Capítulo 4 Matemáticas del espacio-tiempo de Minkowski — Métrica, 4-vectores y tensores¶
Resumen de los capítulos anteriores: En Cap. 3, a partir del principio de relatividad y el principio de invariancia de la velocidad de la luz, dedujimos el intervalo espacio-temporal \(ds^2 = -(cdt)^2 + dx^2 + dy^2 + dz^2\), y obtuvimos la transformación de Lorentz como la transformación de coordenadas que preserva \(ds^2\). De ahí extrajimos consecuencias físicas como la relatividad de la simultaneidad, la dilatación del tiempo y la contracción de longitudes, completando así la "física" de la relatividad especial. Sin embargo, para avanzar hacia la relatividad general, necesitamos reescribir esta física en expresiones matemáticas independientes del sistema de coordenadas.
Objetivo de este capítulo
- Organizar la física de la relatividad especial obtenida en Cap. 3 con el lenguaje matemático necesario para avanzar hacia la relatividad general
- Concretamente, introducir el sistema de unidades naturales (\(c = 1\)), la notación de índices y la convención de suma de Einstein, la métrica de Minkowski \(\eta_{\mu\nu}\), los 4-vectores (contravariantes y covariantes), y los fundamentos de los tensores
- Con esto, quedará preparado el terreno para tratar "espacio-tiempos curvos"
4.1 Espacio-tiempo de Minkowski y tensor métrico¶
🟡 Lina: En la sección 3 de Cap. 3 dije que "los tensores de rango 1 (4-vectores) los dejamos para después", ¿recuerdas? Como ya resolvimos la transformación de Lorentz y sus consecuencias físicas, es hora de continuar con la jerarquía tensorial — tensores de rango 1 (4-vectores) y tensores de rango 2 (la métrica \(\eta_{\mu\nu}\)). Primero, como preparación, introduzcamos el sistema de unidades naturales y la notación de índices. Pero antes, confirmemos la visión general del espacio-tiempo de Minkowski en Fig. 4.1「Cono de luz del espacio-tiempo de Minkowski」.
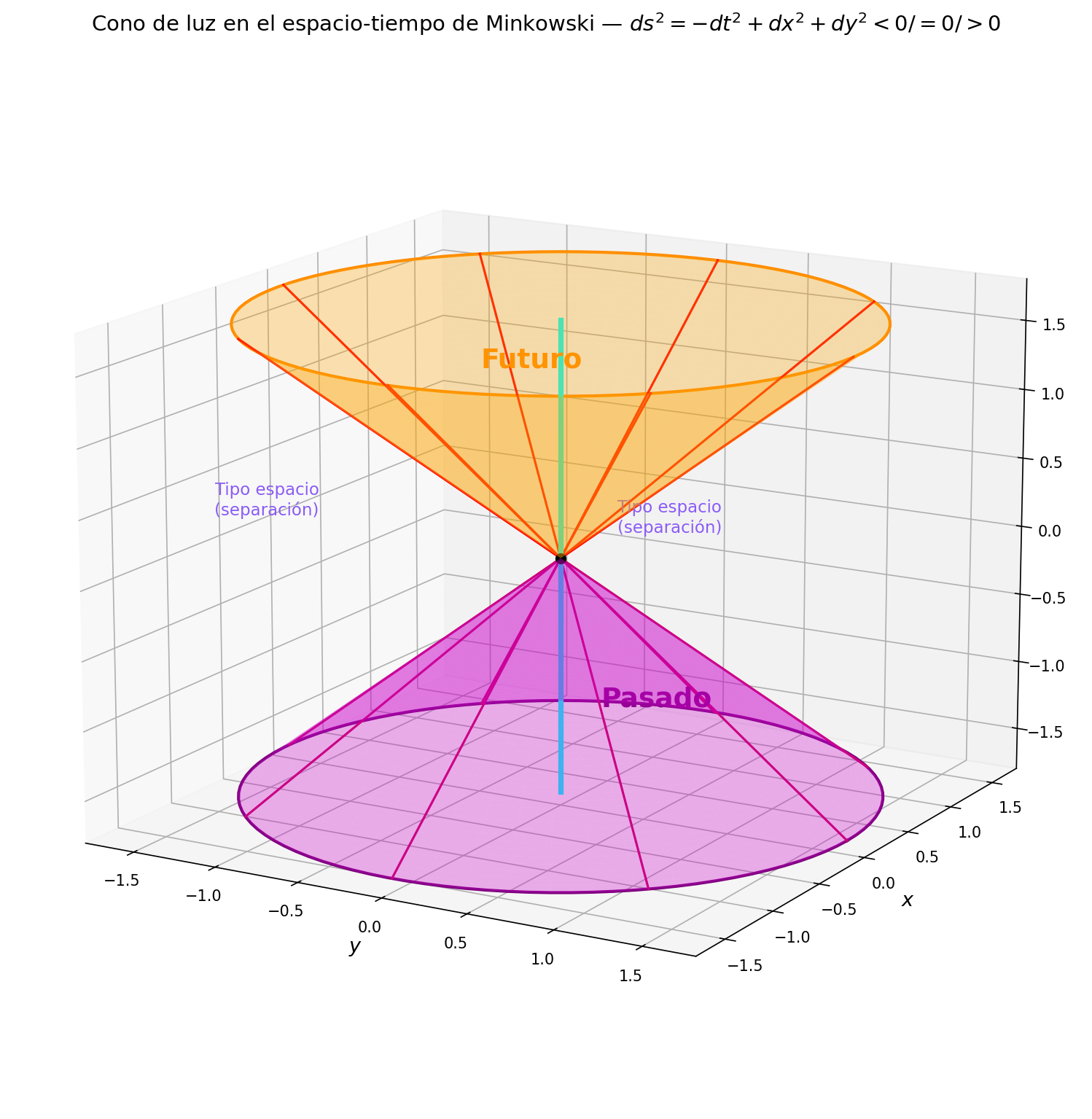
Fig. 4.1: Cono de luz del espacio-tiempo de Minkowski. Desde cada evento, el interior del cono formado por los rayos de luz corresponde al futuro y pasado (conectables temporalmente), y el exterior es espacial (causalmente separado). El signo de \(ds^2 = -(c\,dt)^2 + dx^2 + dy^2 + dz^2\) (en este capítulo, con \(c = 1\): \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2\)) determina la región (\(< 0\): temporal, \(= 0\): luminoso, \(> 0\): espacial). La línea azul es la línea de universo de una partícula material (siempre contenida dentro del cono de luz).
🔵 Kai: Viendo Fig. 4.1「Cono de luz del espacio-tiempo de Minkowski」, el interior del cono de luz es "causalmente conectable" y el exterior está "causalmente separado"… es decir, como la información no puede viajar más rápido que la luz, no podemos influir en eventos fuera del cono de luz.
🟡 Lina: Exacto. Y la línea de universo de una partícula material (la línea azul en la figura) siempre queda dentro del cono de luz — porque no puede superar la velocidad de la luz. El signo de \(ds^2\) expresa matemáticamente esta estructura — si \(ds^2 < 0\) es temporal (interior del cono de luz), si \(ds^2 = 0\) es luminoso (superficie del cono de luz), si \(ds^2 > 0\) es espacial (exterior del cono de luz).
Sistema de unidades con \(c = 1\) (unidades naturales)¶
🟡 Lina: De aquí en adelante, para hacer las fórmulas más legibles, usaremos el sistema de unidades con \(c = 1\). Este es un tipo de unidades naturales (natural units), donde al fijar la velocidad de la luz \(c\) en 1, tratamos el tiempo y el espacio con las mismas unidades.
🔵 Kai: ¿Qué significa hacer la velocidad de la luz igual a 1?
🟡 Lina: Se mide el tiempo en "metros". "1 metro de tiempo" es el tiempo que tarda la luz en recorrer 1 metro — es decir, \(1/c \approx 3.3\) nanosegundos. Entonces
Inversamente, si medimos el tiempo en segundos y la longitud en "segundos-luz" (la distancia que recorre la luz en 1 segundo \(\approx 3 \times 10^8\) m), también obtenemos \(c = 1\). En esencia, se trata de medir el tiempo y la longitud con las mismas unidades.
⚪ Mei: ¿Cómo se reescriben concretamente las fórmulas?
✅ Verificación de comprensión: ¿Qué es el sistema de unidades naturales (\(c = 1\))? ¿Y cuál es su ventaja?
Respuesta
Es un sistema de unidades donde se fija la velocidad de la luz \(c\) en 1, tratando el tiempo y el espacio con las mismas unidades. Los factores de \(c\) desaparecen de las fórmulas haciéndolas más simples, y la ventaja es que "no hay que preocuparse por dónde colocar \(c\)". Cuando se quiere volver a unidades SI, basta restaurar \(c\) mediante análisis dimensional.
🟡 Lina: Veamos algunos ejemplos.
Tabla 4.1: Comparación de fórmulas físicas en unidades SI y unidades naturales
| Unidades SI | Unidades naturales (\(c=1\)) |
|---|---|
| \(E = mc^2\) | \(E = m\) |
| \(\tau = t\sqrt{1 - v^2/c^2}\) | \(\tau = t\sqrt{1 - v^2}\) |
| \(\gamma = 1/\sqrt{1 - v^2/c^2}\) | \(\gamma = 1/\sqrt{1 - v^2}\) |
| \(ds^2 = -c^2 dt^2 + dx^2 + dy^2 + dz^2\) | \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2\) |
| \(v/c\) (velocidad adimensional) | \(v\) (velocidad en unidades de la velocidad de la luz, \(0 \le v \le 1\)) |
🔵 Kai: ¿La energía y la masa se convierten en la misma cantidad?
🟡 Lina: Así es. La energía en reposo de una masa \(m\) kg es \(E = mc^2\) julios, pero en unidades naturales es simplemente \(E = m\). Puedes pensar que tanto la masa como la energía se miden con las mismas unidades (por ejemplo, kg, o eV).
💡 Consejo para acostumbrarte: "Medir la masa en kg y la energía también en kg" puede confundir al principio. Pero si adoptas la perspectiva de que "la energía y la masa son esencialmente lo mismo (intercambiables por \(E=mc^2\))", es una elección natural. En física de partículas, al contrario, tanto la masa como la energía se miden en eV; por ejemplo, se escribe "la masa del electrón es 511 keV" (estrictamente \(511\ \mathrm{keV}/c^2\), pero en unidades naturales se omite \(c\)). En cálculos de relatividad, la mayor ventaja es "no tener que preocuparse por las unidades".
⚪ Mei: Es decir, cuando queramos volver a unidades SI, basta con restaurar \(c\) mediante análisis dimensional.
🟡 Lina: Exacto. Por ejemplo, si \(E = m\), para igualar la dimensión de la energía \([\text{kg}\cdot\text{m}^2/\text{s}^2]\) con la dimensión de la masa \([\text{kg}]\), multiplicamos por \(c^2\) (dimensión \([\text{m}^2/\text{s}^2]\)) y recuperamos \(E = mc^2\). Las unidades naturales tienen la ventaja de que "no hay que preocuparse por dónde colocar \(c\)". Al escribir las fórmulas, las escribimos de forma simple con \(c = 1\), y al final, si necesitamos valores numéricos en unidades SI, restauramos \(c\) por análisis dimensional. En cálculos de relatividad, esta convención es estándar.
Sistemas de unidades relacionados
- Unidades naturales (natural units): \(c = 1\). Se usan en relatividad. Adoptadas en este capítulo.
- Unidades geometrizadas (geometrized units): \(G = c = 1\). También se fija la constante de gravitación universal de Newton en 1. En relatividad general se usan frecuentemente a partir de Cap. 8.
- Unidades de Planck (Planck units): \(G = c = \hbar = 1\). Se usan en gravedad cuántica (aparecen en Cap. 25).
- Unidades naturales de física de partículas: \(\hbar = c = 1\). Se usan en mecánica cuántica y teoría cuántica de campos.
En este libro indicaremos al inicio de cada capítulo "el sistema de unidades de este capítulo", así que presta atención para no confundirte.
🟡 Lina: En unidades naturales, la transformación de Lorentz se escribe de forma limpia:
Y el intervalo espacio-temporal:
En los capítulos siguientes, salvo que se indique lo contrario, usaremos unidades naturales (\(c = 1\)). A veces cambiaremos a unidades geometrizadas (\(G = c = 1\)), así que verifica "el sistema de unidades de este capítulo" al inicio de cada uno.
📝 Ejercicios:
- Conversión a unidades naturales y restauración de \(c\) → Problema B-1. Conversión al sistema de unidades naturales y restauración de \(c\), Problema B-2. Tiempo y longitud en unidades naturales
Numeración de coordenadas¶
🟡 Lina: Ahora introduzcamos una notación para manejar las 4 coordenadas de forma conjunta.
Los números en superíndice no son potencias sino índices (index). Las 4 coordenadas se escriben conjuntamente como \(x^\mu\) (\(\mu = 0, 1, 2, 3\)). ¿Por qué en superíndice? Porque, como aprenderemos más adelante, hay dos tipos de índices — "superíndices" y "subíndices" — y cada uno se transforma de manera diferente. El desplazamiento infinitesimal de coordenadas \(dx^\mu\) es una cantidad que se transforma multiplicando por \(\Lambda\) en la transformación de Lorentz, y este tipo de cantidad se llama "vector contravariante" y se escribe con índice superior por convención — por eso la posición natural de las coordenadas es con índice arriba. El significado preciso de "vector contravariante" se definirá en la sección 2, así que por ahora solo recuerda que "las coordenadas se escriben con índice superior".
🔵 Kai: ¿No es confuso que \(x^2\) pueda ser "\(x\) al cuadrado" o "la coordenada \(y\)"?
🟡 Lina: Al principio es confuso, pero con el contexto aprenderás a distinguirlos. Te doy un truco — cuando se usa como índice, la pista es que aparece una letra griega como \(\mu, \nu, \alpha, \beta, \ldots\) junto a \(x^\mu\). Cuando aparece un número directamente (como \(x^2\)), si el contexto es "listar componentes de coordenadas" es un índice, y si es "en medio de un cálculo" es una potencia. En este libro, cuando pueda haber confusión con potencias, a veces escribiremos \((x)^2\) o \(x^2\) (sin cursiva) para distinguirlos.
Convención de notación: - Los índices con letras griegas (\(\mu, \nu, \alpha, \beta, \ldots\)) recorren \(0, 1, 2, 3\) y se refieren a las 4 componentes espacio-temporales - Los índices con letras latinas (\(i, j, k, \ldots\)) recorren \(1, 2, 3\) y se refieren solo a las 3 componentes espaciales
Convención de suma de Einstein¶
🟡 Lina: Ahora que hemos introducido la notación de índices, voy a presentar la convención de notación más importante para aprender relatividad general.
Convención de suma de Einstein (Einstein summation convention): Dentro de un mismo término, si el mismo índice aparece una vez arriba y una vez abajo, se suma sobre ese índice de 0 a 3. Se omite el símbolo de suma \(\sum\).
🔵 Kai: ¿Qué significa concretamente?
🟡 Lina: Empecemos con el ejemplo más simple. Si tenemos un 4-vector \(A^\mu = (A^0, A^1, A^2, A^3)\), al sustituir valores concretos en el índice \(\mu\) obtenemos cada componente. Ahora, si multiplicamos \(A^\mu\) (índice superior) por otra cantidad \(B_\mu\) (índice inferior) y escribimos \(A^\mu B_\mu\), ¿qué pasa? Habrás notado que el índice de \(B_\mu\) está abajo. La definición precisa de \(B_\mu\) se introducirá en la sección 3, pero por ahora piensa que es "otro tipo de cantidad con 4 componentes, también un conjunto de 4 números \((B_0, B_1, B_2, B_3)\)" — por ejemplo, \(B_\mu = (5, 2, 0, 3)\), simplemente 4 números alineados, está bien. La razón por la que distinguimos entre superíndices y subíndices se entenderá después, así que por ahora solo recuerda la regla "si el mismo índice aparece arriba y abajo, se suma". Si lo expandimos explícitamente, dado que \(\mu\) aparece arriba (en \(A^\mu\)) y abajo (en \(B_\mu\)) una vez cada uno, sustituimos \(\mu = 0, 1, 2, 3\) y sumamos:
Una suma de 4 términos. ¿Ves que sin escribir \(\sum\), solo con la posición de los índices ya se sabe que "hay que sumar"?
🔵 Kai: ¡Oh, es simplemente omitir \(\sum_{\mu=0}^{3}\)!
🟡 Lina: Así es. Veamos otro ejemplo. Si escribimos la transformación de Lorentz en notación de índices: \(x^{\mu'} = \Lambda^{\mu'}{}_{\nu}\,x^\nu\). Aquí \(x^{\mu'}\) es la coordenada del sistema inercial \(S'\) después de la transformación, y el primo (\('\)) en el índice indica que es "una cantidad del sistema \(S'\)". \(x^\nu\) es la coordenada del sistema inercial original \(S\). \(\Lambda^{\mu'}{}_{\nu}\) es la componente de la fila \(\mu'\), columna \(\nu\) de la matriz de transformación — el superíndice \(\mu'\) representa "el número de componente del destino (sistema \(S'\))" y el subíndice \(\nu\) representa "el número de componente del origen (sistema \(S\))". Como \(\nu\) aparece arriba (en \(x^\nu\)) y abajo (en \(\Lambda^{\mu'}{}_{\nu}\)) una vez cada uno, por la convención de suma se toma la suma:
⚪ Mei: En ambos ejemplos se suma sobre un índice obteniendo 4 términos — el mismo patrón.
🟡 Lina: Exacto. Y esta estructura de "multiplicar componente a componente y sumar" es la misma forma que el producto escalar que aprendiste en el instituto. La contracción con un solo índice es, en esencia, la misma operación que el producto escalar.
🔵 Kai: Entonces es como una generalización del producto escalar.
🟡 Lina: Exacto. Ahora, usando una cantidad con 2 índices — el tensor métrico \(\eta_{\mu\nu}\) — reescribamos el intervalo espacio-temporal.
✅ Verificación de comprensión: ¿Qué es la convención de suma de Einstein?
Respuesta
Dentro de un mismo término, si el mismo índice aparece una vez arriba y una vez abajo, se suma sobre ese índice de 0 a 3. Se omite el símbolo de suma \(\sum\).
Organización de terminología: El índice sobre el cual se suma por la convención (el mismo carácter que aparece arriba y abajo) se llama índice mudo (dummy index). El índice mudo da el mismo resultado independientemente de qué letra se use. Por ejemplo, \(A^\mu B_\mu = A^\nu B_\nu\). Por otro lado, un índice que no se suma se llama índice libre (free index).
Métrica de Minkowski \(\eta_{\mu\nu}\)¶
🟡 Lina: Ahora quiero reescribir el intervalo espacio-temporal en notación de índices. \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2\) contiene los desplazamientos infinitesimales de 4 coordenadas, y si podemos escribir esto como \(ds^2 = \eta_{\mu\nu}\,dx^\mu\,dx^\nu\) de un solo golpe, podremos usar la misma forma sin importar cuántas coordenadas haya. Para eso necesitamos el concepto de "métrica" (metric). Primero captemos la intuición.
🔵 Kai: ¿Qué es la métrica?
🟡 Lina: En una palabra, es una "regla de medir" — una herramienta que nos dice "cómo medir la distancia entre 2 puntos" en un espacio (o espacio-tiempo). Veámoslo paso a paso con 3 ejemplos. Primero, resumo la visión general en Fig. 4.2「Tres ejemplos de métrica. Izquierda: plano (la métrica es constante \(\mathrm{diag}(1,1)\)). Centro: esfera (la métrica es función de la coordenada \(\theta\)」.
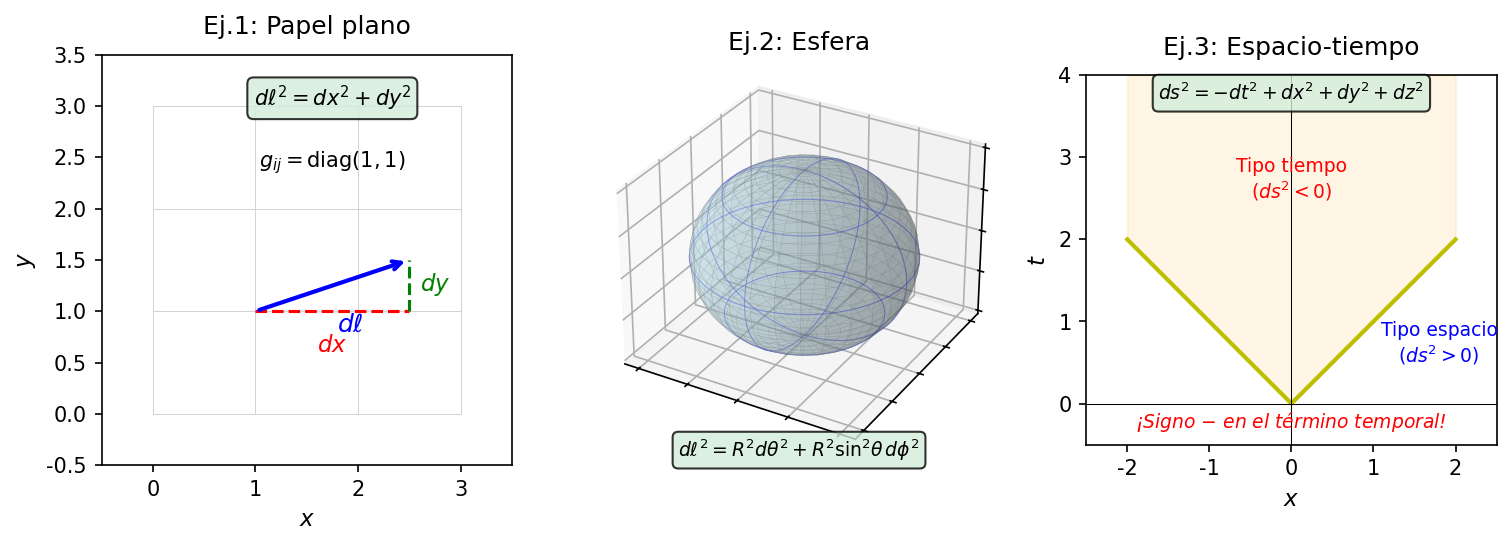
Fig. 4.2: Tres ejemplos de métrica. Izquierda: plano (la métrica es constante \(\mathrm{diag}(1,1)\)). Centro: esfera (la métrica es función de la coordenada \(\theta\) — la "escala de la regla" cambia según el lugar). Derecha: espacio-tiempo (el término temporal lleva signo negativo, con una estructura diferente a la geometría euclídea).
Ejemplo 1: Sobre una hoja plana¶
En un plano ordinario, la distancia entre 2 puntos se determina por el teorema de Pitágoras:
La información de que "delante de \(dx^2\) hay un 1, delante de \(dy^2\) hay un 1, sin términos cruzados" es la métrica del plano. Escrita como matriz:
La matriz identidad — esta es la métrica del "espacio plano".
Ejemplo 2: La superficie de la Tierra (superficie curva)¶
🟡 Lina: Ahora consideremos la superficie de la Tierra (centro de Fig. 4.2「Tres ejemplos de métrica. Izquierda: plano (la métrica es constante \(\mathrm{diag}(1,1)\)). Centro: esfera (la métrica es función de la coordenada \(\theta\)」). Para especificar una posición en la Tierra, usamos dos ángulos. El primero es el ángulo polar \(\theta\) (theta) — medido desde el polo norte como \(\theta = 0\) hacia el sur. El polo norte es \(\theta = 0\) (= 0°), el ecuador es \(\theta = \pi/2\) (= 90°), el polo sur es \(\theta = \pi\) (= 180°). En geografía, la "latitud" se toma desde el ecuador como 0° con norte positivo y sur negativo, pero el ángulo polar en física empieza en el polo norte y crece hacia el sur — la dirección es opuesta, así que ten cuidado. El segundo es la longitud \(\phi\) (fi) — el ángulo en dirección este-oeste, que va de \(0\) a \(2\pi\) (= 360°). La dirección es la misma que la longitud geográfica (\(-180°\) a \(+180°\)), pero el punto inicial y el rango son ligeramente diferentes. Usando estos dos ángulos, la distancia infinitesimal sobre la superficie terrestre es
¿Por qué es así? Intuitivamente — al moverse \(d\theta\) en dirección latitudinal (norte-sur), se avanza \(R\,d\theta\) a lo largo de un gran círculo (el círculo de la sección que pasa por el centro de la Tierra) de radio \(R\). Al moverse \(d\phi\) en dirección longitudinal (este-oeste), el radio del "pequeño círculo" (círculo de paralelo) a esa latitud es \(R\sin\theta\), por lo que se avanza \(R\sin\theta\,d\phi\). ¿Por qué \(R\sin\theta\)? Porque la distancia desde el eje de rotación de la Tierra hasta el círculo de paralelo es \(R\sin\theta\) — en el polo norte (\(\theta = 0\)), \(\sin 0 = 0\) y el radio es cero (un punto); en el ecuador (\(\theta = \pi/2\)), \(\sin(\pi/2) = 1\) y el radio es \(R\) (máximo). Y estas dos direcciones (norte-sur y este-oeste) son mutuamente perpendiculares sobre la esfera — si miras un globo terráqueo, los meridianos y los paralelos siempre se cruzan en ángulo recto. En una región infinitesimal, una superficie curva puede considerarse plana (igual que la superficie de la Tierra parece plana localmente), así que aplicando el teorema de Pitágoras a los desplazamientos infinitesimales en dos direcciones ortogonales:
🔵 Kai: Un momento. ¿Por qué \(R\sin\theta\) es el radio del círculo de paralelo? El radio de la Tierra es \(R\), ¿por qué aparece \(\sin\theta\)?
🟡 Lina: Buena pregunta. Imagina una sección transversal de la Tierra. La distancia horizontal desde el eje de rotación hasta el círculo de paralelo es, por trigonometría, \(R\sin\theta\) — en el polo norte (\(\theta = 0\)) está sobre el eje, distancia cero; en el ecuador (\(\theta = \pi/2\)) está lo más alejado posible del eje, distancia \(R\). Es decir, \(\sin\theta\) representa la proporción de "cuánto se está alejado del eje de rotación".
🔵 Kai: Ah, ya veo. Entonces, como \(\sin^2\theta\) está presente, la "distancia por grado" en dirección longitudinal cambia según el lugar. Cerca del ecuador (\(\theta \approx \pi/2\)), \(\sin^2\theta \approx 1\) y es grande, pero cerca del polo (\(\theta \approx 0\)), \(\sin^2\theta \approx 0\) y es casi cero.
🟡 Lina: Exacto. La "escala de la regla" cambia según el lugar — esto es lo que significa que la métrica sea una función de las coordenadas \(g_{ij}(\theta)\).
A diferencia de la matriz identidad del ejemplo 1, las componentes diagonales dependen del lugar (\(\theta\)).
🔵 Kai: La métrica del plano es una matriz constante, y la métrica de la esfera es una función de las coordenadas… ¿entonces se puede saber si algo es "plano" o "curvo" según si la métrica depende de las coordenadas o no?
🟡 Lina: Buena observación, pero en realidad no es tan simple. Incluso en un plano, si usamos coordenadas polares \((r, \theta)\), la métrica es \(d\ell^2 = dr^2 + r^2 d\theta^2\), que es función de las coordenadas. "Métrica dependiente de coordenadas = curvado" no es necesariamente cierto. Para determinar si algo está realmente curvado, se necesita una herramienta más precisa (el tensor de curvatura, que aparece en Cap. 12). Pero en esta etapa, la intuición de "métrica no constante → posiblemente curvado" es suficiente.
Ejemplo 3: Espacio-tiempo¶
🟡 Lina: Y el espacio-tiempo (derecha de Fig. 4.2「Tres ejemplos de métrica. Izquierda: plano (la métrica es constante \(\mathrm{diag}(1,1)\)). Centro: esfera (la métrica es función de la coordenada \(\theta\)」). El intervalo espacio-temporal que dedujimos en la sección 2 de Cap. 3:
también puede escribirse con una métrica. Si fuera solo espacio, todo sería positivo, pero el término temporal lleva un signo negativo. Esta es la esencia de que "el espacio-tiempo posee una geometría diferente al espacio ordinario", y es la conclusión que derivamos de la invariancia de la velocidad de la luz en la sección 2.3 de Cap. 3.
🔵 Kai: Es decir, la métrica no solo determina "cómo medir distancias", sino que representa las propiedades del espacio en sí.
🟡 Lina: Exactamente. Y en relatividad general, esta métrica se convierte en \(g_{\mu\nu}(x)\) que varía según el lugar — la misma estructura que cuando \(\sin^2\theta\) variaba según el lugar en la superficie de la Tierra. El papel que en Newton desempeña el potencial gravitatorio \(\Phi\), en relatividad general lo asume el tensor métrico \(g_{\mu\nu}\). La métrica es simultáneamente una "regla de medir" y "el campo gravitatorio en sí" — esta es la idea central de la relatividad general. Pero eso es para más adelante. Primero escribamos la métrica del espacio-tiempo plano en notación de índices.
⚪ Mei: En los 3 ejemplos la dificultad fue aumentando gradualmente — una métrica constante, una métrica dependiente de coordenadas, y una métrica con signos mezclados.
🟡 Lina: Así es. Y en relatividad especial tratamos el tercer caso — signos mezclados pero constante. Reescribamos el intervalo espacio-temporal en notación de índices usando la convención de suma. \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2\) se puede escribir como
Aquí \(\eta_{\mu\nu}\) (eta) es una cantidad llamada métrica de Minkowski (Minkowski metric), cuyas componentes ordenadas como matriz \(4 \times 4\) son:
🔵 Kai: \(\eta_{\mu\nu}\,dx^\mu\,dx^\nu\), como \(\mu\) y \(\nu\) recorren cada uno de 0 a 3… ¿es una suma de 16 términos en total?
🟡 Lina: Sí. Mira bien la expresión \(\eta_{\mu\nu}\,dx^\mu\,dx^\nu\) — la letra \(\mu\) aparece 2 veces, ¿verdad? La primera vez dentro de \(\eta_{\mu\nu}\) como subíndice, la segunda vez en \(dx^\mu\) como superíndice. Como aparece una vez arriba y una vez abajo, por la convención de suma se toma la suma con \(\mu = 0, 1, 2, 3\). Lo mismo para \(\nu\): está como subíndice en \(\eta_{\mu\nu}\) y como superíndice en \(dx^\nu\) — así que también se suma. El resultado es una suma doble sobre \(\mu\) y \(\nu\) con \(4 \times 4 = 16\) términos. Pero \(\eta_{\mu\nu}\) es una matriz diagonal — es decir, todas las componentes donde el número de fila y columna son diferentes (\(\mu \neq \nu\)) son cero. Por ejemplo, \(\eta_{01} = 0\), \(\eta_{12} = 0\), etc. Así que de los 16 términos, los 12 con \(\mu \neq \nu\) se anulan, y solo quedan los 4 con \(\mu = \nu\):
🔵 Kai: ¡Oh, 12 términos se anulan de golpe y solo quedan 4! Con una matriz diagonal todo es sencillo.
⚪ Mei: Es decir, con la sola expresión \(\eta_{\mu\nu}\,dx^\mu\,dx^\nu\) queda determinado "qué signo se pone al cuadrado de cada componente" — basta especificar la métrica para que la fórmula del intervalo espacio-temporal salga automáticamente.
🟡 Lina: Exacto. Este \(\eta_{\mu\nu}\) es la "regla de medir" del espacio-tiempo de Minkowski — el tensor métrico. En relatividad general, este se reemplaza por \(g_{\mu\nu}(x)\) que varía según el lugar. Esa es la expresión matemática de que "el espacio-tiempo se curva".
📝 Ejercicios:
- Producto interno de Minkowski, convención de suma, notación de índices → Problema B-3. Cálculo del producto interno de Minkowski, Problema B-4. Componentes del vector covariante, Problema B-5. Expansión en 16 términos del intervalo espaciotemporal, Problema B-6. Reetiquetado de índices mudos
Convenciones de notación de este libro
Hasta aquí han aparecido varios símbolos, así que vamos a organizarlos. Está diseñado para que por el tipo de letra se pueda distinguir si es un 4-vector o una matriz (tensor), y si es 3-dimensional o 4-dimensional.
| Tipo | Símbolo | Ejemplo |
|---|---|---|
| 4-vector (índice griego \(\mu,\nu,\ldots\)) | Mayúscula latina | \(A^\mu\), \(B_\mu\), \(V^\mu\), \(U^\mu\) (4-velocidad) |
| Tensor de rango 2 (métrica) | Minúscula griega | \(\eta_{\mu\nu}\), \(g_{\mu\nu}\) |
| Tensor de rango 2 o superior (otros) | Mayúscula latina | \(T^{\mu\nu}\), \(R_{\mu\nu\rho\sigma}\) |
| Matriz de transformación | Mayúscula griega | \(\Lambda^{\mu'}{}_{\nu}\) (transformación de Lorentz) |
| Coordenadas y desplazamientos | Minúsculas tradicionales | \(x^\mu\), \(dx^\mu\) |
| Vector 3-dimensional | Minúscula + flecha | \(\vec{v}\), \(\vec{r}\), \(\vec{p}\), \(\vec{F}\) |
| Componentes de vector 3D (índice latino \(i,j = 1,2,3\)) | Minúscula | \(v^i\), \(v^x\), \(v^y\), \(v^z\) |
En resumen, "4-vectores en mayúscula, métrica en minúscula griega, 3D con flecha". Pero hay una excepción — el 4-momento \(p^\mu\) se escribe en minúscula por convención histórica. Como se escribe así universalmente en los libros de física, lo adoptamos tal cual.
4.2 4-vectores¶
¿Por qué necesitamos 4-vectores?¶
🟡 Lina: En la mecánica de Newton, la posición \((x, y, z)\) y la velocidad \((v_x, v_y, v_z)\) eran vectores de 3 componentes. Pero en relatividad especial, el tiempo y el espacio se mezclan. Por eso, las magnitudes físicas deben representarse como vectores de 4 componentes que incluyen la componente temporal — 4-vectores (four-vectors).
🔵 Kai: ¿Concretamente, qué tipo de cosas son?
4-vector desplazamiento¶
🟡 Lina: El 4-vector más básico es el desplazamiento infinitesimal entre dos eventos:
Cómo cambia esto bajo una transformación de Lorentz, escrito en notación de índices (representación por componentes):
🔵 Kai: ¿Esto es diferente de una ecuación matricial?
🟡 Lina: Sí. Esto no es la matriz en sí, sino una expresión que representa una componente particular. \(\mu'\) representa abstractamente un número de componente (alguno de 0, 1, 2, 3); por ejemplo, si sustituyes \(\mu' = 0\) obtienes la ecuación para \(dt'\), si sustituyes \(\mu' = 1\) obtienes la ecuación para \(dx'\). Con una sola ecuación se escriben las 4 componentes de forma conjunta.
🟡 Lina: Aquí \(\Lambda\) (lambda) es la matriz de la transformación de Lorentz, y \(\Lambda^{\mu'}{}_{\nu}\) es su componente \((\mu', \nu)\). Para un boost en la dirección \(x\) con velocidad \(v\):
🟡 Lina: Intenta calcular la componente \(\mu' = 0\). Por la convención de suma, se suma sobre \(\nu\) —
🔵 Kai: Veamos, sustituyendo \(\nu = 0, 1, 2, 3\) y sumando… \(\Lambda^{0'}{}_{0}\,dx^0 + \Lambda^{0'}{}_{1}\,dx^1 + \Lambda^{0'}{}_{2}\,dx^2 + \Lambda^{0'}{}_{3}\,dx^3\). Poniendo las componentes de la matriz, ¿\(\gamma\,dt - \gamma v\,dx\)?
⚪ Mei: Es decir, \(dt' = \gamma(dt - v\,dx)\) — coincide con la transformación de Lorentz de antes.
Definición de 4-vector¶
🟡 Lina: Como acabamos de ver, \(dx^\mu\) se mezcla bajo la transformación de Lorentz según \(dx^{\mu'} = \Lambda^{\mu'}{}_{\nu}\,dx^\nu\). Resulta que entre las magnitudes que aparecen en la física, hay muchas otras que se mezclan exactamente de la misma manera que \(dx^\mu\) — velocidad, momento, densidad de corriente…. Por eso, es conveniente dar un nombre colectivo a las cantidades que comparten esta "regla de mezcla".
🔵 Kai: ¿"Mezclarse de la misma manera" qué significa concretamente?
🟡 Lina: Si tenemos un conjunto de 4 cantidades \(V^\mu = (V^0, V^1, V^2, V^3)\), y al cambiar de sistema inercial de \(S\) a \(S'\), usando la matriz de transformación \(\Lambda\) (lambda), se puede escribir:
es decir, se transforma con la misma matriz \(\Lambda\) que \(dx^\mu\). Las cantidades con esta propiedad se llaman vectores contravariantes (contravariant vectors). El propio \(dx^\mu\) es el primer ejemplo de vector contravariante.
🔵 Kai: ¿Pueden desglosarme un poco más esta ecuación?
🟡 Lina: Claro. Analicemos \(V^{\mu'} = \Lambda^{\mu'}{}_{\nu}\,V^\nu\). Como \(\nu\) aparece arriba (en \(V^\nu\)) y abajo (en \(\Lambda^{\mu'}{}_{\nu}\)), por la convención de suma de la sección 1.3, se toma la suma. Es decir, esta ecuación es la forma abreviada de:
Una suma de 4 términos. Si sustituyes un valor concreto (0, 1, 2, 3) en \(\mu'\), obtienes cada componente en el sistema \(S'\).
🔵 Kai: Es la misma estructura que cuando Mei calculó \(dx^{0'} = \gamma\,dt - \gamma v\,dx\) antes.
🟡 Lina: Exacto. Intuitivamente, esta ecuación dice "las componentes del sistema \(S\), \(V^0, V^1, V^2, V^3\), se mezclan según la regla de conversión \(\Lambda\) para producir la componente \(V^{\mu'}\) del sistema \(S'\)". Es la misma estructura que cuando un vector 3-dimensional se rota: \((v_x, v_y, v_z)\) se mezcla con la matriz de rotación. Los valores numéricos de las componentes cambian, pero el vector en sí (su contenido físico) no cambia.
🔵 Kai: Entonces, ¿si las componentes \(V^{\mu'}\) calculadas multiplicando por \(\Lambda\) coinciden con los valores realmente medidos en el sistema \(S'\), es un vector contravariante?
🟡 Lina: Exactamente así. Si tienes un conjunto de 4 números, el cálculo de multiplicar por \(\Lambda\) siempre se puede hacer. Pero no está garantizado que el resultado coincida con el valor correcto en el sistema \(S'\). De hecho, hay cantidades cuyas componentes cambian en la "misma dirección" que la transformación de coordenadas, y otras que cambian en la "dirección opuesta" — esta es la distinción entre "vector covariante" y "vector contravariante", que se trata en detalle en la sección 3. Por ahora, solo recuerda que "índice superior (contravariante) e índice inferior (covariante) se transforman de forma opuesta".
🔵 Kai: Entonces "si al multiplicar por \(\Lambda\) sale la respuesta correcta" es el criterio para saber si algo es un vector contravariante.
🟡 Lina: Exacto. Las cantidades que se transforman con la matriz inversa de \(\Lambda\) (índice inferior \(V_\mu\)) se llaman vectores covariantes (covariant vectors). El origen de los nombres es co = "junto con", contra = "en contra de". ¿"Junto con" o "en contra de" qué? — respecto al cambio de escala de las coordenadas. En una transformación que hace la escala más grande, si las componentes también se hacen más grandes es covariante (co = cambian juntas), y si las componentes se hacen más pequeñas es contravariante (contra = cambian en sentido opuesto). Capta la intuición con el siguiente ejemplo concreto. El ejemplo representativo de vector covariante es el gradiente — la derivada parcial de un campo escalar (por ejemplo, una cantidad como el potencial gravitatorio \(\Phi\) que tiene un valor definido en cada punto del espacio-tiempo): \(\partial\Phi/\partial x^\mu\) resulta ser un vector covariante. Esto se derivará formalmente en capítulos posteriores, pero por ahora recuerda solo que "el desplazamiento \(dx^\mu\) es el representante contravariante, y el gradiente es el representante covariante". Intuitivamente — piensa en una transformación que estira la escala de coordenadas al doble.
Te doy un ejemplo concreto. Imagina una recta numérica. En 1 dimensión, la longitud de una barra es \(\Delta x = 3\) marcas en las coordenadas originales. Estiramos el intervalo entre marcas al doble — es decir, una nueva marca corresponde a la longitud física de 2 marcas originales. La posición física no ha cambiado, pero como las marcas se hicieron más grandes, al leer la misma posición en las nuevas coordenadas el valor numérico se reduce a la mitad — en coordenadas, \(x' = x/2\). Entonces, midiendo la misma barra de nuevo, \(\Delta x' = 3/2 = 1.5\) marcas — al hacerse las marcas más grandes, el valor numérico del desplazamiento se redujo a la mitad. La base (vector unitario de la escala) se hace "más grande" en la transformación, pero la componente del desplazamiento se hace "más pequeña". Esto es lo que significa "contravariante = cambia en dirección opuesta a la transformación de la base".
🔵 Kai: Ah, cuando la regla se estira, el valor numérico se encoge. Opuesto a la escala, por eso "contravariante".
Por otro lado, piensa en la pendiente de una cuesta (gradiente). En las coordenadas originales, "al avanzar 1 marca, la altura sube 4 m". Si estiramos las marcas al doble, una nueva marca corresponde a la distancia de 2 marcas originales. Así que al "avanzar 1 marca" en las nuevas coordenadas, realmente se ha avanzado 2 marcas originales, por lo que la altura sube \(4 \times 2 = 8\) m — el valor numérico del gradiente se duplica. En una transformación donde las coordenadas se hacen "más grandes", el gradiente también se hace "más grande". Esto es lo que significa "covariante = cambia en la misma dirección que la transformación de coordenadas".
En resumen — ante la misma transformación "estirar la escala al doble", la componente del desplazamiento se reduce a la mitad (dirección opuesta = contravariante), la componente del gradiente se duplica (misma dirección = covariante). La matriz que describe la transformación es diferente (\(\Lambda\) o \(\Lambda^{-1}\)) — esa es la distinción esencial.
🔵 Kai: El ejemplo era en 1 dimensión, ¿pero la misma idea se aplica en el espacio-tiempo de 4 dimensiones?
🟡 Lina: Sí. En 4 dimensiones la esencia es la misma — ante la forma en que cambia la escala de coordenadas (\(\Lambda\)), las componentes que cambian en dirección opuesta son contravariantes, las que cambian en la misma dirección son covariantes. La fórmula de transformación concreta con índices y su uso se verán en detalle en la sección 3; por ahora recuerda solo que "con índice arriba y abajo la forma de transformarse es opuesta". Los vectores contravariantes y covariantes se denominan colectivamente 4-vectores (four-vectors).
%%{init: {"theme": "default", "themeCSS": ".edgePath .path, .flowchart-link { stroke-width: 2px !important; }"}}%%
flowchart TB
all["<b>Conjunto de 4 números</b><br/>Ej: (t, x, m, 0) o cualquier cosa"]
all -->|"Se transforma con Λ o Λ⁻¹"| four["<b>4-vector</b>"]
all -->|"No posee regla de transformación"| not4["No es un 4-vector<br/>Ej: (t, x, m, 0)"]
four --> contra["<b>Vector contravariante</b> Vᵘ (índice superior)<br/>Se transforma con Λ<br/>Ej: dxᵘ, Uᵘ, pᵘ"]
four --> co["<b>Vector covariante</b> V_μ (índice inferior)<br/>Se transforma con Λ⁻¹<br/>Ej: gradiente ∂φ/∂xᵘ"]
style all fill:#f0f0f0,stroke:#666
style four fill:#d1ecf1,stroke:#0c5460
style not4 fill:#ffcccc,stroke:#721c24
style contra fill:#d4edda,stroke:#155724
style co fill:#fff3cd,stroke:#856404🟡 Lina: Como he organizado en Fig. 4.3「Clasificación de los 4-vectores y relación con las reglas de transformación」, quiero enfatizar los puntos importantes. Poner 4 números en fila no los convierte automáticamente en un 4-vector — solo aquellos que siguen la regla de transformación correcta bajo Lorentz son 4-vectores. Y hay 2 tipos de 4-vectores — con índice superior \(V^\mu\) (contravariante) y con índice inferior \(V_\mu\) (covariante).
⚪ Mei: Es decir, lo esencial es si posee o no una regla de transformación, y cuando la posee, se divide en 2 tipos según si se transforma con \(\Lambda\) o con \(\Lambda^{-1}\).
🟡 Lina: Exacto. Por qué hay 2 tipos, y cómo se usan concretamente, lo veremos en detalle en la sección 3. Por ahora concentrémonos primero en los vectores contravariantes que siguen la misma regla de transformación que \(dx^\mu\).
🔍 Dive Deep: "Covariancia" y "vector covariante" tienen significados diferentes
En Cap. 2 llamamos covariancia (covariance) a que "un modelo físico tome la misma forma en todos los sistemas de coordenadas". Por otro lado, el vector covariante (covariant vector) que apareció en esta sección es "una cantidad que se transforma con la matriz inversa de \(\Lambda\)". Es la misma palabra "covariante" pero con significados diferentes.
- Covariancia (covariance): la propiedad de que la forma de las ecuaciones no depende del sistema de coordenadas
- Vector covariante (covariant vector): un tipo de vector que sigue una regla de transformación específica
Es confuso, pero históricamente se llaman así, así que no queda más que acostumbrarse. Lo importante es que tanto los vectores contravariantes como los covariantes son herramientas para escribir "ecuaciones que poseen covariancia".
Veamos ahora ejemplos concretos de vectores contravariantes.
4-velocidad¶
🟡 Lina: Veamos un ejemplo concreto. La 4-velocidad (four-velocity) \(U^\mu\) de una partícula se define como la derivada de la coordenada \(x^\mu\) a lo largo de la línea de universo. Sin embargo, como parámetro de diferenciación no se usa el tiempo coordenado \(t\), sino el tiempo propio (proper time) \(\tau\) (tau).
🔵 Kai: ¿Qué es el tiempo propio?
🟡 Lina: Es el tiempo que marca el reloj que la partícula lleva consigo. Comparémoslo en una figura.
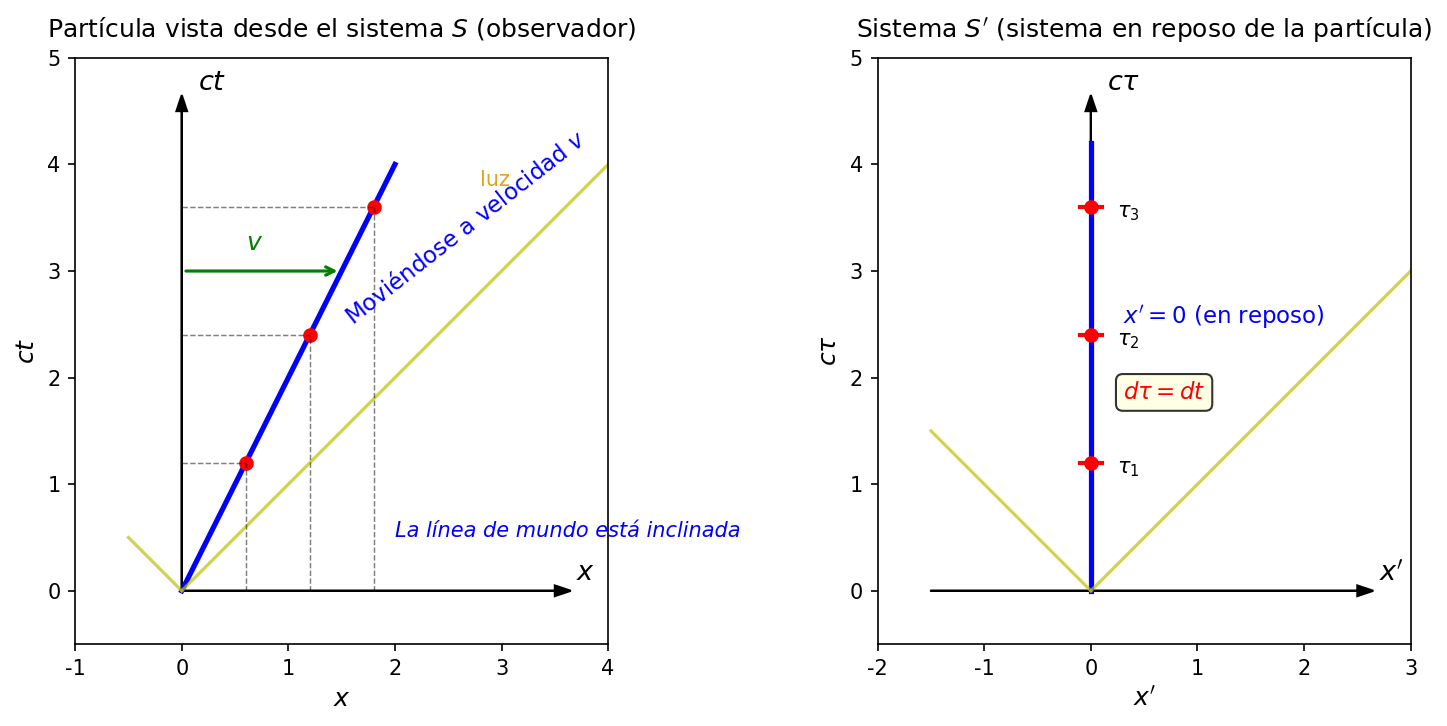
Fig. 4.4: Comprensión intuitiva del tiempo propio. Izquierda — visto desde el sistema \(S\) (observador), la partícula se mueve con velocidad \(v\), por lo que su línea de universo se inclina. Derecha — visto desde el sistema de reposo \(S'\) de la partícula, ella siempre está en el origen \(x' = 0\) y simplemente avanza recto a lo largo del eje \(c\tau\). Este \(\tau\) es el tiempo propio.
🟡 Lina: Mira el lado derecho de Fig. 4.4「Comprensión intuitiva del tiempo propio. Izquierda」. En el sistema de reposo \(S'\) de la partícula, esta no se mueve — las coordenadas espaciales son siempre cero, y solo avanza el tiempo. Ese "tiempo que marca su propio reloj" es el tiempo propio \(\tau\).
⚪ Mei: Ya veo, desde el sistema \(S\) la línea de universo se inclina, pero desde la perspectiva de la partícula ella simplemente avanza recto en la dirección temporal — ese tiempo es \(\tau\).
🟡 Lina: Exacto. Y el punto importante es que cualquier observador utiliza el tiempo propio \(\tau\) de esta partícula para definir magnitudes físicas como la velocidad. ¿Por qué? Porque el tiempo coordenado \(t\) toma valores diferentes en cada sistema inercial, pero el tiempo propio \(\tau\) es un invariante — da el mismo valor sin importar desde qué sistema inercial se calcule. Si divides por un invariante, el resultado también es un invariante (o una cantidad que sigue la regla de transformación correcta).
🔵 Kai: "Si divides por un invariante, el resultado sigue la regla de transformación correcta", ¿pueden ser más concretos?
🟡 Lina: Por ejemplo, \(dx^\mu\) es un vector contravariante — una cantidad que se transforma multiplicando por \(\Lambda\) bajo una transformación de Lorentz. Si divides esto por \(d\tau\) (un escalar, es decir, una cantidad cuyo valor no cambia bajo la transformación), solo el numerador se transforma con \(\Lambda\) y el denominador es invariante, por lo que el resultado \(dx^\mu / d\tau\) también sigue la regla de transformación de un vector contravariante. Si dividieras por el tiempo coordenado \(dt\), como \(dt\) mismo cambia de un sistema inercial a otro, el resultado no sería un vector contravariante.
⚪ Mei: Por eso es necesario dividir por el tiempo propio \(\tau\) y no por el tiempo coordenado \(t\). Para no romper la regla de transformación.
🟡 Lina: Entonces, ¿cómo definimos el tiempo propio con fórmulas? Como es "el tiempo en el sistema de reposo de la partícula", queremos una cantidad que satisfaga \(d\tau = dt\) en el sistema de reposo de la partícula (donde \(dx = dy = dz = 0\)). Además, debe dar el mismo valor sin importar desde qué sistema inercial se calcule (ser un invariante) — de lo contrario, el significado de "reloj de la propia partícula" dependería del sistema de coordenadas.
🔵 Kai: Un invariante… ¿ah, \(ds^2\)?
🟡 Lina: Exacto. En la sección 2 de Cap. 3 dedujimos que \(ds^2\) es un invariante que toma el mismo valor en todos los sistemas inerciales. Es un invariante que puede calcularse directamente a partir de los desplazamientos infinitesimales de coordenadas y que da la "distancia espacio-temporal" entre dos eventos cercanos. Entonces, calculemos \(ds^2\) en el sistema de reposo de la partícula — es decir, el sistema inercial que se mueve junto con la partícula. En este sistema, la partícula no se mueve, así que las coordenadas espaciales no cambian. Por tanto \(dx = dy = dz = 0\). Sustituyendo: \(ds^2 = -dt^2 + 0 + 0 + 0 = -dt^2\). Aquí, "\(dt\) en el sistema de reposo" es el tiempo que marca el reloj que se mueve con la partícula — es decir, un reloj colocado justo al lado de la partícula (en el lado derecho de Fig. 4.4「Comprensión intuitiva del tiempo propio. Izquierda」, donde la partícula no se mueve y avanza a lo largo del eje temporal, ese tiempo). Como hay un signo negativo, \(ds^2 < 0\). Y como \(ds^2\) es un invariante, si calculas \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2\) en otro sistema inercial, obtienes el mismo valor numérico — coincide con el \(-dt^2\) obtenido en el sistema de reposo.
🔵 Kai: \(ds^2\) negativo… ¿es el cuadrado del tiempo y es negativo, está bien eso?
🟡 Lina: Buena pregunta. Ese es exactamente el punto. Lo que queremos hacer es definir "el tiempo \(d\tau\) que marca el reloj de la propia partícula" — es decir, queremos obtener un tiempo real. Por tanto \(d\tau^2\) debe ser una cantidad positiva. Sin embargo, \(ds^2\) resulta negativo. ¿Por qué es negativo? — en el sistema de reposo (\(dx = dy = dz = 0\)), \(ds^2 = -dt^2 < 0\). Y como \(ds^2\) es un invariante, si es negativo en el sistema de reposo, es negativo en cualquier otro sistema inercial.
🔵 Kai: Es decir, para una partícula que se mueve a menos de la velocidad de la luz, sin importar en qué sistema inercial se calcule, siempre \(ds^2 < 0\).
🟡 Lina: Correcto. También puedes verificarlo directamente en un sistema inercial general — la rapidez de la partícula es \(v^2 = (dx^2 + dy^2 + dz^2)/dt^2\), así que si \(v < 1\) (sublumínica), entonces \(v^2 < 1\). Multiplicando ambos lados por \(dt^2 > 0\): \(dx^2 + dy^2 + dz^2 < dt^2\), por tanto \(ds^2 = -dt^2 + dx^2 + dy^2 + dz^2 < 0\).
Ahora bien, si \(ds^2 < 0\), no podemos tomar la raíz cuadrada y obtener un "tiempo" real. La solución es simple — ponemos un signo negativo para obtener \(-ds^2 > 0\). En el sistema de reposo: \(-ds^2 = -(-dt^2) = dt^2\) — exactamente "el cuadrado del tiempo del reloj de la partícula". Y como \(ds^2\) es un invariante, \(-ds^2\) también lo es. Así definimos el tiempo propio como:
🔵 Kai: Se resuelve simplemente poniendo un signo negativo. Las convenciones de signo son realmente importantes.
🟡 Lina: Con esta definición, en el sistema de reposo (\(dx = dy = dz = 0\)): \(d\tau^2 = dt^2\), es decir \(d\tau = dt\) — corresponde correctamente al "reloj de la propia partícula". Y como \(ds^2\) era un invariante que tomaba el mismo valor en todos los sistemas inerciales (lo dedujimos en la sección 2 de Cap. 3), \(-ds^2\) también es obviamente un invariante — solo invertimos el signo. Por tanto \(d\tau\) es un invariante y da el mismo valor sin importar desde qué sistema inercial se calcule.
🔵 Kai: Ya veo, construyeron la definición calculando hacia atrás para que \(d\tau = dt\) en el sistema de reposo. Como \(ds^2\) es negativo, le ponen un signo menos para hacerlo positivo — y así \(d\tau\) es real.
🟡 Lina: Exacto.
Nota: Esta definición solo da \(d\tau^2 > 0\) (y \(d\tau\) tiene sentido como número real) cuando \(ds^2 < 0\) (temporal). Es decir, el tiempo propio se define solo a lo largo de la línea de universo de partículas que se mueven a menos de la velocidad de la luz — trayectorias causalmente alcanzables. Para la luz (\(ds^2 = 0\)) o trayectorias hipotéticas superlumínicas no se puede definir tiempo propio.
⚪ Mei: En el sistema de reposo de la partícula, \(dx = dy = dz = 0\) así que \(d\tau = dt\). Es decir, el tiempo propio es "el tiempo del reloj que se mueve con la partícula".
🔵 Kai: Entonces, visto desde el sistema \(S\) donde la partícula se mueve, ¿qué pasa con \(d\tau\)? Como \(dx \neq 0\), ¿resulta \(d\tau < dt\)?
🟡 Lina: Exacto. En el sistema \(S\) la partícula se mueve, así que \(dx^2 + dy^2 + dz^2 > 0\), y \(d\tau^2 = dt^2 - (dx^2 + dy^2 + dz^2) < dt^2\) — con \(d\tau > 0\), \(dt > 0\) (avanzando hacia el futuro), obtenemos \(d\tau < dt\). El tiempo propio de una partícula en movimiento es menor que el tiempo coordenado del sistema \(S\). Esto es lo mismo que "un reloj en movimiento se atrasa" que vimos en la sección 4.2 de Cap. 3. Cuánto más corto es concretamente, lo calcularemos ahora.
🟡 Lina: La definición de la 4-velocidad es
\(d\tau\) es un escalar (invariante) y \(dx^\mu\) es un vector contravariante. Como expliqué antes, un escalar no cambia de valor bajo una transformación de Lorentz, así que la regla de transformación de \(dx^\mu / d\tau\) es la misma que la del numerador \(dx^\mu\) — es decir, sigue la regla de transformación de vector contravariante con un solo \(\Lambda\). Por tanto \(U^\mu\) es un vector contravariante.
🔵 Kai: ¿Cómo quedan las componentes concretamente?
🟡 Lina: Siguiendo la definición \(U^\mu = dx^\mu / d\tau\), expresemos cada componente en términos del tiempo coordenado \(t\). Primero necesitamos reescribir \(d\tau\) en términos de \(dt\). De la definición \(d\tau^2 = dt^2 - dx^2 - dy^2 - dz^2\), si sacamos \(dt^2\) como factor del lado derecho:
Aquí la escritura \(dx^2/dt^2\) puede confundir, pero es \((dx)^2/(dt)^2 = (dx/dt)^2\) — el cociente de cuadrados de cantidades infinitesimales es lo mismo que el cuadrado de la derivada.
🔵 Kai: Mmm, ¿sacar \(dt^2\) como factor, concretamente qué cálculo es?
🟡 Lina: De \(d\tau^2 = dt^2 - dx^2 - dy^2 - dz^2\), divides los 4 términos del lado derecho por \(dt^2\) y sacas \(dt^2\) como factor. \(dt^2/dt^2 = 1\), \(dx^2/dt^2 = (dx/dt)^2\), \(dy^2/dt^2 = (dy/dt)^2\), \(dz^2/dt^2 = (dz/dt)^2\). Así que \(d\tau^2 = dt^2\bigl(1 - (dx/dt)^2 - (dy/dt)^2 - (dz/dt)^2\bigr)\). Usando el cuadrado de la velocidad tridimensional \(v^2 \equiv (dx/dt)^2 + (dy/dt)^2 + (dz/dt)^2\) (en unidades con \(c = 1\): \(0 \le v < 1\)): $$ d\tau^2 = dt^2(1 - v^2) $$
Tomando la raíz cuadrada (como \(dt > 0\), \(d\tau > 0\), tomamos la raíz positiva): \(d\tau = dt\sqrt{1 - v^2}\), es decir
🔵 Kai: ¡Ah, aparece \(\gamma\)! La razón entre el tiempo propio y el tiempo coordenado es exactamente el factor de Lorentz.
🟡 Lina: Así es. Por tanto, al convertir la derivada respecto a \(\tau\) en derivada respecto a \(t\) (usando la regla de la cadena \(dx^\mu/d\tau = (dx^\mu/dt)(dt/d\tau)\)):
Aquí \(v^i = dx^i/dt\) es la velocidad tridimensional ordinaria. La componente temporal dentro del paréntesis es 1 porque \(dx^0/dt = dt/dt = 1\) (y multiplicado por \(\gamma\) da \(U^0 = \gamma\)).
🔵 Kai: ¿Cómo se calcula la "magnitud" de este \(U^\mu\)? En 3 dimensiones sería \(|\vec{v}|^2 = v_x^2 + v_y^2 + v_z^2\), pero…
🟡 Lina: En el espacio-tiempo de 4 dimensiones, la cantidad que corresponde al "cuadrado de la magnitud" de un vector — que llamamos norma (norm) — se calcula usando la métrica \(\eta_{\mu\nu}\). Lo que corresponde al \(|\vec{v}|^2 = v_x^2 + v_y^2 + v_z^2\) tridimensional es:
Si lo expandimos con la convención de suma de la sección 1.3: \((-1)(U^0)^2 + (U^1)^2 + (U^2)^2 + (U^3)^2\). A diferencia de 3 dimensiones, la componente temporal lleva un signo negativo, así que la norma puede tomar valores negativos — mientras que en 3 dimensiones el "cuadrado de la longitud" siempre es positivo, en el espacio-tiempo el signo tiene significado físico (temporal, espacial o luminoso). Intenta sustituir \(U^\mu = \gamma(1, v^x, v^y, v^z)\).
⚪ Mei: Sustituyendo:
🔵 Kai: ¡La magnitud de la 4-velocidad es siempre \(-1\)! Es constante sin importar la rapidez.
🟡 Lina: Así es. Esta es una propiedad que se sigue automáticamente de la definición del tiempo propio. Que la norma sea \(-1\) (negativa) significa que la 4-velocidad es un vector temporal (timelike vector) — es decir, un vector que satisface \(\eta_{\mu\nu} V^\mu V^\nu < 0\). Es la misma clasificación que cuando en la sección 2.3 de Cap. 3 llamamos "temporal" a un intervalo con \(ds^2 < 0\), ahora aplicada a vectores — si la norma del vector es negativa: temporal, cero: luminoso, positiva: espacial. Un vector temporal apunta hacia el interior del cono de luz.
🔵 Kai: Si la norma es \(-1\) y constante, ¿no se puede cambiar la "magnitud" de la 4-velocidad?
🟡 Lina: Correcto. Intuitivamente es así — en el sistema de reposo de la partícula, \(U^\mu = (1, 0, 0, 0)\). Es decir, avanza en la dirección temporal con "rapidez 1" (= velocidad de la luz). No se mueve en la dirección espacial.
⚪ Mei: Visto desde otro sistema inercial, \(U^\mu = \gamma(1, v, 0, 0)\) y aparece la componente espacial. Pero la norma sigue siendo \(-1\).
🟡 Lina: Así es. El vector 4-velocidad simplemente se inclina en el plano \(t\)-\(x\) manteniendo su norma (magnitud) — la misma estructura que la rotación hiperbólica vista en la sección 3.7 de Cap. 3. Cuanto más rápido se mueve en la dirección espacial, más crece la componente temporal \(\gamma\), manteniendo la norma en \(-1\).
🔵 Kai: …entonces, cuanto más rápido se mueve en la dirección espacial, más grande se hace la componente temporal para que la norma se conserve. Me viene a la mente la imagen de que todos avanzan por el espacio-tiempo a "la velocidad de la luz", y la diferencia es solo si la dirección es más temporal o más espacial… ¿es correcto?
🟡 Lina: Es una intuición interesante. Pero hay que tener cuidado — "avanzar a la velocidad de la luz" es solo una metáfora; lo preciso es que "la norma de la 4-velocidad es \(-1\) (restaurando \(c\): \(-c^2\)) y es constante". La norma del fotón es 0, así que las partículas con masa y los fotones no "avanzan a la velocidad de la luz" en el mismo sentido. Esta metáfora se usa frecuentemente en libros de divulgación, pero difiere un poco del significado de las fórmulas, así que si la escribes en un examen quizás te quiten puntos (risas).
🔵 Kai: Entonces, ¿cómo se diría con precisión?
🟡 Lina: Dicho con precisión — la norma de la 4-velocidad de todas las partículas con masa no puede cambiarse. Cuanto más rápido se muevan en la dirección espacial, la componente temporal \(U^0 = \gamma\) crece proporcionalmente para mantener la norma en \(-1\). Como resultado, el avance del tiempo propio se ralentiza — esto es la reformulación en términos de la 4-velocidad del "un reloj en movimiento se atrasa" que vimos en la sección 4.2 de Cap. 3.
🔵 Kai: ¿Y para el fotón? Con masa cero, \(U^\mu = dx^\mu/d\tau\) tendría \(d\tau\) igual a cero y no se podría definir, ¿no?
🟡 Lina: Perspicaz. Así es, para el fotón no se puede definir tiempo propio (porque \(ds^2 = 0\) implica \(d\tau = 0\)). Por eso la 4-velocidad no es aplicable al fotón. ¿Entonces cómo se describe el movimiento del fotón? — lo trataremos en 「Partículas de masa cero」 después de introducir el 4-momento.
✅ Verificación de comprensión: ¿Por qué en la definición de la 4-velocidad se deriva respecto al tiempo propio \(\tau\) y no respecto al tiempo coordenado \(t\)?
Respuesta
El tiempo coordenado \(t\) toma valores diferentes en cada sistema inercial, pero el tiempo propio \(\tau\) es un invariante (da el mismo valor sin importar desde qué sistema inercial se calcule). Al dividir por un invariante, se garantiza que el resultado siga la regla de transformación correcta (la de vector contravariante).
4-momento¶
🟡 Lina: Una vez que tenemos la 4-velocidad, el 4-momento (four-momentum) \(p^\mu\) se define naturalmente.
Aquí \(m\) es la masa (en reposo) de la partícula.
🔵 Kai: Las componentes espaciales \(p^i = \gamma m v^i\)… ah, a baja velocidad \(\gamma \approx 1\) así que recupera el momento de Newton \(mv^i\). ¿Y la componente temporal \(p^0 = \gamma m\), qué representa?
🟡 Lina: En el sistema de unidades con \(c = 1\), \(p^0 = \gamma m = E\) — tiene el mismo valor que la energía. Para volver a unidades SI, usamos el análisis dimensional aprendido en la sección 1.1. De \(p^\mu = (p^0, p^1, p^2, p^3)\), las componentes espaciales \(p^i = \gamma m v^i\) tienen dimensión de momento \([\text{kg}\cdot\text{m/s}]\).
🔵 Kai: ¿La componente temporal \(p^0\) también tiene que tener la misma dimensión?
🟡 Lina: Sí. Al expandir la transformación de Lorentz \(p^{\mu'} = \Lambda^{\mu'}{}_{\nu} p^\nu\), el lado derecho es una suma de \(p^0, p^1, p^2, p^3\). Para poder sumarlos, todas las componentes deben tener la misma dimensión — no puedes sumar "3 kg·m/s + 5 julios".
🔵 Kai: Ah, claro. Solo se pueden sumar cantidades de la misma dimensión.
🟡 Lina: Exacto. En SI, las componentes espaciales \(p^i = \gamma mv^i\) (donde \(v^i\) tiene dimensión de m/s) tienen dimensión de momento \([\text{kg}\cdot\text{m/s}]\). Así que la componente temporal también debe tener la misma dimensión. En unidades naturales teníamos \(p^0 = \gamma m\), ¿qué pasa al volver a SI? Usamos el análisis dimensional de la sección 1.1. La dimensión de \(\gamma m\) es \([\text{kg}]\), y le falta \([\text{m/s}]\) respecto a la dimensión de las componentes espaciales \([\text{kg}\cdot\text{m/s}]\). Así que completamos con \(c\) (dimensión \([\text{m/s}]\)), y la expresión correcta en SI es \(p^0 = \gamma mc\) — ahora tiene dimensión \([\text{kg}\cdot\text{m/s}]\). Por otro lado, la expresión SI de la energía es \(E = \gamma mc^2\) (dimensión: \([\text{kg}\cdot\text{m}^2/\text{s}^2]\)). Entonces \(E/c = \gamma mc\) (dimensión: \([\text{kg}\cdot\text{m/s}]\)) — la misma dimensión que las componentes espaciales. Es decir, en unidades SI, escribiendo \(p^0 = E/c\) todas las componentes tienen la misma dimensión.
Nota: En algunos libros de texto, se define la coordenada temporal como \(x^0 = ct\) (dimensión de longitud) desde el principio para igualar las dimensiones de todas las componentes. En ese caso \(U^0 = dx^0/d\tau = c\,dt/d\tau = \gamma c\), \(p^0 = mU^0 = \gamma mc = E/c\), y la conclusión es la misma. Como en este capítulo unificamos con \(c = 1\), podemos escribir simplemente \(p^0 = E\).
En resumen — en este capítulo (\(c = 1\)): \(p^0 = E\). Volviendo a SI: \(p^0 = E/c\). Cuando necesites valores numéricos concretos en SI, restaura \(c\) por análisis dimensional como aprendimos en la sección 1.1. La expansión a baja velocidad da \(E \approx m + \frac{1}{2}mv^2\) (\(c = 1\)); restaurando \(c\): \(E \approx mc^2 + \frac{1}{2}mv^2\) — la suma de la energía en reposo y la energía cinética. La derivación de esta expansión la haremos en detalle enseguida en 「Límite de baja velocidad y conexión con la mecánica de Newton」.
🟡 Lina: Calculemos la norma invariante del 4-momento. Como \(p^\mu = mU^\mu\):
En componentes: \(-(p^0)^2 + |\vec{p}|^2 = -m^2\). Con \(c = 1\), \(p^0 = E\), así que \(-E^2 + |\vec{p}|^2 = -m^2\), es decir \(E^2 = |\vec{p}|^2 + m^2\). Esta es la relación energía-momento con \(c = 1\).
🔵 Kai: ¡Vaya, usando solo la invariancia de la norma sale la relación entre energía y momento!
🟡 Lina: Para restaurar \(c\), usamos el análisis dimensional de la sección 1.1. En la fórmula con \(c = 1\): \(E^2 = |\vec{p}|^2 + m^2\), cada término en SI tiene dimensiones diferentes — el lado izquierdo \(E^2\) es energía al cuadrado con dimensión \([\text{kg}^2\cdot\text{m}^4/\text{s}^4]\), \(|\vec{p}|^2\) es momento al cuadrado con dimensión \([\text{kg}^2\cdot\text{m}^2/\text{s}^2]\), \(m^2\) es masa al cuadrado con dimensión \([\text{kg}^2]\). Para igualar cada término a la dimensión del lado izquierdo \([\text{kg}^2\cdot\text{m}^4/\text{s}^4]\) — a \(|\vec{p}|^2\) le falta \([\text{m}^2/\text{s}^2]\) así que multiplicamos por \(c^2\), y a \(m^2\) le falta \([\text{m}^4/\text{s}^4]\) así que multiplicamos por \(c^4\). Por tanto:
⚪ Mei: De la invariancia de la norma sale de un golpe la relación entre energía y momento.
🔵 Kai: Cuando \(\vec{p} = 0\) (reposo): \(E^2 = m^2 c^4\), es decir \(E = mc^2\) — ¡\(E = mc^2\) era un caso particular de esta fórmula! Pero un momento. Si ponemos \(m = 0\), obtenemos \(E = |\vec{p}|c\); ¿una partícula de masa cero puede tener energía? ¿No es extraño?
🟡 Lina: Buena pregunta. Efectivamente, con masa cero se puede tener energía y momento. El fotón es exactamente así. Esto lo trataremos en detalle un poco más adelante en la sección 2.7, así que espera un poco.
🔵 Kai: Además, antes dijiste que "en la expansión a baja velocidad \(E \approx m + \frac{1}{2}mv^2\)". Intuitivamente entiendo que aparece la energía cinética de Newton, pero me pregunto cómo se obtiene esa aproximación a partir de \(\gamma m\). Y otra cosa, ¿para qué sirve el 4-momento? En mecánica de Newton, la conservación del momento y la conservación de la energía eran leyes separadas…
🟡 Lina: La derivación de la expansión a baja velocidad es una buena pregunta — la haremos con detalle en la siguiente sección (「Límite de baja velocidad y conexión con la mecánica de Newton」), así que espera un poco. Primero te contesto "para qué sirve el 4-momento". Por ejemplo, en colisiones y desintegraciones de partículas. Cuando dos partículas chocan y nacen otras, \(p^\mu_{\text{total}}\) se conserva antes y después de la reacción — es decir, la energía y el momento se conservan simultáneamente. En mecánica de Newton, la conservación del momento y la de la energía eran leyes separadas, pero en relatividad donde tiempo y espacio forman un todo, se unifican como la conservación de un solo 4-vector, el 4-momento \(p^\mu = (E, \vec{p})\).
🔵 Kai: Dos leyes separadas en mecánica de Newton se unifican en una sola ecuación en relatividad… Pero espera, en mecánica de Newton la conservación del momento se derivaba de la tercera ley de Newton (acción-reacción). En relatividad, la tercera ley no necesariamente se aplica tal cual, entonces ¿de qué se deriva que el 4-momento se conserve?
🟡 Lina: Buena pregunta. En la sección 5 de Cap. 1 vimos la relación entre "simetrías y cantidades conservadas" — la simetría de traslación temporal garantiza la conservación de la energía, y la simetría de traslación espacial garantiza la conservación del momento. En relatividad, como tiempo y espacio forman un todo, estas dos leyes de conservación se unifican como la conservación del 4-momento debida a la simetría de traslación espacio-temporal. La derivación rigurosa la revisitaremos en capítulos posteriores en el contexto de la teoría de campos.
✅ Verificación de comprensión: A partir de \(E^2 = |\vec{p}|^2 c^2 + m^2 c^4\), ¿qué conclusión se obtiene para una partícula de masa cero (fotón)?
Respuesta
Sustituyendo \(m = 0\) se obtiene \(E = |\vec{p}|c\), lo que significa que con masa cero se puede tener energía y momento. Además, la rapidez de una partícula con masa viene dada por \(v = |\vec{p}|c^2/E\) (derivable de \(\vec{p} = \gamma m\vec{v}\), \(E = \gamma mc^2\)). En el límite \(m \to 0\), sustituyendo \(E = |\vec{p}|c\): \(v = |\vec{p}|c^2/(|\vec{p}|c) = c\), así que una partícula de masa cero se mueve necesariamente a la velocidad de la luz.
Límite de baja velocidad y conexión con la mecánica de Newton¶
🔵 Kai: Antes, Lina, mencionaste la conclusión de que "en la expansión a baja velocidad \(E \approx mc^2 + \frac{1}{2}mv^2\)". ¿Cómo se deriva esto?
🟡 Lina: Buena observación. Vamos a calcularlo. Basta aproximar \(\gamma\) en \(E = \gamma mc^2\) para \(v \ll c\). Usando la fórmula de aproximación \((1 + x)^n \approx 1 + nx\) (para \(|x| \ll 1\)) que se aprende en el instituto, con \(x = -v^2/c^2\), \(n = -1/2\):
Sustituyendo en \(E = \gamma mc^2\):
⚪ Mei: El primer término es la energía en reposo, el segundo es la energía cinética de Newton. Se separan limpiamente.
🟡 Lina: Exacto. Y lo importante es que para \(v \ll c\), el segundo término es extremadamente pequeño comparado con el primero. Para \(v = 100\,\text{m/s}\) (algo más rápido que un tren bala), \(v^2/c^2 \sim 10^{-13}\), así que la energía cinética es 13 órdenes de magnitud menor que la energía en reposo \(mc^2\).
🔵 Kai: Con 13 órdenes de diferencia, es imposible que en la época de Newton se dieran cuenta. Pero visto al revés, ¿el hecho de que una reacción nuclear libere una energía inmensa con solo una pequeñísima reducción de masa se debe a que \(mc^2\) es enorme?
🟡 Lina: Así es. En el movimiento cotidiano solo es visible \(\frac{1}{2}mv^2\), y la enorme \(mc^2\) detrás estaba completamente oculta. Solo cuando la relatividad reveló que "en la masa hay energía almacenada" se pudo entender las reacciones nucleares — que con solo liberar una pequeña parte de \(mc^2\) se obtiene una energía inmensa.
Partículas de masa cero¶
🟡 Lina: Y otra consecuencia importante. Si ponemos una partícula de masa cero (fotón) en \(E^2 = |\vec{p}|^2 c^2 + m^2 c^4\):
Con masa cero se puede tener energía y momento. Y para que \(E = \gamma mc^2\) con \(m = 0\) y \(E \neq 0\) se cumpla, necesitamos \(\gamma \to \infty\), es decir \(v = c\) — una partícula de masa cero se mueve necesariamente a la velocidad de la luz. Tanto el fotón como el gravitón (que discutiremos en Cap. 25, una partícula aún no detectada pero predicha teóricamente) que aparecerá en capítulos posteriores, se cree que satisfacen esta relación.
✅ Verificación de comprensión: ¿Cuál es el valor de la norma invariante de la 4-velocidad \(\eta_{\mu\nu} U^\mu U^\nu\)?
Respuesta
\(-1\) (en unidades con \(c = 1\)). Es siempre constante sin importar la rapidez, y esto se sigue automáticamente de la definición del tiempo propio.
📝 Ejercicios:
- Normalización de la 4-velocidad, límite de baja velocidad de la energía relativista, 4-aceleración → Problema B-7. Verificación de la condición de normalización de la 4-velocidad, Problema B-8. Límite de baja velocidad de la energía relativista, Problema A-1. 4-velocidad y 4-aceleración
4.3 Índices superiores e inferiores — vectores covariantes¶
Operación de bajar índices¶
🟡 Lina: Hasta ahora hemos hablado de \(A^\mu\) (índice superior), pero también necesitamos introducir el índice inferior \(A_\mu\). La definición es:
🔵 Kai: Se multiplica por la métrica \(\eta_{\mu\nu}\) y se contrae. ¿Concretamente cómo queda?
🟡 Lina: \(\eta_{\mu\nu}\) es una matriz diagonal con \(\eta_{00} = -1\), \(\eta_{11} = \eta_{22} = \eta_{33} = 1\), así que:
Análogamente \(A_2 = A^2\), \(A_3 = A^3\). (Aquí, al sumar sobre \(\nu\), como \(\eta_{1\nu}\) es cero para \(\nu \neq 1\), solo sobrevive el término \(\eta_{11}\,A^1\).)
⚪ Mei: Es decir, solo la componente temporal cambia de signo, y las componentes espaciales quedan igual. Si \(A^\mu = (A^0, A^1, A^2, A^3)\), entonces \(A_\mu = (-A^0, A^1, A^2, A^3)\).
🟡 Lina: Exacto. Esquematizo esta operación de "subir y bajar índices" en Fig. 4.5「Operación de subir y bajar índices」.
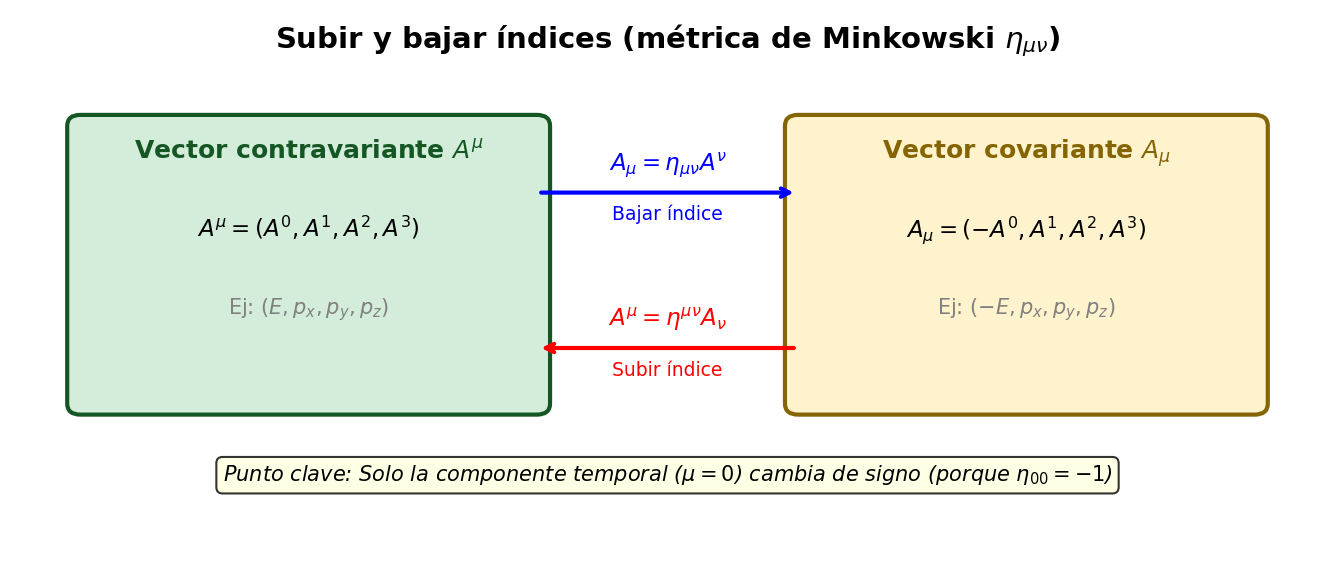
Fig. 4.5: Operación de subir y bajar índices. Se multiplica la métrica \(\eta_{\mu\nu}\) al vector contravariante \(A^\mu\) para crear el vector covariante \(A_\mu\) (bajar el índice). Se usa la matriz inversa \(\eta^{\mu\nu}\) para revertir (subir el índice). En la métrica de Minkowski, solo la componente temporal cambia de signo.
🟡 Lina: \(A^\mu\) se llama vector contravariante (contravariant vector) y \(A_\mu\) se llama vector covariante (covariant vector). Los nombres "contravariante" y "covariante" se originan en la diferencia de las reglas de transformación bajo cambio de coordenadas.
¿Por qué se necesitan dos tipos de vectores?
Al combinar índices superiores e inferiores y contraer, se obtiene una cantidad escalar invariante de Lorentz. Usando \(A_0 = -A^0\), \(A_i = A^i\) (\(i = 1, 2, 3\)) y expandiendo explícitamente:
El signo negativo que queda solo en la componente temporal se debe al cambio de signo \(A_0 = -A^0\). Esto es invariante bajo transformaciones de Lorentz. Esta estructura de "combinar índices arriba y abajo para crear un escalar" es la base de los cálculos en relatividad general.
⚪ Mei: Ah, ¿lo que calculamos en la sección 2.4, \(\eta_{\mu\nu}\,U^\mu\,U^\nu = -1\), tiene relación con esta operación de "bajar el índice"?
🟡 Lina: Buena observación. Exactamente así. \(\eta_{\mu\nu}\,U^\mu\,U^\nu\) es equivalente a bajar el índice de \(U^\mu\) con \(\eta_{\mu\nu}\) para crear \(U_\nu = \eta_{\nu\mu} U^\mu\), y luego tomar el producto interno con \(U^\nu\) — es decir, \(U_\nu\,U^\nu = U_\mu\,U^\mu\). La escritura es diferente, pero todo es el mismo cálculo (como \(\eta_{\mu\nu} = \eta_{\nu\mu}\), el orden de los índices puede intercambiarse).
Operación de subir índices¶
🟡 Lina: Inversamente, para volver un índice inferior a superior, se usa \(\eta^{\mu\nu}\) (la matriz inversa de \(\eta_{\mu\nu}\)).
En el caso de la métrica de Minkowski, \(\eta^{\mu\nu}\) es la misma matriz que \(\eta_{\mu\nu}\) (componentes diagonales \(-1, 1, 1, 1\)).
🔵 Kai: ¿Por qué la matriz inversa es igual a la original?
🟡 Lina: \(\eta_{\mu\nu}\) es una matriz diagonal con componentes diagonales \(-1, 1, 1, 1\). La inversa de una matriz diagonal es la matriz diagonal con los recíprocos de cada componente diagonal. \((-1)^{-1} = -1\), \(1^{-1} = 1\), así que las componentes diagonales de la inversa también son \(-1, 1, 1, 1\) — igual que la original. Esta es una propiedad especial de la métrica de Minkowski; para una métrica general \(g_{\mu\nu}\), la inversa \(g^{\mu\nu}\) tiene componentes diferentes a la original.
⚪ Mei: Que sea su propia inversa… en cierto sentido \(\eta_{\mu\nu}\) es una métrica muy fácil de manejar.
✅ Verificación de comprensión: A partir del vector contravariante \(A^\mu = (A^0, A^1, A^2, A^3)\), al construir el vector covariante \(A_\mu\), ¿qué componente cambia de signo?
Respuesta
Solo la componente temporal cambia de signo. \(A_\mu = (-A^0, A^1, A^2, A^3)\). Esto se debe a \(\eta_{00} = -1\), \(\eta_{ii} = 1\).
4.4 Fundamentos de los tensores¶
¿Qué es un tensor?¶
🟡 Lina: Por fin entramos en la discusión general de los tensores (tensor). En realidad, los 4-vectores son "tensores con un solo índice" (tensores de rango 1). Aquí extenderemos a tensores de rango 2 con "dos índices", para entender las reglas de transformación y el mecanismo de contracción.
🔵 Kai: \(\eta_{\mu\nu}\) también tiene 2 índices, ¿verdad? ¿Eso también es un tensor?
🟡 Lina: Exactamente. En la sección 2.3, dijimos que un vector contravariante se transforma como \(V^{\mu'} = \Lambda^{\mu'}{}_{\nu}\,V^\nu\) — como tiene un solo índice, se le aplica un solo \(\Lambda\). Entonces, ¿cómo se transforma una cantidad \(T^{\mu\nu}\) que tiene 2 índices? La respuesta es simple — por cada índice se aplica un \(\Lambda\). Con 2 índices, se aplican 2 \(\Lambda\):
Ilustro la estructura de esta regla de transformación en Fig. 4.6「Imagen geométrica de la transformación de coordenadas de un tensor. Izquierda: el mismo vector físico \(\mathbf{V}\) tiene diferentes componentes según se expanda en la base \(\mathbf{e}_i\) (azul) o \(\mathbf{e}'_i\) (roja). Derecha: reglas de transformación para contravariante, covariante y tensor de rango 2」.
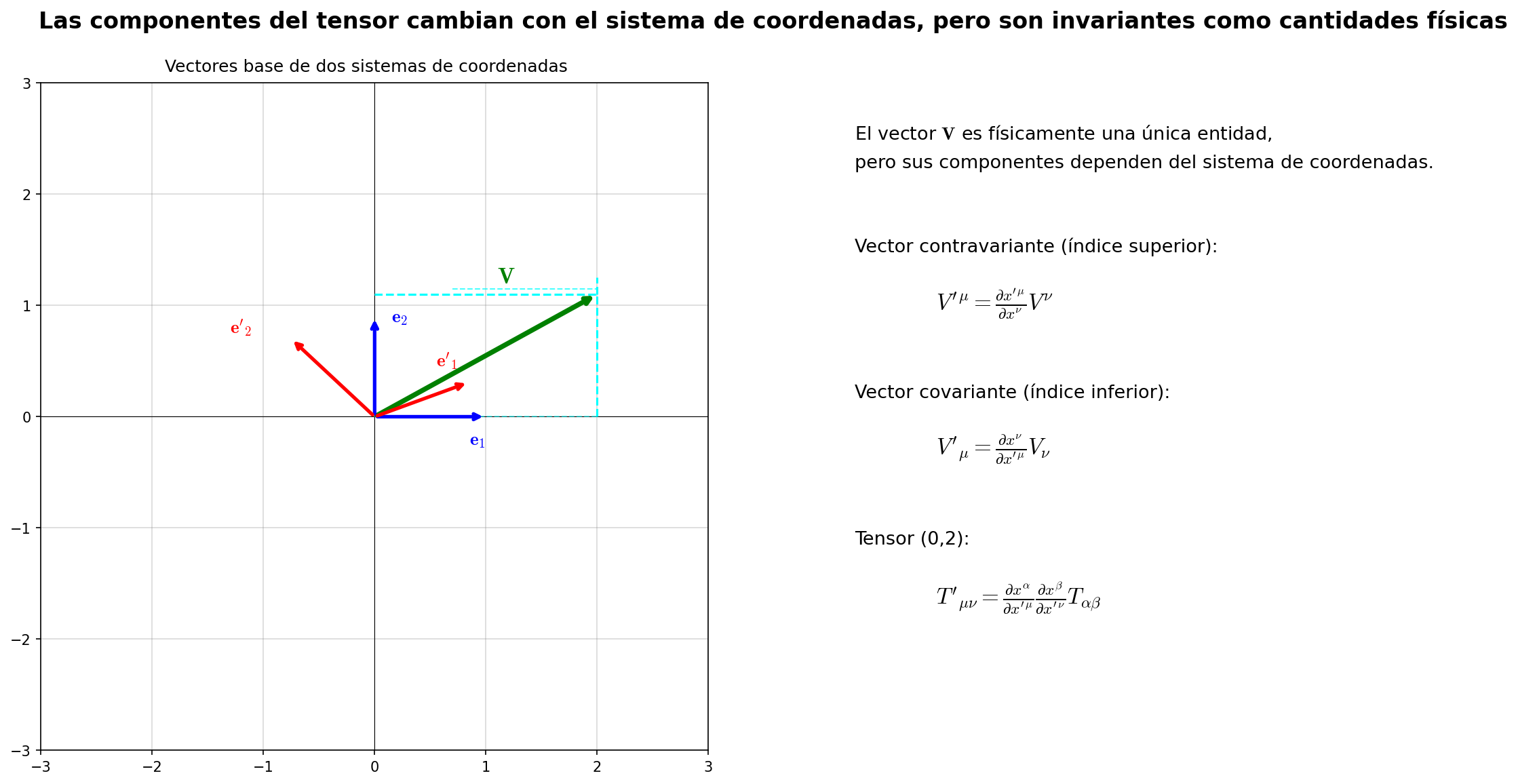
Fig. 4.6: Imagen geométrica de la transformación de coordenadas de un tensor. Izquierda: el mismo vector físico \(\mathbf{V}\) tiene diferentes componentes según se expanda en la base \(\mathbf{e}_i\) (azul) o \(\mathbf{e}'_i\) (roja). Derecha: reglas de transformación para contravariante, covariante y tensor de rango 2 — por cada índice se aplica una matriz de transformación (en relatividad especial: la transformación de Lorentz \(\Lambda\); en general: la matriz de cambio de coordenadas \(\partial x'^\mu/\partial x^\nu\)). Como la magnitud física en sí no depende del sistema de coordenadas, la regla de transformación de componentes describe "cómo difieren al ver lo mismo en coordenadas diferentes".
🔵 Kai: ¡Ah, veo el patrón (el lado derecho de Fig. 4.6「Imagen geométrica de la transformación de coordenadas de un tensor. Izquierda: el mismo vector físico \(\mathbf{V}\) tiene diferentes componentes según se expanda en la base \(\mathbf{e}_i\) (azul) o \(\mathbf{e}'_i\) (roja). Derecha: reglas de transformación para contravariante, covariante y tensor de rango 2」 lo muestra claramente)! Para rango 1 (vector) se aplica 1 \(\Lambda\), para rango 2 se aplican 2. Para rango 3, 3… Es decir, igual que con los vectores, el tensor en sí es una magnitud física independiente del sistema de coordenadas, y solo las componentes cambian según cómo se elijan las coordenadas. Pero aunque veo el patrón, "aplicar 2 \(\Lambda\)" concretamente qué cálculo es, aún no me lo imagino. ¿Pueden expandirlo para que lo vea?
✅ Verificación de comprensión: ¿Por qué en la regla de transformación del tensor de rango 2 \(T^{\mu\nu}\) se necesitan 2 \(\Lambda\)?
Respuesta
\(T^{\mu\nu}\) tiene 2 índices (\(\mu\) y \(\nu\)), y al cambiar de sistema inercial hay que transformar cada índice independientemente. Para la transformación del primer índice se necesita un \(\Lambda\), y para la transformación del segundo índice se necesita otro, en total 2. Con solo un \(\Lambda\) solo se transformaría un índice y quedaría a medias.
🟡 Lina: Vale. Analicemos \(T^{\mu'\nu'} = \Lambda^{\mu'}{}_{\alpha}\,\Lambda^{\nu'}{}_{\beta}\,T^{\alpha\beta}\). Primero, \(\alpha\) y \(\beta\) son índices mudos (aparecen arriba y abajo, así que se suma sobre ellos). Es decir, esta ecuación es la forma abreviada de:
Una suma de \(4 \times 4 = 16\) términos.
🔵 Kai: Para rango 1 era \(V^{\mu'} = \sum_{\nu} \Lambda^{\mu'}{}_{\nu} V^\nu\) con 4 términos, así que cada índice adicional añade una suma más.
🟡 Lina: Exacto. Por ejemplo, si quieres conocer la componente \(\mu' = 0\), \(\nu' = 1\), recorres \(\alpha\) y \(\beta\) cada uno de 0 a 3 y sumas los 16 términos. Sin embargo, para el boost en dirección \(x\) de \(\Lambda\) (mira la matriz escrita en 「4-vector desplazamiento」), las componentes que involucran las direcciones \(y, z\) son \(\Lambda^{0'}{}_{2} = \Lambda^{0'}{}_{3} = \Lambda^{1'}{}_{2} = \Lambda^{1'}{}_{3} = 0\) (en la fila \(\mu' = 0\) y la fila \(\mu' = 1\) de la matriz, las columnas \(\nu = 2, 3\) son cero), así que solo sobreviven los 4 términos con \(\alpha, \beta = 0, 1\):
Para una transformación de Lorentz general (que incluya rotaciones, por ejemplo) pueden sobrevivir los 16 términos, pero la estructura es la misma — es como "repetir 2 veces" la transformación de un vector de rango 1.
🔵 Kai: Es decir, ¿si las componentes del sistema \(S\): \(T^{\alpha\beta}\), multiplicadas por 2 \(\Lambda\), dan un resultado que coincide con lo realmente medido como \(T^{\mu'\nu'}\) en el sistema \(S'\), esa es la condición para ser un tensor?
🟡 Lina: Exactamente. Es la misma estructura que cuando en la sección 2.3 dijimos "una cantidad para la cual multiplicar por \(\Lambda\) da la respuesta correcta es un vector contravariante". Una cantidad para la cual multiplicar por 2 \(\Lambda\) da la respuesta correcta es un tensor contravariante de rango 2.
🔵 Kai: ¿Por qué se aplica \(\Lambda\) 2 veces? ¿1 vez no basta?
🟡 Lina: \(T^{\mu\nu}\) tiene 2 índices, ¿verdad? \(\mu\) y \(\nu\). Al cambiar de sistema inercial, hay que transformar cada índice independientemente. Para transformar el primer índice \(\mu\) se necesita un \(\Lambda\), y para transformar el segundo índice \(\nu\) se necesita otro. En total, 2.
🔵 Kai: Ah, ya veo. Si solo se aplicara \(\Lambda\) una vez, un índice se transformaría al sistema \(S'\) pero el otro quedaría en el sistema \(S\) — un estado a medias. ¿Pueden mostrarme un ejemplo concreto?
🟡 Lina: Claro. El tensor de rango 2 más fácil de entender es el que se forma multiplicando las componentes de 2 vectores en todas las combinaciones: \(T^{\mu\nu} = A^\mu B^\nu\). Por ejemplo, \(T^{01} = A^0 B^1\), \(T^{23} = A^2 B^3\), etc., una cantidad con \(4 \times 4 = 16\) componentes. En el sistema \(S'\): \(A^{\mu'} = \Lambda^{\mu'}{}_{\alpha} A^\alpha\), \(B^{\nu'} = \Lambda^{\nu'}{}_{\beta} B^\beta\), así que:
Para transformar \(A\) se necesita un \(\Lambda\), para transformar \(B\) otro. En total, 2. Si solo se aplicara \(\Lambda\) una vez, solo \(A\) se transformaría al sistema \(S'\) y \(B\) quedaría en el sistema \(S\) — obtendríamos \(A^{\mu'} B^{\nu}\), una cantidad sin sentido.
⚪ Mei: Pensándolo con el producto de 2 vectores, la razón por la que se necesitan 2 \(\Lambda\) es clarísima.
🟡 Lina: Un vector \(V^\mu\) tiene un índice, así que \(\Lambda\) se aplica 1 vez. Un tensor \(T^{\mu\nu}\) tiene 2 índices, así que se aplica 2 veces. Número de índices = número de \(\Lambda\), esa es la esencia de la regla de transformación tensorial. Las cantidades que siguen esta regla de transformación se llaman tensores, y el rango se determina por el número de índices.
Tabla 4.2: Correspondencia entre rango del tensor, número de índices y regla de transformación
| Rango | Nº de índices | Nº de \(\Lambda\) | Nombre | Ejemplo |
|---|---|---|---|---|
| 0 | 0 | 0 | Escalar (invariante) | \(ds^2\), \(m\) |
| 1 | 1 | 1 | 4-vector | \(V^\mu\), \(U^\mu\), \(p^\mu\) |
| 2 | 2 | 2 | Tensor de rango 2 | \(\eta_{\mu\nu}\), \(T^{\mu\nu}\) |
🔵 Kai: Pero, ¿por qué es importante esta condición?
🟡 Lina: Por la misma razón que discutimos para los vectores en la sección 2.3. Los valores numéricos de las componentes cambian de un sistema inercial a otro, pero el contenido físico no cambia. La fórmula de transformación es "la regla de conversión de componentes cuando ves la misma magnitud física desde otro sistema inercial". Si escribes las ecuaciones con tensores, tendrán la misma forma en todos los sistemas inerciales — esa es la base de la relatividad general.
🔵 Kai: Por cierto, para decir que \(\eta_{\mu\nu}\) es un tensor, ¿qué hay que verificar?
🟡 Lina: Estrictamente, \(\eta_{\mu\nu}\) es un tensor covariante con 2 índices inferiores, así que su regla de transformación es ligeramente diferente al caso contravariante — en lugar de \(\Lambda\), se aplican 2 matrices inversas \(\Lambda^{-1}\). Mientras que los tensores contravariantes (índices superiores) se transforman con \(\Lambda\), los tensores covariantes (índices inferiores) se transforman con \(\Lambda^{-1}\) — exactamente la misma estructura que la relación entre vectores contravariantes y covariantes. La fórmula de transformación concreta y el cálculo los dejo para un ejercicio (→ Problema M-2. Condición de preservación de la métrica bajo transformaciones de Lorentz). Solo diré la conclusión: al calcular \(\eta_{\mu'\nu'}\), resulta tener los mismos valores que \(\eta_{\mu\nu}\) — es decir, la métrica de Minkowski tiene las mismas componentes en todos los sistemas inerciales. La razón por la que contravariante y covariante tienen transformaciones opuestas se verá en detalle en la sección 4.4, donde "el par arriba-abajo cancela \(\Lambda\) y \(\Lambda^{-1}\)". Aquí veamos una propiedad muy especial que posee \(\eta_{\mu\nu}\).
\(\eta_{\mu\nu}\) es la misma en todos los sistemas inerciales¶
En el sistema \(S\):
En el sistema \(S'\), por la invariancia de la velocidad de la luz, la misma forma se cumple:
🔵 Kai: En el sistema \(S'\) los coeficientes también son \((-1, 1, 1, 1)\)… es decir, \(\eta_{\mu'\nu'}\) también es la matriz con componentes diagonales \((-1, 1, 1, 1)\) — igual que en el sistema \(S\). Pero un momento. Un tensor es "una cantidad cuyas componentes cambian bajo transformación de coordenadas", ¿verdad? ¿No es contradictorio que las componentes no cambien?
🟡 Lina: Buena pregunta. Primero una corrección — la definición de tensor no es "una cantidad cuyas componentes cambian", sino "una cantidad que sigue una regla de transformación específica". Al aplicar la regla de transformación, las componentes pueden cambiar, o pueden resultar casualmente iguales a las originales. \(\eta_{\mu\nu}\) es el segundo caso, y no es una coincidencia — viene de la definición misma de la transformación de Lorentz. En Cap. 3 definimos la transformación de Lorentz como "la transformación que preserva \(ds^2\)". Que \(ds^2 = \eta_{\mu\nu}\,dx^\mu\,dx^\nu\) sea invariante significa que después de la transformación se puede escribir con las mismas componentes de \(\eta\). Es decir, las componentes de la métrica de Minkowski son diagonales \((-1, 1, 1, 1)\) en todos los sistemas inerciales — esta es una propiedad que se sigue necesariamente de la definición de la transformación de Lorentz.
⚪ Mei: Es decir, como definimos la transformación de Lorentz como "la transformación que preserva \(ds^2\)", que la métrica sea invariante bajo esa transformación es obvio — casi una tautología.
🟡 Lina: Sin embargo, esta es una propiedad propia de la relatividad especial (espacio-tiempo plano). En relatividad general, las componentes de la métrica \(g_{\mu\nu}\) cambian bajo transformaciones de coordenadas — esa es la expresión matemática de que "el espacio-tiempo está curvado".
Contracción — sumar alineando índices arriba y abajo¶
🟡 Lina: Voy a presentar una operación que se usa frecuentemente en capítulos posteriores. La operación de reducir el rango de un tensor — se llama contracción (contraction). En Cap. 12, a partir de un tensor de rango 4 se construye un tensor de rango 2, y luego un escalar — esta operación de "reducir el rango" es esencial para construir las ecuaciones de Einstein.
🔵 Kai: Tensores de rango 4 y eso es tema de más adelante, ¿no? ¿A nosotros ahora nos concierne?
🟡 Lina: En realidad, ya han usado esta operación antes — solo no sabían el nombre.
🔵 Kai: ¿Eh, dónde?
🟡 Lina: El producto interno que apareció en la sección 3.1:
Este es el ejemplo más básico de contracción. Un índice superior \(\mu\) (en \(B^\mu\)) y un índice inferior \(\mu\) (en \(A_\mu\)) aparecen en par, y se sustituye \(\mu = 0, 1, 2, 3\) y se suma — a esta operación se le llama "contraer sobre \(\mu\)".
⚪ Mei: Ah, ya veo. Es decir, la convención de suma de Einstein de la sección 1.3 (si el mismo índice aparece arriba y abajo, se omite \(\sum\)) se reinterpreta como una operación con significado.
🟡 Lina: Exacto. La regla como notación (sección 1.3) y la contracción como operación (lo que estamos haciendo ahora) se refieren al mismo cálculo \(\sum\), pero el punto de vista es diferente — la primera es "una convención de escritura", la segunda es "una operación sobre tensores".
Aclaración terminológica: 'convención de suma' y 'contracción'
- Convención de suma de Einstein (convention): una convención de notación para omitir \(\sum\)
- Contracción tensorial (contraction): una operación que reduce el rango emparejando índices arriba y abajo y sumando
Los nombres son parecidos, pero uno es una forma de escribir y el otro es una operación. Sin embargo, el cálculo subyacente es el mismo \(\sum\).
Caso de dos vectores (producto interno)¶
🟡 Lina: En el producto interno \(A_\mu B^\mu\), veamos con una figura qué está haciendo la contracción. Como el índice \(\mu\) recorre 0, 1, 2, 3, las combinaciones de componentes de \(A\) y \(B\) son en total \(4 \times 4 = 16\):
La contracción \(A_\mu B^\mu\) es la operación de sumar solo las 4 "componentes diagonales" (subrayadas) de entre las 16 combinaciones:
🔵 Kai: Se seleccionan y suman solo 4 de 16. La imagen de extraer la diagonal.
Caso de un tensor de rango 2¶
🟡 Lina: Ahora extendamos el objeto a un tensor de rango 2. En \(T^\mu{}_\nu\) (2 índices, 16 componentes), si hacemos \(\nu\) igual a \(\mu\) y escribimos \(T^\mu{}_\mu\) — como \(\mu\) aparece arriba y abajo, por la convención de suma de la sección 1.3 se toma la suma:
Se recorre \(\mu\) de 0 a 3 y se suman solo las 4 componentes diagonales. Esto es exactamente la traza (trace) de una matriz.
⚪ Mei: La estructura es exactamente la misma que en el producto interno. El objeto cambió de "vector \(A\) y vector \(B\)" a "un solo tensor de rango 2 \(T\)", pero la operación de "recorrer un par de índices arriba-abajo y sumar" es común.
🟡 Lina: Exacto. La operación en sí puede unificarse. Profundicemos un poco más en este punto de vista unificado.
Definición general de la contracción¶
Contracción (contraction): Cuando un tensor tiene un índice superior y un índice inferior, al hacerlos la misma letra y sustituir 0, 1, 2, 3, sumando. Al desaparecer un par de índices arriba-abajo, el rango se reduce en 2.
Tabla 4.3: Ejemplos concretos de la operación de contracción y rango resultante
| Tensor original | Escritura de la contracción | Resultado |
|---|---|---|
| \(A_\mu\) y \(B^\mu\) (2 vectores) | \(A_\mu B^\mu\) | Escalar (rango 0) = producto interno |
| \(T^\mu{}_\nu\) (1 tensor de rango 2) | \(T^\mu{}_\mu\) | Escalar (rango 0) = traza (trace) |
| \(R^\rho{}_{\sigma\mu\nu}\) (tensor de rango 4, aparece en Cap. 12) | \(R^\mu{}_{\sigma\mu\nu} = R_{\sigma\nu}\) | Tensor de rango 2 (tensor de Ricci) |
🔵 Kai: Con la misma operación de "sumar sobre el par de índices", según el objeto se llama "producto interno", "traza", "tensor de Ricci"…
🟡 Lina: Los nombres difieren por razones históricas, pero la operación está unificada. Esa es la fortaleza de la notación de índices — la misma regla de contracción se aplica a cualquier tensor.
Regla de la contracción: por qué debe ser un par arriba-abajo¶
🔵 Kai: Tengo una pregunta. Dicen que hay que hacer el par con un índice arriba y uno abajo, pero ¿no se puede con ambos arriba o ambos abajo? Por ejemplo, \(A^\mu B^\mu\) con "ambos arriba" y sumar daría lo mismo, ¿no?—
🟡 Lina: Eso no funciona. La razón es que el resultado no sería un escalar — es decir, al cambiar de sistema inercial, el valor cambiaría.
Veámoslo concretamente. Como aprendimos en la sección 3.1, la relación entre componentes superiores e inferiores es \(A_\mu = \eta_{\mu\nu} A^\nu\), donde solo la componente temporal cambia de signo: \(A_0 = -A^0\), \(A_i = A^i\). Entonces, si forzamos la suma con \(\mu = 0, 1, 2, 3\) con ambos índices arriba \(A^\mu B^\mu\):
En cambio, la contracción correcta \(A_\mu B^\mu\) es:
Solo la componente temporal con signo negativo. Este signo negativo es la clave de la invariancia de Lorentz.
⚪ Mei: Espera. ¿Por qué ese signo negativo está relacionado con la invariancia de Lorentz?
🟡 Lina: Separemos la rotación espacial del boost para analizarlo.
- Rotación espacial: Las componentes temporales \(A^0, B^0\) no se tocan, solo se mezclan las 3 componentes espaciales. Igual que el teorema de Pitágoras: \(A^i B^i = A^1 B^1 + A^2 B^2 + A^3 B^3\) es invariante bajo rotación.
- Boost: Los ejes temporal y espacial (por ejemplo, el eje \(x\)) se mezclan entre sí (la rotación hiperbólica de la sección 3.7 de Cap. 3).
🔵 Kai: Cuando hay un boost, ¿cómo se verifica que \(-A^0 B^0 + A^1 B^1\) es invariante?
🟡 Lina: Como vimos en la sección 3.7 de Cap. 3, un boost con rapidez \(\varphi\) (\(\tanh\varphi = v\)) tiene la forma \(t' = t\cosh\varphi - x\sinh\varphi\), \(x' = -t\sinh\varphi + x\cosh\varphi\). La misma transformación se aplica al vector contravariante \(A^\mu\): \(A^{0'} = A^0\cosh\varphi - A^1\sinh\varphi\), \(A^{1'} = -A^0\sinh\varphi + A^1\cosh\varphi\) (igual para \(B^\mu\)). Omitiendo las componentes \(y, z\) que no cambian, queremos verificar si \(A_\mu B^\mu = -A^0 B^0 + A^1 B^1\) es invariante. Sustituyendo en \(-A^{0'}B^{0'} + A^{1'}B^{1'}\), por ejemplo la parte \(A^{0'}B^{0'}\) es:
Análogamente \(A^{1'}B^{1'} = (-A^0\sinh\varphi + A^1\cosh\varphi)(-B^0\sinh\varphi + B^1\cosh\varphi)\). Al expandir y calcular \(-A^{0'}B^{0'} + A^{1'}B^{1'}\): el término con \(A^0 B^0\) queda con factor \(-\cosh^2\varphi + \sinh^2\varphi = -(\cosh^2\varphi - \sinh^2\varphi) = -1\), el término con \(A^1 B^1\) queda con factor \(-\sinh^2\varphi + \cosh^2\varphi = +(\cosh^2\varphi - \sinh^2\varphi) = +1\), y los términos cruzados (que contienen \(A^0 B^1\) o \(A^1 B^0\)) dan \(+\cosh\varphi\sinh\varphi - \cosh\varphi\sinh\varphi = 0\) y se cancelan — todo gracias a la identidad \(\cosh^2\varphi - \sinh^2\varphi = 1\) de la sección 3.6 de Cap. 3. El resultado es \(-A^0 B^0 + A^1 B^1\) — el mismo valor original. El cálculo completo expandido se puede verificar en el ejercicio → Problema A-2. Boost de Lorentz en una dirección general.
🔵 Kai: Es decir, \(\cosh^2 - \sinh^2 = 1\) combinado con "el signo negativo del tiempo" garantiza la invariancia.
🔵 Kai: Y al revés, si ponemos todo positivo \(A^0 B^0 + A^1 B^1 + \cdots\), ¿qué pasa?
🟡 Lina: Con el boost aparecería \(\cosh^2\varphi + \sinh^2\varphi \neq 1\) y el valor cambiaría. El signo negativo de la componente temporal tiene el mismo origen que el patrón de signos de \(ds^2 = -c^2 dt^2 + dx^2 + \cdots\) — es una propiedad de la métrica de Minkowski misma.
🔵 Kai: Es el mismo mecanismo que \(ds^2\) de la sección 2 de Cap. 3. Precisamente porque tiempo y espacio tienen signos diferentes, se garantiza la invariancia de la velocidad de la luz. …Entonces, ¿si el universo fuera euclídeo (todos los signos positivos), no se necesitaría la distinción arriba-abajo?
🟡 Lina: Perspicaz. Exactamente — si la métrica fuera la identidad \(\delta_{\mu\nu}\) (todo positivo), no se necesitaría distinguir entre arriba y abajo, y \(A^\mu B^\mu\) ya sería un invariante. La distinción arriba-abajo es necesaria en el espacio-tiempo de Minkowski precisamente porque tiempo y espacio tienen signos diferentes. Dicho de forma más general, si escribimos \(\Lambda\) para la transformación de Lorentz y \(\Lambda^{-1}\) para su inversa:
- El vector con índice superior \(B^\mu\) se transforma con \(\Lambda\): \(B^{\mu'} = \Lambda^{\mu'}{}_{\nu} B^\nu\)
- El vector con índice inferior \(A_\mu\) se transforma con \((\Lambda^{-1})^T\): \(A_{\mu'} = (\Lambda^{-1})^{\nu}{}_{\mu'} A_\nu\)
La fórmula de transformación concreta con índices se derivará en capítulos posteriores; por ahora recuerda solo que "los vectores contravariantes se transforman con \(\Lambda\), mientras que los covariantes se transforman con la transpuesta de la inversa de \(\Lambda\) — es decir, reciben una transformación en sentido opuesto".
🔵 Kai: Se transforman en sentidos opuestos con \(\Lambda\) y \(\Lambda^{-1}\)… es decir, ¿al emparejar arriba y abajo y multiplicar, las transformaciones se cancelan?
🟡 Lina: Exactamente. La razón intuitiva es esta — \(A_\mu B^\mu\) es un escalar (invariante) con la misma estructura que el intervalo espacio-temporal, así que si \(B^\mu\) se transforma con \(\Lambda\), entonces \(A_\mu\) debe transformarse con la inversa de \(\Lambda\) para que el producto sea invariante. Con una analogía numérica, es como "\(2 \times \frac{1}{2} = 1\)" — necesitan cancelarse. Más concretamente — cuando \(B^{\mu'} = \Lambda^{\mu'}{}_{\nu} B^\nu\) y las componentes de \(B\) se mezclan, las de \(A_{\mu'}\) se mezclan en sentido opuesto, de modo que al multiplicar y sumar (contraer), el efecto de \(\Lambda\) se cancela. Por eso, al combinar un par arriba-abajo, las matrices de transformación se cancelan y el resultado es un escalar (invariante). Con ambos arriba, \(\Lambda\) se aplica 2 veces sin cancelarse; con ambos abajo, la inversa se aplica 2 veces sin cancelarse — en ambos casos el valor cambiaría bajo transformación de Lorentz.
¿Por qué contravariante (arriba) y covariante (abajo) se transforman en sentidos opuestos?
Explicado intuitivamente: si consideramos una transformación donde la coordenada \(dx^\mu\) (índice superior) se "duplica", las componentes del vector covariante \(A_\mu\) que representa la misma magnitud física deben "reducirse a la mitad" para que el producto interno \(A_\mu\,dx^\mu\) mantenga el mismo valor. Por eso \(dx^\mu\) y \(A_\mu\) se transforman en sentidos opuestos. Para la derivación rigurosa, consulta la bibliografía (Ishii, Entender la relatividad general paso a paso con fórmulas, §3, etc.).
⚪ Mei: Es decir, la regla de "par arriba-abajo" para la contracción no es una mera convención de notación, sino una condición necesaria para garantizar la invariancia de Lorentz como física. La distinción arriba-abajo de los índices tiene un significado real.
🟡 Lina: Así es. La notación de índices es una notación que expresa de forma compacta la garantía física de que "si escribes así, automáticamente será invariante de Lorentz" — esa es la razón por la que la notación de índices es absolutamente conveniente en los cálculos de relatividad.
Comprensión unificada del producto interno y la contracción¶
⚪ Mei: Es decir, cuando Lina dijo antes "ya han usado esta operación", era porque el producto interno \(A_\mu B^\mu\) es exactamente una contracción — ambos son la misma operación de "seleccionar solo las 4 combinaciones donde los índices arriba y abajo coinciden, y sumar". Pero el producto interno es una operación de "2 vectores", y la traza de antes es una operación de "1 tensor". ¿Realmente se puede decir que son lo mismo?
🟡 Lina: Buena pregunta. En realidad, si multiplicas todas las componentes de 2 vectores \(A_\mu\) y \(B^\nu\) entre sí, obtienes una cantidad con \(4 \times 4 = 16\) componentes que es un tensor de rango 2 — esto se llama producto tensorial (tensor product). Se escribe \(A_\mu B^\nu\), y por ejemplo la componente \((\mu, \nu) = (0, 1)\) es \(A_0 B^1\), alineando todas las combinaciones. Es la misma estructura que "\(T^{\mu\nu} = A^\mu B^\nu\)" que Kai vio en 「¿Qué es un tensor?」 — donde verificamos que satisface la regla de transformación. Sumar sus componentes diagonales (contraer con \(\mu = \nu\)) da el producto interno \(A_\mu B^\mu\). Es decir, se ve diferente pero la operación está unificada.
🔵 Kai: Ya veo, producto tensorial → contracción da el producto interno. Todo está conectado.
🟡 Lina: En general, al contraer una vez un tensor de rango \(n\), se obtiene un tensor de rango \((n-2)\):
- Producto interno: rango \(1 + 1 = 2\) → después de contraer: 0 (escalar)
- Traza de tensor de rango 2: rango \(2\) → después de contraer: 0 (escalar)
- Riemann → Ricci: rango \(4\) → después de contraer: 2
- Ricci → curvatura escalar: rango \(2\) → después de contraer: 0
Este mecanismo de "reducir el rango en 2" será protagonista en Cap. 12 cuando construyamos la curvatura escalar a partir del tensor de curvatura.
✅ Verificación de comprensión: Explique en una frase por qué la contracción debe ser entre "un índice superior y un índice inferior".
Respuesta
Al contraer un par arriba-abajo, la matriz de transformación \(\Lambda\) y su inversa \(\Lambda^{-1}\) se cancelan y el resultado es un invariante de Lorentz (escalar). Con ambos arriba o ambos abajo no se cancelan, y al cambiar de sistema inercial el valor cambiaría.
📝 Ejercicios:
- Contracción de tensores, boost de Lorentz general, invariancia de la métrica de Minkowski → Problema M-1. Contracción de tensores y clasificación de índices, Problema A-2. Boost de Lorentz en una dirección general, Problema M-2. Condición de preservación de la métrica bajo transformaciones de Lorentz
4.5 Resumen — Visión de conjunto del espacio-tiempo de Minkowski¶
🟡 Lina: Organicemos el marco construido en este capítulo.
⚪ Mei: El punto de partida son dos postulados — el principio de relatividad y el principio de invariancia de la velocidad de la luz. De ahí se deduce que el intervalo espacio-temporal
es un invariante.
🔵 Kai: La transformación de coordenadas que preserva el invariante es la transformación de Lorentz. La misma estructura que la rotación espacial como "la transformación que preserva la distancia".
🟡 Lina: Y si escribimos los modelos físicos usando cantidades que se transforman correctamente bajo Lorentz — 4-vectores y tensores —, las ecuaciones tendrán la misma forma en todos los sistemas inerciales. Eso es la covariancia.
⚪ Mei: Organicemos las herramientas obtenidas en este capítulo —
Tabla 4.4: Resumen de las herramientas básicas de la relatividad especial
| Herramienta | Contenido |
|---|---|
| Intervalo espacio-temporal \(ds^2\) | \(-dt^2 + dx^2 + dy^2 + dz^2\). Escalar invariante en todos los sistemas inerciales |
| Transformación de Lorentz | Transformación de coordenadas que preserva \(ds^2\). \(t' = \gamma(t - vx)\), \(x' = \gamma(x - vt)\) |
| Métrica de Minkowski \(\eta_{\mu\nu}\) | Matriz con componentes diagonales \((-1, 1, 1, 1)\). La "forma de medir distancias" del espacio-tiempo plano |
| 4-vector \(A^\mu\) | Cantidad que bajo Lorentz sigue \(A^{\mu'} = \Lambda^{\mu'}{}_{\nu}A^\nu\) |
| 4-velocidad \(U^\mu\) | \(\gamma(1, v^x, v^y, v^z)\). Norma invariante \(U_\mu U^\mu = -1\) |
| 4-momento \(p^\mu\) | \((E, \vec{p})\). Norma invariante \(p_\mu p^\mu = -m^2\). $E^2 = |
| Subir y bajar índices | \(A_\mu = \eta_{\mu\nu}A^\nu\). El signo de la componente temporal se invierte |
| Convención de suma de Einstein | Mismo índice arriba y abajo → sumar (se omite \(\sum\)) |
⚪ Mei: La métrica de Minkowski \(\eta_{\mu\nu}\) es la métrica del espacio-tiempo plano. Como dijo Lina en la sección 1, en relatividad general se reemplaza por \(g_{\mu\nu}\) que varía según el lugar.
🟡 Lina: Exacto. Y eso es la expresión matemática de que "el espacio-tiempo se curva". En el próximo capítulo discutiremos precisamente la equivalencia entre aceleración y gravedad — el principio de equivalencia (equivalence principle) — y abriremos el camino hacia "por qué la métrica varía según el lugar".
Adelanto del próximo capítulo¶
En Cap. 5 trataremos el principio de equivalencia (equivalence principle) de Einstein. Titulado "Principio de equivalencia — la equivalencia entre aceleración y gravedad", a través del experimento mental del ascensor comprenderemos que "la aceleración y el campo gravitatorio son localmente indistinguibles", y veremos que esto es el primer paso hacia que "la métrica del espacio-tiempo \(g_{\mu\nu}\) varía según el lugar" — es decir, hacia la curvatura del espacio-tiempo.
Bibliografía¶
- Hartle, J. B. Gravity: An Introduction to Einstein's General Relativity, Chapters 4–5. Addison-Wesley, 2003.
- Schutz, B. F. A First Course in General Relativity, 3rd ed., Chapters 1–3. Cambridge University Press, 2022.
- 佐藤勝彦『相対性理論』岩波基礎物理シリーズ, 第 1–5 章. 岩波書店, 1996.
- 石井俊全『一般相対性理論を一歩一歩数式で理解する』第 8–9 章. ベレ出版, 2013.
- Lancaster, T. and Blundell, S. J. General Relativity for the Gifted Amateur, Chapters 1–2. Oxford University Press, 2014.
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.