términos restantes \(\Gamma \cdot \delta\Gamma\).
Expandiendo \(\nabla_\alpha(\delta\Gamma^\alpha_{\mu\nu})\) según la definición de derivada covariante (después de realizar la contracción \(\rho = \alpha\)), además de la derivada parcial \(\partial_\alpha(\delta\Gamma^\alpha_{\mu\nu})\) aparecen 3 términos \(\Gamma\cdot\delta\Gamma\):
De forma similar, expandiendo \(\nabla_\nu(\delta\Gamma^\alpha_{\mu\alpha})\):
Al tomar la diferencia aparecen en total 6 términos \(\Gamma\cdot\delta\Gamma\). De estos, el cuarto término de la primera ecuación \(-\Gamma^\sigma_{\alpha\nu}(\delta\Gamma^\alpha_{\mu\sigma})\) y el cuarto término de la segunda ecuación \(+\Gamma^\sigma_{\nu\alpha}(\delta\Gamma^\alpha_{\mu\sigma})\) se cancelan exactamente por la simetría de los índices inferiores de \(\Gamma\): \(\Gamma^\sigma_{\alpha\nu} = \Gamma^\sigma_{\nu\alpha}\). Escribiendo los 4 términos restantes:
- Segundo término de la primera ecuación: \(+\Gamma^\alpha_{\alpha\sigma}(\delta\Gamma^\sigma_{\mu\nu})\)
- Tercer término de la primera ecuación: \(-\Gamma^\sigma_{\alpha\mu}(\delta\Gamma^\alpha_{\sigma\nu})\)
- Segundo término de la segunda ecuación: \(-\Gamma^\alpha_{\nu\sigma}(\delta\Gamma^\sigma_{\mu\alpha})\)
- Tercer término de la segunda ecuación: \(+\Gamma^\sigma_{\nu\mu}(\delta\Gamma^\alpha_{\sigma\alpha})\)
Se puede verificar que estos coinciden con los 4 términos \(\Gamma\cdot\delta\Gamma\) de \(\delta R_{\mu\nu}\) al inicio del Paso 2, mediante renombramiento de índices mudos (por ejemplo, en el tercer término de la segunda ecuación \(+\Gamma^\sigma_{\nu\mu}(\delta\Gamma^\alpha_{\sigma\alpha})\), poniendo \(\sigma \to \beta\) se obtiene \(+\Gamma^\beta_{\nu\mu}(\delta\Gamma^\alpha_{\beta\alpha})\), y usando la simetría de los índices inferiores de \(\Gamma\): \(\Gamma^\beta_{\nu\mu} = \Gamma^\beta_{\mu\nu}\), queda \(+\Gamma^\beta_{\mu\nu}(\delta\Gamma^\alpha_{\beta\alpha})\). Esto corresponde al término \((\delta\Gamma^\alpha_{\alpha\beta})\Gamma^\beta_{\mu\nu}\) de la expresión original, solo con el orden de los factores invertido). Los demás términos se verifican de forma similar por renombramiento de índices mudos (los lectores que deseen seguir la correspondencia de los 4 términos uno por uno pueden consultar los ejercicios en Relatividad General Relatividad General Apéndice C). El punto clave es que los términos con coeficientes de conexión contenidos en la definición de derivada covariante absorben exacta y completamente los 4 términos \(\Gamma\cdot\delta\Gamma\) de \(\delta R_{\mu\nu}\). Esto no es casualidad, sino una consecuencia directa de que \(\delta\Gamma\) es un tensor——como la derivada covariante es la derivada parcial de un tensor más la corrección con coeficientes de conexión, una expresión que contiene derivadas parciales de un tensor \(\delta\Gamma\) necesariamente se reorganiza en forma de derivada covariante. El resultado es:
Nótese aquí que la dirección de diferenciación (\(\alpha\) y \(\nu\)) es diferente en el primer y segundo término.
Esta es la identidad de Palatini.
🔵 Kai: Los términos con \(\Gamma\cdot\delta\Gamma\) se absorben todos dentro de la derivada covariante.
⚪ Mei: De 6 términos, 2 se cancelan y los 4 restantes coinciden exactamente——una estructura hermosa.
🔵 Kai: Entiendo que se absorben en la derivada covariante, pero ¿qué pasa en el siguiente Paso 3 cuando multiplicamos por \(g^{\mu\nu}\)?
🟡 Lina: Buena pregunta. La derivada covariante de un tensor es un tensor, así que esta expresión no depende de las coordenadas. Ahora multipliquemos por \(g^{\mu\nu}\) y reorganicemos en forma de derivada total.
Paso 3: Convertir \(g^{\mu\nu}\,\delta R_{\mu\nu}\) en una derivada total
Multiplicamos por \(g^{\mu\nu}\):
Con la conexión de Levi-Civita se cumple la condición de compatibilidad métrica \(\nabla_\alpha g^{\mu\nu} = 0\) (ver Relatividad General Relatividad General Cap. 12), por lo que \(g^{\mu\nu}\) puede introducirse dentro de la derivada covariante. Primero para el primer término:
Luego para el segundo término:
⚪ Mei: Gracias a la condición de compatibilidad métrica, \(g^{\mu\nu}\) puede pasar dentro de la derivada.
🔵 Kai: Pero el primer término es \(\nabla_\alpha(\cdots)\) y el segundo es \(\nabla_\nu(\cdots)\)——el índice de diferenciación es diferente, ¿cómo los combinamos?
🟡 Lina: Buena observación. Tal como están, no pueden combinarse en una sola divergencia. Aquí, tanto \(\alpha\) en el primer término como \(\nu\) en el segundo son índices mudos (la misma letra aparece dos veces y se contrae). Lo que queremos hacer es poner ambos términos en la misma forma \(\nabla_\lambda(\text{algo})\) para combinarlos como \(\nabla_\lambda(\text{contenido del 1er término} - \text{contenido del 2do término})\). Para ello, necesitamos igualar la letra del índice de diferenciación en ambos términos a la misma letra \(\lambda\).
🔵 Kai: Los índices mudos no cambian el valor si les cambias el nombre, ¿verdad? Como \(\sum_i a_i = \sum_j a_j\).
🟡 Lina: Exacto. Por ejemplo, en 2 dimensiones \(\sum_{\nu=0}^{1} A_\nu B^\nu = A_0 B^0 + A_1 B^1\) se escribe igual que \(\sum_{\alpha=0}^{1} A_\alpha B^\alpha = A_0 B^0 + A_1 B^1\)——la letra es solo una etiqueta del "número que se suma".
Así que voy a explicar lo que hacemos concretamente en 2 pasos:
Paso A: Renombramos los índices mudos del segundo término \(\nabla_\nu(g^{\mu\nu}\,\delta\Gamma^\alpha_{\mu\alpha})\). El objetivo es igualar el índice de diferenciación a \(\lambda\). Queremos cambiar \(\nu \to \lambda\). Verificamos que no hay problemas si \(\alpha\) se mantiene——\(\nabla_\lambda(g^{\mu\lambda}\,\delta\Gamma^\alpha_{\mu\alpha})\) tiene \(\lambda\) una vez arriba y una vez abajo, y \(\alpha\) una vez arriba y una vez abajo, sin violar la regla de contracción. OK.
🔵 Kai: Espera. ¿Qué pasaría si hago \(\nu \to \alpha\)?
🟡 Lina: Quedaría \(\nabla_\alpha(g^{\mu\alpha}\,\delta\Gamma^\alpha_{\mu\alpha})\), donde \(\alpha\) aparece en 3 lugares. Eso viola la regla de contracción de Einstein——el mismo índice solo debe aparecer como par arriba-abajo una sola vez. Por eso \(\nu\) debe cambiarse a una letra nueva distinta de \(\alpha\).
Paso B: Miramos el primer término \(\nabla_\alpha(g^{\mu\nu}\,\delta\Gamma^\alpha_{\mu\nu})\). Aquí \(\alpha\) es simultáneamente el índice de diferenciación y el índice superior de \(\Gamma\) (aparece en ambos lugares y se contrae). Renombramos este \(\alpha\) a \(\lambda\) y escribimos \(\nabla_\lambda(g^{\mu\nu}\,\delta\Gamma^\lambda_{\mu\nu})\).
Ahora que ambos términos tienen la forma \(\nabla_\lambda(\cdots)\), podemos restar el contenido de los paréntesis y combinarlos en uno solo.
🔵 Kai: ¿Está bien usar \(\lambda\) en ambos términos? ¿No se mezclan?
🟡 Lina: No hay problema. El punto es que al final combinamos los dos términos en una sola derivada covariante \(\nabla_\lambda(\text{contenido del 1er término} - \text{contenido del 2do término})\). Una vez combinados, \(\lambda\) se convierte en un solo índice mudo para toda la expresión. Por ejemplo, es la misma operación que combinar \(\sum_i a_i - \sum_j b_j\) en \(\sum_i(a_i - b_i)\), donde renombras \(j\) a \(i\) antes de restar. No hay problema mientras los índices mudos no se dupliquen dentro de cada término.
⚪ Mei: Es decir, como cambiar el nombre no cambia el valor, unificamos el índice de diferenciación de ambos términos a \(\lambda\) para poder restar el contenido de los paréntesis.
🟡 Lina: Exacto. El primer término era originalmente \(\nabla_\alpha(g^{\mu\nu}\,\delta\Gamma^\alpha_{\mu\nu})\), pero renombrando \(\alpha \to \lambda\) lo escribimos como \(\nabla_\lambda(g^{\mu\nu}\,\delta\Gamma^\lambda_{\mu\nu})\). El segundo término ya lo teníamos como \(\nabla_\lambda(g^{\mu\lambda}\,\delta\Gamma^\alpha_{\mu\alpha})\). Con esto, la derivada de ambos es \(\nabla_\lambda\) y podemos restar los contenidos:
Definimos el vector \(V^\lambda\):
Entonces:
🔵 Kai: ¡Vaya, los 6 términos con \(\Gamma\cdot\delta\Gamma\) desaparecen todos y al final queda una sola divergencia \(\nabla_\lambda V^\lambda\)!
🟡 Lina: Así es. Este es el poder del análisis tensorial.
Paso 4: Integrar y convertir en término de frontera
Multiplicando por \(\sqrt{-g}\) e integrando, por el teorema de la divergencia en coordenadas generales (ver Relatividad General Relatividad General Cap. 7):
La última igualdad se debe a la identidad \(\sqrt{-g}\,\nabla_\alpha V^\alpha = \partial_\alpha(\sqrt{-g}\,V^\alpha)\) (ver Relatividad General Relatividad General Cap. 7).
Esto puede convertirse en una integral sobre la frontera mediante el teorema de la divergencia en 4 dimensiones:
⚪ Mei: La integral de volumen se convierte en una integral sobre la superficie frontera——el mismo espíritu que el teorema de Gauss del análisis vectorial.
🟡 Lina: Exacto. Y ahora entramos en la discusión de las condiciones de frontera.
Condiciones de frontera: En el problema variacional imponemos \(\delta g^{\mu\nu} = 0\) en la frontera (fijamos la métrica en la frontera). Ingenuamente querríamos decir "si \(g\) está fijo, \(\Gamma\) también está fijo, así que \(V^\alpha = 0\)", pero ¿es realmente así?
🔵 Kai: Espera. Aunque \(\delta g^{\mu\nu} = 0\), \(\partial_\rho(\delta g^{\mu\nu})\) no necesariamente es cero en la frontera, ¿no? Como \(\Gamma\) contiene derivadas de \(g\)…
🟡 Lina: ¡Agudo! Exactamente. Estrictamente, \(\delta g^{\mu\nu}|_{\partial\mathcal{M}} = 0\) por sí solo no garantiza \(\delta\Gamma|_{\partial\mathcal{M}} = 0\). La derivada normal de \(g\), \(\partial_n g\), no está fija.
Para resolver completamente este problema se añade el término de frontera de Gibbons-Hawking-York:
a la acción. Aquí \(h\) es el determinante de la métrica 3-dimensional inducida en la frontera, y \(K\) es la traza de la curvatura extrínseca de la frontera (omitimos la definición formal). La curvatura extrínseca representa en qué dirección y cuánto se curva la superficie frontera al estar embebida en el espaciotiempo circundante. Como ejemplo cotidiano, la superficie de un globo se abulta hacia afuera, así que su curvatura extrínseca es positiva; el interior de una silla de montar se hunde, así que su curvatura extrínseca es negativa. Una hoja de papel plana tiene curvatura extrínseca cero. Su traza \(K\) resume en un solo número "cuánto se abulta la superficie frontera en conjunto". En este apéndice no entraremos en el cálculo concreto de \(K\), pero el punto clave es: al añadir este término, el problema variacional queda bien planteado con solo \(\delta g^{\mu\nu}|_{\partial\mathcal{M}} = 0\).
⚪ Mei: ¿Pero no afecta a las ecuaciones de movimiento finales (ecuaciones de Einstein)?
🟡 Lina: No. La variación del término GHY \(S_{GHY}\) está diseñada para cancelar exactamente el término de frontera que surge de la variación de \(S_{EH}\). Como resultado, en la variación de la acción total \(S_{EH} + S_{GHY} + S_M\) los términos de frontera se cancelan completamente, y solo queda el integrando de la integral de volumen. Por lo tanto, las ecuaciones de movimiento obtenidas de \(\delta S/\delta g^{\mu\nu} = 0\) son las mismas con o sin \(S_{GHY}\). En la termodinámica de agujeros negros (Cap. 10) y en la integral de camino de la gravedad cuántica, el valor del término de frontera en sí se vuelve importante, pero aquí concluimos que "el Término 2 se cancela" y avanzamos. El panorama completo de este proceso se resume en Fig. G.2「Identidad de Palatini y proceso de cancelación del término de frontera」.
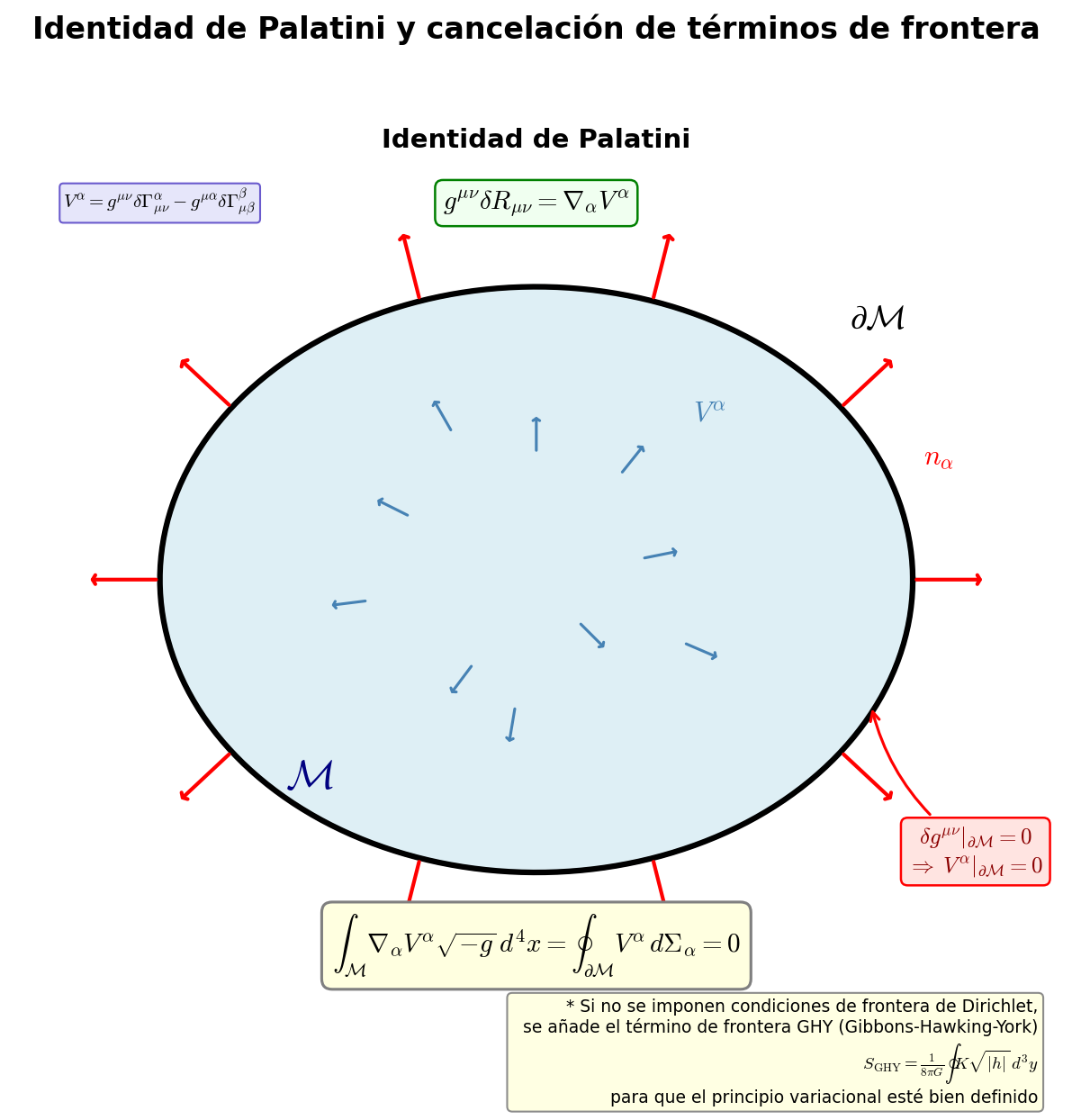
Fig. G.2: Identidad de Palatini y proceso de cancelación del término de frontera. \(g^{\mu\nu}\delta R_{\mu\nu} = \nabla_\alpha V^\alpha\) se convierte en integral de frontera por el teorema de la divergencia. Estrictamente se necesita añadir el término de frontera de Gibbons-Hawking-York, pero no afecta a las ecuaciones de movimiento
G.3.4 Combinación de las 3 contribuciones¶
🟡 Lina: Resumamos lo anterior. Los 3 términos de \(\delta(\sqrt{-g}\,R)\) son:
- Término 1: \(\sqrt{-g}\,R_{\mu\nu}\,\delta g^{\mu\nu}\)
- Término 2: \(0\) (se cancela como término de frontera)
- Término 3: \(-\frac{1}{2}\sqrt{-g}\,R\,g_{\mu\nu}\,\delta g^{\mu\nu}\)
Por lo tanto:
🔵 Kai: Gracias a que el Término 2 se cancela, queda \(R_{\mu\nu} - \frac{1}{2}g_{\mu\nu}R\) de forma elegante. ¡Ya se ve la forma del tensor de Einstein!
🟡 Lina: Exacto. Solo falta añadir la variación del término de constante cosmológica:
Combinando:
⚪ Mei: La variación de la parte gravitatoria está completa. Solo falta sumar la acción de la materia.
✅ Verificación de comprensión: Según la identidad de Palatini, ¿en qué forma se expresa \(\delta R_{\mu\nu}\)?
Respuesta
Se expresa como la diferencia de derivadas covariantes: \(\delta R_{\mu\nu} = \nabla_\alpha(\delta\Gamma^\alpha_{\mu\nu}) - \nabla_\nu(\delta\Gamma^\alpha_{\mu\alpha})\).
✅ Verificación de comprensión: ¿Cuál es la razón por la que el término \(g^{\mu\nu}\delta R_{\mu\nu}\) no contribuye al final?
Respuesta
Porque toma la forma de una derivada total (\(\nabla_\alpha V^\alpha\)), que por el teorema de la divergencia se convierte en un término de frontera, y se cancela si se impone \(\delta g^{\mu\nu} = 0\) en la frontera.
G.4 Acción de la materia y tensor de energía-momento¶
G.4.1 Definición variacional del tensor de energía-momento¶
🟡 Lina: Variamos la acción de los campos de materia \(S_M[g^{\mu\nu}, \phi]\) con respecto a la métrica. Aquí \(\phi\) es un símbolo que representa colectivamente los campos de materia (campo escalar, campo electromagnético, etc., todos los campos excepto la gravedad). Veremos un ejemplo concreto enseguida.
🟡 Lina: \(\frac{\delta S_M}{\delta g^{\mu\nu}}\) se llama derivada funcional. Así como la derivada ordinaria representa "la tasa de cambio de una función cuando la variable cambia un poco", la derivada funcional representa "la tasa de cambio de la acción (una cantidad integral) cuando el campo \(g^{\mu\nu}(x)\) cambia un poco en cada punto" (ver Relatividad General Relatividad General Apéndice C).
🔵 Kai: La derivada ordinaria es \(df/dx\), "la tasa de cambio de \(f\) cuando mueves un poco \(x\)". ¿Qué diferencia tiene la derivada funcional?
🟡 Lina: En la derivada ordinaria las variables son un número finito (\(x\), \(y\), \(z\), etc.). En la derivada funcional la "variable" es el campo \(g^{\mu\nu}(x)\)——es decir, tiene un valor en cada punto del espacio. Intuitivamente, si discretizas el espacio en puntos de una red y consideras \(g^{\mu\nu}\) en cada punto como una variable independiente, en la versión discreta puedes escribir \(\delta S \approx \sum_i \frac{\partial S}{\partial g^{\mu\nu}_i}\,\delta g^{\mu\nu}_i\). Al hacer la red infinitamente fina, la suma \(\sum_i\) se convierte en la integral \(\int d^4x\), y la derivada parcial \(\partial S/\partial g^{\mu\nu}_i\) se reemplaza por la derivada funcional \(\delta S_M/\delta g^{\mu\nu}(x)\).
⚪ Mei: Es decir, en la práctica basta con escribir la variación de \(S_M\) en forma de integral y leer el coeficiente de \(\delta g^{\mu\nu}\), ¿no?
🟡 Lina: Exactamente. La definición práctica es precisamente esa: si escribimos la variación de \(S_M\) como
entonces el coeficiente que multiplica a \(\delta g^{\mu\nu}\) en el integrando es \(\frac{\delta S_M}{\delta g^{\mu\nu}}\)——esa es la definición de derivada funcional. Nota sobre la notación: en el lado izquierdo, \(\delta S_M\) es "el cambio infinitesimal de la acción total"; en el derecho, \(\delta g^{\mu\nu}\) es "el cambio infinitesimal de la métrica", y \(\frac{\delta S_M}{\delta g^{\mu\nu}}\) es "la derivada funcional". Se usa la misma \(\delta\) pero se distingue por el contexto (la misma convención que cuando en la derivada ordinaria se escribe \(df = \frac{df}{dx}\,dx\), donde \(d\) se usa tanto para "diferencial total" como para "operador de diferenciación"). En el ejemplo del campo escalar de G.4.3 haremos el cálculo explícitamente, así que ahí confirmaremos el procedimiento concreto.
🔵 Kai: Un momento. En la derivada parcial ordinaria, \(\partial f/\partial x_i\) significa "mover solo \(x_i\) manteniendo el resto fijo". ¿La derivada funcional es igual, "mover \(g^{\mu\nu}\) solo en un punto \(x\) manteniendo los demás puntos fijos"?
🟡 Lina: Intuitivamente sí. La derivada funcional es el límite cuando los puntos de la red se hacen infinitamente finos, y se usa el símbolo \(\delta\) en vez de \(\partial\) para distinguirla. Sin embargo, en la práctica es más fácil calcular usando la definición que mencioné antes——escribir \(\delta S_M\) en forma integral y leer el coeficiente de \(\delta g^{\mu\nu}\)——en vez de pensar en "mover un solo punto". En el ejemplo del campo escalar de G.4.3 usaremos exactamente ese procedimiento, así que ahí captarás la intuición.
🔵 Kai: Entonces a ver si lo tengo——según esa definición, si escribo \(\delta S_M\) en forma integral y leo el coeficiente de \(\delta g^{\mu\nu}\), eso es \(\delta S_M/\delta g^{\mu\nu}\). ¿Es la misma estructura que en la derivada ordinaria donde el coeficiente en \(df = (\partial f/\partial x)\,dx\) es el coeficiente de diferenciación?
🟡 Lina: Comprensión perfecta. Exactamente así. Ahora un paso más——variar la acción de la materia "con respecto a la métrica", ¿qué significa físicamente según tú?
🔵 Kai: Mmm… "¿Cuánto se ve afectada la materia cuando cambias un poco la forma del espaciotiempo"? Pero espera, visto al revés, ¿no sería también un indicador de "cuánto quiere la materia curvar el espaciotiempo"? Como acción y reacción.
🟡 Lina: Ahí está precisamente el núcleo. Cuánto "resiste" la materia ante una deformación del espaciotiempo——lo que cuantifica la intensidad de esa respuesta es el tensor de energía-momento. Y eso se sienta en el lado derecho de la ecuación de Einstein como la fuente que determina la curvatura del espaciotiempo. Concretamente, definimos el tensor de energía-momento \(T_{\mu\nu}\) como:
Entonces:
🔵 Kai: ¿Por qué el coeficiente \(-2/\sqrt{-g}\)?
🟡 Lina: Hay dos razones. Primera, con este coeficiente en la definición, en el límite newtoniano \(T_{00}\) coincide exactamente con la densidad de energía \(\rho\)——esto lo verificaremos en 「G.5.3 Consistencia con el límite newtoniano」. Segunda, la ecuación de Einstein adopta la forma elegante \(G_{\mu\nu} = 8\pi G\,T_{\mu\nu}\). Además, con esta definición el \(T_{\mu\nu}\) obtenido es automáticamente un tensor simétrico (\(T_{\mu\nu} = T_{\nu\mu}\)). Esto difiere en general del tensor de energía-momento canónico obtenido del teorema de Noether en Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3, pero el físicamente correcto es este.
G.4.2 Ejemplo concreto: fluido perfecto¶
⚪ Mei: ¿Qué \(T_{\mu\nu}\) se obtiene concretamente?
🟡 Lina: Veamos dos ejemplos. Primero el fluido perfecto, donde solo muestro el resultado——la variación de la acción del fluido es técnicamente algo compleja. Después, con el campo escalar seguiremos el procedimiento de variación línea por línea. El tensor de energía-momento del fluido perfecto es:
donde \(\rho\) es la densidad de energía, \(p\) es la presión, y \(u^\mu\) es la cuadrivelocidad del fluido.
Para confirmar que esto se obtiene de la definición variacional, hay que variar la acción del fluido perfecto \(S_M = -\int d^4x\,\sqrt{-g}\,\rho\) con respecto a \(g^{\mu\nu}\) (los detalles están en los ejercicios de Relatividad General Relatividad General Apéndice C).
G.4.3 Ejemplo concreto: campo escalar¶
🟡 Lina: La acción del campo escalar \(\phi\) que estudiamos en Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3:
La variamos con respecto a \(g^{\mu\nu}\). Escribiendo el integrando como \(\mathcal{L}_M\sqrt{-g}\):
🔵 Kai: El \(\delta\sqrt{-g}\) que calculamos en G.3.1 vuelve a aparecer aquí.
🟡 Lina: Sí, las herramientas se reutilizan. Primer término: derivando \(\mathcal{L}_M = -\frac{1}{2}g^{\alpha\beta}\partial_\alpha\phi\,\partial_\beta\phi - V(\phi)\) con respecto a \(g^{\mu\nu}\):
Segundo término: usando \(\delta\sqrt{-g} = -\frac{1}{2}\sqrt{-g}\,g_{\mu\nu}\,\delta g^{\mu\nu}\):
Combinando:
Sustituyendo en la definición \(T_{\mu\nu} = -\frac{2}{\sqrt{-g}}\frac{\delta S_M}{\delta g^{\mu\nu}}\):
🔵 Kai: ¡Es la misma forma que el tensor de energía-momento del campo escalar que vimos en Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3!
🟡 Lina: Sí. Aunque en espaciotiempo curvo \(\eta_{\mu\nu} \to g_{\mu\nu}\).
⚪ Mei: El procedimiento de la definición variacional——"escribir \(\delta S_M\) y leer el coeficiente de \(\delta g^{\mu\nu}\)"——da el resultado de forma tan directa.
✅ Verificación de comprensión: ¿Cómo se define el tensor de energía-momento \(T_{\mu\nu}\) usando la acción de la materia \(S_M\)?
Respuesta
Se define como \(T_{\mu\nu} \equiv -\frac{2}{\sqrt{-g}}\frac{\delta S_M}{\delta g^{\mu\nu}}\).
G.5 Completando las ecuaciones de Einstein¶
G.5.1 Derivación desde el principio variacional¶
🟡 Lina: Igualamos a cero la variación de la acción total \(S = S_{\text{grav}} + S_M\):
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart LR
S["Acción total S = S_grav + S_M"] --> SG["S_grav = 1/(16πG) ∫√-g (R-2Λ) d⁴x"]
S --> SM["S_M[g, φ]"]
SG -->|δ/δg^μν| LHS["(R_μν - ½g_μν R + Λg_μν) / (16πG)"]
SM -->|δ/δg^μν| RHS["-½ T_μν"]
LHS --> EQ["δS = 0"]
RHS --> EQ
EQ --> EINSTEIN["G_μν + Λg_μν = 8πG T_μν"]Fig. G.3: Derivación de las ecuaciones de Einstein a partir de la variación de la acción total
Como \(\delta g^{\mu\nu}\) es arbitrario, el integrando debe ser cero:
Multiplicando por \(16\pi G\) y reorganizando:
Esta es la ecuación de Einstein con término de constante cosmológica. Usando el tensor de Einstein \(G_{\mu\nu} \equiv R_{\mu\nu} - \frac{1}{2}g_{\mu\nu}R\):
🔵 Kai: ¡Por fin salió! Lo que calculamos en G.3 separándolo en 3 partes confluye todo aquí para dar limpiamente la ecuación de Einstein.
⚪ Mei: Es la misma forma que vimos en Cap. 6. En aquel momento la aceptamos axiomáticamente, pero ahora la misma ecuación sale simplemente determinando la acción a partir de 4 requisitos y variando——es impresionante que no hubo ningún punto donde se eligiera algo arbitrariamente.
G.5.2 Identidad de Bianchi y conservación de la energía¶
🟡 Lina: Como verificación de consistencia de la derivación, confirmemos la identidad de Bianchi. Como identidad de la geometría diferencial (ver Relatividad General Relatividad General Cap. 13):
Esto se cumple de forma puramente geométrica por las simetrías del tensor de Riemann. Combinando con \(\nabla^\mu(\Lambda g_{\mu\nu}) = 0\) (porque \(\nabla^\mu g_{\mu\nu} = 0\)):
La misma condición se impone al lado derecho de la ecuación de Einstein:
🔵 Kai: \(\nabla^\mu T_{\mu\nu} = 0\) es la generalización de \(\partial^\mu T_{\mu\nu} = 0\) (conservación de energía-momento) en espaciotiempo plano, ¿verdad? Pero en espaciotiempo curvo el significado de "conservación" debe cambiar…
🟡 Lina: Buena intuición. En espaciotiempo curvo, \(\nabla^\mu T_{\mu\nu} = 0\) corresponde a una ley de conservación local. En espaciotiempo plano se reduce a \(\nabla^\mu \to \partial^\mu\) y se recupera la conservación usual de energía-momento \(\partial^\mu T_{\mu\nu} = 0\). Sin embargo, en espaciotiempo curvo definir "la cantidad total de energía del universo" es en general difícil——surge el problema de cómo contabilizar la energía del propio campo gravitatorio (ver Relatividad General Relatividad General Cap. 15). Aquí no profundizaremos, pero tenlo en mente.
Lo importante es que esta ley de conservación surge automáticamente como consecuencia de las ecuaciones de Einstein. La invariancia de la acción bajo transformaciones generales de coordenadas (\(S\) invariante bajo cambios de coordenadas) garantiza \(\nabla^\mu T_{\mu\nu} = 0\) por el teorema de Noether (ver Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3).
⚪ Mei: Es decir, no necesitamos postular la ley de conservación por separado; sale automáticamente de la simetría.
🟡 Lina: Exacto. Ahora quiero que notes que la identidad de Bianchi \(\nabla^\mu G_{\mu\nu} = 0\) proporciona 4 identidades para \(\nu = 0, 1, 2, 3\). La ecuación de Einstein tiene 10 componentes por la simetría de \(g_{\mu\nu}\), pero——
🔵 Kai: Espera. Si 4 identidades se cumplen siempre, eso significa que… ¿4 de las 10 componentes no son independientes?
🟡 Lina: Exactamente. De las 10 componentes de la ecuación menos las 4 identidades de Bianchi, quedan 6 ecuaciones independientes. Esto coincide con los 6 grados de libertad que resultan de restar los 4 grados de libertad de coordenadas a las 10 componentes de la métrica \(g_{\mu\nu}\).
🔵 Kai: ¿Hmm? ¿Qué es "restar los grados de libertad de coordenadas"? Antes hubo algo parecido cuando de las 4 componentes de \(A_\mu\) se restaban los grados de gauge y se reducían los grados de libertad físicos (Teoría Cuántica de Campos Teoría Cuántica de Campos Cap. 3). ¿Es similar?
🟡 Lina: Exactamente. En electromagnetismo hay 1 grado de libertad de gauge \(A_\mu \to A_\mu + \partial_\mu\chi\), y de las 4 componentes se resta 1 dando 3 grados de libertad——además, por las restricciones de las ecuaciones de movimiento, físicamente son 2 grados de libertad (ondas transversales). Las ecuaciones de Maxwell tienen 1 identidad correspondiente (\(\partial_\mu J^\mu = 0\)). En gravedad hay 4 grados de libertad de transformación de coordenadas que dan 4 identidades de Bianchi. La estructura es exactamente la misma. Es decir, ambos tienen la estructura de tres etapas "simetría de la acción → ley de conservación → consistencia de las ecuaciones". En electromagnetismo: invariancia de gauge → conservación de la carga → consistencia de las ecuaciones de Maxwell. En gravedad: invariancia de coordenadas → conservación de energía-momento → consistencia de las ecuaciones de Einstein.
🔵 Kai: Entonces cuanto mayor es la simetría, más identidades hay y menos ecuaciones independientes quedan. En electromagnetismo 1 identidad y \(4-1=3\), en gravedad 4 identidades y \(10-4=6\)——¡el mismo patrón!
🟡 Lina: Exacto. La simetría "acota" la teoría. Resumiendo cuantitativamente——en electromagnetismo: "invariancia de gauge \(U(1)\) (1 parámetro) → conservación de la carga (1 identidad) → de 4 componentes, 3 ecuaciones independientes". En gravedad: "invariancia general de coordenadas (4 parámetros) → conservación de energía-momento (4 identidades) → de 10 componentes, 6 ecuaciones independientes".
⚪ Mei: Organizándolo: electromagnetismo es "1 parámetro de simetría → 1 identidad → ecuaciones independientes \(4-1=3\)", gravedad es "4 parámetros de simetría → 4 identidades → ecuaciones independientes \(10-4=6\)". El número de parámetros de la simetría se convierte directamente en el número de identidades.
🟡 Lina: Esa relación se resume en el diagrama Fig. G.4「Consistencia entre la invariancia de coordenadas y la identidad de Bianchi」.
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart TD
A["Invariancia bajo coordenadas generales de la acción S"] -->|Teorema de Noether| B["∇^μ T_μν = 0<br>(Conservación de energía-momento)"]
A -->|Identidad de geometría diferencial| C["∇^μ G_μν = 0<br>(Identidad de Bianchi)"]
C -->|Lado izquierdo de la ec. de Einstein| D["G_μν + Λg_μν = 8πG T_μν"]
B -->|Lado derecho de la ec. de Einstein| D
D --> E["Se garantiza la consistencia de las ecuaciones"]Fig. G.4: Consistencia entre la invariancia de coordenadas y la identidad de Bianchi
🟡 Lina: Así es. Este es el poder del principio de acción.
G.5.3 Consistencia con el límite newtoniano¶
🟡 Lina: Confirmemos que el coeficiente \(8\pi G\) es correcto. En campo gravitatorio débil:
Consideramos materia estática y no relativista (\(T^{00} \approx \rho\), las demás componentes son aproximadamente cero, \(c = 1\)). Bajando los índices, \(T_{00} = g_{0\alpha}g_{0\beta}T^{\alpha\beta}\). En la aproximación de campo débil \(g_{0i} \approx 0\) y \(T^{0i} \approx 0\), \(T^{ij} \approx 0\), así que el único término que sobrevive en la suma es \(\alpha = 0\), \(\beta = 0\): \(T_{00} \approx g_{00}g_{00}T^{00} \approx (-1)(-1)\rho = \rho\).
🔵 Kai: ¿\(T^{0i} \approx 0\), por qué? Si la densidad de energía no es cero, ¿la densidad de momento es cero?
🟡 Lina: "No relativista" significa que la materia está prácticamente en reposo. \(T^{0i}\) es la densidad de momento——es decir, corresponde a la velocidad del flujo de materia. Si la materia no se mueve, la densidad de momento es cero. En el límite estático y no relativista la presión también es cero, así que \(T_{00} \approx \rho\) y las demás componentes son despreciables.
⚪ Mei: Consideramos "materia prácticamente en reposo" y verificamos si se reproduce el límite newtoniano.
🟡 Lina: Exacto. Usar directamente la componente \(00\) de la ecuación de Einstein da \(R_{00} - \frac{1}{2}g_{00}R = 8\pi G\,\rho\), pero es más claro tomar primero la traza para eliminar \(R\).
Paso 1: Tomar la traza
Multiplicamos ambos lados de la ecuación de Einstein \(G_{\mu\nu} = 8\pi G\,T_{\mu\nu}\) por \(g^{\mu\nu}\). El lado izquierdo es \(g^{\mu\nu}G_{\mu\nu} = g^{\mu\nu}R_{\mu\nu} - \frac{1}{2}g^{\mu\nu}g_{\mu\nu}R = R - \frac{1}{2}\cdot 4 \cdot R = R - 2R = -R\). El lado derecho es \(8\pi G\,g^{\mu\nu}T_{\mu\nu} = 8\pi G\,T\) (\(T \equiv g^{\mu\nu}T_{\mu\nu}\) es la traza del tensor de energía-momento). Por lo tanto:
🔵 Kai: \(g^{\mu\nu}g_{\mu\nu} = 4\), ¿porque estamos en 4 dimensiones?
🟡 Lina: Sí. \(g^{\mu\nu}g_{\mu\nu} = \delta^\mu_\mu = 4\) (en \(D\) dimensiones sería \(D\)).
Paso 2: Forma con traza invertida
Sustituyendo esto en la ecuación original \(R_{\mu\nu} - \frac{1}{2}g_{\mu\nu}R = 8\pi G\,T_{\mu\nu}\) para eliminar \(R\):
Esta forma se llama forma con traza invertida (trace-reversed form).
Paso 3: Tomar la componente \(00\)
Para materia estática y no relativista, \(T_{00} \approx \rho\). En la fórmula del fluido perfecto con \(p = 0\), \(T_{ij} = \rho\,u_i u_j\), pero en el límite no relativista \(u_i \approx 0\) (el mismo argumento de antes), así que \(T_{ij} \approx 0\). Además, no relativista significa \(u^i \approx 0\) (materia prácticamente en reposo). Sustituyendo la condición de normalización de la cuadrivelocidad \(g_{\mu\nu}u^\mu u^\nu = -1\) con la aproximación de campo débil \(g_{00} \approx -1\), \(u^i \approx 0\), se obtiene \(-u^0 u^0 \approx -1\), luego \(u^0 \approx 1\). Usando la fórmula de G.4.2 \(T_{0i} = (\rho + p)u_0 u_i + p\,g_{0i}\). Con \(p = 0\) el segundo término desaparece. El primer término contiene \(u_i\), pero bajando el índice \(u_i = g_{i\mu}u^\mu = g_{i0}u^0 + g_{ij}u^j\). En la aproximación de campo débil \(g_{i0} \approx 0\) y en el límite no relativista \(u^j \approx 0\), así que aunque \(u^0 \approx 1\), tenemos \(u_i \approx 0\). Por lo tanto \(T_{0i} \approx 0\). En la aproximación de campo débil \(g^{\mu\nu} \approx \eta^{\mu\nu}\), así que con la convención de signos \((-,+,+,+)\): \(g^{00} \approx \eta^{00} = -1\), \(g^{0i} \approx \eta^{0i} = 0\), \(g^{ij} \approx \eta^{ij} = \delta^{ij}\). Por tanto la traza es \(T = g^{\mu\nu}T_{\mu\nu}\). Por la regla de contracción con \(\mu, \nu\) recorriendo de 0 a 3: \(T = \sum_{\mu=0}^{3}\sum_{\nu=0}^{3} g^{\mu\nu}T_{\mu\nu}\). Separando por casos según los valores de \(\mu, \nu\): \(T = g^{00}T_{00} + g^{0i}T_{0i} + g^{i0}T_{i0} + g^{ij}T_{ij}\) (\(i\) recorre 1, 2, 3). Por la simetría \(g^{0i} = g^{i0}\), \(T_{0i} = T_{i0}\), los términos 2 y 3 tienen el mismo valor: \(T = g^{00}T_{00} + 2g^{0i}T_{0i} + g^{ij}T_{ij}\). En la aproximación de campo débil \(g^{00} \approx -1\), \(g^{0i} \approx 0\), \(g^{ij} \approx \delta^{ij}\), y \(T_{00} \approx \rho\), \(T_{0i} \approx 0\), \(T_{ij} \approx 0\):
🔵 Kai: Que la traza sea \(-\rho\) se debe al signo de \(g^{00} = -1\).
🟡 Lina: Exacto. \(g_{00} \approx -1\) (en la aproximación de campo débil \(|\Phi| \ll 1\): \(-(1+2\Phi) \approx -1\)), así que la componente \(00\) del lado derecho de la forma con traza invertida es \(8\pi G(T_{00} - \frac{1}{2}g_{00}T)\). Sustituyendo \(T_{00} \approx \rho\), \(g_{00} \approx -1\), \(T \approx -\rho\):
Paso 4: Escribir el lado izquierdo \(R_{00}\) en términos del potencial newtoniano
En la aproximación lineal \(R_{00} \approx -\frac{1}{2}\nabla^2 h_{00}\) (ver Relatividad General Relatividad General Cap. 8). En la aproximación de campo débil \(g_{00} \approx -(1+2\Phi)\) (\(\Phi\) es el potencial newtoniano, \(|\Phi| \ll 1\)), así que:
Sustituyendo:
Paso 5: Ecuación de Poisson
Igualando los Pasos 3 y 4:
🔵 Kai: ¡Es la ecuación de Poisson de Newton! ¡La ecuación de Einstein se reduce a la gravedad newtoniana!
🟡 Lina: Es exactamente la ecuación de Poisson de Newton. La coincidencia de los coeficientes fija el valor \(8\pi G\).
📝 Ejercicios:
- Verificación del límite newtoniano → Problema M-2. Límite newtoniano de Einstein-Hilbert
✅ Verificación de comprensión: Escribe la ecuación de Einstein (con constante cosmológica) obtenida de la derivación.
Respuesta
\(R_{\mu\nu} - \frac{1}{2}g_{\mu\nu}R + \Lambda g_{\mu\nu} = 8\pi G\,T_{\mu\nu}\) (en unidades naturales \(c=1\)).
✅ Verificación de comprensión: ¿De qué condición se determina el coeficiente \(8\pi G\) del lado derecho de la ecuación de Einstein?
Respuesta
Se determina de la condición de que en el límite de campo gravitatorio débil se recupere la ecuación de Poisson de Newton \(\nabla^2\Phi = 4\pi G\rho\).
G.6 Significado de la derivación y perspectivas hacia la teoría de cuerdas¶
G.6.1 El poder del principio de acción¶
🟡 Lina: Resumamos lo que demuestra esta derivación.
- La ecuación de Einstein no "cayó del cielo" — Surge necesariamente de la variación de la acción más simple invariante bajo coordenadas generales \(\int\sqrt{-g}\,R\,d^4x\)
- La simetría determina la ecuación — Con solo los requisitos "invariancia bajo coordenadas generales", "construida solo con la métrica y sus derivadas", "hasta derivadas de segundo orden" y "máxima simplicidad", la forma de la acción queda casi unívocamente determinada (salvo la libertad de la constante cosmológica)
- Las leyes de conservación se garantizan automáticamente — Simetría de la acción → identidad de Bianchi → \(\nabla^\mu T_{\mu\nu} = 0\)
- Punto de partida para la cuantización — La integral de camino \(\int\mathcal{D}[g]\,e^{iS_{EH}/\hbar}\) es (a pesar del problema de divergencias ultravioletas) el punto de partida formal de la gravedad cuántica
🔵 Kai: El punto 2 es impresionante. "Si determinas la simetría, determinas la ecuación"——visto al revés, si te equivocas en la simetría, todo sale mal.
🟡 Lina: Exacto. Por eso "encontrar la simetría correcta" es el paso más importante en la construcción de una teoría. Históricamente, Maxwell organizó el electromagnetismo con la simetría de gauge, Einstein postuló la invariancia general de coordenadas, Yang-Mills introdujo la simetría de gauge no abeliana——en todos los casos, el descubrimiento de la simetría fue el avance decisivo. Y cuanto mayor es la simetría, más se reducen los grados de libertad de la teoría y más se acotan las ecuaciones——si la simetría es insuficiente, hay demasiados candidatos y no se puede determinar unívocamente.
⚪ Mei: Es decir, si los 4 requisitos determinaron la acción casi unívocamente, fue porque las restricciones impuestas por la simetría eran muy fuertes.
🟡 Lina: Exactamente. Concretamente, la invariancia general de coordenadas es una simetría mucho mayor que la invariancia de Lorentz, por lo que restringe fuertemente las formas de acción permitidas. Por ejemplo, si intentas describir la gravedad solo con invariancia de Lorentz, la simetría es insuficiente y no se obtiene una teoría consistente. La identidad de Bianchi que vimos en G.5.2 es también un ejemplo concreto de este "acotamiento"——la simetría genera 4 identidades que reducen las ecuaciones independientes de 10 a 6.
G.6.2 Conexión con la teoría de cuerdas {#string-appendix-g-connection-to-string-theory}}¶
🔵 Kai: ¿Y en la teoría de cuerdas qué pasa?
🟡 Lina: La acción de Polyakov que veremos en Cap. 13:
es la acción de campos escalares \(X^\mu\) en la hoja de mundo bidimensional, donde la métrica de la hoja de mundo \(h_{ab}\) entra como variable dinámica independiente. Lo que comparte con la acción de Einstein-Hilbert es la estructura de "variar una acción que contiene la métrica con respecto a la métrica". \(h_{ab}\) es la métrica de la hoja de mundo, \(X^\mu\) son las coordenadas de embebimiento (funciones que indican en qué punto del espaciotiempo se encuentra cada punto de la cuerda; se introducen con detalle en Cap. 13).
🔵 Kai: Variar con respecto a \(g^{\mu\nu}\) en G.4 para obtener \(T_{\mu\nu}\) y variar con respecto a \(h^{ab}\) tiene exactamente el mismo espíritu.
🟡 Lina: Exacto.
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart TD
subgraph GR["Relatividad general (espaciotiempo 4D)"]
A1["Variable dinámica: g_μν"] --> A2["Acción: S_EH = ∫d⁴x √-g R"]
A2 -->|δ/δg^μν = 0| A3["Ecuaciones de Einstein"]
end
subgraph ST["Teoría de cuerdas (hoja de mundo 2D)"]
B1["Variables dinámicas: h_ab, X^μ"] --> B2["Acción: S_P = -T/2 ∫d²σ √-h h^ab ∂_a X^μ ∂_b X_μ"]
B2 -->|δ/δh^ab = 0| B3["Condición de vínculo T_ab = 0"]
B2 -->|δ/δX^μ = 0| B4["Ecuación de onda"]
end
GR -.->|"Mismo espíritu variacional<br>Dimensión: 4→2"| STFig. G.5: Similitud estructural entre la acción gravitatoria y la acción de cuerdas
El espíritu de la variación es exactamente el mismo: - Variar con respecto a \(h^{ab}\) → tensor de energía-momento sobre la hoja de mundo \(= 0\) (condición de vínculo) - Variar con respecto a \(X^\mu\) → ecuación de movimiento de la cuerda (ecuación de onda)
🔵 Kai: Ah, variar con respecto a la métrica de la hoja de mundo \(h_{ab}\) corresponde a variar con respecto a \(g_{\mu\nu}\) en la ecuación de Einstein (Fig. G.5「Similitud estructural entre la acción gravitatoria y la acción de cuerdas」).
⚪ Mei: Solo cambia la dimensión de 4 a 2, pero lo que se hace es lo mismo.
🟡 Lina: Así es. Además, de la acción efectiva de baja energía de la teoría de cuerdas emergen las ecuaciones de Einstein en dimensiones superiores (+ correcciones de orden superior). Es decir, la teoría de cuerdas "contiene" la gravedad de Einstein. Esta es una de las razones por las que la teoría de cuerdas es candidata a una teoría de gravedad cuántica.
G.6.3 Nota de filosofía de la ciencia¶
🟡 Lina: Para terminar, un punto importante. Esta derivación es hermosa, pero hay algo que no debemos olvidar.
Las ecuaciones de Einstein son un modelo. Elegir "la acción más simple" es un juicio estético humano, y no hay garantía de que la naturaleza lo obedezca. De hecho:
- A altas energías podrían ser importantes términos como \(R^2\) o \(R_{\mu\nu}R^{\mu\nu}\) (modelos de gravedad de orden superior)
- Los efectos cuánticos podrían modificar la acción misma
- La teoría de cuerdas predice infinitas correcciones de orden superior en la expansión en \(\alpha'\) (inverso de la tensión de la cuerda)
🔵 Kai: Es decir, la ecuación de Einstein no es "correcta", sino que es "el modelo más simple que hasta ahora concuerda con los experimentos", ¿no?
🟡 Lina: Exacto. Elegir la forma de la acción como "la más simple" se justifica porque es correcta dentro del rango verificable con la precisión experimental actual. Pero eso no es una verdad eterna, y siempre existe la posibilidad de que experimentos más precisos requieran modificaciones.
🔵 Kai: Si en el futuro una observación más precisa descubriera un término \(R^2\), ¿bastaría con reescribir la acción?
🟡 Lina: Exactamente. Se mantiene el marco del principio de acción y se modifica el contenido de la acción. Esta es otra ventaja del principio de acción — permite extender la teoría de forma sistemática. Es decir, el procedimiento variacional no cambia, solo se reemplaza el contenido. Dicho de otro modo, el principio de acción proporciona "la forma de plantear la pregunta", no "la respuesta"; el contenido se determina experimentalmente. Lo que en filosofía de la ciencia se llama "falsabilidad", es decir, que siempre existe la posibilidad de ser refutado por un experimento, es la fortaleza de la física. No olvides la actitud de juzgar por ti mismo.
⚪ Mei: Ya veo, se fija el marco y se reemplaza el contenido——por eso aunque añadas un término \(R^2\), lo que haces es lo mismo: "variar e igualar a cero".
📝 Ejercicios:
- Variación al añadir el término de constante cosmológica → Problema M-3. Variación del término de constante cosmológica
✅ Verificación de comprensión: ¿Por qué se elige \(R\) (curvatura escalar) como acción?
Respuesta
Porque \(R\) es el escalar más simple invariante bajo transformaciones generales de coordenadas que contiene derivadas de segundo orden del tensor métrico. Sin embargo, esta es una elección basada en el juicio estético de "máxima simplicidad" y podría requerir modificaciones a altas energías.
G.7 Problemas de práctica¶
A continuación se recopilan los ejercicios que aparecieron en este apéndice.
📝 Ejercicios:
- Derivación de \(\delta\sqrt{-g}\) → Problema M-1. Derivación de \(\delta\sqrt{-g}\)
- Verificación del límite newtoniano → Problema M-2. Límite newtoniano de Einstein-Hilbert
- Variación al añadir el término de constante cosmológica → Problema M-3. Variación del término de constante cosmológica
Adelanto del siguiente capítulo¶
En este apéndice completamos la derivación variacional de las ecuaciones de Einstein. En Cap. 13 aplicaremos el mismo espíritu del principio variacional a la cuerda, derivando la ecuación de movimiento y las condiciones de vínculo a partir de la acción de Polyakov.
Referencias¶
- Sean Carroll, Spacetime and Geometry, Cap. 4 "Derivación de las ecuaciones de Einstein" — Discusión detallada de la identidad de Palatini y los términos de frontera
- David Tong, Lectures on General Relativity, Cap. 4: "The Einstein Equations" — Exposición clara del cálculo variacional
- Robert Wald, General Relativity, Cap. E "Principio variacional" — Tratamiento riguroso del término de frontera de Gibbons-Hawking-York
- Barton Zwiebach, A First Course in String Theory, Cap. 12: "Relativistic quantum open strings" — Analogía entre la acción de cuerdas y la variación
- Relatividad General Capítulo 14 — Derivación de las ecuaciones de Einstein (versión detallada del mismo contenido. Lectores que ya lo hayan leído pueden omitir este apéndice)
- Relatividad General Appendix C — Cálculo variacional y principio de mínima acción
- Teoría Cuántica de Campos Capítulo 3 — Teoría clásica de campos, lagrangiano y teorema de Noether
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.