Apéndice C Lagrangiano de campos y ecuación de Euler–Lagrange¶
Resumen de lo anterior: En Apéndice B aprendimos la definición del producto tensorial \(\otimes\) y sus reglas de cálculo, y comprendimos la estructura del espacio de tensores contravariantes \(T^r(V)\). Introdujimos la convención de suma de Einstein y confirmamos la correspondencia entre la representación por componentes de los tensores y su interpretación como aplicaciones multilineales. Con estas herramientas, quedamos preparados para escribir las ecuaciones de campo en componentes. En este capítulo, aprovechando esa notación por componentes, avanzamos hacia el principio de acción para campos y la derivación de las ecuaciones de movimiento. Cabe señalar que a partir de C.6 también usaremos los conocimientos sobre la derivada covariante aprendidos en Cap. 12. El principio de mínima acción (Cap. 1) será la base a lo largo de todo el capítulo.
Objetivo de este capítulo
- Extender el principio de acción de una partícula a un campo (field)
- Introducir el concepto de densidad lagrangiana (Lagrangian density) y derivar la ecuación de Euler–Lagrange para campos
- Además, aprender a escribir la acción de un campo en un espaciotiempo curvo y mostrar el camino hacia la acción de Einstein–Hilbert (Einstein–Hilbert action)
C.1 ¿Por qué necesitamos un principio de acción para "campos"?¶
🟡 Lina: En Cap. 1 derivamos las ecuaciones de movimiento de una partícula a partir del principio de mínima acción. En aquel momento, las variables dinámicas eran "la posición de la partícula \(x^i(t)\)" — es decir, solo había un número finito de funciones del tiempo.
Alrededor de la trayectoria real (línea continua), añadimos un desplazamiento infinitesimal \(\delta x^i\) (línea discontinua) y buscamos la condición para que la acción sea un extremo (Fig. C.1「Figura C.1: Concepto del método variacional」). En la teoría de campos, este \(\delta x^i\) se reemplaza por un desplazamiento infinitesimal del campo \(\delta\phi\) — ese es el tema de este capítulo.
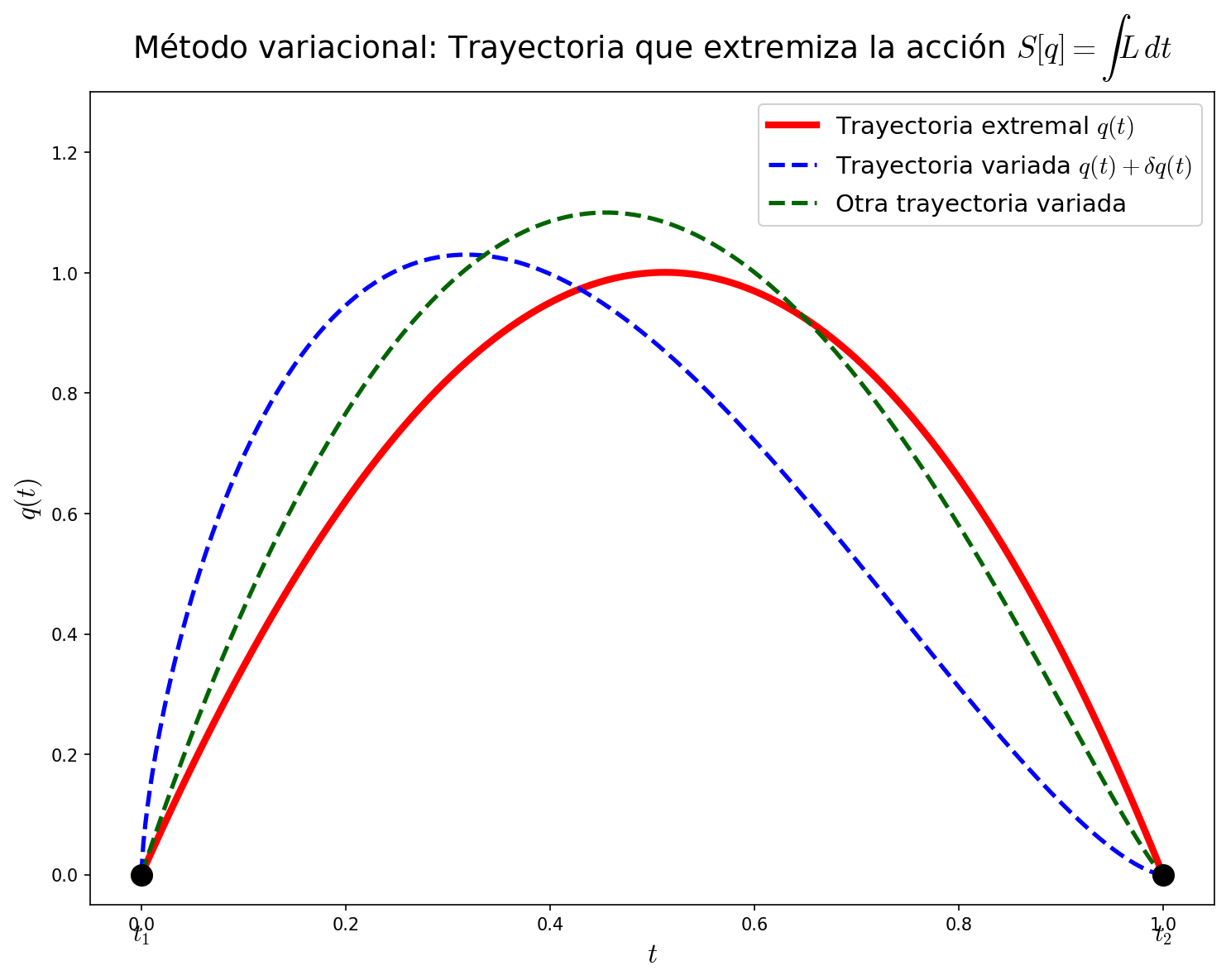
Fig. C.1: Figura C.1: Concepto del método variacional. Alrededor de la configuración real (línea continua) se añade un desplazamiento infinitesimal (línea discontinua) y se busca la condición para que la acción sea un extremo. En la mecánica de partículas \(\delta x^i\), y en la teoría de campos \(\delta\phi\), corresponden a este desplazamiento.
🔵 Kai: Sí. En tres dimensiones espaciales son \(x^1(t), x^2(t), x^3(t)\), solo 3.
🟡 Lina: Pero, ¿cuál era el protagonista de la relatividad general?
🔵 Kai: Mmm… ¿la métrica?
🟡 Lina: Exacto, el campo métrico \(g_{\mu\nu}(x)\). Este no es "un número finito de coordenadas", sino que tiene un valor asignado en cada punto del espaciotiempo. Es decir, las variables dinámicas son infinitas. No podemos usar directamente el principio de acción para partículas — necesitamos extenderlo para la teoría de campos.
🔵 Kai: En el caso de partículas buscábamos "la condición para que la acción sea un extremo al desplazar ligeramente la trayectoria". ¿Y en el caso de campos?
🟡 Lina: Buscamos "la condición para que la acción sea un extremo al desplazar ligeramente el valor del campo en cada punto". El espíritu es exactamente el mismo. Solo que la integral ya no es solo sobre el tiempo, sino sobre todo el espaciotiempo.
✅ Verificación de comprensión: ¿Cuál es la diferencia esencial entre el principio de acción para partículas y el principio de acción para campos?
Respuesta
En el caso de partículas, las variables dinámicas son un número finito de coordenadas \(x^i(t)\) y la acción es una integral solo sobre el tiempo, mientras que en el caso de campos, las variables dinámicas son el campo \(\phi(x^\mu)\) que tiene un valor en cada punto del espaciotiempo (infinitos grados de libertad) y la acción es una integral sobre todo el espaciotiempo. Sin embargo, el espíritu de "variar y buscar la condición de extremo" es el mismo.
C.2 De partículas a campos — correspondencia¶
🟡 Lina: Primero, organicemos la correspondencia entre la mecánica de partículas y la teoría de campos (Tabla C.1「Correspondencia entre mecánica de partículas y teoría de campos」).
Tabla C.1: Correspondencia entre mecánica de partículas y teoría de campos
| Mecánica de partículas | Teoría de campos |
|---|---|
| Coordenada generalizada \(q(t)\) | Campo \(\phi(x^\mu)\) |
| Velocidad generalizada \(\dot{q}\) | Derivada del campo \(\partial_\mu \phi\) |
| Lagrangiano \(L(q, \dot{q})\) | Densidad lagrangiana \(\mathcal{L}(\phi, \partial_\mu \phi)\) |
| Acción \(S = \int dt \, L\) | Acción \(S = \int d^4x \, \mathcal{L}\) |
⚪ Mei: El índice discreto \(i\) (número de la coordenada) se reemplaza por la coordenada continua del espaciotiempo \(x^\mu\).
🔵 Kai: ¿Qué es \(d^4x\)?
🟡 Lina: Es el elemento de volumen del espaciotiempo de 4 dimensiones. \(d^4x = dt\,dx\,dy\,dz\). La densidad lagrangiana \(\mathcal{L}\) del campo es "el lagrangiano por unidad de volumen", así que al integrar sobre todo el espacio obtenemos el lagrangiano total \(L\):
Si además integramos sobre el tiempo, obtenemos la acción \(S\):
⚪ Mei: Por eso \(\mathcal{L}\) se llama "densidad lagrangiana". Como es una densidad, al integrar se obtiene la cantidad total.
✅ Verificación de comprensión: Describe la relación entre la densidad lagrangiana \(\mathcal{L}\), el lagrangiano \(L\) y la acción \(S\).
Respuesta
La densidad lagrangiana \(\mathcal{L}\) es el lagrangiano por unidad de volumen; al integrar sobre todo el espacio se obtiene el lagrangiano \(L = \int d^3x\,\mathcal{L}\). Al integrar además sobre el tiempo se obtiene la acción \(S = \int d^4x\,\mathcal{L}\).
C.3 Ejemplo concreto para captar la idea — vibración de una cuerda¶
🟡 Lina: Antes de la discusión abstracta, captemos la intuición con un ejemplo familiar incluso desde el bachillerato. Consideremos una cuerda con tensión \(\mathcal{T}\) y densidad lineal \(\rho\). El desplazamiento de cada punto de la cuerda es \(\psi(x,t)\).
🔵 Kai: Como una cuerda de guitarra, ¿no?
🟡 Lina: Exacto. La densidad lagrangiana de este sistema es:
🔵 Kai: \(\frac{\partial \psi}{\partial t}\) es la velocidad de cada punto de la cuerda, así que \(\frac{1}{2}\rho v^2\) es la densidad de energía cinética… eso lo entiendo. Pero el segundo término, ¿por qué \(\left(\frac{\partial\psi}{\partial x}\right)^2\)? No me queda claro por qué el cuadrado de la pendiente se convierte en energía…
🟡 Lina: Buena pregunta. La parte de la cuerda que está inclinada tiene mayor longitud que si estuviera horizontal — la tensión \(\mathcal{T}\) que se opone a ese estiramiento realiza trabajo, por lo que se almacena energía. La longitud real de un segmento infinitesimal \(dx\) de la cuerda es \(\sqrt{1 + (\partial_x\psi)^2}\,dx \approx (1 + \frac{1}{2}(\partial_x\psi)^2)\,dx\), así que el estiramiento es proporcional a \(\frac{1}{2}(\partial_x\psi)^2\,dx\). Multiplicando por la tensión se obtiene la densidad de energía \(\frac{\mathcal{T}}{2}(\partial_x\psi)^2\).
🟡 Lina: El punto clave de este ejemplo es que la variable dinámica es \(\psi(x,t)\), un campo. Cada punto \(x\) de la cuerda juega el papel de "índice de la coordenada generalizada", de modo que hay un número continuo infinito de variables dinámicas.
✅ Verificación de comprensión: En el ejemplo de la vibración de una cuerda, ¿a qué concepto de la mecánica de partículas corresponde cada punto \(x\) de la cuerda?
Respuesta
Cada punto \(x\) de la cuerda corresponde al "índice" (número discreto \(i\)) de las coordenadas generalizadas en la mecánica de partículas. Mientras que en mecánica de partículas hay un número finito de coordenadas \(q_i(t)\), en la cuerda hay un desplazamiento \(\psi(x,t)\) para cada posición continua \(x\), por lo que las variables dinámicas son infinitas en número continuo.
📝 Ejercicios:
- Derivadas parciales de la densidad lagrangiana de la cuerda → Problema B-3. Derivadas parciales del Lagrangiano de una cuerda
C.4 Derivación de la ecuación de Euler–Lagrange para campos¶
🟡 Lina: Vamos al tema principal. Cuando la acción de un campo escalar \(\phi(x^\mu)\) está dada por
derivemos la ecuación de movimiento a partir de \(\delta S = 0\).
Paso 1: Variación del campo¶
🟡 Lina: Desplazamos el campo infinitesimalmente:
Como condición de frontera, imponemos \(\delta\phi = 0\) sobre la frontera de la región de integración \(D\). Es el mismo espíritu que cuando en el caso de partículas poníamos \(\delta x^i = 0\) en los extremos.
Paso 2: Cálculo de la variación de la acción¶
🟡 Lina: La variación a primer orden de la acción es:
Esto es la misma idea que la diferencial total de una función de varias variables. \(\mathcal{L}\) depende de dos tipos de variables, \(\phi\) y \(\partial_\mu\phi\), así que sumamos la contribución cuando \(\phi\) cambia en \(\delta\phi\) y la contribución cuando \(\partial_\mu\phi\) cambia — es la extensión del \(df = \frac{\partial f}{\partial x}dx + \frac{\partial f}{\partial y}dy\) que aprendiste en el bachillerato. La notación \(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\) significa "derivar parcialmente tratando \(\partial_\mu\phi\) como una variable independiente de \(\phi\)" — la misma idea que cuando en mecánica de partículas calculabas \(\frac{\partial L}{\partial\dot{q}}\) de \(L(q,\dot{q})\) tratando \(q\) y \(\dot{q}\) como entidades separadas. El método de cálculo concreto lo mostraré paso a paso en C.5, así que por ahora simplemente piensa "existe este símbolo".
⚪ Mei: La correspondencia \(q \to \phi\), \(\dot{q} \to \partial_\mu\phi\) que vimos en la tabla de C.2 (Tabla C.1「Correspondencia entre mecánica de partículas y teoría de campos」) se refleja directamente en la fórmula.
🟡 Lina: Exacto. Puedes ver que los términos correspondientes a \(q \to \phi\) y \(\dot{q} \to \partial_\mu \phi\) aparecen uno al lado del otro.
🔵 Kai: ¿Qué es \(\delta(\partial_\mu \phi)\)?
🟡 Lina: En conclusión, la variación y la derivada parcial conmutan, así que \(\delta(\partial_\mu \phi) = \partial_\mu(\delta\phi)\).
🔵 Kai: ¿Eh? ¿Se puede intercambiar el orden? ¿Por qué?
🟡 Lina: Intuitivamente, \(\delta\phi\) es "un desplazamiento infinitesimal del campo" que cambia ligeramente el valor del campo en cada punto \(x^\mu\), pero no desplaza la posición de la coordenada \(x^\mu\) misma — el mismo espíritu que cuando en mecánica de partículas cambiábamos la forma de la trayectoria manteniendo fijos los extremos. Por eso la operación de derivar respecto a \(x^\mu\) (\(\partial_\mu\)) y la operación de desplazar el valor del campo (\(\delta\)) no interfieren entre sí — "desplazar y luego derivar" da el mismo resultado que "derivar y luego desplazar".
🔵 Kai: ¿Porque la coordenada está fija y solo se mueve el valor del campo, la derivada parcial y la variación no interfieren… es eso?
🟡 Lina: Exactamente. Como la operación de derivar respecto a la coordenada y la operación de desplazar el valor del campo son independientes, conmutan. Verifiquémoslo un poco más concretamente. La definición de \(\partial_\mu\phi\) es "la tasa de cambio de \(\phi\) al avanzar una cantidad infinitesimal \(\epsilon\) en la dirección \(x^\mu\)", es decir:
Cuando desplazamos el campo \(\phi \to \phi + \delta\phi\), simplemente todos los \(\phi\) dentro de esta definición se reemplazan por \(\phi + \delta\phi\), así que la variación es:
Es decir, se cumple \(\delta(\partial_\mu\phi) = \partial_\mu(\delta\phi)\).
🔵 Kai: ¡Oh, si vuelves a la definición y lo escribes, sale directamente! Queda claro.
Paso 3: Integración por partes¶
🟡 Lina: Aplicamos integración por partes al segundo término. Es exactamente la misma idea que en el caso de partículas. \(\partial_\mu\) es la derivada parcial ordinaria respecto a \(x^\mu\), así que la regla del producto que aprendiste en el bachillerato se aplica tal cual. Escribiendo la versión en 4 dimensiones de \(f\,g' = (fg)' - f'\,g\):
🔵 Kai: ¡Usando \(f = \frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\), \(g = \delta\phi\) y aplicando \((fg)' = f'g + fg'\), despejé \(fg'\) hacia el lado izquierdo!
🟡 Lina: Exacto. El primer término es una divergencia total (total divergence) — es decir, tiene la forma \(\partial_\mu(\text{algo})\). Cuando integramos este tipo de términos sobre todo el espacio, por el teorema de Gauss (teorema de la divergencia) se puede convertir en una integral sobre la superficie frontera.
🔵 Kai: ¿El teorema de la divergencia es ese que aprendimos en el bachillerato de "convertir una integral de volumen en una integral de superficie"?
🟡 Lina: Sí, su generalización. En 1 dimensión es \(\int_a^b f'(x)\,dx = f(b) - f(a)\) — al integrar algo derivado, solo quedan los valores en los extremos (frontera). En 3 dimensiones, la integral de volumen se convierte en una integral de superficie sobre la frontera. En 4 dimensiones exactamente el mismo principio: la integral sobre el volumen de 4 dimensiones se convierte en una integral sobre la frontera de 3 dimensiones. Escrito como ecuación: \(\int_D \partial_\mu V^\mu\,d^4x = \oint_{\partial D} V^\mu\,dS_\mu\) — el lado izquierdo "integral de la divergencia del interior" es igual al lado derecho "integral sobre la superficie frontera". Aquí \(dS_\mu\) es el "elemento de superficie orientado" de la frontera, que puedes pensar como la versión en 4 dimensiones del vector normal \(\vec{n}\,dA\) que aparece en la integral de superficie del teorema de la divergencia en 3 dimensiones.
🔵 Kai: Sinceramente me cuesta imaginar un elemento de superficie en 4 dimensiones… pero ¿puedo pensar por ahora que es el mismo espíritu que el caso unidimensional donde "solo quedan los valores en la frontera"?
🟡 Lina: Con esa comprensión es suficiente. Y en nuestro caso, estamos poniendo \(V^\mu = \frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\,\delta\phi\). \(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\) da un número para cada valor de \(\mu\) — es decir, es una cantidad con 4 componentes, y al multiplicarla por \(\delta\phi\) (escalar) sigue teniendo 4 componentes. Por eso \(V^\mu\) puede desempeñar el papel de la "cantidad vectorial de 4 componentes" que aparece en el teorema de la divergencia. En la frontera \(\partial D\) hemos supuesto que \(\delta\phi = 0\), así que \(V^\mu\) también es cero en la frontera — por tanto el lado derecho es cero. Es decir, este término se anula.
⚪ Mei: En mecánica de partículas también anulamos el término de frontera poniendo \(\delta q = 0\) en los extremos; es exactamente el mismo argumento extendido a 4 dimensiones.
Paso 4: Ecuación de Euler–Lagrange¶
🟡 Lina: Juntando lo que queda:
Esto debe ser cero para cualquier \(\delta\phi(x)\) arbitrario. Si el contenido del corchete fuera positivo (por ejemplo) en algún punto \(x_0\), por continuidad también sería positivo en un entorno de \(x_0\). Si eligiéramos un \(\delta\phi\) que tome valores positivos solo cerca de \(x_0\) y sea cero en el resto, la integral sería positiva, contradiciendo \(\delta S = 0\).
🔵 Kai: ¿De verdad se puede construir una función que sea "positiva solo cerca de \(x_0\) y cero en el resto"? Además tiene que satisfacer la condición de frontera \(\delta\phi = 0\)…
🟡 Lina: Sí se puede. Por ejemplo, se sabe que existen funciones suaves que se elevan solo dentro de una pequeña bola centrada en \(x_0\) y son exactamente cero fuera de ella. En matemáticas, a estas funciones se las llama "funciones de soporte compacto" — el "soporte" es la región donde la función no es cero, y "compacto" significa, en términos generales, que esa región está contenida en un rango finito (no se extiende hasta el infinito). Como la frontera está en el borde de la región de integración, mientras \(x_0\) sea un punto interior, si tomamos la bola suficientemente pequeña no entrará en conflicto con las condiciones de frontera.
🔵 Kai: Ya veo, como se puede colocar una "función de prueba" así en cualquier punto interior, no hay escape.
🟡 Lina: Exacto. Por eso el contenido del corchete debe ser cero en cada punto:
Esta es la ecuación de Euler–Lagrange para campos.
⚪ Mei: La correspondencia \(q \to \phi\), \(\dot{q} \to \partial_\mu\phi\) de la tabla de C.2 (Tabla C.1「Correspondencia entre mecánica de partículas y teoría de campos」) se refleja directamente, y la estructura es completamente paralela al caso de partículas.
🔵 Kai: ¡Como la estructura es la misma, es fácil de recordar! Pero \(\partial_\mu\) es una suma sobre \(\mu = 0,1,2,3\), ¿verdad? Me pregunto cómo queda al calcularlo concretamente…
🟡 Lina: Buena pregunta. Vamos a hacerlo en la siguiente sección.
📝 Ejercicios:
- Cálculo de \(\partial\mathcal{L}/\partial\phi\) → Problema B-1. \(\partial \mathcal{L}/\partial \phi\) de Klein-Gordon, cálculo de \(\partial\mathcal{L}/\partial(\partial_\mu\phi)\) → Problema B-2. \(\partial \mathcal{L}/\partial(\partial\phi)\) de Klein-Gordon, derivadas parciales de la teoría \(\phi^4\) → Problema B-4. \(\partial \mathcal{L}/\partial \phi\) de la teoría \(\phi^4\), ecuación de Euler–Lagrange en 2 dimensiones → Problema B-6. Ecuación de Euler–Lagrange para un campo escalar en 2 dimensiones
C.5 Ejemplo concreto: ecuación de movimiento del campo escalar libre¶
🟡 Lina: Usemos la ecuación que derivamos para obtener una ecuación de movimiento concreta. La densidad lagrangiana del campo escalar libre en el espaciotiempo de Minkowski de 4 dimensiones — "libre" significa sin interacciones con otros campos, es decir, un sistema cerrado solo con \(\phi\) — es:
Puede sorprenderte el signo negativo global, pero esto está diseñado para que al expandir, gracias a \(\eta^{00} = -1\), el término con la derivada temporal sea positivo — lo verificaremos enseguida. Primero, déjame explicar de dónde viene esta expresión. Es la densidad lagrangiana de la cuerda de C.3, \(\frac{\rho}{2}(\partial_t\psi)^2 - \frac{\mathcal{T}}{2}(\partial_x\psi)^2\), extendida a 4 dimensiones y escrita de forma invariante Lorentz — es decir, de forma que no cambie bajo transformaciones de coordenadas de la relatividad especial (transformaciones de Lorentz). En la cuerda, las derivadas temporal y espacial estaban escritas por separado, pero usando \(\eta^{\mu\nu}\) podemos expresar tiempo y espacio juntos en una sola fórmula. La razón por la que es invariante Lorentz es que \(\eta^{\mu\nu}(\partial_\mu\phi)(\partial_\nu\phi)\) es una cantidad escalar con todos los índices contraídos — bajo una transformación de Lorentz cada componente cambia, pero el resultado de la contracción (la suma) no cambia. Es exactamente el mismo principio por el que el producto escalar de vectores \(\vec{a}\cdot\vec{b}\) es invariante bajo rotaciones.
🔵 Kai: Ah, es el mismo mecanismo que la invariancia del producto escalar. Entonces, ¿qué pasa con \(-\frac{m^2}{2}\phi^2\)?
🟡 Lina: \(-\frac{m^2}{2}\phi^2\) es el término de masa, que no existía en la cuerda. Se llama "masa" porque al sustituir una solución de onda plana \(\phi \propto e^{i(\vec{k}\cdot\vec{x} - \omega t)}\) — la representación de ondas mediante la exponencial compleja que aprendimos en el Apéndice A — en la ecuación de movimiento que derivaremos enseguida, se obtiene la relación de dispersión \(\omega^2 = |\vec{k}|^2 + m^2\). Esta tiene la misma forma que la relación relativista entre energía y momento \(E^2 = |\vec{p}|^2 + m^2\) (que aprendimos en Cap. 4). Es decir, \(m\) es un parámetro que corresponde a la masa en reposo de los cuantos (partículas) del campo. Verificaremos por qué se puede afirmar esto después de derivar la ecuación de Klein–Gordon al final de esta sección. Por ahora, es suficiente pensar que "\(m\) es un parámetro de peso: cuanto mayor es, más difícil es que el campo oscile".
⚪ Mei: Es decir, el término con \(\eta^{\mu\nu}\) es la versión relativista del "\(T - V\)" de la cuerda, y el término \(m^2\) es un potencial adicional debido a la masa.
🟡 Lina: Aquí \(\eta^{\mu\nu}\) es la inversa de la métrica de Minkowski \(\eta_{\mu\nu} = \mathrm{diag}(-1,+1,+1,+1)\). La inversa de una matriz diagonal es simplemente el recíproco de cada componente, así que \(1/(-1) = -1\), \(1/1 = 1\), dando \(\eta^{\mu\nu} = \mathrm{diag}(-1,+1,+1,+1)\) con los mismos componentes. Además, aquí estamos usando el sistema de unidades naturales (\(c = \hbar = 1\)). \(c = 1\) es el sistema de unidades introducido en Cap. 4 — que unifica las dimensiones de distancia y tiempo. Además aquí añadimos \(\hbar = 1\) (ponemos la constante de Planck igual a 1), unificando energía, masa, inverso de longitud e inverso de tiempo en la misma dimensión (más detalles en Cap. 25). Así las fórmulas se simplifican, pero cuando quieras volver a las unidades originales necesitas restaurar \(c\) y \(\hbar\) en los lugares apropiados mediante análisis dimensional.
🔵 Kai: Con \(c = \hbar = 1\), ¿cuál es la dimensión de \(m\) en esta fórmula?
🟡 Lina: Con \(c = \hbar = 1\), masa, energía, momento, inverso de longitud e inverso de tiempo tienen todos la misma dimensión — lo confirmamos en Cap. 25. Así que el \(m\) que aparece en la ecuación de Klein–Gordon tiene dimensión de "inverso de longitud" — puedes pensar que cuanto mayor es \(m\), más corta es la longitud de onda de Compton \(1/m\).
🔵 Kai: Pero tiene un signo negativo global… en la cuerda era \(+\frac{\rho}{2}(\dot\psi)^2 - \cdots\), ¿no? ¿De verdad queda positivo al expandir?
🟡 Lina: Verifiquémoslo. Como la componente temporal de \(\eta^{\mu\nu}\) es \(\eta^{00} = -1\), el término \(\mu=\nu=0\) de \(-\frac{1}{2}\eta^{\mu\nu}(\partial_\mu\phi)(\partial_\nu\phi)\) es \(-\frac{1}{2}\times(-1)\times(\partial_t\phi)^2 = +\frac{1}{2}(\partial_t\phi)^2\). ¿Ves? Los dos signos negativos se cancelan y queda positivo. El término de masa \(-\frac{m^2}{2}\phi^2\) también tiene la estructura "\(T - V\)" del lagrangiano — es la parte \(-V\) con la densidad de energía potencial \(V = \frac{m^2}{2}\phi^2 \geq 0\) con signo negativo.
🔵 Kai: ¿Cómo queda al expandir con \(\eta^{\mu\nu}\)?
🟡 Lina: Como \(\eta^{\mu\nu} = \mathrm{diag}(-1,+1,+1,+1)\), solo sobreviven los componentes diagonales. Expandamos primero:
Sustituyendo los valores de cada componente:
Donde \((\nabla\phi)^2 = (\partial_x\phi)^2 + (\partial_y\phi)^2 + (\partial_z\phi)^2\) es la suma de los cuadrados de las derivadas espaciales. Combinando con el \(-\frac{1}{2}\) del frente:
Añadiendo el término de masa:
⚪ Mei: El primer término es la "densidad de energía cinética" y el resto es la "densidad de energía potencial". La misma estructura \(T - V\) que en la cuerda.
🟡 Lina: Ahora calculemos la ecuación de Euler–Lagrange.
Paso 1: Derivada parcial respecto a \(\phi\):
Paso 2: Derivada parcial respecto a \(\partial_\mu \phi\). Primero muestro el resultado final:
🟡 Lina: A continuación voy a derivar paso a paso "por qué sale esto", pero primero confirmemos cómo leer esta fórmula. En el lado derecho, \(\nu\) aparece tanto en \(\eta^{\mu\nu}\) (índice superior) como en \(\partial_\nu\phi\) (índice inferior) — por la regla de contracción de Einstein aprendida en Apéndice B, cuando el mismo índice aparece una vez arriba y una vez abajo se suma sobre \(\nu = 0,1,2,3\). Es decir, \(\nu\) es un "índice de suma" (índice mudo). En cambio, \(\mu\) aparece solo una vez tanto en el lado izquierdo como en el derecho: es un "índice libre" — no se suma, y fijando un valor de \(\mu\) se obtiene una ecuación, así que esta fórmula representa 4 ecuaciones condensadas.
🔵 Kai: ¿Por qué aparece \(\eta^{\mu\nu}\partial_\nu\phi\)? Para empezar, derivar respecto a \(\partial_\mu\phi\)... no me queda claro qué se mantiene fijo y qué se varía…
🟡 Lina: El punto clave aquí es tratar \(\partial_\mu\phi\) como una variable independiente. Recuerda — en el lagrangiano de mecánica de partículas \(L(q, \dot{q})\), aunque \(q\) y \(\dot{q}\) físicamente son "la derivada temporal de \(q\)", al calcular derivadas parciales los tratábamos formalmente como variables separadas. Al calcular \(\frac{\partial L}{\partial q}\) manteníamos \(\dot{q}\) fijo, y al calcular \(\frac{\partial L}{\partial \dot{q}}\) manteníamos \(q\) fijo. ¿Por qué? Porque estamos viendo el lagrangiano como "una función con dos ranuras de entrada, \(q\) y \(\dot{q}\)". Sobre el movimiento físico existe la relación \(\dot{q} = dq/dt\), pero en la etapa de la derivada parcial estamos preguntando "si cambio solo \(\dot{q}\) manteniendo \(q\) fijo, ¿cómo cambia \(L\)?" — imponer las restricciones del movimiento real es algo que se hace después de calcular las derivadas parciales.
🔵 Kai: Ah, en el caso de partículas también tratábamos \(q\) y \(\dot{q}\) como "cosas separadas". ¿En el caso de campos es la misma idea, tratar \(\phi\) y \(\partial_0\phi, \partial_1\phi, \partial_2\phi, \partial_3\phi\) como variables separadas?
🟡 Lina: Exactamente. Tratamos un total de 5 como variables formalmente independientes. Es la misma idea que en una función ordinaria de varias variables \(f(u, v, w)\) donde \(\frac{\partial u}{\partial v} = 0\) — si \(u, v, w\) son variables independientes, mover \(v\) no cambia \(u\). Aquí \(\phi, \partial_0\phi, \partial_1\phi, \partial_2\phi, \partial_3\phi\) son esas "variables independientes". Por eso \(\frac{\partial(\partial_\alpha\phi)}{\partial(\partial_\mu\phi)} = \delta^\mu{}_\alpha\). \(\delta^\mu{}_\alpha\) es la delta de Kronecker — vale 1 cuando \(\alpha = \mu\) y 0 en caso contrario (también apareció en Cap. 6 y Apéndice B). Que los índices estén uno arriba y otro abajo es una convención notacional; aquí simplemente es un símbolo que "determina si \(\alpha\) y \(\mu\) tienen el mismo valor". Es exactamente la misma idea que en funciones de varias variables escribir \(\frac{\partial x_i}{\partial x_j} = \delta_{ij}\) (\(1\) si \(i = j\), \(0\) si \(i \neq j\)) — solo que los índices están separados arriba y abajo. Por ejemplo, si fijamos \(\mu = 1\): \(\frac{\partial(\partial_1\phi)}{\partial(\partial_1\phi)} = 1\), pero \(\frac{\partial(\partial_0\phi)}{\partial(\partial_1\phi)} = 0\) — como \(\partial_0\phi\) y \(\partial_1\phi\) son variables independientes, derivar respecto a una no mueve la otra.
⚪ Mei: La delta de Kronecker actúa como un "filtro de si es la misma variable o no".
🟡 Lina: Además, el término de masa \(-\frac{m^2}{2}\phi^2\) no contiene \(\partial_\mu\phi\), así que al derivar respecto a \(\partial_\mu\phi\) da cero — solo contribuye el término cinético \(-\frac{1}{2}\eta^{\alpha\beta}(\partial_\alpha\phi)(\partial_\beta\phi)\). Aquí he renombrado los índices mudos originales \(\mu, \nu\) como \(\alpha, \beta\) para evitar colisión con el índice \(\mu\) de la variable respecto a la cual derivamos — los índices mudos son "letras desechables para sumar", así que cambiar el nombre no cambia el significado físico.
Bien, en la definición de \(\mathcal{L}\) escribimos \(\eta^{\mu\nu}(\partial_\mu\phi)(\partial_\nu\phi)\), pero esos \(\mu, \nu\) eran índices mudos (índices para sumar), ¿verdad? Sin embargo, ahora cuando decimos "derivar respecto a \(\partial_\mu\phi\)", ese \(\mu\) es un índice libre — representa un valor fijo. Usar la misma letra con dos significados genera confusión, así que renombramos los índices mudos dentro de la densidad lagrangiana como \(\alpha, \beta\). \(\eta^{\alpha\beta}(\partial_\alpha\phi)(\partial_\beta\phi)\) es exactamente la misma cantidad que \(\eta^{\mu\nu}(\partial_\mu\phi)(\partial_\nu\phi)\) — solo cambiamos las letras. Así evitamos la colisión entre el índice de la variable de derivación \(\mu\) y los índices de la suma.
🔵 Kai: Se cambian las letras para evitar colisión de índices. Como el contenido es el mismo, no hay problema…
🟡 Lina: Ahora derivemos respecto a \(\partial_\mu \phi\). Como \(\eta^{\alpha\beta}(\partial_\alpha\phi)(\partial_\beta\phi)\) es una doble suma sobre \(\alpha, \beta\) cada uno de \(0,1,2,3\), al expandir resulta un polinomio de grado 2 en las 4 variables independientes \(\partial_0\phi, \partial_1\phi, \partial_2\phi, \partial_3\phi\). Por ejemplo, si derivamos con \(\mu = 1\), puedes pensar que "solo sobreviven los términos donde aparece \(\partial_1\phi\)". \(\eta^{\alpha\beta}\) son las componentes de la métrica de Minkowski, constantes que no dependen de \(\partial_\mu\phi\), así que salen fuera de la derivada — igual que en la derivada ordinaria \(\frac{d}{dx}[c \cdot f(x)] = c\frac{df}{dx}\). Usando la regla del producto para \(\mu\) general:
El primer término del lado derecho es "derivé el primer factor \((\partial_\alpha\phi)\) y salió \(\delta^\mu{}_\alpha\)", el segundo es "derivé el segundo factor \((\partial_\beta\phi)\) y salió \(\delta^\mu{}_\beta\)" — la misma estructura que \(\frac{d}{dx}[f(x)g(x)] = f'g + fg'\). En el primer término, \(\delta^\mu{}_\alpha\) tiene el efecto de "eliminar todo excepto \(\alpha = \mu\)" — al sumar sobre \(\alpha = 0,1,2,3\) solo sobrevive el término \(\alpha = \mu\), dando como resultado \(\eta^{\mu\beta}\partial_\beta\phi\). Por ejemplo, si \(\mu = 1\): \(\delta^1{}_0 = 0\), \(\delta^1{}_1 = 1\), \(\delta^1{}_2 = 0\), \(\delta^1{}_3 = 0\), así que los términos \(\alpha = 0,2,3\) se anulan y solo queda \(\alpha = 1\), obteniendo \(\eta^{1\beta}\partial_\beta\phi\). De forma similar, en el segundo término \(\delta^\mu{}_\beta\) deja solo el término \(\beta = \mu\), eliminando la suma sobre \(\beta\) y quedando \(\eta^{\alpha\mu}\partial_\alpha\phi\). Es decir:
🔵 Kai: ¡Así que la delta de Kronecker selecciona solo un término de la suma!
🟡 Lina: Como \(\eta^{\mu\nu}\) es simétrica (\(\eta^{\alpha\mu} = \eta^{\mu\alpha}\)), el segundo término \(\eta^{\alpha\mu}\partial_\alpha\phi\) se puede escribir como \(\eta^{\mu\alpha}\partial_\alpha\phi\). Además, si renombramos el índice mudo \(\alpha\) como \(\nu\), y el índice mudo \(\beta\) del primer término también como \(\nu\) (la letra de la suma puede ser cualquiera), ambos quedan como \(\eta^{\mu\nu}\partial_\nu\phi\). Sumando: \(2\eta^{\mu\nu}\partial_\nu\phi\). Multiplicando por el coeficiente \(-\frac{1}{2}\) del término cinético \(-\frac{1}{2}\eta^{\alpha\beta}(\partial_\alpha\phi)(\partial_\beta\phi)\) de la densidad lagrangiana: \(-\frac{1}{2} \times 2\eta^{\mu\nu}\partial_\nu\phi = -\eta^{\mu\nu}\partial_\nu\phi\).
⚪ Mei: Gracias a la simetría, los dos términos adoptan la misma forma y se cancelan exactamente con el coeficiente \(\frac{1}{2}\). Satisfactorio.
Paso 3: Aplicar \(\partial_\mu\).
🟡 Lina: El resultado del paso 2, \(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)} = -\eta^{\mu\nu}\partial_\nu\phi\), es "la ecuación cuando se fija un \(\mu\)" — por ejemplo, si \(\mu=0\) es \(-\eta^{0\nu}\partial_\nu\phi\), si \(\mu=2\) es \(-\eta^{2\nu}\partial_\nu\phi\).
🔵 Kai: En el paso 2 calculamos fijando \(\mu\), pero al sustituir en la ecuación de Euler–Lagrange ¿sumamos sobre \(\mu\)? ¿No es contradictorio?
🟡 Lina: Buena pregunta. No hay contradicción. El segundo término de la ecuación de Euler–Lagrange tiene la forma \(\partial_\mu\!\left(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\right)\), donde el \(\partial_\mu\) exterior y el \(\mu\) interior son la misma letra — es decir, aquí se tiene la estructura de sumar sobre \(\mu = 0,1,2,3\). En el paso 2, primero calculamos "qué pasa al fijar un \(\mu\)", y al final sumamos sobre todos los \(\mu\) — es simplemente un cálculo dividido en dos etapas. Escribiéndolo explícitamente: \(\partial_0(-\eta^{0\nu}\partial_\nu\phi) + \partial_1(-\eta^{1\nu}\partial_\nu\phi) + \partial_2(-\eta^{2\nu}\partial_\nu\phi) + \partial_3(-\eta^{3\nu}\partial_\nu\phi)\), una suma de 4 términos — la siguiente fórmula es eso expresado en notación de contracción. Calculando:
Aquí \(\mu\) aparece una vez arriba (en \(\eta^{\mu\nu}\)) y una vez abajo (en \(\partial_\mu\)), así que se suma sobre \(\mu = 0,1,2,3\) — es la notación resumida de la suma de 4 términos que acabamos de escribir.
En la segunda igualdad hemos usado que \(\eta^{\mu\nu}\) es constante (no depende de las coordenadas). La métrica de Minkowski \(\eta^{\mu\nu} = \mathrm{diag}(-1,1,1,1)\) es la métrica del espaciotiempo plano, así que tiene el mismo valor en cada punto — es decir, al derivar respecto a \(x^\mu\) da cero. Por eso \(\partial_\mu(\eta^{\mu\nu}\partial_\nu\phi) = \eta^{\mu\nu}\partial_\mu\partial_\nu\phi\), la derivada solo actúa sobre \(\partial_\nu\phi\). En la sección C.6, donde trataremos el espaciotiempo curvo, la métrica \(g^{\mu\nu}\) depende de las coordenadas, así que esta simplificación ya no es posible.
🔵 Kai: Ya veo, como es espaciotiempo de Minkowski la métrica es constante y se puede sacar fuera de la derivada.
🟡 Lina: Aquí la combinación \(\eta^{\mu\nu}\partial_\mu\partial_\nu\) es el operador de d'Alembert \(\Box\) que también apareció en Cap. 19. Confirmémoslo de nuevo. Un "operador" es una operación que actúa sobre una función y devuelve otra función — aquí, cuando \(\Box\) actúa sobre \(\phi\), devuelve una combinación específica de derivadas parciales de segundo orden de \(\phi\):
Aquí estamos usando \(x^0 = t\) (en unidades naturales \(c = 1\), así que \(x^0 = t\) en lugar de \(x^0 = ct\)). Al restaurar \(c\), como \(x^0 = ct\), tenemos \(\partial_0 = \frac{\partial}{\partial(ct)} = \frac{1}{c}\frac{\partial}{\partial t}\), y \(\eta^{00}\partial_0\partial_0 = (-1)\frac{1}{c^2}\frac{\partial^2}{\partial t^2}\), dando \(\Box = -\frac{1}{c^2}\frac{\partial^2}{\partial t^2} + \nabla^2\) — en el texto principal Cap. 19 usamos esta forma. Agrupando la parte espacial como \(\nabla^2 = \frac{\partial^2}{\partial x^2} + \frac{\partial^2}{\partial y^2} + \frac{\partial^2}{\partial z^2}\) (laplaciano), con \(c = 1\) queda \(\Box = -\frac{\partial^2}{\partial t^2} + \nabla^2\) de forma compacta. Usando este símbolo, el resultado anterior se escribe como \(-\Box\phi\).
Paso 4: Sustitución en la ecuación de Euler–Lagrange:
🟡 Lina: La ecuación de Euler–Lagrange era \(\frac{\partial\mathcal{L}}{\partial\phi} - \partial_\mu\!\left(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\right) = 0\). Del paso 1: \(\frac{\partial\mathcal{L}}{\partial\phi} = -m^2\phi\); del paso 3: \(\partial_\mu\!\left(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\right) = -\Box\phi\). Sustituyendo:
El segundo término se convierte en \(-(-\Box\phi) = +\Box\phi\) porque la estructura de la ecuación de Euler–Lagrange es "primer término menos segundo término \(= 0\)".
Esta es la ecuación de Klein–Gordon — la ecuación fundamental del campo escalar relativista. Ten en cuenta que en algunos libros de texto la convención de signos de \(\Box\) es la opuesta (\(\Box = +\partial_t^2 - \nabla^2\)), y en ese caso se escribe como \((\Box + m^2)\phi = 0\). Al leer otros libros, verifica la convención de signos de la métrica.
⚪ Mei: Con solo determinar una densidad lagrangiana, la ecuación de movimiento sale automáticamente a través de la ecuación de Euler–Lagrange.
🔵 Kai: Si \(m = 0\), queda \(\Box\phi = 0\)… ¿eso es la ecuación de ondas, verdad? Al expandir: \(-\frac{\partial^2\phi}{\partial t^2} + \nabla^2\phi = 0\). Entonces, cuando \(m \neq 0\), ¿se comporta diferente de una onda?
🟡 Lina: Buena observación. Si \(m = 0\) es exactamente la ecuación de ondas que se propagan a la velocidad de la luz. La ecuación de la luz (ondas electromagnéticas) también tiene esencialmente esta forma. En el caso \(m \neq 0\), la relación de dispersión cambia y componentes de diferente longitud de onda se propagan a diferentes velocidades — la masa afecta a la propagación de las ondas. Los detalles los trataremos en la parte de mecánica cuántica. Hasta aquí hemos hablado del espaciotiempo plano de Minkowski, pero ahora vamos a extenderlo al espaciotiempo curvo.
✅ Verificación de comprensión: Describe en una frase el papel de la ecuación de Euler–Lagrange para campos.
Respuesta
Es la ecuación que determina la configuración del campo que extremiza la acción \(S = \int \mathcal{L}\,d^4x\). Es la versión para teoría de campos de las ecuaciones de movimiento de partículas, y a partir de la densidad lagrangiana \(\mathcal{L}\) se derivan las ecuaciones de movimiento.
📝 Ejercicios:
- Expansión del operador de d'Alembert → Problema B-5. Escritura explícita del operador d'Alembert, derivación de la ecuación de ondas de la cuerda → Problema M-1. Derivación de la ecuación de onda de una cuerda mediante Euler–Lagrange, ecuación de movimiento de la teoría \(\phi^4\) → Problema M-2. Ecuación de movimiento de la teoría \(\phi^4\)
C.6 Acción de un campo en espaciotiempo curvo¶
🟡 Lina: Hasta ahora hemos hablado del espaciotiempo plano de Minkowski. En relatividad general el espaciotiempo está curvado, así que necesitamos reescribir la acción para el espaciotiempo curvo.
Corrección del elemento de volumen¶
🔵 Kai: ¿Qué cambia?
🟡 Lina: Primero, cambia el elemento de volumen. En el espaciotiempo plano bastaba con \(d^4x\), pero en el espaciotiempo curvo ocurre que "para la misma anchura de coordenadas, el volumen real es diferente" dependiendo de cómo se elijan las coordenadas. El elemento de volumen correcto es:
Donde \(g = \det(g_{\mu\nu})\) es el determinante de la matriz \(4 \times 4\) formada por las componentes del tensor métrico. El determinante es una cantidad que expresa con un solo número cuánto "estira o encoge" una matriz al espacio. Para una matriz \(2\times 2\) \(\begin{pmatrix}a & b\\c & d\end{pmatrix}\) el determinante es \(ad - bc\), que es igual al área con signo del paralelogramo formado por los vectores \((a,c)\) y \((b,d)\). El cálculo general para \(4\times 4\) se aprende en álgebra lineal, pero aquí solo necesitamos el hecho de que "el determinante de una matriz diagonal es el producto de los elementos diagonales". En el espaciotiempo de Minkowski con \(\eta_{\mu\nu} = \mathrm{diag}(-1,1,1,1)\), \(g = (-1)\times 1 \times 1 \times 1 = -1\), así que \(\sqrt{-g} = \sqrt{1} = 1\) y volvemos al caso original. Se escribe \(\sqrt{-g}\) con "\(-g\)" porque, con la métrica de signatura de Lorentz, la componente temporal hace que \(g < 0\) — ponemos el signo negativo para que \(-g > 0\) y luego tomamos la raíz cuadrada, obteniendo siempre un número real positivo. Para métricas generales con componentes fuera de la diagonal el cálculo es más complejo, pero conceptualmente piensa en "un solo número que expresa cuánto estira o encoge la matriz al espacio".
🔵 Kai: ¿Por qué la raíz cuadrada del determinante corrige el volumen?
🟡 Lina: Piénsalo con un ejemplo sencillo. En coordenadas polares 2D \((r, \theta)\), el elemento de área es \(dx\,dy = r\,dr\,d\theta\), ¿verdad? Cuanto mayor es \(r\), para la misma anchura angular \(d\theta\) la longitud del arco es \(r\,d\theta\) y se alarga, así que el área aumenta — esa corrección es el factor \(r\). En un sistema de coordenadas general, este factor de corrección es \(\sqrt{|\det(g_{ij})|}\). En 4 dimensiones con signatura de Lorentz, \(\det(g_{\mu\nu}) < 0\), así que escribimos \(\sqrt{-g}\).
⚪ Mei: Es decir, \(\sqrt{-g}\) desempeña el mismo papel que \(r\) en coordenadas polares — es el factor que corrige la expansión y contracción del volumen debida a la elección de coordenadas.
🟡 Lina: Este factor es la generalización de la cantidad que expresa cómo se expande o contrae el volumen bajo un cambio de coordenadas de varias variables. En matemáticas, esta "tasa de dilatación del volumen bajo un cambio de coordenadas" se llama jacobiano (Jacobian) — en el ejemplo de coordenadas polares de antes, \(r\) corresponde precisamente al jacobiano.
Corrección de la derivada parcial¶
🟡 Lina: Otra cosa. La derivada parcial \(\partial_\mu\) del espaciotiempo plano, en el espaciotiempo curvo en algunos casos debe reemplazarse por la derivada covariante \(\nabla_\mu\). ¿Por qué? Porque si derivamos normalmente un campo vectorial o tensorial, al hacer un cambio de coordenadas ya no satisface las reglas de transformación tensorial — como aprendimos en Cap. 12. Intuitivamente, en un espacio curvo no podemos restar directamente "el vector en el punto vecino" del "vector en el punto actual" (porque la dirección de los vectores de base cambia de punto a punto). La derivada covariante corrige esa "rotación de la base" y da la derivada correcta independiente del sistema de coordenadas. Sin embargo, para un campo escalar, \(\nabla_\mu \phi = \partial_\mu \phi\), así que la derivada parcial sirve tal cual.
🔵 Kai: ¿Por qué solo el campo escalar es especial?
🟡 Lina: Lo que diferencia la derivada covariante de la parcial es la corrección por los símbolos de Christoffel \(\Gamma\) — coeficientes que representan cómo rotan los vectores de base de punto a punto en un espacio curvo (ver Cap. 8). Para un campo vectorial \(V^\mu\), \(\nabla_\nu V^\mu = \partial_\nu V^\mu + \Gamma^\mu{}_{\nu\alpha}V^\alpha\), se añade el término con \(\Gamma\) que corrige el cambio de base (ver Cap. 12). Pero un campo escalar no tiene índices — es decir, \(\Gamma\) no tiene ningún índice al que "agarrarse", así que el término de corrección es cero. Por eso \(\nabla_\mu\phi = \partial_\mu\phi\).
🔵 Kai: Pero \(\partial_\mu\phi\) tiene un índice, así que es una cantidad tipo vector, ¿no? Cuando se deriva otra vez, ¿no se necesita la derivada covariante?
🟡 Lina: Aguda observación. Efectivamente, \(\partial_\mu\phi\) es un covector, y si lo derivamos de nuevo necesitamos la derivada covariante — de hecho, al realizar el mismo procedimiento variacional de C.4 para la acción que contiene \(\sqrt{-g}\), al integrar por partes también se diferencia \(\sqrt{-g}\), y la ecuación de movimiento toma la forma \(\frac{1}{\sqrt{-g}}\partial_\mu(\sqrt{-g}\,g^{\mu\nu}\partial_\nu\phi) - m^2\phi = 0\), donde \(\sqrt{-g}\) aparece enredado.
⚪ Mei: El \(\sqrt{-g}\) que no se veía en el espaciotiempo plano, en el espaciotiempo curvo aparece incluso en la ecuación de movimiento.
🟡 Lina: De hecho, \(\frac{1}{\sqrt{-g}}\partial_\mu(\sqrt{-g}\,g^{\mu\nu}\partial_\nu\phi)\) es lo mismo que \(g^{\mu\nu}\nabla_\mu\nabla_\nu\phi\) (\(= \nabla^\mu\nabla_\mu\phi\)) escrito en derivadas covariantes — es decir, la operación de "tomar dos veces la derivada covariante del campo escalar" escrita en componentes de coordenadas. Para dar una intuición de por qué son lo mismo en una frase: la derivada covariante \(\nabla_\mu\) es la derivada parcial \(\partial_\mu\) más la corrección de los símbolos de Christoffel, ¿verdad? Para un campo escalar \(\nabla_\mu\phi = \partial_\mu\phi\), pero cuando derivamos covariantemente de nuevo — es decir, cuando derivamos el covector \(\partial_\nu\phi\) — aparecen los símbolos de Christoffel. Dentro de esos símbolos de Christoffel hay derivadas de \(\sqrt{-g}\), y el resultado coincide con la forma \(\frac{1}{\sqrt{-g}}\partial_\mu(\sqrt{-g}\,\cdots)\). El cálculo detallado puedes verificarlo en el problema Problema M-3. Campo escalar sin masa en espacio-tiempo curvo. En el espaciotiempo plano, \(\sqrt{-g} = 1\) (constante) y \(g^{\mu\nu} = \eta^{\mu\nu}\), así que volvemos a \(\Box\phi - m^2\phi = 0\) de C.5 — es consistente. Pero en esta etapa solo necesitamos escribir el contenido de la densidad lagrangiana, y el \(\partial_\mu\phi\) que aparece allí es lo mismo que "la derivada covariante del campo escalar \(\phi\)", \(\nabla_\mu\phi\) (\(\nabla_\mu\phi = \partial_\mu\phi\)). Es decir, la densidad lagrangiana \(g^{\mu\nu}(\partial_\mu\phi)(\partial_\nu\phi)\) da la misma fórmula tanto si se escribe con derivadas covariantes como con derivadas parciales — así que puedes usar tranquilamente \(\partial_\mu\phi\). La operación de "derivar una vez más" al obtener la ecuación de movimiento será procesada correctamente por el principio variacional incluyendo \(\sqrt{-g}\).
Acción del campo escalar libre en espaciotiempo curvo¶
🟡 Lina: Con todo esto, la acción del campo escalar libre en espaciotiempo curvo es:
🔵 Kai: Solo cambió \(\eta^{\mu\nu} \to g^{\mu\nu}\) y se añadió \(\sqrt{-g}\).
🟡 Lina: Exacto. Esta sustitución "en la fórmula del espaciotiempo plano hacer \(\eta^{\mu\nu} \to g^{\mu\nu}\), \(d^4x \to \sqrt{-g}\,d^4x\)" se llama acoplamiento mínimo (minimal coupling), y es la receta básica para colocar campos de materia en un espaciotiempo curvo.
📝 Ejercicios:
- Cálculo de \(\sqrt{-g}\) (Minkowski) → Problema B-7. \(\sqrt{-g}\) de la métrica de Minkowski, cálculo de \(\sqrt{-g}\) (Schwarzschild) → Problema B-8. \(\sqrt{-g}\) de la métrica de Schwarzschild, derivación de la ecuación de movimiento en espaciotiempo curvo → Problema M-3. Campo escalar sin masa en espacio-tiempo curvo
C.7 La acción del propio campo gravitatorio — acción de Einstein–Hilbert¶
🔵 Kai: Ya entendí la acción de los campos de materia, pero… entonces ¿la ecuación de movimiento del propio campo métrico \(g_{\mu\nu}\) también se puede obtener del principio de acción?
🟡 Lina: Sí se puede. Y lo que se obtiene es precisamente la ecuación de Einstein. Esa acción es la acción de Einstein–Hilbert:
El coeficiente \(\frac{1}{16\pi G}\) (\(G\) es la constante de gravitación universal de Newton) es una constante de normalización determinada para que esta teoría reproduzca correctamente la ley de gravitación de Newton en el límite de campo débil. Y \(R\) es el escalar de curvatura de Ricci — una cantidad escalar que expresa con un solo número "cuánto está curvado" el espaciotiempo en cada punto. Se construye a partir del tensor de Riemann. El tensor de Riemann es la cantidad que contiene la información completa de la curvatura; intuitivamente representa "cuánto se desvía un vector de su orientación original al transportarlo paralelamente a lo largo de un pequeño bucle" — en un espacio plano la desviación es cero, pero en un espacio curvo no lo es. Ese tensor de Riemann \(R^\alpha{}_{\beta\mu\nu}\) tiene 4 índices — de izquierda a derecha: primer índice \(\alpha\), segundo índice \(\beta\), tercer índice \(\mu\), cuarto índice \(\nu\). A partir de aquí vamos "comprimiendo" la información.
🔵 Kai: De una cantidad con 4 índices, vamos contrayendo hasta llegar a sin índices (escalar).
🟡 Lina: Primero, en el tensor de Riemann \(R^\sigma{}_{\rho\mu\nu}\) contraemos el primer índice (el \(\sigma\) superior) con el tercer índice (el \(\mu\) inferior) — es decir, igualamos estos dos índices y sumamos. Concretamente, usando \(\lambda\) como índice mudo, escribimos \(R^\lambda{}_{\rho\lambda\nu}\). Entonces \(\lambda\) aparece una vez arriba y una vez abajo, así que por la regla de contracción de Einstein (que aprendimos en Apéndice B) se suma sobre \(\lambda = 0,1,2,3\) — es decir, \(R^0{}_{\rho 0\nu} + R^1{}_{\rho 1\nu} + R^2{}_{\rho 2\nu} + R^3{}_{\rho 3\nu}\), una suma de 4 términos. Así un tensor de rango 4 se "contrae" a un tensor de rango 2 — la cantidad obtenida es el tensor de Ricci \(R_{\rho\nu}\).
Luego, una contracción más usando la métrica: \(R = g^{\mu\nu}R_{\mu\nu}\) convierte el tensor de rango 2 en un escalar (tensor de rango 0) — este es el escalar de Ricci \(R\). La construcción detallada está resumida en la colección de fórmulas de Apéndice D, así que por ahora piensa en él como "un escalar que mide el grado de curvatura del espaciotiempo con un solo número".
🔵 Kai: Es muy simple…
🟡 Lina: Así es. \(R\) se construye diferenciando los símbolos de Christoffel (que se construyen a partir de las primeras derivadas de la métrica), así que contiene segundas derivadas de la métrica (recuerda la expresión por componentes del tensor de Riemann \(R^\sigma{}_{\rho\mu\nu} = \partial_\mu\Gamma^\sigma{}_{\nu\rho} - \partial_\nu\Gamma^\sigma{}_{\mu\rho} + \cdots\) — ver Cap. 13). Y entre las cantidades escalares que se pueden construir en un espaciotiempo curvo, \(R\) es la única (salvo un término constante) que contiene como máximo segundas derivadas de la métrica. Podrías pensar "¿pero \(R^2\) o \(R_{\mu\nu}R^{\mu\nu}\) no son también escalares?", pero como \(R\) mismo ya contiene segundas derivadas, elevarlo al cuadrado introduce información de cuartas derivadas — por eso no satisface la condición de "como máximo segundas derivadas". Por tanto, la acción más simple para la gravedad es la integral de \(\sqrt{-g}\,R\).
🔵 Kai: ¿Por qué restringimos a "como máximo segundas derivadas"?
🟡 Lina: Cuando el lagrangiano de una partícula \(L(q, \dot{q})\) solo contiene \(q\) y su primera derivada \(\dot{q}\), la ecuación de Euler–Lagrange es una ecuación diferencial de segundo orden, ¿verdad? De igual forma, si la densidad lagrangiana del campo solo contiene el campo y sus primeras derivadas, la ecuación de movimiento es de segundo orden. En el caso de la gravedad, la densidad lagrangiana incluye hasta segundas derivadas de la métrica (contenidas en \(R\)), pero aun así la ecuación de movimiento (ecuación de Einstein) sigue siendo una ecuación diferencial de segundo orden en la métrica. Esto se debe a una razón técnica: la parte de \(R\) que contiene las segundas derivadas se puede separar como una divergencia total (término de frontera), que no contribuye a la variación — el mismo mecanismo que vimos en el paso 3 de C.4 donde "el término de divergencia total se anula por las condiciones de frontera". Los detalles se tratan en Cap. 24 del texto principal, pero recuerda la conclusión. Si se permitieran derivadas de tercer orden o superiores, la ecuación de movimiento sería de orden superior y tendería a admitir soluciones físicamente inestables — por eso "como máximo segundas derivadas" es una restricción físicamente natural.
⚪ Mei: Es decir, la "exigencia de simplicidad" y la "estabilidad física" apuntan en la misma dirección, y el resultado es que \(R\) es la única opción.
✅ Verificación de comprensión: Explica brevemente por qué la acción de Einstein–Hilbert tiene la forma \(\sqrt{-g}\,R\).
Respuesta
Entre las cantidades escalares que se pueden construir en un espaciotiempo curvo, la única que contiene como máximo segundas derivadas de la métrica es el escalar de Ricci \(R\) (salvo una constante). Por tanto, la acción más simple para la gravedad es la integral de \(\sqrt{-g}\,R\) sobre todo el espaciotiempo.
🔵 Kai: Para obtener la ecuación de movimiento de esta acción, ¿respecto a qué se varía?
🟡 Lina: La variable dinámica es el campo métrico \(g_{\mu\nu}\), así que consideramos su variación \(\delta g_{\mu\nu}\). Sin embargo, en la práctica el cálculo suele ser más limpio usando la variación de la métrica inversa \(g^{\mu\nu}\), es decir \(\delta g^{\mu\nu}\). Como \(g_{\mu\nu}\) y \(g^{\mu\nu}\) están relacionados como matrices inversas, determinar la variación de una determina la de la otra — variar respecto a una u otra da la misma física. Al imponer \(\delta S_{\text{EH}} = 0\), se obtiene la ecuación de Einstein en el vacío \(G_{\mu\nu} = 0\). Aquí \(G_{\mu\nu} = R_{\mu\nu} - \frac{1}{2}g_{\mu\nu}R\) es el tensor de Einstein — una cantidad construida a partir del tensor de Ricci y el escalar de Ricci que describe la curvatura del espaciotiempo. El término \(-\frac{1}{2}g_{\mu\nu}R\) surge naturalmente del cálculo variacional de la acción, y el hecho de que el resultado sea automáticamente compatible con la conservación de la energía (\(\nabla_\mu T^{\mu\nu} = 0\)) se debe a la identidad de Bianchi (\(\nabla_\mu G^{\mu\nu} = 0\)) — que aprendimos en Cap. 13 y Cap. 15.
🔵 Kai: Pero la variación de una matriz inversa… ¿cómo se relacionan \(\delta g^{\mu\nu}\) y \(\delta g_{\mu\nu}\)? Además, variar \(\sqrt{-g}\) y \(R\) respecto a \(g^{\mu\nu}\) parece terriblemente complicado…
🟡 Lina: Efectivamente el cálculo es pesado. Solo respondo la relación entre \(\delta g^{\mu\nu}\) y \(\delta g_{\mu\nu}\): al variar ambos lados de \(g^{\mu\alpha}g_{\alpha\nu} = \delta^\mu_\nu\) (definición de matriz inversa), el lado derecho \(\delta^\mu_\nu\) es constante así que su variación es cero. El lado izquierdo por la regla del producto da \(\delta g^{\mu\alpha} \cdot g_{\alpha\nu} + g^{\mu\alpha} \cdot \delta g_{\alpha\nu} = 0\). Despejando \(\delta g^{\mu\alpha}\) se obtiene \(\delta g^{\mu\nu} = -g^{\mu\alpha}g^{\nu\beta}\delta g_{\alpha\beta}\) — la generalización de la fórmula de la derivada de una matriz inversa. La variación de \(\sqrt{-g}\) y \(R\) la derivaremos paso a paso en Cap. 24 del texto principal, así que por ahora quédate con el espíritu. Y ese espíritu es exactamente el mismo que la ecuación de Euler–Lagrange de C.4 — simplemente la variable dinámica es la métrica \(g^{\mu\nu}\) en lugar del campo \(\phi\).
⚪ Mei: Ya veo. En C.4 igualamos a cero el coeficiente de \(\delta\phi\) y obtuvimos la ecuación de Euler–Lagrange. Aquí, del mismo modo, igualamos a cero el coeficiente de \(\delta g^{\mu\nu}\) y sale la ecuación de Einstein — sin importar cuál sea la variable dinámica, la estructura lógica del principio variacional es la misma.
🟡 Lina: Exacto. El \(G_{\mu\nu} = 0\) de antes era el caso con solo gravedad (vacío). En el universo real hay materia, así que variando la acción total que incluye la acción de los campos de materia \(S_m\):
respecto a \(g^{\mu\nu}\), se obtiene la ecuación de Einstein completa \(G_{\mu\nu} = 8\pi G\, T_{\mu\nu}\). El tensor de energía-momento \(T_{\mu\nu}\) se define como la derivada funcional de la acción de materia \(S_m\) respecto a la métrica \(g^{\mu\nu}\).
🔵 Kai: ¿Derivada funcional? ¿Es diferente de una derivada normal?
🟡 Lina: La derivada parcial ordinaria es "la tasa de cambio al mover ligeramente una de un número finito de variables \(x_1, x_2, \ldots\)". Pero la "variable" de la acción \(S\) es \(g^{\mu\nu}(x)\), la función misma — que tiene infinitos grados de libertad, un valor en cada punto del espaciotiempo. Por eso necesitamos una herramienta para "derivar respecto a una función". Esa es la derivada funcional.
Primero una palabra sobre "funcional". Una función ordinaria recibe un número y devuelve un número, pero la acción \(S\) recibe un campo \(\phi(x)\), una función entera, y devuelve un solo número. A esta correspondencia "de función a número" se la llama funcional (functional). Escribir \(S[\phi]\) con corchetes es la marca de ello.
🔵 Kai: ¡Ah, por eso la acción se escribía \(S[\phi]\) con corchetes! Para distinguirla de una función ordinaria \(f(x)\).
🟡 Lina: Y la derivada funcional es la cantidad que expresa "cuánto cambia la acción \(S_m\) ante un cambio infinitesimal \(\delta g^{\mu\nu}(x)\) de \(g^{\mu\nu}(x)\)". Concretamente, cuando la variación de la acción se puede escribir como
ese coeficiente \(\frac{\delta S_m}{\delta g^{\mu\nu}(x)}\) es la derivada funcional. Aquí \(\mu, \nu\) son índices libres — no se suma, y para cada par \((\mu,\nu)\) (10 componentes independientes en total) se cumple una ecuación. Podrías pensar "¿\(\mu\nu\) aparece dos veces y no se suma?", pero el \(g^{\mu\nu}\) del denominador es un símbolo que especifica "respecto a qué derivamos" y no es un índice tensorial, así que no está sujeto a la regla de contracción. La notación usa \(\frac{\delta}{\ }\) en lugar del \(\frac{\partial}{\ }\) de la derivada ordinaria para distinguir esta operación especial de "derivar respecto a una función".
🟡 Lina: De hecho es exactamente lo que ya hacíamos en C.4. Allí escribimos \(\delta S = \int[\cdots]\delta\phi\,d^4x\) e igualamos a cero el coeficiente de \(\delta\phi\), ¿verdad? El contenido de ese corchete, \(\frac{\partial\mathcal{L}}{\partial\phi} - \partial_\mu\left(\frac{\partial\mathcal{L}}{\partial(\partial_\mu\phi)}\right)\), no es otra cosa que \(\frac{\delta S}{\delta\phi(x)}\). Es decir, la derivada funcional no es un nuevo método de cálculo, sino la operación que hicimos en C.4 de "variar y leer el coeficiente" a la que le hemos puesto nombre.
⚪ Mei: Ya veo, el procedimiento de C.4 era directamente la definición de la derivada funcional.
🔵 Kai: Entiendo… pero algo me preocupa: en C.4, \(\delta\phi\) era "una función arbitraria" y por eso pudimos igualar el coeficiente a cero. En el caso de \(\delta g^{\mu\nu}\), ¿realmente se puede decir "arbitrario"? La métrica parece tener simetría y restricciones…
🟡 Lina: Buena pregunta. Como \(g^{\mu\nu}\) es un tensor simétrico, \(\delta g^{\mu\nu}\) también es simétrico (\(\delta g^{\mu\nu} = \delta g^{\nu\mu}\)), esa restricción sí existe. Pero dentro de esa restricción, si consideramos "cualquier variación simétrica arbitraria", el mismo argumento permite igualar el coeficiente a cero. El punto es que si \(\delta S = \int (\text{algo})_{\mu\nu}\,\delta g^{\mu\nu}\,d^4x = 0\) y \(\delta g^{\mu\nu}\) es simétrico, entonces se exige que la parte simétrica del coeficiente sea cero — es decir, \((\text{algo})_{\mu\nu} + (\text{algo})_{\nu\mu} = 0\). El tensor de Einstein \(G_{\mu\nu}\) que resulta es simétrico desde el principio (\(G_{\mu\nu} = G_{\nu\mu}\)), así que esta condición es equivalente a \(G_{\mu\nu} = 0\) — la consistencia se mantiene.
⚪ Mei: Es decir, la simetría de la variación y la simetría de la ecuación están correctamente alineadas.
🟡 Lina: Bien, el tensor de energía-momento se define usando esta derivada funcional como:
🔵 Kai: Dividir por \(\sqrt{-g}\), multiplicar por \(2\), con signo negativo… ¿cada uno de estos coeficientes tiene un significado?
🟡 Lina: Sí. Te los explico uno por uno. Primero, la razón de dividir por \(\sqrt{-g}\) — como vimos en C.6, \(\sqrt{-g}\,d^4x\) era el "verdadero elemento de volumen" independiente de las coordenadas. El integrando de \(S_m\) contiene \(\sqrt{-g}\), así que en \(\frac{\delta S_m}{\delta g^{\mu\nu}}\) queda un factor de \(\sqrt{-g}\). Al dividir por \(\sqrt{-g}\), \(T_{\mu\nu}\) se convierte en una "cantidad por unidad de volumen verdadero" — es decir, una cantidad que se transforma correctamente como tensor bajo cambios de coordenadas.
🔵 Kai: Ya veo, dividir por \(\sqrt{-g}\) es para obtener una "densidad independiente de coordenadas".
🟡 Lina: Luego el coeficiente \(2\) — es una convención que proviene de que \(g^{\mu\nu}\) es un tensor simétrico (\(g^{\mu\nu} = g^{\nu\mu}\)), y con esta definición la ecuación de Einstein queda en la forma limpia \(G_{\mu\nu} = 8\pi G\,T_{\mu\nu}\). Finalmente el signo negativo — es un ajuste para que con la convención de signos de la métrica \((-,+,+,+)\), \(T_{00}\) (densidad de energía) sea un valor positivo. En resumen, \(T_{\mu\nu}\) es "la respuesta de la acción de la materia al variar la métrica" — se obtiene automáticamente del lagrangiano. El cálculo concreto de \(T_{\mu\nu}\) para el campo escalar libre de C.5 se trata en el problema (Problema M-4. Derivación del tensor energía-momento), así que te animo a hacerlo con tus propias manos.
🔵 Kai: Con escribir un lagrangiano, salen tanto la ecuación de movimiento como el tensor de energía-momento… Pero visto al revés, si el lagrangiano está mal, todo se desvía, ¿no? Para empezar, ¿cómo se determina el "lagrangiano correcto"? No es que valga cualquier cosa, ¿verdad?
🟡 Lina: Buena pregunta. En realidad, la "simetría" proporciona restricciones poderosas. Que la acción sea invariante bajo cambios de coordenadas, que solo contenga hasta segundas derivadas de la métrica — al imponer estas condiciones, las opciones se reducen enormemente. En el texto principal Cap. 24 lo discutimos sistemáticamente como "los 3 requisitos del principio de acción". Ese es el poder del principio de acción. Permite describir las leyes físicas de forma independiente del sistema de coordenadas, y además todas las ecuaciones se derivan unificadamente de un solo principio. Para un modelo como la relatividad general, donde "no hay sistema de coordenadas privilegiado", es la herramienta ideal.
📝 Ejercicios:
- Derivación del tensor de energía-momento → Problema M-4. Derivación del tensor energía-momento, constante cosmológica y ecuación de Einstein modificada → Problema A-2. Ecuación de Einstein con constante cosmológica, derivación de las ecuaciones de Maxwell desde el lagrangiano (problema avanzado: partiendo de la densidad lagrangiana electromagnética \(\mathcal{L}_{\text{EM}} = -\frac{1}{4}F_{\mu\nu}F^{\mu\nu}\)) → Problema A-1. Ecuaciones de Maxwell a partir del Lagrangiano del campo electromagnético
C.8 Caso con múltiples campos¶
🟡 Lina: Por último, un complemento sobre el caso con múltiples campos. En el universo real coexisten no solo el campo métrico sino también el campo electromagnético y campos de materia. En ese caso, la acción total es:
es decir, la suma de las contribuciones de cada campo y sus interacciones.
⚪ Mei: Entonces, si variamos independientemente respecto a cada campo, ¿obtenemos la ecuación de movimiento de cada uno?
🟡 Lina: Exactamente. Variando respecto a \(g_{\mu\nu}\) sale la ecuación de Einstein, respecto a \(\phi\) la ecuación de Klein–Gordon, respecto a \(A_\mu\) las ecuaciones de Maxwell — todo sale del mismo principio de acción.
🔵 Kai: Es impresionante que de una sola acción \(S\) salgan todas las ecuaciones… pero ¿este marco no tiene límites? Por ejemplo, ¿es compatible con la mecánica cuántica?
🟡 Lina: Buena pregunta. En realidad, cuando se intenta cuantizar la gravedad, este marco presenta dificultades serias. Ese es un tema que se trata en El Desafío de la Gravedad Cuántica.
🔵 Kai: Entonces esta teoría también tiene límites. Si los tiene, ¿qué habría que cambiar? ¿Deja de servir el principio de acción en sí, o hay que reescribir el contenido de la acción…?
🟡 Lina: Buena pregunta. De hecho se investigan ambas posibilidades — la dirección de mantener el "marco" del principio de acción y modificar el lagrangiano, y la dirección de cambiar el marco mismo desde los cimientos. Sin embargo, hasta el momento este marco es la mejor hipótesis no refutada experimentalmente. Su precisión predictiva y su belleza están, creo yo, entre lo mejor que la humanidad ha creado como herramienta intelectual.
⚪ Mei: Es decir, ambas direcciones son posibles, pero por ahora el principio de acción sigue en pie.
🔵 Kai: Ya veo… que la forma se determine por la simetría es hermoso. Pero eso significa que si en el futuro algún experimento más preciso detecta desviaciones de la ecuación de Einstein, ¿habría que modificar el lagrangiano?
🟡 Lina: Exacto. La simetría y la simplicidad permiten reducir enormemente los candidatos, pero en última instancia el criterio de juicio es la coherencia con los experimentos y observaciones. Qué lagrangiano ha "elegido" la naturaleza solo se puede averiguar preguntándole al experimento — esa es la actitud esencial de la física.
🟡 Lina: Mirando este capítulo en retrospectiva — con determinar una densidad lagrangiana \(\mathcal{L}\), del principio variacional sale la ecuación de movimiento. Para campos de materia la ecuación de Euler–Lagrange, para el campo gravitatorio la ecuación de Einstein. Como vimos en C.8, incluso con múltiples campos, basta variar la acción total respecto a cada campo. El marco de "derivar todo de un solo principio".
⚪ Mei: Empezando por el principio de acción de partículas, pasando por la teoría de campos, el espaciotiempo curvo, hasta la ecuación de Einstein — todo está conectado por la misma idea variacional.
🔵 Kai: Ciertamente es hermoso que todo esté conectado por un solo principio. …Pero visto al revés, ese "hilo" podría romperse en la gravedad cuántica, ¿no?
🟡 Lina: Cuida esa curiosidad. Al menos, el procedimiento de "escribir un lagrangiano y variar" que aprendimos en este capítulo juega un papel central también en la integral de caminos de la teoría cuántica de campos. Así que la idea del principio de acción sobrevive incluso en el mundo cuántico — solo que cuando se intenta cuantizar la gravedad aparecen nuevas dificultades. Ese es el tema de El Desafío de la Gravedad Cuántica.
Adelanto del próximo capítulo¶
En Apéndice D se reúnen como colección de fórmulas la métrica, los símbolos de Christoffel, el tensor de Riemann, el tensor de Ricci y el escalar de Ricci de los espaciotiempos representativos que aparecieron en el texto principal — Schwarzschild, esféricamente simétrico general, modelo cosmológico FRW y Minkowski. Es un apéndice práctico que ahorra el esfuerzo de recalcular todo desde cero, y puede consultarse repetidamente como "diccionario" para verificar resultados de cálculos y para ejercicios.
Referencias¶
- D. Tong, Lectures on General Relativity, Chapter 2: The Principle of Least Action (Cambridge, 2019).
- T. Lancaster & S. J. Blundell, Quantum Field Theory for the Gifted Amateur, Chapter 11: Lagrangian Field Theory (Oxford University Press, 2014).
- S. Carroll, Spacetime and Geometry, Chapter 4: Gravitation (Cambridge University Press, 2019).
- L. D. Landau & E. M. Lifshitz, The Classical Theory of Fields, 4th ed., Chapter 2 (Butterworth-Heinemann, 1975).
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.