Apéndice B Producto tensorial, componentes y notación de contracción: resumen¶
Resumen de los capítulos anteriores:
En Apéndice A organizamos, con demostraciones, el análisis vectorial en el espacio euclídeo tridimensional —producto vectorial, operadores diferenciales (grad, div, rot, laplaciano) y teoremas integrales (teorema de Gauss, teorema de Stokes)—. Preparamos estas herramientas como un "diccionario" utilizable como base para los cálculos tensoriales del texto principal.
Objetivo de este capítulo
- Comprender la definición del producto tensorial \(\otimes\) y sus reglas de cálculo (distributividad, no conmutatividad), y captar la estructura del espacio de tensores contravariantes \(T^r(V)\)
- Además, adquirir la perspectiva independiente de coordenadas que concibe los tensores como "aplicaciones multilineales", y comprender la relación con los tensores covariantes (como el tensor métrico). Dominar la notación de contracción de Einstein
- Estas son herramientas indispensables para manejar las cantidades con múltiples índices que aparecen en el texto principal, como el tensor métrico y el tensor de Riemann
B.1 ¿Por qué es necesario el producto tensorial?¶
🟡 Lina: Hasta ahora hemos aprendido sobre vectores y 1-formas. Los vectores son "cantidades con un índice superior" y las 1-formas son "cantidades con un índice inferior". Sin embargo, en las ecuaciones de Einstein
aparecen cantidades con dos índices inferiores. El tensor de Riemann \(R^\rho{}_{\sigma\mu\nu}\) llega a tener 4 índices.
🔵 Kai: Que aumenten los índices significa que solo con vectores no basta, ¿verdad?
🟡 Lina: Así es. Los vectores son tensores de "rango 1" —cantidades con un solo índice. Para manejar sistemáticamente cantidades con 2 o más índices, necesitamos una operación que construya espacios más grandes a partir de un espacio vectorial. Eso es el producto tensorial (tensor product) \(\otimes\). Es decir, el producto tensorial es la herramienta matemática para "aumentar los índices". Hoy vamos a dominar bien las reglas de cálculo del producto tensorial.
⚪ Mei: Ya veo, como con vectores solo podemos manejar un índice, necesitamos una operación para crear cantidades con más índices.
B.2 Construcción del espacio producto tensorial¶
🟡 Lina: Consideremos un espacio lineal \(V\) de dimensión 2, con base \(e_1, e_2\). Queremos construir el producto tensorial \(V \otimes V\) de \(V\) consigo mismo. El procedimiento es simple. Combinamos \(e_1, e_2\) de dos en dos para crear
estos 4 símbolos. El espacio lineal que se forma tomando estos 4 como base con coeficientes reales es \(V \otimes V\).
🔵 Kai: ¿Con 4 vectores base, es un espacio lineal de dimensión 4?
🟡 Lina: Así es. Si \(V\) tiene dimensión 2, entonces \(V \otimes V\) tiene dimensión \(2 \times 2 = 4\). Si \(V\) tiene dimensión \(n\), entonces \(V \otimes V\) tiene dimensión \(n^2\).
✅ Verificación de comprensión: ¿Cuál es la dimensión del espacio producto tensorial \(V \otimes V\) de un espacio vectorial \(V\) de dimensión \(n\)? ¿Qué forma tienen sus vectores base?
Respuesta
La dimensión de \(V \otimes V\) es \(n^2\). La base consta de \(n^2\) elementos de la forma \(e_i \otimes e_j\) (\(i, j = 1, \ldots, n\)). Son combinaciones de dos vectores base de \(V\) conectados mediante \(\otimes\).
⚪ Mei: \(e_1 \otimes e_2\)... ¿qué tipo de objeto es concretamente?
🟡 Lina: Siendo honesta, no necesitas preocuparte por su naturaleza. Basta con entenderlo como "algo que se obtiene al colocar \(e_1\) y \(e_2\) en orden y pegarlos". Lo importante no es la identidad del objeto, sino las reglas de cálculo que explicaré a continuación.
B.3 Reglas de cálculo del producto tensorial¶
🟡 Lina: Definimos que el producto tensorial \(\otimes\) satisface las siguientes 3 leyes. Para un escalar \(k\) y vectores \(S, T, U\):
🔵 Kai: La primera dice que "multiplicar por un escalar da lo mismo en cualquier posición", y la segunda y tercera son la propiedad distributiva. ¡Es igual que las fórmulas de expansión de la secundaria!
🟡 Lina: Exactamente. Hagamos un ejemplo concreto. Si \(S = 2e_1 + 3e_2\) y \(T = -2e_1 + e_2\), calcula \(S \otimes T\).
🔵 Kai: A ver, ¿lo expando como si fuera \((a + b)(c + d)\)? \(2e_1 \otimes (-2e_1)\) y \(2e_1 \otimes e_2\) y... ¿salen 4 términos?
🟡 Lina: Sí, así es. Escribe los 4 términos completos.
🔵 Kai: Entonces...
¿Así?
🟡 Lina: Perfecto. Esa es la idea.
⚪ Mei: Tiene exactamente la misma estructura que \((a + b)(c + d) = ac + ad + bc + bd\). El procedimiento de expansión es el mismo que la multiplicación ordinaria, pero...
🔵 Kai: Ah, pero \(e_1 \otimes e_2\) y \(e_2 \otimes e_1\) son cosas distintas, ¿verdad? ¿No se cumple \(ab = ba\) como en la multiplicación de números normales?
🟡 Lina: Buena pregunta. Así es, el producto tensorial en general no satisface la ley conmutativa. \(e_1 \otimes e_2 \neq e_2 \otimes e_1\). Que "el orden importa" es una característica fundamental del producto tensorial. Por eso, al agrupar "términos semejantes" después de la expansión, hay que tratar \(e_1 \otimes e_2\) y \(e_2 \otimes e_1\) como objetos distintos.
⚪ Mei: Es decir, en la multiplicación de números normales se puede hacer \(ab = ba\) y agrupar términos semejantes, pero en el producto tensorial, si el orden es diferente son bases distintas, así que no se pueden mezclar.
📝 Ejercicios:
- Expansión del producto tensorial → Problema B-1. Producto tensorial \(S \otimes T\) básico, verificación de la no conmutatividad → Problema B-2. No conmutatividad del producto tensorial
B.4 Suma y multiplicación por escalar de elementos del espacio producto tensorial¶
🟡 Lina: La suma entre elementos de \(V \otimes V\) y la multiplicación por escalar siguen exactamente las mismas reglas que para vectores ordinarios. Solo que la base tiene la forma poco familiar \(e_i \otimes e_j\), pero lo que se hace no cambia. Por ejemplo, calcula esto:
🔵 Kai: Veamos, el coeficiente de \(e_1 \otimes e_1\) es \(-3 + 2 = -1\), el coeficiente de \(e_2 \otimes e_1\) es \(-2 + (-1) = -3\), así que...
¿Así? Solo hay que sumar los coeficientes de la misma base, tiene exactamente la misma estructura que la suma de vectores ordinarios.
🟡 Lina: La multiplicación por escalar sigue la misma lógica. Por ejemplo:
simplemente se multiplica cada coeficiente por 3.
⚪ Mei: Tanto la suma como la multiplicación por escalar solo operan sobre los coeficientes de la misma base. Exactamente las mismas reglas que un espacio vectorial ordinario.
🔵 Kai: Pero \(e_1 \otimes e_2\) y \(e_2 \otimes e_1\) son bases diferentes, así que no se pueden sumar sus coeficientes, ¿verdad?
🟡 Lina: Correcto. Que si el orden es diferente son objetos distintos, ese es el punto importante del producto tensorial. Por cierto, esto también tiene significado físico —por ejemplo, en el tensor de esfuerzos, "la fuerza en dirección \(y\) sobre la cara en dirección \(x\)" y "la fuerza en dirección \(x\) sobre la cara en dirección \(y\)" representan situaciones generalmente distintas.
🔵 Kai: "La cara en dirección \(x\)" es la cara perpendicular al eje \(x\), ¿verdad? Y ahí actúa una fuerza en dirección \(y\)... ¿como un esfuerzo de cizalladura?
🟡 Lina: Sí, exactamente un esfuerzo de cizalladura. La combinación de la orientación de la cara y la dirección de la fuerza corresponde a los dos índices. Por eso el orden tiene significado físico.
📝 Ejercicios:
- Suma y multiplicación por escalar en el espacio producto tensorial → Problema B-3. Combinaciones lineales de tensores
B.5 Tensores no descomponibles¶
🟡 Lina: Aquí hay una advertencia importante. No todos los elementos de \(V \otimes V\) pueden escribirse en la forma \(S \otimes T\) (\(S, T \in V\)).
⚪ Mei: ¿En serio?
🟡 Lina: Por ejemplo, consideremos \(e_1 \otimes e_1 + e_2 \otimes e_2\). Si pudiéramos escribirlo en la forma \(S \otimes T\), con \(S = \alpha e_1 + \beta e_2\), \(T = \gamma e_1 + \delta e_2\), tendríamos
Comparando los coeficientes de cada base:
🔵 Kai: De \(\alpha\delta = 0\) se deduce que \(\alpha = 0\) o \(\delta = 0\). Pero si \(\alpha = 0\) entonces \(\alpha\gamma = 0 \neq 1\), contradicción; si \(\delta = 0\) entonces \(\beta\delta = 0 \neq 1\), contradicción...
⚪ Mei: Es decir, no existe solución. \(e_1 \otimes e_1 + e_2 \otimes e_2\) no puede escribirse en la forma \(S \otimes T\).
🟡 Lina: Así es. A los elementos que sí pueden escribirse en la forma \(S \otimes T\) se les llama tensores descomponibles (decomposable tensors). Como el espacio producto tensorial también contiene sumas de tensores descomponibles, tiene una estructura mucho más rica que una simple "colección de pares".
✅ Verificación de comprensión: ¿Qué es un "tensor descomponible"? Además, ¿cómo se puede demostrar que no todos los elementos de \(V \otimes V\) son necesariamente tensores descomponibles?
Respuesta
Un tensor descomponible es un elemento de \(V \otimes V\) que puede escribirse en la forma \(S \otimes T\) (\(S, T \in V\)). Para demostrar que no todos los elementos son descomponibles, se puede considerar por ejemplo \(e_1 \otimes e_1 + e_2 \otimes e_2\), suponer \(S = \alpha e_1 + \beta e_2\), \(T = \gamma e_1 + \delta e_2\), y mostrar que la comparación de coeficientes lleva a un sistema de ecuaciones contradictorio.
📝 Ejercicios:
- Condición necesaria y suficiente para tensores descomponibles → Problema M-1. Condición para tensores descomponibles, ejemplo concreto de no descomponibilidad → Problema M-7. No descomponibilidad de un tensor antisimétrico
B.6 Representación en componentes y notación de contracción de Einstein¶
🟡 Lina: A partir de aquí viene algo muy importante para la práctica. Un elemento general \(S\) de \(V \otimes V\) se escribe como
\(S^{ij}\) son las componentes y \(e_i \otimes e_j\) es la base. Fíjate en que las componentes llevan índices superiores y la base lleva índices inferiores.
⚪ Mei: Como cada una de las 4 bases tiene un coeficiente, escribirlo todo se vuelve largo.
🟡 Lina: Así es. Usando \(\Sigma\) podemos resumirlo como
Y aquí, usando la notación de contracción de Einstein (Einstein summation convention), podemos omitir el \(\Sigma\) y escribir
🔵 Kai: La regla era "cuando el mismo índice aparece una vez arriba y una vez abajo, se suma sobre ese índice", ¿verdad? Lo aprendimos en Cap. 2.
🟡 Lina: Correcto. En la ecuación (B.4), \(i\) aparece una vez arriba en \(S^{ij}\) y una vez abajo en \(e_i\), y \(j\) aparece una vez arriba en \(S^{ij}\) y una vez abajo en \(e_j\), así que se suma sobre ambos, \(i\) y \(j\).
⚪ Mei: Concretamente, si \(S^{11} = 3, S^{12} = 4, S^{21} = 5, S^{22} = 6\) entonces
¿verdad?
🟡 Lina: Perfecto. Los "protagonistas" del tensor son las componentes \(S^{ij}\) y su correspondencia con valores numéricos. Una vez elegida la base, toda la información del tensor se concentra en las componentes.
Precaución sobre los índices mudos¶
🟡 Lina: Los índices sobre los que se suma en la notación de contracción se llaman índices mudos (dummy indices). El nombre de la letra que se use para un índice mudo no tiene significado. Por ejemplo:
Todos significan lo mismo.
🔵 Kai: Aunque cambies el nombre de la variable, el contenido del \(\sum\) es el mismo.
🟡 Lina: Así es. Sin embargo, un mismo índice no debe aparecer 3 o más veces en un mismo término. Eso viola la convención y además hace que el significado físico sea indefinido.
🟡 Lina: Otra precaución importante. Cuando se representan sumas diferentes, se deben usar índices mudos diferentes obligatoriamente. Por ejemplo, al usar dos vectores \(\vec{A} = A^\alpha e_\alpha\) y \(\vec{B} = B^\beta e_\beta\), si usamos la misma letra para \(\alpha\) y \(\beta\), el significado se destruye.
🔵 Kai: ¿Qué pasa si se usa la misma letra?
🟡 Lina: Te doy un ejemplo concreto. El producto escalar de dos vectores se puede escribir usando ciertos coeficientes \(g_{\alpha\beta}\) como \(\vec{A} \cdot \vec{B} = A^\alpha B^\beta g_{\alpha\beta}\). Aquí usamos letras griegas \(\alpha, \beta\) porque tenemos en mente los índices espacio-temporales (\(0, 1, 2, 3\)) del texto principal. \(g_{\alpha\beta}\) es la cantidad que se introduce formalmente como "tensor métrico" en el texto principal (Cap. 6) —son los coeficientes que especifican las reglas de cálculo del producto escalar componente a componente. Por ejemplo, en el espacio euclídeo ordinario vale 1 cuando \(\alpha = \beta\) y 0 en caso contrario. En la sección B.9 lo reinterpretaremos desde la perspectiva de aplicaciones multilineales, así que por ahora solo confirma que "se puede escribir así". Además, en la discusión que sigue usaremos letras latinas \(i, j\) y escribiremos \(g_{ij}\) para tratar espacios de \(n\) dimensiones en general, pero es la misma cantidad con las letras de los índices cambiadas. Lo importante es que el índice mudo \(\alpha\) usado para la expansión de \(\vec{A}\) y el índice mudo \(\beta\) usado para la expansión de \(\vec{B}\) son letras diferentes. Si ambos fueran la misma \(\alpha\), tendríamos \(A^\alpha B^\alpha g_{\alpha\alpha}\) con \(\alpha\) apareciendo 4 veces. Es un error que cometen frecuentemente los principiantes, así que ten cuidado.
⚪ Mei: Claro, \(A^\alpha B^\alpha g_{\alpha\alpha}\) tiene \(\alpha\) apareciendo 4 veces, lo cual viola la regla de "no más de 3 veces" que acabamos de mencionar.
✅ Verificación de comprensión: En la notación de contracción de Einstein, ¿cuáles son las 2 reglas que se deben respetar al usar índices mudos?
Respuesta
(1) Un mismo índice no debe aparecer 3 o más veces en un mismo término. (2) Al representar sumas diferentes, se deben usar obligatoriamente índices mudos diferentes. Si se violan estas reglas, el significado de la expresión se vuelve ambiguo.
✅ Verificación de comprensión: En la convención de contracción de Einstein, ¿qué se hace cuando un mismo índice aparece arriba y abajo? ¿Cómo se llama ese índice?
Respuesta
Se suma sobre ese índice (el \(\sum\) se omite). El rango de la suma depende del contexto —en los espacios lineales de este capítulo va de \(1\) a \(n\); en los índices espacio-temporales de relatividad, de \(0\) a \(n-1\). El índice sobre el que se suma se llama índice mudo. El resultado es el mismo independientemente de la letra que se use para el índice mudo.
📝 Ejercicios:
- Dimensión del espacio producto tensorial → Problema B-4. Dimensiones de los espacios tensoriales, expansión de la notación de contracción → Problema B-5. Expansión de la suma de Einstein, violaciones de la convención de contracción → Problema B-6. Violaciones del convenio de Einstein, reconstrucción a partir de componentes → Problema B-7. Reconstruir un tensor a partir de sus componentes
B.7 Espacio de tensores contravariantes \(T^r(V)\)¶
🟡 Lina: Generalicemos la discusión hasta aquí. Sea \(V\) un espacio lineal de dimensión \(n\) con base \(e_1, e_2, \ldots, e_n\).
Espacio de tensores contravariantes de rango 2: \(T^2(V)\)¶
\(V \otimes V\) se escribe como \(T^2(V)\) y se llama espacio de tensores contravariantes de segundo orden (second-order contravariant tensor space).
- Número de vectores base: \(n^2\) (\(e_i \otimes e_j\), \(i, j = 1, \ldots, n\))
- Dimensión: \(n^2\)
- Notación de los elementos: \(S = S^{ij}\,e_i \otimes e_j\)
🔵 Kai: "Segundo orden" es porque se conectan 2 con \(\otimes\), y "contravariante" es...
🟡 Lina: "Contravariante" tiene que ver con cómo cambian las componentes cuando se cambia el sistema de coordenadas. Solo explicando el origen del nombre: como las componentes se transforman en sentido opuesto a la transformación de los vectores base, se llama "contravariante" (contra-variant = que varía en sentido contrario). Por ejemplo, si cambias las unidades de metros a centímetros, la longitud de cada vector base se reduce de 1m a 1cm, pero el valor numérico de las componentes necesarias para representar el mismo vector se multiplica por 100 —esta "dirección opuesta" es la imagen de contravariante. \(T^2(V)\) tiene 2 índices superiores, así que esa transformación inversa se aplica 2 veces. Lo tratamos en detalle en Cap. 4 del texto principal. Aquí basta con entender que es "el espacio de cantidades con 2 índices superiores".
Rango 3 y superior: \(T^3(V)\), \(T^4(V)\), ...¶
🟡 Lina: De la misma manera, el espacio que tiene como base los elementos formados al conectar 3 \(e_i\):
es \(T^3(V)\). Si \(V\) tiene dimensión \(n\), la base tiene \(n^3\) elementos y la dimensión del espacio es \(n^3\). 🔵 Kai: ¿Si \(n = 2\) entonces \(T^3(V)\) tiene dimensión \(2^3 = 8\)? Entonces la dimensión crece cada vez más al aumentar el rango... ¿qué pasa para un rango general \(r\)?
🟡 Lina: Buena pregunta. Efectivamente, cada vez que el rango sube, se multiplica por \(n\). En general, resumamos la definición del espacio de tensores contravariantes de rango \(r\), \(T^r(V)\).
Definición B.1 — \(T^r(V)\)
Sea \(V\) un espacio lineal de dimensión \(n\), y \(e_1, \ldots, e_n\) una base de \(V\). El espacio lineal de dimensión \(n^r\) que tiene como base los \(n^r\) elementos
\[e_{i_1} \otimes e_{i_2} \otimes \cdots \otimes e_{i_r} \quad (i_1, \ldots, i_r = 1, \ldots, n)\]se llama espacio de tensores contravariantes de rango \(r\) y se denota \(T^r(V)\). Un elemento \(S\) de \(T^r(V)\) se representa como
\[S = S^{i_1 i_2 \cdots i_r}\,e_{i_1} \otimes e_{i_2} \otimes \cdots \otimes e_{i_r} \tag{B.5}\]
🔵 Kai: ¿Entonces el espacio vectorial \(V\) en sí mismo es \(T^1(V)\)?
🟡 Lina: Así es. La base de \(T^1(V)\) es \(e_1, \ldots, e_n\), son \(n\) elementos, dimensión \(n\). Es exactamente \(V\) mismo.
B.8 Producto tensorial entre tensores de diferente rango¶
🟡 Lina: Si calculamos el producto tensorial \(S \otimes T\) de un elemento \(S\) de \(T^2(V)\) y un elemento \(T\) de \(T^1(V) = V\), obtenemos un elemento de \(T^3(V)\).
🟡 Lina: Hagámoslo concretamente. Con \(S = 3\,e_1 \otimes e_1 + 2\,e_2 \otimes e_1\) y \(T = e_1 - e_2\), calcula \(S \otimes T\).
🔵 Kai: A ver, igual que antes, lo expando con la propiedad distributiva. Conecto cada término de \(S\) con cada término de \(T\) mediante \(\otimes\)...
¿Así? La base ha quedado con 3 elementos conectados.
⚪ Mei: Efectivamente, está escrito con bases de la forma \(e_i \otimes e_j \otimes e_k\), así que es un elemento de \(T^3(V)\).
🟡 Lina: En general, el producto tensorial de un elemento de \(T^r(V)\) con un elemento de \(T^m(V)\) es un elemento de \(T^{r+m}(V)\). Los rangos se suman.
🔵 Kai: Rango 2 conectado con rango 1 mediante \(\otimes\) da rango 3... Si el producto tensorial aumenta el rango, ¿existe también una operación que disminuya el rango?
🟡 Lina: Buena pregunta. Esa es la operación llamada "contracción" (contraction). Los detalles se tratan en el texto principal, pero la idea es que al "colapsar" un par de índices y sumar, el rango disminuye. Por ahora recuerda solo que "el producto tensorial aumenta el rango, la contracción lo disminuye" son operaciones complementarias.
🔵 Kai: El producto tensorial aumenta el rango y la contracción lo disminuye... son operaciones inversas que van en pareja. Entonces, ¿si contraemos un tensor de rango 2 obtenemos rango 0, es decir, un escalar?
🟡 Lina: Buena intuición. Pero hay que tener un poco de cuidado. Consideremos un "tensor con un índice superior y un índice inferior" —por ejemplo una cantidad como \(S^i{}_j\). Permíteme organizar aquí la notación del "tipo" de un tensor. Escribimos \((r, s)\) donde \(r\) es el número de índices superiores y \(s\) el número de índices inferiores. Así que el \(S^i{}_j\) actual es de tipo \((1,1)\) —uno arriba, uno abajo. Usaremos esta notación también en la sección B.9, así que apréndela aquí.
🔵 Kai: Tipo \((1,1)\)... uno arriba, uno abajo, rango total 2, ¿verdad?
🟡 Lina: Así es. En este caso, al colapsar el par superior e inferior haciendo \(S^i{}_i\) (sumando sobre \(i\)), los índices desaparecen y queda un escalar. Esto corresponde a la traza de una matriz (suma de los elementos diagonales).
🔵 Kai: Ya veo, ¡la traza de una matriz es un ejemplo concreto de contracción! Pero para \(S^{ij}\) como el de B.7, donde solo hay índices superiores, ¿qué pasa? Me parece que no se puede formar un par entre dos superiores...
🟡 Lina: Buena duda. Así es, con tipo \((2,0)\) no se puede formar un par directamente. Para contraer índices superiores entre sí se necesita la operación de bajar índices con el tensor métrico, pero eso lo tratamos en el texto principal.
⚪ Mei: Es decir, si es tipo \((1,1)\) hay un par superior-inferior y se puede contraer directamente, pero si es tipo \((2,0)\) no se puede formar el par y se necesita una herramienta adicional.
🔵 Kai: Pero si con tipo \((2,0)\) no se puede formar el par, ¿cómo se contrae? ¿Hay que interponer alguna otra operación?
🟡 Lina: Exacto. Hay que convertir un índice superior en inferior —es decir, "bajar el índice" con el tensor métrico. Es el mismo procedimiento que \(A_\mu = g_{\mu\nu} A^\nu\) que aprendimos en Cap. 4 del texto principal. En la sección B.9 confirmaremos que el tensor métrico es el ejemplo representativo de un tensor de tipo \((0,2)\), pero el procedimiento concreto de bajar índices lo dejamos para Cap. 4. Por ahora recuerda solo la regla "si hay un par superior-inferior, se puede contraer".
🔵 Kai: Entiendo, se convierte un índice superior en inferior con el tensor métrico y luego se forma el par —se interpone un paso intermedio.
✅ Verificación de comprensión: El producto tensorial de un elemento de \(T^r(V)\) con un elemento de \(T^m(V)\), ¿a qué espacio pertenece? ¿Cómo se llama esta propiedad?
Respuesta
Es un elemento de \(T^{r+m}(V)\). Es decir, al tomar el producto tensorial, los rangos se suman aditivamente (aditividad del rango). Por ejemplo, el producto tensorial de un tensor de rango 2 con uno de rango 1 da un tensor de rango 3.
📝 Ejercicios:
- Producto tensorial de rangos diferentes → Problema B-8. Producto tensorial de tensores de rango 1 y rango 2, demostración de la aditividad del rango → Problema M-3. Adición de rango mediante el producto tensorial, tensor de rango 0 y escalar → Problema M-4. \(T^0(V)\) y los escalares, práctica de cálculo con producto tensorial → Problema M-5. Desarrollo simple de \(S \otimes T\), dimensión en 3 dimensiones → Problema M-6. Dimensión del espacio tensorial en 3 dimensiones
B.9 Visión del tensor como "aplicación multilineal"¶
🟡 Lina: Hasta aquí hemos introducido los tensores con el enfoque de "alinear bases para construir el espacio". Pero hay otra visión importante. Es el método de definir los tensores como aplicaciones multilineales. Yo lo llamo la imagen de la máquina tragaperras. Mira la Fig. B.1「Imagen de máquina tragaperras del tensor. Se ve el tensor como "una máquina con ranuras". Izquierda」.
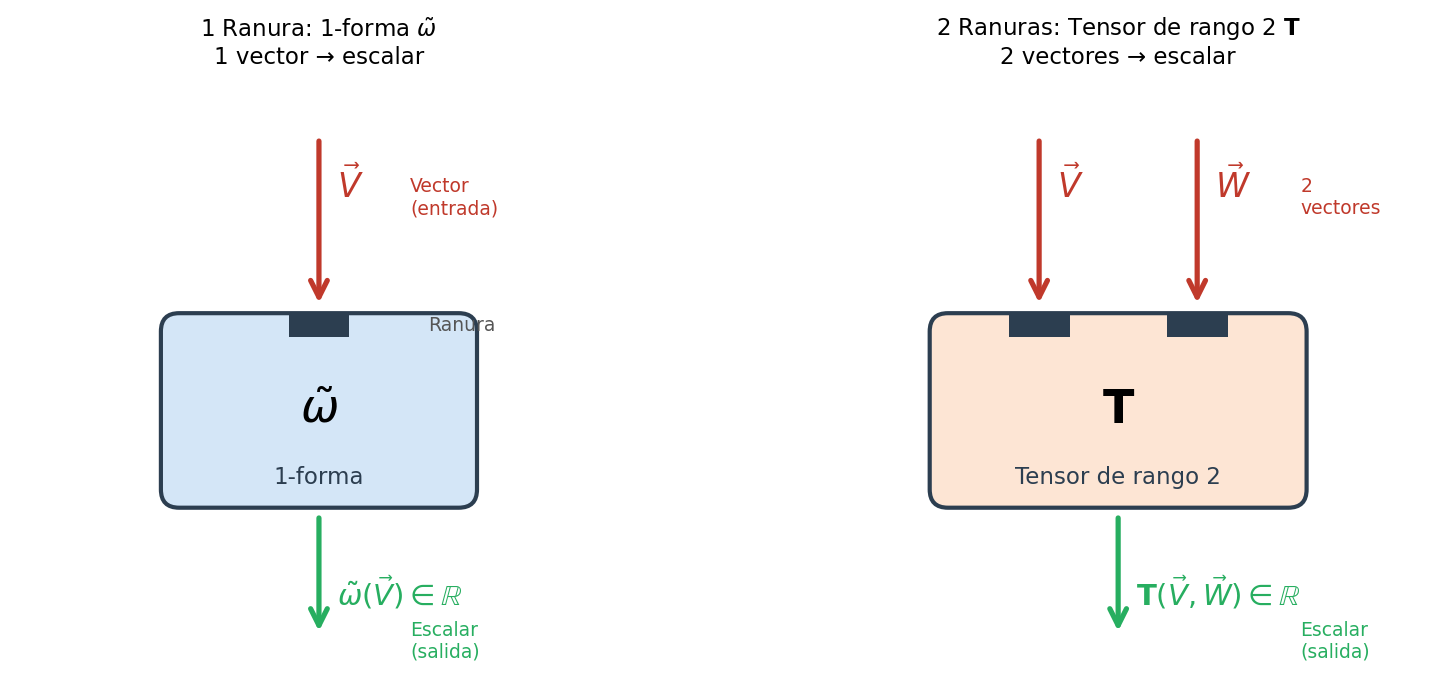
Fig. B.1: Imagen de máquina tragaperras del tensor. Se ve el tensor como "una máquina con ranuras". Izquierda — una 1-forma (una ranura) es una función que recibe un vector y devuelve un escalar. Derecha — un tensor de rango 2 (dos ranuras) es una función que recibe 2 vectores y devuelve un escalar. El significado preciso de "lineal" se define inmediatamente después en el texto.
Piensa en un tensor como "una máquina con ranuras". Mira el lado izquierdo de la figura —hay una caja dibujada con una sola ranura. Esa es una 1-forma: una función lineal que al insertar un vector devuelve un escalar. Lo aprendimos en el texto principal (Cap. 4). El lado derecho de la figura es una caja con dos ranuras —ese es un tensor de rango 2: metes 2 vectores y sale un escalar. El punto clave es que respecto a cada argumento que se inserta en cada ranura es lineal independientemente —esta propiedad se llama "multilineal". El significado preciso de "independientemente lineal" lo explicaré enseguida con ecuaciones, pero intuitivamente significa que "si fijas el contenido de una ranura y duplicas solo el de la otra, la salida también se duplica". El número de ranuras corresponde al "rango" del tensor.
⚪ Mei: Ya veo, una 1-forma es una máquina de una ranura, un tensor de rango 2 es una máquina de dos ranuras... entonces ¿a mayor rango, más ranuras?
🟡 Lina: Exactamente. Un tensor de rango 3 tiene 3 ranuras, de rango 4 tiene 4 —rango = número de ranuras. Definamos matemáticamente esta "máquina con ranuras". Antes, confirmemos dos palabras. Primero, "argumento" —es el valor que se introduce en una función. Es lo que corresponde a \(x\) en \(f(x)\). Segundo, "lineal" —a grandes rasgos significa "se puede sacar un factor constante fuera y se puede separar una suma". Aquí \(f\) es "una función que recibe un vector como entrada y devuelve un número real (escalar)". En ecuaciones: \(f(\alpha \vec{A}) = \alpha f(\vec{A})\) y \(f(\vec{A} + \vec{B}) = f(\vec{A}) + f(\vec{B})\). Por ejemplo, en 2 dimensiones, consideremos la función \(f(\vec{A}) = 2A^1 + 3A^2\) (la suma del doble de la primera componente y el triple de la segunda). Entonces \(f(5\vec{A}) = 2(5A^1) + 3(5A^2) = 5(2A^1 + 3A^2) = 5f(\vec{A})\), y efectivamente se puede sacar el factor constante. "Lineal respecto a cada argumento" significa que, cuando hay múltiples argumentos, si fijas los demás y mueves solo uno, para ese uno se cumple la linealidad que acabamos de ver. Escribiré las ecuaciones concretas enseguida.
🟡 Lina: Usando estas dos palabras, la definición es: una función que toma \(N\) vectores como argumentos, devuelve un número real, y es lineal respecto a cada argumento se define como un tensor.
⚪ Mei: Por cierto, "aplicación multilineal" del título, si lo descomponemos es "multi (múltiples argumentos) + lineal (lineal respecto a cada argumento) + aplicación", ¿verdad? ¿"Aplicación" significa lo mismo que "función"?
🟡 Lina: Correcto. "Aplicación" es "una correspondencia que recibe una entrada y devuelve una salida" —el mismo significado que "función". El nombre es largo, pero el contenido es lo que acabo de explicar.
🔵 Kai: Déjame organizar. "Un dispositivo que al meter \(N\) vectores saca un número real, y además es lineal respecto a cada entrada" —¿esa es la definición de tensor? Pero en B.7 ya definimos el tensor como "elemento del espacio producto tensorial". ¿Hay dos definiciones?
🟡 Lina: Buena pregunta. La definición actual captura al tensor desde otro ángulo diferente a B.7 —la apariencia es distinta pero en realidad describe el mismo objeto. Lo demostraremos formalmente en la sección B.11. Por ahora piensa que "el tensor tiene dos caras". Y el "tipo" de este tensor se escribe \((0, N)\), pero—
🔵 Kai: ¿Qué representan el \(0\) y el \(N\) en \((0, N)\)?
🟡 Lina: Buena pregunta. Recuerda la notación \((r, s)\) introducida en la sección B.8 —\(r\) era el número de índices superiores (contravariantes) y \(s\) el número de índices inferiores (covariantes). El \(T^r(V)\) definido en B.7 tenía \(r\) índices superiores y 0 inferiores, así que era de tipo \((r, 0)\). La "función que come vectores y devuelve un número real" de ahora tiene índices inferiores, así que es de tipo \((0, N)\). Por qué "una función que come vectores" tiene índices inferiores lo explicaré enseguida. Por ejemplo, una 1-forma tiene una sola ranura así que es tipo \((0, 1)\); una función con 2 ranuras como el producto escalar es tipo \((0, 2)\) —el número de ranuras corresponde a \(s\).
⚪ Mei: Ya veo, \(s\) representa el número de ranuras.
🟡 Lina: Por cierto, algunos libros de texto usan la notación \(\binom{0}{N}\), pero como se confunde con coeficientes binomiales, en este libro usamos \((r, s)\).
🔵 Kai: Espera, hasta ahora tratábamos con "tensores contravariantes" de índices superiores, ¿y ahora hablamos de índices inferiores?
🟡 Lina: Buena pregunta. Primero organizaré el panorama general en una tabla, y luego explicaré "por qué son índices inferiores".
| Tipo | Nº de índices superiores | Nº de índices inferiores | Ejemplo |
|---|---|---|---|
| \((1, 0)\) | 1 | 0 | Vector \(A^i\) |
| \((2, 0)\) | 2 | 0 | \(S^{ij}\) de B.7 |
| \((0, 1)\) | 0 | 1 | 1-forma \(f_i\) (introducida en Cap. 4) |
| \((0, 2)\) | 0 | 2 | Tensor métrico \(g_{ij}\) (introducido formalmente en Cap. 6. Aquí lo reinterpretamos desde la perspectiva de aplicación multilineal. Por ahora basta con entenderlo como "los coeficientes que reciben 2 vectores y devuelven el producto escalar") |
🔵 Kai: El tensor métrico \(g_{ij}\) lo aprendimos en el texto principal, pero aquí aparece como "ejemplo de tensor de tipo \((0,2)\)", ¿verdad? Me pregunto cómo se ve desde la perspectiva de aplicación multilineal.
🟡 Lina: Buena pregunta. La definición formal del tensor métrico ya la hicimos en el texto principal (Cap. 6 y Cap. 7). Aquí el objetivo es reinterpretar que "el tensor métrico es el ejemplo representativo de un tensor de tipo \((0,2)\)" desde la perspectiva de aplicación multilineal. El \(g_{\alpha\beta}\) que mencionamos en la sección B.6 (los coeficientes para calcular el producto escalar) lo vamos a reinterpretar en la discusión que sigue como "una función bilineal que recibe 2 vectores y devuelve el producto escalar". Por otro lado, los tensores de tipo \((0, N)\) actuales son "tensores con \(N\) índices inferiores" —definidos como funciones que comen vectores y devuelven números reales. A estos tensores con índices inferiores se les llama tensores covariantes.
🔵 Kai: ¿De dónde viene el nombre "covariante"?
🟡 Lina: Cuando se hace un cambio de coordenadas, las componentes se transforman en la misma dirección que los vectores base, por eso "covariante". Es el par opuesto de "contravariante" que iba en dirección contraria. Los detalles se tratan en Cap. 4, pero por ahora basta con recordar que "cantidad con índices inferiores = covariante".
⚪ Mei: Pero, ¿por qué "una función que come vectores" tiene índices inferiores?
🟡 Lina: Piénsalo intuitivamente así. En la notación de contracción que aprendimos en B.6, los índices superiores e inferiores se emparejan para sumar. Las componentes de un vector son superiores \(A^i\), así que para poder contraer con ellas, las componentes de la función deben ser inferiores. Recuerda que en Cap. 4 las componentes de la 1-forma \(f_i\) eran inferiores —era para poder "comer el vector \(A^i\) y devolver el escalar \(f_i A^i\)". Para un tensor de rango 2 sería \(f_{ij} A^i B^j\): superior e inferior se emparejan para poder sumar. Por eso "una función que come vectores" tiene naturalmente índices inferiores.
🔵 Kai: Entiendo, se determina necesariamente por la regla de contracción. Para "comer" un vector con componentes superiores, la contraparte necesita ser inferior para poder formar el par —como piezas de un puzle.
🟡 Lina: Sí, buena analogía. Superiores e inferiores son tipos diferentes de tensores, pero las reglas de cálculo del producto tensorial y la idea de la representación en componentes son comunes. En el texto principal también se tratan tensores generales de tipo \((r, s)\) con índices superiores e inferiores mezclados, pero aquí primero vamos a captar la idea de "aplicación multilineal" con el ejemplo de tensores covariantes.
🔵 Kai: ¿Qué significa "lineal respecto a cada argumento"?
🟡 Lina: Consideremos por ejemplo una función \(f(\vec{A}, \vec{B})\) con 2 argumentos. "Lineal respecto al primer argumento" significa que, manteniendo fijo \(\vec{B}\) y moviendo solo el primer argumento, se comporta como una función lineal ordinaria. En ecuaciones:
Respecto al primer argumento (fijando \(\vec{B}\)): $\(f(\alpha \vec{A} + \beta \vec{C},\; \vec{B}) = \alpha\,f(\vec{A}, \vec{B}) + \beta\,f(\vec{C}, \vec{B})\)$
De manera análoga, fijando \(\vec{A}\) y moviendo solo el segundo argumento, también es lineal:
Respecto al segundo argumento (fijando \(\vec{A}\)): $\(f(\vec{A},\; \alpha \vec{B} + \beta \vec{C}) = \alpha\,f(\vec{A}, \vec{B}) + \beta\,f(\vec{A}, \vec{C})\)$
Verifiquemos con un ejemplo concreto. Con el producto escalar \(f(\vec{A}, \vec{B}) = \vec{A} \cdot \vec{B}\), tomemos \(\vec{A} = (1, 0)\), \(\vec{B} = (1, 1)\), \(\vec{C} = (0, 1)\). Con \(\alpha = 2, \beta = 3\), verifiquemos la linealidad del segundo argumento: el lado izquierdo es \(f(\vec{A},\; 2\vec{B} + 3\vec{C}) = (1, 0) \cdot (2, 5) = 2\). El lado derecho es \(2\,f(\vec{A}, \vec{B}) + 3\,f(\vec{A}, \vec{C}) = 2 \cdot 1 + 3 \cdot 0 = 2\). Efectivamente coinciden.
Así, una función que es lineal respecto a cada argumento cuando se fija el otro se llama bilineal (bilinear). En general, una función lineal respecto a los \(N\) argumentos se llama multilineal (multilinear).
🔵 Kai: Un momento, el producto escalar \(\vec{A} \cdot \vec{B}\) es "una función que recibe 2 vectores y devuelve un número real", ¿verdad? Entonces encaja en la definición actual... ¿el producto escalar es un tipo de tensor?
🟡 Lina: Buena observación. Verifiquémoslo. Recuerda las propiedades del producto escalar que aprendiste en el instituto —se cumple \((\vec{A} + \vec{B}) \cdot \vec{C} = \vec{A} \cdot \vec{C} + \vec{B} \cdot \vec{C}\) y \((k\vec{A}) \cdot \vec{B} = k(\vec{A} \cdot \vec{B})\). Esto es exactamente "lineal respecto al primer argumento". Como lo mismo vale para el segundo argumento, el producto escalar es bilineal —es decir, satisface las condiciones de un tensor de tipo \((0, 2)\).
🔵 Kai: ¡Las propiedades del producto escalar que aprendimos en el instituto satisfacen directamente la condición de "bilineal"!
🟡 Lina: Exacto. Veamos ahora cómo queda en componentes. En la precaución sobre índices mudos de B.6 mencionamos "los coeficientes \(g_{\alpha\beta}\) para calcular el producto escalar". Es la misma cosa. En B.6 usamos letras griegas \(\alpha, \beta\) pensando en el espacio-tiempo 4-dimensional, pero ahora como hablamos de un espacio general de \(n\) dimensiones, usamos letras latinas \(i, j\) y escribimos \(g_{ij}\). Solo cambia el símbolo, el contenido es el mismo —la letra del índice es solo un indicador de "de cuántas dimensiones estamos hablando".
⚪ Mei: Letras griegas para espacio-tiempo 4-dimensional, letras latinas para \(n\) dimensiones en general —la misma convención que en el texto principal.
🟡 Lina: Así es. Veamos por qué el producto escalar se puede escribir como \(g_{ij} A^i B^j\) —verifícalo con un ejemplo simple. El producto escalar en el espacio euclídeo 2-dimensional ordinario es \(\vec{A} \cdot \vec{B} = A^1 B^1 + A^2 B^2\). Ajustándolo a la forma \(g_{ij} A^i B^j\), si ponemos \(g_{11} = 1, g_{22} = 1, g_{12} = g_{21} = 0\) entonces \(g_{ij} A^i B^j = 1 \cdot A^1 B^1 + 0 \cdot A^1 B^2 + 0 \cdot A^2 B^1 + 1 \cdot A^2 B^2 = A^1 B^1 + A^2 B^2\), y coincide.
🔵 Kai: Ya veo. Pero en el espacio euclídeo \(g_{ij}\) es la matriz identidad, y sin necesidad de usar \(g_{ij}\) basta con \(A^1 B^1 + A^2 B^2\), ¿verdad? ¿Por qué molestarse en usar \(g_{ij}\)?
🟡 Lina: Buena pregunta. Si solo consideramos el espacio euclídeo, efectivamente no es necesario. Pero como aprendimos en el texto principal, en el espacio-tiempo de Minkowski \(g_{00} = -1\) con un signo negativo en la componente temporal, y en espacio-tiempos curvos \(g_{ij}\) cambia de punto a punto. Es decir, para tratar de manera unificada situaciones donde "las reglas del producto escalar difieren según el espacio", se necesita \(g_{ij}\). Por ahora entiéndelo como "el caso especial que se reduce a la matriz identidad en el espacio euclídeo".
⚪ Mei: Es decir, \(g_{ij}\) son "los coeficientes que especifican las reglas del producto escalar componente a componente". En el espacio euclídeo coinciden con las componentes de la matriz identidad, pero en un espacio general no necesariamente es así.
🟡 Lina: Exacto. En un espacio general \(g_{ij}\) no tiene por qué ser la matriz identidad, pero la estructura es la misma. Ahora, antes dije que "el producto escalar satisface las condiciones de un tensor de tipo \((0,2)\)". Vamos a verificarlo realmente en la forma de componentes \(g_{ij} A^i B^j\) —es decir, vamos a comprobar que esta expresión es efectivamente lineal respecto a cada argumento. Fijamos \(\vec{A}\) y cambiamos el segundo argumento a \(\alpha \vec{B} + \beta \vec{C}\). Lo que queremos demostrar es que \(g_{ij} A^i (\alpha B^j + \beta C^j) = \alpha\,g_{ij} A^i B^j + \beta\,g_{ij} A^i C^j\) se cumple —es decir, que se puede usar la propiedad distributiva ordinaria.
🔵 Kai: ¿Que se pueda usar la propiedad distributiva no es algo obvio? Solo hay que expandir normalmente...
🟡 Lina: Buena pregunta. El punto es que la parte \(g_{ij} A^i\) es "simplemente un valor numérico" que no depende de \(\vec{B}\) ni de \(\vec{C}\). Verifiquémoslo concretamente con \(n = 2\) —si fijamos \(j\) y calculamos \(g_{ij} A^i\): cuando \(j = 1\) obtenemos \(g_{i1} A^i = g_{11} A^1 + g_{21} A^2\); cuando \(j = 2\) obtenemos \(g_{i2} A^i = g_{12} A^1 + g_{22} A^2\) —estos son valores numéricos determinados solo por las componentes de \(\vec{A}\) y \(g_{ij}\), que no dependen en absoluto de la elección de \(\vec{B}\) o \(\vec{C}\). Por ejemplo, en el espacio euclídeo con \(\vec{A} = (3, 5)\): \(g_{i1} A^i = 1 \cdot 3 + 0 \cdot 5 = 3\), \(g_{i2} A^i = 0 \cdot 3 + 1 \cdot 5 = 5\) —valores numéricos concretos que quedan determinados antes de elegir \(\vec{B}\) o \(\vec{C}\).
🔵 Kai: "Fijando \(j\)", ¿qué significa eso? ¿No se suma sobre \(j\)?
🟡 Lina: Buena pregunta. En la expresión \(g_{ij} A^i\), \(i\) aparece emparejado arriba (en \(A^i\)) y abajo (en el primer índice de \(g_{ij}\)), así que es un índice mudo —se suma sobre \(i\). Pero \(j\) aparece solo una vez dentro de \(g_{ij}\). A un "índice que queda sin emparejar" como este se le llama índice libre (free index) —un término que apareció en Cap. 2. Los índices libres no se suman, sino que se consideran caso por caso: "cuando \(j = 1\)", "cuando \(j = 2\)". Es decir, \(g_{ij} A^i\) devuelve un valor numérico para cada valor de \(j\) —3 si \(j = 1\), 5 si \(j = 2\), y así.
⚪ Mei: Entiendo, \(g_{ij} A^i\) se convierte en un valor numérico cada vez que se fija \(j\). Queda determinado independientemente de \(\vec{B}\) o \(\vec{C}\).
🟡 Lina: Así es. Por eso, al considerar la expresión \(g_{ij} A^i (\alpha B^j + \beta C^j)\), fijamos \(j\) uno por uno —es decir, miramos en orden "cuando \(j = 1\)", "cuando \(j = 2\)". Cada vez que fijamos \(j\), \(g_{ij} A^i\) se comporta como un valor numérico fijo, así que se puede expandir con la propiedad distributiva ordinaria. Escribámoslo concretamente para \(n = 2\). El término con \(j = 1\) es \(g_{i1} A^i \cdot (\alpha B^1 + \beta C^1) = \alpha\,g_{i1} A^i B^1 + \beta\,g_{i1} A^i C^1\); el término con \(j = 2\) de manera similar es \(\alpha\,g_{i2} A^i B^2 + \beta\,g_{i2} A^i C^2\).
🔵 Kai: Hasta aquí estábamos fijando \(j\) y separando en casos. ¿Al final también se suma sobre \(j\)?
🟡 Lina: Exacto. Si sumamos los resultados de \(j = 1\) y \(j = 2\), obtenemos \(\alpha\,g_{ij} A^i B^j + \beta\,g_{ij} A^i C^j\). En esta última expresión, \(j\) también aparece emparejado arriba en \(B^j\) y abajo en \(g_{ij}\), así que se suma como índice mudo.
⚪ Mei: Es decir, finalmente \(g(\vec{A},\; \alpha\vec{B} + \beta\vec{C}) = \alpha\,g(\vec{A}, \vec{B}) + \beta\,g(\vec{A}, \vec{C})\) se cumple —efectivamente es lineal respecto al segundo argumento.
🟡 Lina: Correcto. Por lo tanto, el producto escalar \(g(\vec{A}, \vec{B}) = g_{ij} A^i B^j\) es efectivamente bilineal y es el ejemplo representativo de un tensor de tipo \((0, 2)\). Este es el tensor métrico que aparece en el texto principal.
⚪ Mei: Ya veo, una operación tan familiar como el producto escalar encaja perfectamente en la definición de tensor.
🔵 Kai: Déjame verificar. En la expresión \(g_{ij} A^i B^j\), \(i\) está abajo en \(g_{ij}\) y arriba en \(A^i\) así que se emparejan y se suma; \(j\) está abajo en \(g_{ij}\) y arriba en \(B^j\) así que también se emparejan y se suma... entonces en total son \(n^2\) términos en la suma, ¿verdad?
🟡 Lina: Correcto. Si \(n = 2\) son los 4 términos \(g_{11}A^1 B^1 + g_{12}A^1 B^2 + g_{21}A^2 B^1 + g_{22}A^2 B^2\). Aquí quiero enfatizar un punto importante. En la discusión actual, al dictaminar que "el producto escalar es bilineal y por tanto es un tensor de tipo \((0,2)\)", no usamos los valores concretos de las componentes \(g_{ij}\). La definición de tensor en sí no depende de las componentes —se determina solo por la propiedad de "ser un cierto tipo de función". Las componentes aparecen solo cuando se elige un sistema de coordenadas. Entonces, ¿cómo se obtienen las componentes? Ese es el tema de la siguiente sección B.10.
🔵 Kai: ...Entonces eso significa que el tensor en sí es un ente geométrico independiente de las coordenadas, y las componentes son valores numéricos que se determinan solo al elegir un sistema de coordenadas. ¡Es la misma estructura que con los vectores! Pero con los vectores teníamos la imagen intuitiva de una "flecha"; para tensores de rango 2 o superior, ¿qué "forma" geométrica tienen?
🟡 Lina: Buena pregunta, pero representar tensores de rango 2 o superior con un solo dibujo es difícil. Por eso la definición abstracta como "aplicación multilineal" es tan poderosa —caracteriza al tensor no por su forma sino por su comportamiento (qué sale cuando se mete algo). Y esta forma de pensar es la clave para realizar naturalmente el principio de covariancia general en relatividad general: "las leyes físicas no dependen del sistema de coordenadas".
✅ Verificación de comprensión: Al definir un tensor como "aplicación multilineal", ¿qué tipo de función es un tensor de tipo \((0, 2)\)? Además, ¿cuál es la ventaja de esta definición?
Respuesta
Un tensor de tipo \((0, 2)\) es una función que toma 2 vectores como argumentos y devuelve un número real, siendo lineal respecto a cada argumento (bilineal). La ventaja de esta definición es que no intervienen componentes ni coordenadas, lo que permite concebir el tensor como un objeto geométrico independiente de las coordenadas.
B.10 Obtención de las componentes del tensor a partir de la "aplicación multilineal"¶
🟡 Lina: Las componentes de un tensor como aplicación multilineal se definen como los números reales que se obtienen al sustituir los vectores base.
Las componentes de un tensor de tipo \((0, 2)\), \(f\), son:
⚪ Mei: Para la métrica \(g\) que apareció antes, ¿cómo queda esta definición?
🟡 Lina: Buena pregunta. Verifiquémoslo con un ejemplo concreto del texto principal. La métrica de Minkowski que aprendimos en Cap. 4 es exactamente este caso. A partir de aquí hablamos del espacio-tiempo 4-dimensional, así que cambio los índices a letras griegas \(\alpha, \beta\) (\(= 0, 1, 2, 3\)) —la misma notación que en el texto principal. En un espacio-tiempo plano, las componentes del tensor métrico \(g_{\alpha\beta}\) son constantes, y las denotamos específicamente \(\eta_{\alpha\beta}\). Sustituyendo la base \(e_0, e_1, e_2, e_3\) del espacio-tiempo 4-dimensional:
Aquí \(g(e_\alpha, e_\beta)\) es "el producto escalar de los vectores base \(e_\alpha\) y \(e_\beta\) calculado con el tensor métrico \(g\)" —es decir, el tensor métrico es precisamente la herramienta que define el producto escalar. Con la convención de signos \((-,+,+,+)\):
Estas son precisamente las "componentes del tensor métrico". Una vez conocidas las componentes, se puede calcular el valor para cualquier vector.
🟡 Lina: Sustituimos \(\vec{A} = A^\alpha e_\alpha\) y \(\vec{B} = B^\beta e_\beta\). Observa que para la expansión de \(\vec{A}\) y \(\vec{B}\) usamos índices mudos diferentes \(\alpha, \beta\) —es la puesta en práctica de la regla "usar índices mudos diferentes para sumas diferentes" que aprendimos en B.6.
Primero usamos la linealidad del primer argumento. Como \(\vec{A} = A^0 e_0 + A^1 e_1 + A^2 e_2 + A^3 e_3 = A^\alpha e_\alpha\), primero separamos la suma:
Luego sacamos el escalar fuera de cada término:
🔵 Kai: Separar la suma y luego sacar el escalar fuera —se usa la regla de linealidad en dos pasos.
Luego usamos la linealidad del segundo argumento de la misma manera:
⚪ Mei: Solo se aplicó la misma operación al segundo argumento. Todos los escalares salieron fuera limpiamente.
Resumiendo:
Así, usando la multilinealidad se pueden sacar los coeficientes escalares fuera de la función uno a uno.
🔵 Kai: Los índices del espacio-tiempo son \(0, 1, 2, 3\), así que al expandir queda \(-A^0 B^0 + A^1 B^1 + A^2 B^2 + A^3 B^3\). ¡Es exactamente el producto escalar que vimos en Cap. 5!
✅ Verificación de comprensión: ¿Cómo se obtienen las componentes \(f_{ij}\) de un tensor \(f\) como aplicación multilineal?
Respuesta
Se definen como los números reales obtenidos al sustituir los vectores base como argumentos. Es decir, \(f_{ij} := f(e_i, e_j)\). Una vez conocidas las componentes, el valor para cualquier vector se calcula usando la multilinealidad como \(f(\vec{A}, \vec{B}) = A^i B^j f_{ij}\).
📝 Ejercicios:
- Cálculo de componentes de una aplicación bilineal → Problema M-2. Representación en componentes de una aplicación bilineal, cálculo de un tensor tipo matriz identidad → Problema M-8. Evaluación de la forma bilineal identidad
B.11 Conexión entre los dos enfoques¶
🟡 Lina: Hasta aquí hemos introducido los tensores de dos maneras. Las organizo en Tabla B.1「Comparación de los dos enfoques para introducir tensores」. En esta sección mostraremos que las dos son en realidad la misma cosa.
🔵 Kai: Intuitivamente entiendo que son lo mismo, pero ¿cómo se verifica concretamente? ¿Se puede "sustituir" un vector en un elemento del espacio producto tensorial \(f_{ij}\,e_i \otimes e_j\)?
🟡 Lina: Buena pregunta. Ese es precisamente el problema. \(e_i \otimes e_j\) es un producto de vectores entre sí, así que no tiene mecanismo para "comer" vectores. Como aprendimos en B.9, lo que puede recibir vectores como entrada y devolver un número real son las 1-formas. Por eso, si preparamos una "compañera" 1-forma que corresponda a cada vector base \(e_i\), y reemplazamos la base del espacio producto tensorial por el producto tensorial de 1-formas \(\epsilon^i \otimes \epsilon^j\), podremos comer vectores de manera natural. Esa "compañera" es la base dual (dual basis).
🔵 Kai: ¿Qué es "dual"? Entiendo lo de "compañera", pero ¿por qué se llama "dual"?
🟡 Lina: "Dual" significa "que forma un par". Los vectores y las 1-formas tienen una relación mutua de "comer y ser comido" —un vector es comido por una 1-forma y devuelve un escalar; inversamente, una 1-forma es comida por un vector y devuelve un escalar. A esta relación simétrica de par se le llama "dual". Así que "base dual" significa "la base de 1-formas que forma par con la base original".
Tabla B.1: Comparación de los dos enfoques para introducir tensores
| Enfoque | Esencia | Ventaja |
|---|---|---|
| Espacio producto tensorial | Se alinean las bases \(e_i \otimes e_j\) para construir el espacio | Procedimiento de cálculo claro |
| Aplicación multilineal | Función que toma vectores como argumentos y devuelve un número real | Definición independiente de coordenadas |
⚪ Mei: Siento que los dos enfoques miran el mismo objeto desde ángulos diferentes... ¿son realmente lo mismo?
🟡 Lina: Buena intuición. De hecho, se puede demostrar matemáticamente que son lo mismo. La razón por la que necesitamos verificarlo es que —si los dos enfoques son realmente iguales, se garantiza que "el método de calcular alineando componentes" y "el método de sustituir como función" siempre darán la misma respuesta. Así podremos elegir el más conveniente según la situación. Digo primero el objetivo —queremos mostrar que "al sustituir vectores en un elemento del espacio producto tensorial, se obtiene el mismo resultado que al calcular como aplicación multilineal: \(f_{ij} A^i B^j\)". Para ello usaremos la base dual \(\epsilon^i\) que introdujimos al responder la pregunta de Kai. Si reemplazamos la base de tensores covariantes por \(\epsilon^i \otimes \epsilon^j\), podrán "comer" vectores naturalmente.
🔵 Kai: Espera un momento. ¿"Reconstruir la base con 1-formas" significa que descartamos el espacio que construimos con \(e_i \otimes e_j\)? ¿O creamos un nuevo espacio diferente?
🟡 Lina: Buena pregunta. No lo descartamos. El espacio de tensores contravariantes \(T^2(V)\) queda tal cual como un espacio con base \(e_i \otimes e_j\). Lo que queremos hacer ahora es reescribir el espacio de tensores covariantes —es decir, el espacio de "funciones que comen vectores"— en el lenguaje del producto tensorial. Para eso usamos la base de 1-formas \(\epsilon^i\) y construimos la base \(\epsilon^i \otimes \epsilon^j\). Recordatorio sobre 1-formas —son "funciones lineales que reciben un vector y devuelven un número real" (lo estudiamos en detalle en Cap. 4).
🔵 Kai: Hmm... pero ¿por qué la covariante se construye con 1-formas? ¿No se puede con los vectores base \(e_i\)?
🟡 Lina: Los tensores covariantes son "funciones que comen vectores". Así que la base misma debe poder comer vectores. \(e_1\) es solo una flecha, no tiene mecanismo para recibir \(\vec{A}\) y devolver un número. Pero una 1-forma sí puede devolver un número —por eso construimos la base con 1-formas. Concretamente, dada la base \(e_1, \ldots, e_n\) de \(V\), definimos el conjunto de 1-formas \(\epsilon^1, \ldots, \epsilon^n\). Usamos la letra griega \(\epsilon\) (épsilon) porque \(e^i\) se confundiría con la función exponencial \(e^x\). En algunos libros de texto se escribe \(\theta^i\). Fíjate en la posición del índice —\(\epsilon^i\) tiene índice superior. Lo contrario de la base de vectores \(e_i\) que tenía índice inferior. Como vimos en B.6, los vectores tenían "componentes con índice superior \(A^i\), base con índice inferior \(e_i\)". Las 1-formas son lo contrario: "componentes con índice inferior \(f_i\), base con índice superior \(\epsilon^i\)". Componentes y base siempre tienen los índices invertidos —esta es la regla para ser consistente con la notación de contracción.
⚪ Mei: Entiendo, tanto para vectores como para 1-formas la regla unificada es "los índices de componentes y base son siempre opuestos".
🔵 Kai: Entonces, ¿qué 1-forma es concretamente \(\epsilon^i\)? ¿Qué se mete y qué devuelve?
🟡 Lina: Buena pregunta. Antes dijimos que "queremos sustituir vectores en elementos del espacio producto tensorial". Para ello necesitamos una herramienta que pueda extraer cada componente del vector una a una. Queremos que \(\epsilon^i\) tenga el papel de "dispositivo que extrae solo la componente \(i\)-ésima". Imagínalo concretamente —dado un vector \(\vec{A} = 3e_1 + 5e_2\), queremos "un dispositivo que extraiga solo el 3 de la primera componente" y "un dispositivo que extraiga solo el 5 de la segunda componente". \(\epsilon^1\) hace lo primero y \(\epsilon^2\) lo segundo. "Extraer la primera componente" significa que al meter \(e_1\) devuelve 1, y al meter \(e_2\) devuelve 0 —así \(\epsilon^1(3e_1 + 5e_2) = 3 \cdot 1 + 5 \cdot 0 = 3\) y solo queda la primera componente. En general, queremos que para cada base devuelva "1 solo cuando es su propio número, 0 en caso contrario". Escribiéndolo en ecuaciones:
🔵 Kai: \(\delta^i{}_j\)... ¡ah, es la delta de Kronecker! Apareció en Cap. 6. Devuelve 1 si \(i = j\) y 0 si \(i \neq j\).
🟡 Lina: Sí, buena memoria. Aquí escribimos los índices separados arriba y abajo como \(\delta^i{}_j\), pero numéricamente es lo mismo.
🔵 Kai: Si numéricamente son iguales, ¿por qué separar en arriba y abajo? ¿No basta con \(\delta_{ij}\)?
🟡 Lina: Buena pregunta. La razón es la consistencia con la notación de contracción. Mira el lado izquierdo —en \(\epsilon^i(e_j)\), \(\epsilon^i\) tiene índice superior y \(e_j\) tiene índice inferior. Si el lado derecho también mantiene la misma disposición de índices, cuando se haga una contracción después, la regla de "sumar emparejando superior con inferior" se aplica directamente. Numéricamente \(\delta^i{}_j\), \(\delta_{ij}\) y \(\delta^{ij}\) son todos iguales (1 si \(i = j\), 0 en caso contrario), así que por ahora piensa en ello como "una convención de escritura".
⚪ Mei: En resumen, tiene el mismo valor que la componente \((i, j)\) de la matriz identidad, pero si se mantienen las posiciones de los índices alineadas, no habrá confusión en cálculos posteriores.
🟡 Lina: Exacto. Es decir, cada \(\epsilon^i\) es una 1-forma que "extrae solo la componente \(i\)-ésima de la base". Por cierto, en algunos libros de texto la base dual se escribe como \(e^i\), pero como se confunde con la exponencial \(e^x\), en este libro usamos \(\epsilon^i\).
🔵 Kai: Las 1-formas eran funciones que comen vectores y devuelven un número real. ¿\(\epsilon^i\) es "si meto \(e_i\) devuelve 1, si meto otra base devuelve 0"?
🟡 Lina: Exactamente. Verifiquémoslo con un ejemplo concreto. Aplicando \(\epsilon^1\) a \(\vec{A} = 3e_1 + 5e_2\): \(\epsilon^1(\vec{A}) = \epsilon^1(3e_1 + 5e_2) = 3\,\epsilon^1(e_1) + 5\,\epsilon^1(e_2) = 3 \cdot 1 + 5 \cdot 0 = 3\). Es decir, extrae solo la primera componente.
⚪ Mei: Entiendo, \(\epsilon^i\) es como un "dispositivo lector de la componente \(i\)-ésima".
🟡 Lina: Así es. Y al construir el espacio con el producto tensorial de estas bases duales \(\epsilon^i \otimes \epsilon^j\) como base, para cualquier elemento \(f = f_{ij}\,\epsilon^i \otimes \epsilon^j\) podemos definir la operación de "sustituir" vectores \(\vec{A}, \vec{B}\).
🔵 Kai: "Sustituir" vectores en un elemento del espacio producto tensorial, ¿concretamente cómo se hace?
🟡 Lina: La regla de definición es natural. \((\epsilon^i \otimes \epsilon^j)(\vec{A}, \vec{B}) := \epsilon^i(\vec{A})\,\epsilon^j(\vec{B})\) —es decir, el lado izquierdo del producto tensorial se encarga del primer argumento, y el lado derecho del segundo.
🔵 Kai: El \(\epsilon^i\) de la izquierda come \(\vec{A}\), y el \(\epsilon^j\) de la derecha come \(\vec{B}\)... es como la imagen de meter uno en cada ranura de una máquina con 2 ranuras.
🟡 Lina: Exactamente. Generalizando el ejemplo concreto de antes, \(\epsilon^i\) es una 1-forma, así que es una función lineal. Recuerda la regla de funciones lineales —se cumple \(\epsilon^i(\alpha \vec{u} + \beta \vec{v}) = \alpha\,\epsilon^i(\vec{u}) + \beta\,\epsilon^i(\vec{v})\). Sustituimos \(\vec{A} = A^k e_k\) (notación de contracción sumando sobre \(k\)). Aquí uso como índice mudo \(k\) en vez de \(i\) porque el índice superior \(i\) de \(\epsilon^i\) ya está en uso —es la práctica de la regla "usar índices mudos diferentes para sumas diferentes" de la sección B.6. Expandiendo, \(\vec{A} = A^1 e_1 + A^2 e_2 + \cdots + A^n e_n\), y usando la linealidad repetidamente para separar cada término: \(\epsilon^i(\vec{A}) = \epsilon^i(A^1 e_1 + A^2 e_2 + \cdots) = A^1\,\epsilon^i(e_1) + A^2\,\epsilon^i(e_2) + \cdots = A^k\,\epsilon^i(e_k)\). Que el escalar \(A^k\) salga fuera de la función es la regla de linealidad misma. Y como \(\epsilon^i(e_k) = \delta^i{}_k\), queda \(A^k\,\delta^i{}_k\).
🔵 Kai: Ah, es la delta de Kronecker de antes. Al sumar sobre \(k\), solo sobrevive el término con \(k = i\)...
🟡 Lina: Exacto. Añado un suplemento sobre el último paso. Como \(\delta^i{}_k\) vale 1 solo cuando \(i = k\) y 0 en caso contrario, al sumar sobre \(k\) solo sobrevive el término \(k = i\). Es decir, \(A^k\,\delta^i{}_k = A^1 \cdot 0 + \cdots + A^i \cdot 1 + \cdots + A^n \cdot 0 = A^i\). Esta es la función de la delta de Kronecker de "reemplazar índices".
🔵 Kai: Déjame verificar. En \(A^k \delta^i{}_k\) cuando sumo sobre \(k\), \(i\) está fijado, ¿verdad? Por ejemplo si \(i = 2\) entonces \(A^1 \cdot \delta^2{}_1 + A^2 \cdot \delta^2{}_2 + \cdots = 0 + A^2 + 0 + \cdots = A^2\), ¿es así?
🟡 Lina: Exactamente. \(i\) es un índice libre así que está fijado, y solo \(k\) recorre como índice mudo. Si \(i = 2\) solo sobrevive el término con \(k = 2\) y sale \(A^2\). Para cualquier \(i\) general, el mismo mecanismo produce \(A^i\).
⚪ Mei: Es decir, \(\epsilon^i(\vec{A}) = A^i\). \(\epsilon^i\) devuelve directamente la componente \(i\)-ésima del vector.
🟡 Lina: Correcto. Del mismo modo \(\epsilon^j(\vec{B}) = B^j\), así que juntándolo todo:
Es decir, se comporta como "una función que al meter 2 vectores devuelve un número real". Inversamente, si sustituimos vectores base en la aplicación multilineal, obtenemos las componentes. Matemáticamente, estos dos espacios son isomorfos (isomorphic).
🔵 Kai: "Isomorfos"... ¿significa que tienen la misma forma?
🟡 Lina: A grandes rasgos sí. Más precisamente, "aunque parecen diferentes, tienen exactamente la misma estructura de reglas de suma y multiplicación por escalar". Con un ejemplo cotidiano: representar puntos del plano 2D con "coordenadas \((x, y)\)" o con "flechas (vectores)" —parecen diferentes pero las reglas de suma y multiplicación por escalar son iguales, así que calculando con cualquiera de los dos se obtiene la misma respuesta. Con los tensores es igual: si las componentes \(f_{ij}\) son las mismas, calculando con el enfoque del espacio producto tensorial o con el enfoque de aplicación multilineal, siempre sale el mismo valor numérico.
🔵 Kai: Ah, es como la relación entre coordenadas y vectores. Solo la representación es diferente pero el contenido es el mismo... pero ¿realmente dan la misma respuesta en todos los casos? ¿No será que solo coincidieron en este ejemplo por casualidad?
🟡 Lina: Buena duda. Que no es "casualidad" es lo que garantiza el concepto matemático de "isomorfismo". Significa que entre los dos espacios existe "una correspondencia uno a uno que no destruye la estructura de suma ni de multiplicación por escalar". "No destruir la estructura" significa que, por ejemplo, si primero sumas dos elementos y luego los haces corresponder, o si primero los haces corresponder y luego los sumas, el resultado es el mismo.
🔵 Kai: Hmm, es abstracto y me cuesta un poco imaginarlo. ¿Concretamente qué significa?
🟡 Lina: Veámoslo concretamente. Si sumamos el elemento \(f_{ij}\,\epsilon^i \otimes \epsilon^j\) del espacio producto tensorial con otro tensor de tipo \((0,2)\), \(h_{ij}\,\epsilon^i \otimes \epsilon^j\), obtenemos \((f_{ij} + h_{ij})\,\epsilon^i \otimes \epsilon^j\). Por otro lado, si primero los vemos como aplicaciones multilineales y luego los sumamos: \((f + h)(\vec{A}, \vec{B}) = f_{ij} A^i B^j + h_{ij} A^i B^j = (f_{ij} + h_{ij}) A^i B^j\) —salen las mismas componentes \(f_{ij} + h_{ij}\). Es decir, "primero sumar y luego hacer corresponder" y "primero hacer corresponder y luego sumar" coinciden —por eso los dos espacios son iguales incluyendo la estructura, es decir, isomorfos.
⚪ Mei: Ya veo, como las componentes coinciden calculando con cualquiera de los dos enfoques, el resultado es necesariamente el mismo.
🔵 Kai: Al intercambiar el orden de la suma salen las mismas componentes, por eso se puede decir que son "iguales incluyendo la estructura". Es decir, ya sea calculando en componentes o sustituyendo como función, el valor numérico final coincide absolutamente —así que se puede usar cualquiera de los dos métodos. ...Ah, pero todo lo de recién era sobre tensores covariantes. ¿Para tensores contravariantes también existe una visión similar?
🟡 Lina: Buena pregunta. Para tensores contravariantes también se cumple una correspondencia análoga. De manera simétrica a que los tensores covariantes son "funciones que comen vectores", los tensores contravariantes se pueden concebir como "funciones que comen 1-formas y devuelven un número real". Solo se intercambian los papeles de índices superiores e inferiores. Por ejemplo, al aplicar una 1-forma \(f = f_j \epsilon^j\) a un vector \(\vec{A} = A^i e_i\), se obtiene el escalar \(f(\vec{A}) = f_i A^i\). Esto equivale a ver el vector (tipo \((1,0)\)) como "una función que come una 1-forma y devuelve un número real". Los detalles se tratan en el texto principal, así que por ahora quédate con la imagen.
🔵 Kai: Ya veo... covariante "come vectores", contravariante "come 1-formas" —solo se intercambia arriba y abajo, la estructura es la misma.
🟡 Lina: En la práctica, para calcular usa el enfoque del espacio producto tensorial (alinear componentes y hacer sumas y multiplicaciones por escalar), y para entender conceptos usa el enfoque de aplicación multilineal (objeto geométrico independiente de coordenadas) —es bueno usar la herramienta adecuada según la situación.
⚪ Mei: Cálculos con componentes, conceptos con aplicaciones —usar las herramientas según la ocasión.
📝 Ejercicios:
- Descomposición en tensores simétricos y antisimétricos → Problema A-1. Descomposición simétrica y antisimétrica, espacio dual y producto tensorial → Problema A-2. Representación tensorial mediante el espacio dual
Avance del próximo capítulo¶
🟡 Lina: En el siguiente Apéndice C, extenderemos el principio de acción de partículas a campos (fields). Introduciremos el concepto de densidad lagrangiana, derivaremos las ecuaciones de Euler-Lagrange para campos, y aprenderemos cómo escribir la acción de un campo en espacio-tiempo curvo, mostrando el camino hacia la acción de Einstein-Hilbert.
Problemas de práctica¶
📝 Ejercicios:
- Expansión del producto tensorial → Problema B-1. Producto tensorial \(S \otimes T\) básico
- Verificación de la no conmutatividad → Problema B-2. No conmutatividad del producto tensorial
- Suma y multiplicación por escalar en el espacio producto tensorial → Problema B-3. Combinaciones lineales de tensores
- Condición necesaria y suficiente para tensores descomponibles → Problema M-1. Condición para tensores descomponibles
- Ejemplo concreto de no descomponibilidad → Problema M-7. No descomponibilidad de un tensor antisimétrico
- Dimensión del espacio producto tensorial → Problema B-4. Dimensiones de los espacios tensoriales
- Expansión de la notación de contracción → Problema B-5. Expansión de la suma de Einstein
- Violaciones de la convención de contracción → Problema B-6. Violaciones del convenio de Einstein
- Reconstrucción a partir de componentes → Problema B-7. Reconstruir un tensor a partir de sus componentes
- Producto tensorial de rangos diferentes → Problema B-8. Producto tensorial de tensores de rango 1 y rango 2
- Demostración de la aditividad del rango → Problema M-3. Adición de rango mediante el producto tensorial
- Tensor de rango 0 y escalar → Problema M-4. \(T^0(V)\) y los escalares
- Práctica de cálculo con producto tensorial → Problema M-5. Desarrollo simple de \(S \otimes T\)
- Dimensión en 3 dimensiones → Problema M-6. Dimensión del espacio tensorial en 3 dimensiones
- Cálculo de componentes de una aplicación bilineal → Problema M-2. Representación en componentes de una aplicación bilineal
- Cálculo de un tensor tipo matriz identidad → Problema M-8. Evaluación de la forma bilineal identidad
- Descomposición en tensores simétricos y antisimétricos → Problema A-1. Descomposición simétrica y antisimétrica
- Espacio dual y producto tensorial → Problema A-2. Representación tensorial mediante el espacio dual
Referencias¶
- 石井俊全『一般相対性理論を一歩一歩数式で理解する』第 6–7 章(テンソルの基礎・直線座標のテンソル場)
- B. Schutz, A First Course in General Relativity, 3rd ed., Chapter 3(Tensor Analysis in Special Relativity)
- T. Lancaster & S. J. Blundell, General Relativity for the Gifted Amateur, Chapter 2(Vectors and Tensors)
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.