Apéndice B — Representaciones del grupo de Lorentz y espinores¶
Resumen de lo anterior:
En Apéndice A organizamos las herramientas matemáticas utilizadas a lo largo de todo el Teoría Cuántica de Campos: el sistema de unidades naturales, la notación de índices tensoriales, las relaciones de anticonmutación de las matrices \(\gamma\), las convenciones de la transformada de Fourier, etc. Tomando esas notaciones como base, aquí nos adentramos en la teoría de representaciones del grupo de Lorentz, el marco que clasifica matemáticamente los tipos de campos (escalares, espinoriales, vectoriales).
Objetivo de este capítulo
- Derivar que el álgebra de Lie del grupo de Lorentz se descompone en dos \(\mathfrak{su}(2)\) independientes, y comprender que a partir de ahí los tipos de campos —escalares, vectoriales, espinoriales— se clasifican de forma natural
- En particular, esclarecer la construcción de la representación espinorial y el origen matemático de la propiedad "una rotación de \(360°\) invierte el signo"
Teoría general de transformaciones y generadores¶
🟡 Lina: En este Apéndice vamos a derivar formalmente la teoría de representaciones del grupo de Lorentz que en los capítulos 2 a Cap. 5 del texto principal "solo usamos el resultado". Primero confirmemos el punto de partida. ¿Recuerdas que en mecánica cuántica representábamos transformaciones como traslaciones y rotaciones mediante "operadores"?
🔵 Kai: Sí. En mecánica cuántica, el operador \(\hat{U}\) que desplaza el estado \(|\psi\rangle\) es unitario y conserva la probabilidad.
🟡 Lina: Exacto. Aquí comenzaremos con las transformaciones clásicas de coordenadas y repasaremos el método para extraer sus "generadores". En teoría cuántica de campos, cómo se transforma un campo bajo cada transformación de Lorentz determina el tipo de partícula en sí.
La idea de "generador" aprendida de las traslaciones¶
🟡 Lina: Empecemos con la transformación más simple: la traslación espacial. Si desplazamos la función de onda \(\psi(x)\) una distancia \(\delta a\), por desarrollo de Taylor obtenemos
🔵 Kai: Es una extensión de la derivada del bachillerato. Si la cantidad infinitesimal \(\delta a\) es pequeña, basta quedarse con el término de primer orden.
🟡 Lina: Así es. Ahora recordemos el operador de momento \(\hat{p} = -i\hbar \frac{d}{dx}\). Dividiendo ambos lados entre \(-i\hbar\) obtenemos \(\frac{d}{dx} = \frac{1}{-i\hbar}\hat{p} = \frac{i}{\hbar}\hat{p}\) (la última igualdad usa \(1/(-i) = i\). El producto del escalar \(i/\hbar\) con el operador \(\hat{p}\) no requiere preocuparse por el orden), por lo que
A este \(\hat{p}\) lo llamamos generador de la traslación. Significa "el operador que genera (produce) la transformación infinitesimal".
⚪ Mei: Es decir, el operador que realiza la traslación infinitesimal es \(\hat{U}(\delta a) = 1 + \frac{i}{\hbar}\hat{p}\,\delta a\), y lo que "impulsa" la transformación dentro de él es el generador \(\hat{p}\).
🟡 Lina: Perfecto. Entonces, ¿cómo construimos una traslación finita de distancia \(a\)?
🔵 Kai: ¿Repitiendo muchas veces la traslación infinitesimal...? Tomando \(\delta a = a/N\) y aplicándola \(N\) veces, con \(N \to \infty\)
🟡 Lina: Excelente. Es la versión matricial de \(e^x = \lim_{N\to\infty}(1 + x/N)^N\) que aprendiste en el bachillerato. Esta estructura de "transformación infinitesimal → transformación finita mediante la exponencial" aparece exactamente con la misma forma en las transformaciones de Lorentz.
✅ Verificación de comprensión: Intenta explicar en una frase qué es un generador.
Respuesta
Es el operador que produce una transformación infinitesimal. La transformación finita se construye colocando el generador en el exponente como \(e^{i\alpha G}\) (\(\alpha\) es el parámetro, \(G\) es el generador).
Estructura de grupo — condiciones que deben satisfacer las transformaciones¶
🟡 Lina: Organicemos las propiedades que satisface el operador de traslación. De las exigencias físicas surgen 3 condiciones.
① Unitariedad: En mecánica cuántica la probabilidad debe conservarse. Para que se cumpla, para cualquier estado \(|\psi\rangle\),
se requiere \(\hat{U}^\dagger \hat{U} = \mathbf{1}\), es decir, \(\hat{U}\) debe ser unitario.
② Ley de composición: Una traslación de distancia \(a\) seguida de una de distancia \(b\) resulta en una traslación total de \(a + b\):
③ Transformación identidad: La traslación nula no hace nada: \(\hat{U}(0) = \mathbf{1}\).
🔵 Kai: Las condiciones ①②③, ¿forman alguna estructura especial? Tengo la sensación de que no es una coincidencia...
🟡 Lina: Buena observación. Esto es precisamente lo que en matemáticas se llama un "grupo": un conjunto que satisface las 4 condiciones de clausura (el resultado de componer dos transformaciones es otra transformación del mismo tipo), asociatividad (al combinar 3 o más transformaciones no importa cómo se pongan los paréntesis), elemento neutro (existe una transformación que no hace nada) e inverso (para cada transformación existe otra que "deshace" la primera). ①②③ son ejemplos concretos de estas 4 condiciones (el inverso corresponde a que \(\hat{U}(-a)\) es el inverso de \(\hat{U}(a)\)). Además, en el caso de las traslaciones se cumple \(\hat{U}(a)\hat{U}(b) = \hat{U}(b)\hat{U}(a)\) — el resultado no cambia al intercambiar el orden. A este tipo de grupo se le llama grupo abeliano. Intuitivamente resulta claro que "caminar primero al este y luego al norte" da el mismo resultado que "caminar primero al norte y luego al este".
🔵 Kai: ¿Y las rotaciones? Si giras un libro \(90°\) alrededor del eje \(x\) y luego \(90°\) alrededor del eje \(z\), el resultado es distinto que hacerlo en orden inverso, ¿verdad?
🟡 Lina: Buena observación. El grupo de rotaciones es un grupo no abeliano — un grupo donde el orden de las operaciones afecta al resultado. La herramienta matemática que captura esta "diferencia de orden" es la relación de conmutación que aparecerá a continuación.
✅ Verificación de comprensión: ¿Cuál es la diferencia entre un grupo abeliano y un grupo no abeliano? ¿En cuál se clasifica el grupo de traslaciones y en cuál el de rotaciones?
Respuesta
Un grupo abeliano es un grupo donde el resultado no cambia al intercambiar el orden de las operaciones (conmutativo), un grupo no abeliano es un grupo donde el resultado cambia según el orden (no conmutativo). El grupo de traslaciones se clasifica como grupo abeliano, el grupo de rotaciones como grupo no abeliano.
Álgebra de Lorentz — relaciones de conmutación de rotaciones y boosts¶
🟡 Lina: Entremos ya en el tema principal: las transformaciones de Lorentz. En relatividad especial, las coordenadas espacio-temporales \(x^\mu = (x^0, x^1, x^2, x^3) = (ct, x, y, z)\) se transforman bajo una transformación de Lorentz como
\(\Lambda\) es una matriz que preserva la métrica de Minkowski \(\eta_{\mu\nu} = \mathrm{diag}(-1, +1, +1, +1)\). En este Apéndice usamos la misma convención de signos \((-,+,+,+)\) que en la sección de GR (el signo global de la métrica es opuesto al \((+,-,-,-)\) de estilo QFT introducido en Cap. 2, pero como se confirmó en Apéndice A, las conclusiones físicas no cambian). La razón de usar aquí el convenio de GR es que la mayoría de los libros de texto sobre teoría de representaciones del grupo de Lorentz (Schwartz, Tong, etc.) adoptan esta convención. Cuando volvamos al Cap. 5 del texto principal, basta con invertir el signo de cada componente de \(\eta_{\mu\nu}\) para traducir las fórmulas — concretamente, la condición on-shell cambia de \(P^2 \equiv \eta_{\mu\nu}P^\mu P^\nu = -m^2\) (convención de aquí) a \(P^2 = +m^2\) (convención del texto principal). Es decir
El conjunto de todas las transformaciones que satisfacen esta condición es el grupo de Lorentz.
🔵 Kai: Las transformaciones de Lorentz incluyen rotaciones y boosts, ¿verdad? ¿Cuántos parámetros tienen en total?
🟡 Lina: Buena pregunta. Escribamos una transformación de Lorentz infinitesimal cercana a la identidad como
y sustituyámosla en la ecuación (B.7). Sustituyendo \(\Lambda^\mu{}_{\alpha} = \delta^\mu{}_\alpha + \omega^\mu{}_\alpha\) obtenemos
Expandiendo el lado izquierdo y despreciando términos de segundo orden o superior en \(\omega\):
\(\eta_{\alpha\beta}\) se cancela y queda \(\eta_{\mu\beta}\,\omega^\mu{}_\alpha + \eta_{\alpha\nu}\,\omega^\nu{}_\beta = 0\). Aquí \(\eta_{\mu\beta}\,\omega^\mu{}_\alpha\) es "bajar el primer índice \(\mu\) de \(\omega^\mu{}_\alpha\) con la métrica", que se escribe como \(\omega_{\beta\alpha}\) — es decir, \(\omega_{\beta\alpha} \equiv \eta_{\mu\beta}\,\omega^\mu{}_\alpha\). De manera similar \(\eta_{\alpha\nu}\,\omega^\nu{}_\beta = \omega_{\alpha\beta}\). Esta es precisamente la operación de "subir y bajar índices con la métrica" que confirmamos en Apéndice A. Entonces la condición queda
Reescribiendo \(\alpha \leftrightarrow \beta\):
\(\omega_{\mu\nu}\) es antisimétrico — es decir, al intercambiar los índices cambia de signo (\(\omega_{\mu\nu} = -\omega_{\nu\mu}\)).
🔵 Kai: Ya veo, solo la condición de preservar la métrica restringe los parámetros a ser antisimétricos.
🟡 Lina: Una matriz antisimétrica de \(4 \times 4\) tiene todos los elementos diagonales iguales a cero y solo la parte triangular superior es libre, así que las componentes independientes son \(4 \times 3 / 2 = 6\).
⚪ Mei: \(_4C_2 = 6\). Es lo mismo que contar los elementos de la parte triangular superior.
🔵 Kai: Esos 6 parámetros, ¿a qué corresponden concretamente?
🟡 Lina: Esos 6 corresponden a 3 rotaciones espaciales (planos \(xy\), \(yz\), \(zx\)) y 3 boosts de Lorentz (direcciones \(x\), \(y\), \(z\)).
✅ Verificación de comprensión: Del hecho de que el parámetro de la transformación de Lorentz infinitesimal \(\omega_{\mu\nu}\) es antisimétrico, ¿cuántos parámetros independientes hay? ¿A qué corresponden físicamente?
Respuesta
Las componentes independientes de una matriz antisimétrica de \(4 \times 4\) son \(4 \times 3 / 2 = 6\). Corresponden a 3 rotaciones espaciales (planos \(xy\), \(yz\), \(zx\)) y 3 boosts de Lorentz (direcciones \(x\), \(y\), \(z\)).
Forma explícita de los generadores¶
🟡 Lina: Escribamos los generadores correspondientes a los 6 parámetros antisimétricos independientes como \(M^{\rho\sigma}\) (\(\rho < \sigma\)). La idea es la siguiente: como la transformación infinitesimal \(\omega^\mu{}_\nu\) se puede escribir con el parámetro antisimétrico \(\omega_{\rho\sigma}\), queremos descomponerla en la forma "parámetro × generador" como \(\omega^\mu{}_\nu = \frac{1}{2}\omega_{\rho\sigma}(M^{\rho\sigma})^\mu{}_\nu\). Es la misma idea que cuando escribimos \(\hat{U}(\delta a) = 1 + i\hat{p}\,\delta a/\hbar\) para las traslaciones.
🔵 Kai: ¿Por qué aparece el \(\frac{1}{2}\)? Si hay 6 parámetros independientes pero hacemos correr tanto \(\rho\) como \(\sigma\) de \(0\) a \(3\), ¿no salen \(16\) términos?
🟡 Lina: Buena pregunta. Como \(\omega_{\rho\sigma}\) es antisimétrico, \(\omega_{\rho\sigma} = -\omega_{\sigma\rho}\), y los términos con \(\rho < \sigma\) y \(\rho > \sigma\) no son independientes. Por ejemplo, \(\omega_{01}\) y \(\omega_{10} = -\omega_{01}\) contienen la misma información. Al sumar, cada componente independiente se cuenta dos veces, así que se corrige con \(1/2\).
Determinemos \((M^{\rho\sigma})^\mu{}_\nu\). Primero, confirmemos la subida y bajada de índices. \(\omega^\mu{}_\nu = \eta^{\mu\alpha}\omega_{\alpha\nu}\) (subimos el primer índice con la métrica). Como \(\omega_{\alpha\nu}\) es antisimétrico, \(\omega_{\alpha\nu} = -\omega_{\nu\alpha}\). Usando explícitamente esta antisimetría:
En el segundo término renombramos el índice mudo \(\alpha \to \beta\) y usamos \(\omega_{\beta\nu} = -\omega_{\nu\beta}\):
Queremos leer esto en la forma \(\frac{1}{2}\omega_{\rho\sigma}(\cdots)^\mu{}_\nu\).
🔵 Kai: "Leer", ¿qué operación es concretamente?
🟡 Lina: Básicamente, unificar los índices de \(\omega\) como \(\rho, \sigma\) y leer la parte restante como \((M^{\rho\sigma})^\mu{}_\nu\). En la convención de suma de Einstein, la letra del índice mudo sobre el que se suma puede ser cualquiera — \(\alpha\) o \(\rho\) significan lo mismo.
Captemos la intuición con un ejemplo concreto. Reconfirmemos el objetivo: queremos escribir finalmente \(\omega^\mu{}_\nu = \frac{1}{2}\omega_{\rho\sigma}(M^{\rho\sigma})^\mu{}_\nu\). Para ello necesitamos unificar los índices de \(\omega\) en \(\rho, \sigma\) en todos los términos y leer la parte restante como \((M^{\rho\sigma})^\mu{}_\nu\).
Primero el primer término. El \(\alpha\) en \(\omega_{\alpha\nu}\) es un índice mudo de suma, así que cambiar la letra a \(\rho\) no altera el significado: \(\eta^{\mu\alpha}\omega_{\alpha\nu} = \eta^{\mu\rho}\omega_{\rho\nu}\). A continuación, querríamos cambiar el \(\nu\) en \(\omega_{\rho\nu}\) por \(\sigma\), pero \(\nu\) es un índice libre (su valor está especificado desde fuera), así que no se puede cambiar la letra arbitrariamente como con un índice mudo. El objetivo aquí es "hacer que ambos índices de \(\omega\) sean \(\rho, \sigma\)" — así podremos factorizar en la forma \(\frac{1}{2}\omega_{\rho\sigma}(\cdots)^\mu{}_\nu\). Para ello insertamos \(\delta^\sigma{}_\nu\) (que vale \(1\) si \(\sigma = \nu\) y \(0\) en caso contrario), de modo que "se suma sobre \(\sigma\) pero solo sobrevive cuando \(\sigma = \nu\)": \(\omega_{\rho\nu} = \omega_{\rho\sigma}\delta^\sigma{}_\nu\). Esto es una identidad \(\sum_\sigma \omega_{\rho\sigma}\delta^\sigma{}_\nu = \omega_{\rho\nu}\) — el valor no cambia en absoluto, pero los índices de \(\omega\) quedan unificados en \(\rho, \sigma\). Así, el primer término se escribe como \(\frac{1}{2}\omega_{\rho\sigma}\,\eta^{\mu\rho}\delta^\sigma{}_\nu\).
⚪ Mei: Ya veo, insertar \(\delta^\sigma{}_\nu\) es un truco para "introducir formalmente el índice mudo \(\sigma\)". El valor no cambia, pero la notación queda unificada.
🟡 Lina: En el segundo término \(-\frac{1}{2}\eta^{\mu\beta}\omega_{\nu\beta}\) usamos el mismo procedimiento. Renombrando \(\beta \to \sigma\) obtenemos \(-\frac{1}{2}\eta^{\mu\sigma}\omega_{\nu\sigma}\). Aquí \(\omega_{\nu\sigma} = \omega_{\rho\sigma}\delta^\rho{}_\nu\) (el mismo truco — se suma sobre \(\rho\) pero solo sobrevive cuando \(\rho = \nu\)), así que obtenemos \(-\frac{1}{2}\omega_{\rho\sigma}\,\eta^{\mu\sigma}\delta^\rho{}_\nu\). Combinando los dos términos, la parte que multiplica a \(\frac{1}{2}\omega_{\rho\sigma}\) es \((\eta^{\mu\rho}\delta^\sigma{}_\nu - \eta^{\mu\sigma}\delta^\rho{}_\nu)\). En resumen:
Como \(\eta^{\mu\nu}\) es simétrica (\(\eta^{\mu\rho} = \eta^{\rho\mu}\)), \(\eta^{\mu\rho}\) y \(\eta^{\rho\mu}\) tienen el mismo valor, pero escribimos \(\mu\) primero siguiendo el flujo de la derivación. Mirando el lado derecho, al intercambiar \(\rho\) y \(\sigma\) el signo cambia — es decir, \(M^{\rho\sigma} = -M^{\sigma\rho}\) se cumple automáticamente.
Aunque parece complicado con tantos índices, \(\rho, \sigma\) son etiquetas que especifican "qué generador" y \(\mu, \nu\) son los índices que especifican la fila y columna de la matriz \(4 \times 4\).
🔵 Kai: ¿Cómo quedan escritos concretamente?
🟡 Lina: Por ejemplo, \(M^{12}\) (generador de rotación en el plano \(x^1\)-\(x^2\)): en la ecuación (B.10) con \(\rho = 1, \sigma = 2\) tenemos \((M^{12})^\mu{}_\nu = \eta^{\mu 1}\delta^{2}{}_\nu - \eta^{\mu 2}\delta^{1}{}_\nu\), así que para \(\mu = 1, \nu = 2\) da \(\eta^{11}\delta^2{}_2 - \eta^{12}\delta^1{}_2 = (+1)(1) - 0 = +1\), para \(\mu = 2, \nu = 1\) da \(\eta^{21}\delta^2{}_1 - \eta^{22}\delta^1{}_1 = 0 - (+1)(1) = -1\), el resto es cero:
\(x^1\) y \(x^2\) se mezclan — es decir, genera rotaciones en el plano \(xy\). De manera similar, \(M^{01}\) (generador de boost en la dirección \(x^1\)): con \(\rho = 0, \sigma = 1\) tenemos \((M^{01})^\mu{}_\nu = \eta^{\mu 0}\delta^1{}_\nu - \eta^{\mu 1}\delta^0{}_\nu\). Para \(\mu = 0, \nu = 1\): \(\eta^{00}\delta^1{}_1 - \eta^{01}\delta^0{}_1 = (-1)(1) - 0 = -1\). Para \(\mu = 1, \nu = 0\): \(\eta^{10}\delta^1{}_0 - \eta^{11}\delta^0{}_0 = 0 - (+1)(1) = -1\) (\(\eta^{10} = 0\) así que el primer término se anula, \(\eta^{11} = +1\), \(\delta^0{}_0 = 1\) así que el segundo término da \(-1\)):
\(x^0\) (tiempo) y \(x^1\) (espacio) se mezclan — genera boosts.
🔵 Kai: La matriz de rotación (B.11) tiene la componente \((1,2)\) (fila 2, columna 3) igual a \(+1\) y la componente \((2,1)\) (fila 3, columna 2) igual a \(-1\), mientras que la matriz de boost (B.12) tiene tanto la componente \((0,1)\) (fila 1, columna 2) como la \((1,0)\) (fila 2, columna 1) iguales a \(-1\). Me parece que tienen una simetría diferente...
⚪ Mei: Es verdad. En una los signos son opuestos y en la otra son iguales.
🟡 Lina: Buena observación. Concretamente, el generador de rotación al trasponerlo cambia de signo (matriz antisimétrica), mientras que el generador de boost no cambia al trasponerlo (matriz simétrica). Sin embargo, hay que tener cuidado. Lo que estamos viendo es el tensor mixto \((M^{\rho\sigma})^\mu{}_\nu\) dispuesto como matriz — es decir, una matriz que se lee con \(\mu\) como número de fila y \(\nu\) como número de columna. La "transposición" de esta matriz corresponde a intercambiar \(\mu\) y \(\nu\).
Pero lo que tiene significado físico es \((M^{\rho\sigma})_{\mu\nu} \equiv \eta_{\mu\alpha}(M^{\rho\sigma})^\alpha{}_\nu\) con ambos índices abajo. "Bajar el índice" es la operación de multiplicar por la métrica \(\eta_{\mu\alpha}\) y sumar — como \(\eta_{00} = -1\), solo la fila \(\mu = 0\) cambia de signo. Cuando ambos índices están abajo, tanto las rotaciones como los boosts resultan antisimétricos bajo \(\mu \leftrightarrow \nu\) — esto es consistente con que \(\omega_{\mu\nu}\) sea antisimétrico.
🔵 Kai: Entonces, que al nivel del tensor mixto la rotación parezca antisimétrica y el boost simétrico no es una diferencia esencial sino un efecto del signo de la métrica.
🟡 Lina: Que la apariencia del tensor mixto \((M^{\rho\sigma})^\mu{}_\nu\) sea diferente para rotaciones y boosts es un efecto de \(\eta_{00} = -1\). Físicamente, las rotaciones tienen un parámetro compacto (el ángulo \(\theta\) da una vuelta completa de \(0\) a \(2\pi\)), mientras que los boosts tienen un parámetro no compacto (la rapidez \(\phi\) va de \(-\infty\) a \(+\infty\)), y esta diferencia se refleja en el comportamiento de la aplicación exponencial \(e^{\omega M}\) (periódico vs no periódico).
✅ Verificación de comprensión: ¿Cuál es la diferencia en la simetría matricial entre el generador de rotación y el de boost? ¿Con qué propiedad del parámetro está relacionada?
Respuesta
Al ver el tensor mixto \((M^{\rho\sigma})^\mu{}_\nu\) como matriz, el generador de rotación es una matriz antisimétrica y el de boost es una matriz simétrica (aunque esto es un efecto de \(\eta_{00} = -1\); con ambos índices abajo ambos son antisimétricos). El parámetro de la rotación (ángulo) es compacto (da una vuelta completa de \(0\) a \(2\pi\)) mientras que el del boost (rapidez) es no compacto (\(-\infty\) a \(+\infty\)), y esta diferencia se refleja en el comportamiento de la aplicación exponencial (periódico vs no periódico).
Generadores de rotación y boost¶
🟡 Lina: Para mayor claridad física, separemos los 6 generadores en rotaciones y boosts y démosles nombre. Las \(M^{\rho\sigma}\) definidas en la ecuación (B.10) eran matrices \(4 \times 4\) antihermíticas (explicaré enseguida qué significa antihermítico). Para clasificarlas en rotaciones espaciales y boosts, primero definimos las siguientes cantidades:
Aquí \(\varepsilon^{ijk}\) es el símbolo de Levi-Civita — vale \(+1\) para permutaciones pares de los índices, \(-1\) para permutaciones impares, y \(0\) si hay índices repetidos. La tilde (\(\tilde{}\)) indica que estas cantidades son antihermíticas (lo definiremos enseguida) y por tanto incómodas de usar en física. La ecuación (B.13a) se escribió solo para mostrar la correspondencia "clasificar las 6 componentes de \(M^{\rho\sigma}\) en 3 rotaciones y 3 boosts", y enseguida las reemplazaremos por generadores hermíticos
Es decir, la relación entre \(\tilde{J}^i\) y \(J^i\) es simplemente un factor de \(-i\). Las cantidades con tilde ya no aparecerán después de la definición (B.13b) que viene a continuación.
🔵 Kai: ¿Por qué es necesario reemplazarlas? ¿No se puede seguir con \(\tilde{J}^i\)?
🟡 Lina: Buena pregunta. \(\tilde{J}^i\), \(\tilde{K}^i\) se construyeron a partir de \(M^{\rho\sigma}\) y resultan ser antihermíticos.
🔵 Kai: ¿Qué es antihermítico?
🟡 Lina: "Hermítico" significa que cumple \(A^\dagger = A\) (al trasponer y tomar el conjugado complejo se recupera la matriz original); en mecánica cuántica los observables se representan por operadores hermíticos. "Antihermítico" es lo contrario: cumple \(A^\dagger = -A\). Si miras \(M^{12}\) en la ecuación (B.11), es una matriz antisimétrica real, así que al trasponerla cambia de signo — es decir, \((M^{12})^T = -M^{12}\). Para matrices reales, la conjugación hermítica (trasponer y conjugar) es igual a la simple transposición, así que \((M^{12})^\dagger = (M^{12})^T = -M^{12}\). Esta es exactamente la condición de "antihermítico" (\(A^\dagger = -A\)). Queremos que los generadores sean hermíticos, así que multiplicamos la matriz antihermítica por \(-i\) para hacerla hermítica. Comprobémoslo: \((-iM^{12})^\dagger = (+i)(M^{12})^\dagger = (+i)(-M^{12}) = -iM^{12}\), que es hermítico.
⚪ Mei: Ya veo, al multiplicar por \(-i\) lo antihermítico se convierte en hermítico.
🟡 Lina: Exacto. Y si los generadores son hermíticos, la transformación unitaria (que conserva probabilidad) se construye naturalmente en la forma \(e^{-i\theta J}\). Por eso definimos los generadores hermíticos como:
De aquí en adelante en este capítulo, salvo indicación en contrario, \(J^i\), \(K^i\) se referirán a estos generadores hermíticos (cuando los escribamos como vectores usaremos negrita: \(\mathbf{J} = (J^1, J^2, J^3)\), \(\mathbf{K} = (K^1, K^2, K^3)\)). Entonces, usando un vector 3-dimensional \(\boldsymbol{\theta}\) que especifica los ángulos de rotación y un vector 3-dimensional \(\boldsymbol{\phi}\) que especifica las rapideces, una transformación de Lorentz finita se escribe como
🔵 Kai: Espera, en la ecuación (B.3) de la traslación teníamos \(e^{+i\hat{p}a/\hbar}\) con signo positivo, pero aquí es negativo.
🟡 Lina: Buena observación. El signo en el exponente depende de la convención de cómo se define el generador. En la ecuación (B.3) usamos la convención \(e^{+i\hat{p}a/\hbar}\) común en los libros de mecánica cuántica, pero en este libro para las transformaciones de Lorentz adoptamos la convención \(e^{-i\theta \cdot (\text{generador hermítico})}\), igual que el operador de evolución temporal \(e^{-iHt}\). Ambas convenciones dan el mismo resultado físico — la diferencia de \(\pm\) se absorbe en la definición del generador. Las matrices \(M^{\rho\sigma}\) de las ecuaciones (B.11)–(B.12) son antihermíticas, así que los generadores hermíticos corresponden a \(iM^{\rho\sigma}\). La convención de signos varía según el libro, así que recuerda que "en este libro es así".
Relaciones de conmutación del álgebra de Lorentz¶
🟡 Lina: Bien, aquí está el núcleo. Al calcular las relaciones de conmutación de los generadores \(J^i\), \(K^i\), se obtienen las siguientes 3 ecuaciones:
Estas se pueden verificar usando las matrices concretas de la ecuación (B.10), la definición (B.13b) y el factor \(-i\) de la hermitización. Como ejemplo de (B.15), calculemos \([J^1, J^2]\). (B.16) se verifica con el mismo procedimiento — por ejemplo calculando \([J^3, K^1] = [(-iM^{12}), (-iM^{01})] = -[M^{12}, M^{01}]\) mediante producto de matrices. La verificación de (B.17) se deja como ejercicio al final del capítulo.
🔵 Kai: ¿Concretamente cómo se calcula? ¿Hay que calcular el producto de matrices \(4 \times 4\) para \(J^1\) y \(J^2\)?
🟡 Lina: Así es. Primero, reescribamos la definición de la ecuación (B.13) para los generadores hermíticos. \(M^{jk}\) era una matriz antihermítica. El \(J^i\) hermítico se define como \(J^i = -i \cdot \frac{1}{2}\varepsilon^{ijk}M^{jk}\). Concretamente: \(J^1 = -iM^{23}\), \(J^2 = -iM^{31}\), \(J^3 = -iM^{12}\).
Verifiquémoslo directamente en la representación vectorial. De la ecuación (B.11), \((M^{12})^\mu{}_\nu\) tiene \(+1\) en \(\mu=1,\nu=2\) y \(-1\) en \(\mu=2,\nu=1\). Análogamente, \((M^{23})^\mu{}_\nu\) tiene \(+1\) en \(\mu=2,\nu=3\) y \(-1\) en \(\mu=3,\nu=2\); \((M^{31})^\mu{}_\nu\) tiene \(+1\) en \(\mu=3,\nu=1\) y \(-1\) en \(\mu=1,\nu=3\).
Calculemos directamente el producto matricial \([M^{23}, M^{31}]\). Basta rastrear solo las componentes no nulas del producto de matrices \(4\times 4\).
🔵 Kai: Si solo hay que rastrear las componentes no nulas, no parece tan complicado.
🟡 Lina: Así es, hagámoslo. De la ecuación (B.10), las componentes no nulas de cada generador son:
\((M^{23})^\mu{}_\nu\): Componentes no nulas: \((M^{23})^2{}_3 = +1\), \((M^{23})^3{}_2 = -1\). \((M^{31})^\mu{}_\nu\): Componentes no nulas: \((M^{31})^3{}_1 = +1\), \((M^{31})^1{}_3 = -1\).
\(AB = M^{23}M^{31}\): \((AB)^\mu{}_\nu = (M^{23})^\mu{}_\alpha (M^{31})^\alpha{}_\nu\), sumando sobre \(\alpha\). Como \((M^{23})^\mu{}_\alpha\) solo es no nula para \(\mu=2, \alpha=3\) (valor \(+1\)) y \(\mu=3, \alpha=2\) (valor \(-1\)), para \(\mu=0, 1\) tenemos \((AB)^\mu{}_\nu = 0\). - \(\mu=2\): \((M^{23})^2{}_3 \cdot (M^{31})^3{}_1 = (+1)(+1) = +1\) → \((AB)^2{}_1 = +1\) (para \(\nu \neq 1\), \((M^{31})^3{}_\nu = 0\) así que el resto es cero) - \(\mu=3\): \((M^{23})^3{}_2 \cdot (M^{31})^2{}_\nu = (-1) \cdot 0 = 0\). \((M^{31})^2{}_\nu\) es todo cero así que no contribuye.
\(BA = M^{31}M^{23}\): \((BA)^\mu{}_\nu = (M^{31})^\mu{}_\alpha (M^{23})^\alpha{}_\nu\). - \(\mu=1\): \((M^{31})^1{}_3 \cdot (M^{23})^3{}_2 = (-1)(-1) = +1\) → \((BA)^1{}_2 = +1\) - \(\mu=3\): \((M^{31})^3{}_1 \cdot (M^{23})^1{}_\nu\). \((M^{23})^1{}_\nu\) es todo cero así que no contribuye.
\([M^{23}, M^{31}] = AB - BA\): en \(\mu=2, \nu=1\): \(+1 - 0 = +1\); en \(\mu=1, \nu=2\): \(0 - (+1) = -1\). El resto es cero.
🔵 Kai: Ah, ese resultado hay que compararlo con la matriz \((M^{12})\), ¿verdad?
🟡 Lina: Comparándolo con \((M^{12})^\mu{}_\nu\) (\(+1\) en \(\mu=1,\nu=2\) y \(-1\) en \(\mu=2,\nu=1\)), tiene el signo contrario — es decir, \([M^{23}, M^{31}] = -M^{12}\).
Traduzcámoslo a generadores hermíticos. De la definición \(J^i = -i \cdot \frac{1}{2}\varepsilon^{ijk}M^{jk}\): \(J^1 = -iM^{23}\), \(J^2 = -iM^{31}\), \(J^3 = -iM^{12}\). Por lo tanto
Como \(J^3 = -iM^{12}\), tenemos \(M^{12} = iJ^3\). Por tanto \([J^1, J^2] = iJ^3\). ✓
Así queda verificada la ecuación (B.15) \([J^1, J^2] = i\varepsilon^{123}J^3 = iJ^3\) en la representación vectorial.
⚪ Mei: Los dos signos negativos se cancelan limpiamente para dar \(+iJ^3\).
🟡 Lina: El mismo resultado puede verificarse más concisamente con las matrices de Pauli. En la representación espinorial (\(2\times 2\)), con \(J^i = \sigma^i/2\):
En ambas representaciones se cumple la misma relación de conmutación. La verificación de (B.17) en la representación vectorial se deja como ejercicio al final del capítulo. Solo daré una pista: partiendo de \([K^1, K^2] = [-iM^{01}, -iM^{02}] = -[M^{01}, M^{02}]\), escribe las componentes no nulas de \(M^{02}\) de forma análoga a la ecuación (B.12) y calcula el producto matricial. El objetivo es verificar que el resultado coincide con el lado derecho de la ecuación (B.17): \(-i\varepsilon^{123}J^3\).
🔵 Kai: La primera ecuación (B.15) me resulta familiar de mecánica cuántica. Es la relación de conmutación del momento angular \([J_x, J_y] = iJ_z\). Pero me parece extraño que en el largo cálculo matricial saliera \([M^{23}, M^{31}] = -M^{12}\) con un signo negativo, y sin embargo el resultado final sea un positivo \(iJ^3\). ¿Es que el signo negativo de \((-i)^2\) y el de la multiplicación de matrices se cancelaron?
🟡 Lina: Exactamente. \([J^1, J^2] = (-i)^2[M^{23}, M^{31}] = (-1)(-M^{12}) = +M^{12} = iJ^3\): los dos signos negativos se cancelan. El factor \(-i\) de la hermitización absorbe justamente el signo del cálculo matricial.
🔵 Kai: Si no se incluyera el \(-i\) de la hermitización, la forma de la relación de conmutación cambiaría, ¿verdad?
🟡 Lina: Así es. Si usaras directamente las \(M^{jk}\) antihermíticas sin el \(-i\), la relación de conmutación tomaría una forma sin \(i\) en el lado derecho — el contenido físico es el mismo, pero no se obtiene la forma familiar \([J^i, J^j] = i\varepsilon^{ijk}J^k\) de la mecánica cuántica. Los generadores de rotación solos forman un álgebra cerrada — esto es precisamente el álgebra \(\mathfrak{so}(3)\). Y la segunda ecuación (B.16) significa que los generadores de boost \(K^j\) se transforman como un vector bajo rotaciones.
⚪ Mei: Entiendo: en \([J^i, K^j] = i\varepsilon^{ijk}K^k\) aparece \(K^k\) en el lado derecho, lo que significa que bajo rotaciones las \(K\) se mezclan entre sí — exactamente la misma estructura que las coordenadas \((x, y, z)\) mezclándose bajo rotaciones.
🟡 Lina: Así es. Y la tercera ecuación (B.17) es la complicada. El conmutador de dos boosts produce una rotación — y además con un signo negativo en el lado derecho.
🔵 Kai: ¿El signo negativo es importante?
🟡 Lina: Muy importante. Si fuera \([K^i, K^j] = +i\varepsilon^{ijk}J^k\), \(J\) y \(K\) serían equivalentes y el álgebra sería la del grupo de rotaciones 4-dimensionales \(SO(4)\). El signo negativo produce la estructura específica del grupo de Lorentz \(SO(1,3)\). Este signo negativo es la fuente de la distinción entre "mano izquierda" y "mano derecha" que veremos más adelante.
✅ Verificación de comprensión: ¿Por qué es físicamente importante el signo negativo del lado derecho de la ecuación (B.17) \([K^i, K^j] = -i\varepsilon^{ijk}J^k\)?
Respuesta
Si en lugar de un signo negativo hubiera un positivo, el álgebra sería la del grupo de rotaciones 4-dimensionales \(SO(4)\). El signo negativo produce la estructura específica del grupo de Lorentz \(SO(1,3)\) y es la fuente de la distinción entre quiralidad izquierda y derecha que surge al descomponer en \(\mathfrak{su}(2) \oplus \mathfrak{su}(2)\).
✅ Verificación de comprensión: De las relaciones de conmutación del álgebra de Lorentz (B.15)–(B.17), ¿cuál tiene la misma forma que el álgebra del grupo de rotaciones \(SO(3)\)?
Respuesta
La ecuación (B.15) \([J^i, J^j] = i\varepsilon^{ijk}J^k\). Es la relación de conmutación del momento angular en sí misma y forma el álgebra \(\mathfrak{so}(3)\) cerrada solo con los generadores de rotación.
📝 Ejercicios:
- Verificación de \([K^i, K^j] = -i\varepsilon^{ijk}J^k\) en la representación vectorial → Problema M-3. Correspondencia entre la representación \((1/2, 1/2)\) y los cuadrivectores
Descomposición en \(\mathfrak{su}(2) \oplus \mathfrak{su}(2)\) — desenredando el álgebra de Lorentz¶
🟡 Lina: Lo que viene ahora es el resultado más importante de este Apéndice. Vamos a descomponer el álgebra de Lorentz (B.15)–(B.17) en una forma más manejable. Introducimos los siguientes nuevos generadores:
🔵 Kai: Vaya, ¡de repente! ¿Por qué consideramos esta combinación? Además, lo de \(i\mathbf{K}\), multiplicar por el imaginario, es un poco incómodo...
🟡 Lina: En realidad, esto viene motivado por la idea de "querer diagonalizar las relaciones de conmutación". En (B.15)–(B.17), \(J\) y \(K\) están entrelazados entre sí. Si al cambiar a nuevas variables el entrelazamiento se deshace, ¿no sería conveniente? Es la misma idea que cuando se diagonaliza un sistema de ecuaciones mediante un cambio de variables. Multiplicamos por el imaginario \(i\) porque, debido al signo negativo en el lado derecho de la relación (B.17), no se puede separar usando solo combinaciones reales. Por ejemplo, si pruebas \(\mathbf{J} + \mathbf{K}\) y \(\mathbf{J} - \mathbf{K}\), en \([(J^i + K^i), (J^j + K^j)]\) entra \([K^i, K^j] = -i\varepsilon^{ijk}J^k\) y en el lado derecho quedan tanto \(J\) como \(K\) — no se separan. Incluyendo \(i\), el signo negativo de (B.17) se absorbe y la separación queda limpia. Pero atención — \(\mathbf{K}\) en sí no es hermítico. En la ecuación (B.13b) definimos \(K^i = -iM^{0i}\), pero la representación vectorial de \(M^{0i}\) (ecuación (B.12)) es una matriz simétrica de componentes reales, así que \((M^{0i})^\dagger = M^{0i}\). Por lo tanto \((K^i)^\dagger = (-i)^*(M^{0i})^\dagger = (+i)M^{0i} = -K^i\) — es decir, \(K^i\) es antihermítico (\(K^\dagger = -K\)). Esta es una propiedad general independiente de la representación.
⚪ Mei: Es la misma idea que en un sistema de ecuaciones cuando tomamos \(x + y\) y \(x - y\) como nuevas variables. Estamos tomando la "suma" y la "diferencia" de \(\mathbf{J}\) e \(i\mathbf{K}\).
🟡 Lina: Entonces \(i\mathbf{K}\) es hermítico, y \(\mathbf{J}_\pm = (\mathbf{J} \pm i\mathbf{K})/2\) es una suma de cantidades hermíticas. El origen matemático de que la matriz de transformación de boost \(e^{-i\boldsymbol{\phi}\cdot\mathbf{K}}\) no sea unitaria también reside aquí — esto lo verificaremos concretamente en una sección posterior. Por ahora concentrémonos en el cálculo de las relaciones de conmutación.
🟡 Lina: Calculemos entonces. Busquemos \([J^i_+, J^j_+]\). Sustituyendo la definición (B.18):
Para el conmutador se cumple la propiedad distributiva — \([A + B, C] = [A, C] + [B, C]\). Esto se verifica expandiendo: \([A+B, C] = (A+B)C - C(A+B) = AC - CA + BC - CB = [A,C] + [B,C]\). Lo mismo vale para el segundo argumento: \([A, B + C] = [A, B] + [A, C]\) (se verifica expandiendo de la misma forma). También las constantes se sacan fuera: \([cA, B] = c[A, B]\), \([A, cB] = c[A, B]\) de manera similar. Además, el conmutador es antisimétrico: \([A, B] = AB - BA = -(BA - AB) = -[B, A]\). Usando estas propiedades, expandimos:
Saquemos las constantes de cada término. Para el conmutador se cumple \([cA, B] = c[A, B]\) (sacar el escalar del primer argumento) y \([A, cB] = c[A, B]\) (sacar el escalar del segundo argumento), donde \(c\) es un escalar. Procesando cada término en orden:
- Término 1: \([J^i, J^j]\) (sin constante, se queda como está)
- Término 2: \([J^i, iK^j] = i[J^i, K^j]\) (sacamos \(i\) del segundo argumento)
- Término 3: \([iK^i, J^j] = i[K^i, J^j]\) (sacamos \(i\) del primer argumento)
- Término 4: \([iK^i, iK^j] = i[K^i, iK^j] = i \cdot i[K^i, K^j] = i^2[K^i, K^j]\) (sacamos en dos pasos)
Resumiendo:
🔵 Kai: Salen 4 conmutadores. Solo hay que sustituir uno por uno.
🟡 Lina: Reemplacemos cada término usando (B.15)–(B.17). Habrá que hacer algún intercambio de índices, así que lo haré con cuidado.
- Término 1: \([J^i, J^j] = i\varepsilon^{ijk}J^k\) …… directamente (B.15)
- Término 2: \(i[J^i, K^j] = i \cdot i\varepsilon^{ijk}K^k = -\varepsilon^{ijk}K^k\) …… usando (B.16)
- Término 3: \(i[K^i, J^j]\). Lo obtenemos intercambiando índices en (B.16). Por la antisimetría del conmutador \([A, B] = -[B, A]\): \([K^i, J^j] = -[J^j, K^i]\). Ahora (B.16) tiene la forma "\([J^{\text{(primero)}}, K^{\text{(segundo)}}] = i\varepsilon^{\text{(primero)(segundo)}k}K^k\)", así que leyendo el primero como \(j\) y el segundo como \(i\): \([J^j, K^i] = i\varepsilon^{jik}K^k\). El símbolo de Levi-Civita cambia de signo al intercambiar dos índices adyacentes (es totalmente antisimétrico) — por ejemplo, \(\varepsilon^{jik}\) resulta de intercambiar los dos primeros índices \(i, j\) de \(\varepsilon^{ijk}\), así que \(\varepsilon^{jik} = -\varepsilon^{ijk}\). Por lo tanto \([J^j, K^i] = i(-\varepsilon^{ijk})K^k = -i\varepsilon^{ijk}K^k\). Sustituyendo en \([K^i, J^j] = -[J^j, K^i]\): \([K^i, J^j] = -(-i\varepsilon^{ijk}K^k) = +i\varepsilon^{ijk}K^k\). Finalmente \(i[K^i, J^j] = i \cdot i\varepsilon^{ijk}K^k = i^2\varepsilon^{ijk}K^k = -\varepsilon^{ijk}K^k\)
- Término 4: \(i^2[K^i, K^j] = -[K^i, K^j] = -(-i\varepsilon^{ijk}J^k) = i\varepsilon^{ijk}J^k\) …… usando (B.17)
🔵 Kai: Los términos 2 y 3 dan lo mismo: \(-\varepsilon^{ijk}K^k\).
🟡 Lina: Sumando los 4 términos:
🔵 Kai: Hmm, \(iJ^k - K^k\), ¿no se puede reescribir como algo? Me recuerda a la definición de \(J_+\)...
🟡 Lina: Buena observación. \(J^k_+ = (J^k + iK^k)/2\) así que \(2J^k_+ = J^k + iK^k\), es decir \(i(J^k + iK^k) = iJ^k - K^k = 2iJ^k_+\). Por lo tanto
🟡 Lina: Perfecto. Es decir
🔵 Kai: ¡Oh! ¡Tiene la misma forma que la ecuación (B.15) con \(J\) reemplazado por \(J_+\)! ¡Es la misma relación de conmutación que el momento angular! Pero \(\mathbf{J}_+\) contiene el generador de boost \(\mathbf{K}\), y \(\mathbf{K}\) era antihermítico. ¿No causa problemas que una cantidad así satisfaga las mismas relaciones de conmutación que el momento angular?
🟡 Lina: Buena duda. Las relaciones de conmutación determinan la "estructura del álgebra" y son independientes de si los operadores son hermíticos o no. Los operadores que satisfacen el álgebra \(\mathfrak{su}(2)\) no necesitan ser hermíticos — solo que en ese caso la representación no será unitaria. En realidad, \(\mathbf{J}_+\) en sí resulta hermítico en representaciones concretas, pero el \(\mathbf{K}\) que se deduce de ahí es antihermítico, lo que constituye el origen matemático de la no unitariedad de los boosts. Por ahora concentrémonos solo en la estructura de las relaciones de conmutación y avancemos. Con exactamente el mismo cálculo se demuestra
Y lo más importante es
🔵 Kai: ¡Cero! ¿Eso significa que \(J_+\) y \(J_-\) son completamente independientes? Pero \(J_+\) contiene \(K\) y \(J_-\) también contiene \(K\), ¿por qué el conmutador da cero? ¿Y qué ventaja tiene que sean independientes?
🟡 Lina: "Por qué da cero" se puede verificar con el mismo procedimiento que usamos para \([J^i_+, J^j_+]\) — los 4 términos forman 2 parejas que se cancelan entre sí (verifícalo en el apartado de comprensión de abajo). Y "qué ventaja tiene" — esto es muy importante. Que sean independientes significa que podemos elegir por separado la representación de \(\mathbf{J}_+\) y la de \(\mathbf{J}_-\). El problema complejo de 6 generadores entrelazados se descompone en dos problemas independientes de 3 generadores cada uno. ¡Y cada grupo de 3 es el álgebra de \(\mathrm{SU}(2)\) — algo que sabemos resolver completamente de la mecánica cuántica! Es decir:
El álgebra de Lie del grupo de Lorentz se descompone en la suma directa de dos álgebras \(\mathfrak{su}(2)\) independientes: \(\mathfrak{su}(2) \oplus \mathfrak{su}(2)\).
⚪ Mei: Es decir, para encontrar las representaciones del álgebra de Lorentz, basta elegir independientemente la representación de \(\mathbf{J}_+\) y la de \(\mathbf{J}_-\).
🔵 Kai: Un momento. "Elegir representaciones independientemente", ¿qué operación es concretamente? ¿Algo como elegir espín \(1/2\) para \(\mathbf{J}_+\) y espín \(0\) para \(\mathbf{J}_-\)?
🟡 Lina: Exactamente eso. Como aprendiste en mecánica cuántica, las representaciones de \(\mathrm{SU}(2)\) se clasifican por el valor del espín \(j = 0, 1/2, 1, 3/2, \ldots\) y la dimensión es \(2j+1\). Elegir \(j_+ = 1/2\) para \(\mathbf{J}_+\) y \(j_- = 0\) para \(\mathbf{J}_-\) — eso es la representación \((1/2, 0)\), que corresponde al espinor de Weyl levógiro. Por eso las representaciones del grupo de Lorentz se especifican con un par \((j_+, j_-)\). Esta es la base matemática de la clasificación de campos.
🔵 Kai: Pero "elegir \(j_- = 0\)" significa que \(\mathbf{J}_-\) se convierte en la matriz nula de \(2\times 2\), ¿no? Eso quiere decir que "\(\mathbf{J}_-\) no hace nada" y... espera. ¿\(\mathbf{J}_- = (\mathbf{J} - i\mathbf{K})/2 = 0\) significa que \(\mathbf{J} = i\mathbf{K}\)? ¿Las rotaciones y los boosts están completamente vinculados?
🟡 Lina: ¡Excelente, exactamente! \(\mathbf{J} = i\mathbf{K}\) (es decir \(\mathbf{K} = -i\mathbf{J}\)) — si conoces el generador de rotación, el de boost queda automáticamente determinado. Esta restricción de que "rotación y boost no se pueden elegir independientemente" es precisamente el contenido matemático de "mano izquierda". Las matrices concretas las construiremos en la siguiente sección.
✅ Verificación de comprensión: ¿Cuál es la utilidad práctica de que el álgebra de Lorentz se descomponga en \(\mathfrak{su}(2) \oplus \mathfrak{su}(2)\)?
Respuesta
Para encontrar las representaciones del álgebra de Lorentz, basta elegir por separado las representaciones de los dos \(\mathfrak{su}(2)\) independientes. Como las representaciones de \(\mathrm{SU}(2)\) se clasifican por el número cuántico de espín \(j = 0, 1/2, 1, \ldots\), las representaciones del grupo de Lorentz se especifican con el par \((j_+, j_-)\), lo que permite clasificar sistemáticamente los tipos de campo (escalar, espinorial, vectorial, etc.).
✅ Verificación de comprensión: Derive la ecuación (B.22) \([J^i_+, J^j_-] = 0\) usando (B.15)–(B.17).
Respuesta
\([J^i_+, J^j_-] = \frac{1}{4}([J^i, J^j] - i[J^i, K^j] + i[K^i, J^j] - i^2[K^i, K^j])\) \(= \frac{1}{4}(i\varepsilon^{ijk}J^k + \varepsilon^{ijk}K^k - \varepsilon^{ijk}K^k - i\varepsilon^{ijk}J^k) = 0\). Los términos 2 y 3 se cancelan, y los términos 1 y 4 también. Aquí el término 2 es \(-i \cdot i\varepsilon^{ijk}K^k = \varepsilon^{ijk}K^k\), el término 3 es \(i \cdot i\varepsilon^{ijk}K^k = -\varepsilon^{ijk}K^k\) (mismo procedimiento que en el cálculo anterior), y el término 4 es \(+[K^i, K^j] = -i\varepsilon^{ijk}J^k\).
📝 Ejercicios:
- Rederivación del álgebra de Lorentz a partir de \(\mathbf{J}_\pm\) → Problema B-5. Recuperación de los generadores de rotación usando el símbolo de Levi-Civita
Clasificación de representaciones — organizando los tipos de campo con \((j_+, j_-)\)¶
🟡 Lina: Las representaciones irreducibles de \(\mathrm{SU}(2)\) se clasifican por el número cuántico de espín \(j = 0, 1/2, 1, \ldots\) y tienen dimensión \(2j + 1\). Como las representaciones del grupo de Lorentz se especifican con el par \((j_+, j_-)\), la dimensión de la representación es \((2j_+ + 1)(2j_- + 1)\). Resumamos las representaciones principales en una tabla.
Tabla B.1: Principales representaciones irreducibles del grupo de Lorentz y campos correspondientes
| Representación \((j_+, j_-)\) | Dimensión | Nombre | Campo correspondiente |
|---|---|---|---|
| \((0, 0)\) | \(1\) | Escalar (scalar) | Campo de Higgs |
| \((1/2, 0)\) | \(2\) | Espinor de Weyl levógiro | \(\psi_L\) |
| \((0, 1/2)\) | \(2\) | Espinor de Weyl dextrógiro | \(\psi_R\) |
| \((1/2, 0) \oplus (0, 1/2)\) | \(4\) | Espinor de Dirac | Campo del electrón |
| \((1/2, 1/2)\) | \(4\) | Vector (vector) | Campo electromagnético \(A^\mu\) |
🔵 Kai: El campo escalar es \((0, 0)\) y el campo vectorial es \((1/2, 1/2)\)... ¿El espín del campo vectorial corresponde a \(1/2 + 1/2 = 1\)?
🟡 Lina: Buena intuición. Más precisamente, el generador de rotación original es \(\mathbf{J} = \mathbf{J}_+ + \mathbf{J}_-\) (resolviendo la ecuación (B.18) al revés se confirma que \(\mathbf{J} = \mathbf{J}_+ + \mathbf{J}_-\)), así que el espín de rotación se determina por la composición de momentos angulares de \(j_+\) y \(j_-\). Usando la regla de composición que aprendiste en mecánica cuántica \(|j_+ - j_-| \leq j \leq j_+ + j_-\), para \((1/2, 1/2)\) se obtiene \(j = 0\) o \(j = 1\). La componente temporal de un 4-vector corresponde a espín \(0\) (tipo escalar) y las 3 componentes espaciales a espín \(1\) (tipo vectorial).
⚪ Mei: Entiendo. Que el espinor de Dirac se escriba como \((1/2, 0) \oplus (0, 1/2)\) significa que combina espinores de 2 componentes levógiro y dextrógiro para formar 4 componentes.
🟡 Lina: Exacto. Y la razón por la que es necesario combinar ambos está profundamente relacionada con la estructura del término de masa. Esto se trató en detalle en Cap. 5 del texto principal.
¿Por qué no existen partículas de espín \(1/3\)?¶
🔵 Kai: Por cierto, en la tabla solo aparecen espín \(0, 1/2, 1\), ¿por qué no existen partículas de espín \(1/3\)?
🟡 Lina: Excelente pregunta. Se determina a partir de la teoría de representaciones de \(\mathrm{SU}(2)\). Los operadores de ascenso y descenso del momento angular \(J_\pm = J_1 \pm iJ_2\) cambian el autovalor de \(J_3\) en \(\pm 1\). Partiendo del estado de valor máximo \(|j, j\rangle\) y aplicando \(J_-\) repetidamente:
Se desciende en pasos enteros desde \(j\) hasta \(-j\). Para que se detenga exactamente en \(|j, -j\rangle\), \(j - (-j) = 2j\) debe ser un entero no negativo.
⚪ Mei: Es decir, solo se permiten \(j = 0, 1/2, 1, 3/2, 2, \ldots\). Con \(j = 1/3\) tendríamos \(2j = 2/3\) que no es entero, así que no se puede llegar a \(-j\).
🟡 Lina: Exacto. Esta es una conclusión universal de la teoría de representaciones de \(\mathrm{SU}(2)\), no limitada al grupo de Lorentz. Los espines de las partículas que pueden existir en la naturaleza se restringen a \(0, 1/2, 1, 3/2, 2, \ldots\)
✅ Verificación de comprensión: Explica desde el punto de vista de la teoría de representaciones de \(\mathrm{SU}(2)\) por qué no pueden existir partículas de espín \(1/3\).
Respuesta
Los autovalores de \(J_3\) descienden en pasos enteros desde el valor máximo \(j\) hasta el mínimo \(-j\). Para que se detenga exactamente en \(-j\), \(2j\) debe ser un entero no negativo. Con \(j = 1/3\), \(2j = 2/3\) no es entero y no se puede construir una representación de dimensión finita, por lo que las partículas de espín \(1/3\) no están permitidas.
🔵 Kai: Solo la simetría ya restringe los tipos de partículas que pueden existir. Pero en la tabla solo aparecen hasta espín \(2\). ¿Es que espines más altos son permitidos en principio pero no existen en la naturaleza?
🟡 Lina: Una pregunta muy profunda. Los campos de espín alto (\(s > 2\)) pueden construirse en principio, pero se sabe que es extremadamente difícil introducir interacciones de forma consistente. Esto está relacionado con el teorema de Weinberg-Witten y otros resultados que exceden el alcance del texto principal, pero el punto es que hay una brecha entre "lo que la simetría permite" y "lo que la naturaleza realiza".
🔵 Kai: Ya veo... Por cierto, entiendo la clasificación de representaciones, pero todavía no veo con qué matrices concretas se transforman los espinores. ¿Cómo se construye la matriz de transformación de la representación \((1/2, 0)\)?
🟡 Lina: Buena pregunta. Es precisamente lo que haremos en la siguiente sección.
✅ Verificación de comprensión: Verifica que la dimensión de la representación \((1/2, 0) \oplus (0, 1/2)\) del espinor de Dirac es 4.
Respuesta
La dimensión de \((1/2, 0)\) es \((2 \times 1/2 + 1)(2 \times 0 + 1) = 2 \times 1 = 2\). La dimensión de \((0, 1/2)\) es también \(2\). Tomando la suma directa: \(2 + 2 = 4\).
Construcción concreta de la representación espinorial¶
🟡 Lina: Ahora que conocemos la clasificación de representaciones, construyamos concretamente las matrices de transformación de los espinores. Cuando las coordenadas se transforman por \(\Lambda\), la matriz \(D(\Lambda)\) que mezcla las componentes del campo es
La convención de signos es la misma que en la ecuación (B.14). Para cada tipo de campo, basta elegir las matrices concretas de \(\mathbf{J}\) y \(\mathbf{K}\).
Transformación de los espinores de Weyl¶
🟡 Lina: Empecemos con los espinores de Weyl de 2 componentes. En la sección anterior aprendimos que las representaciones del grupo de Lorentz se clasifican con \((j_+, j_-)\). La representación \((1/2, 0)\) tiene dimensión \(2\), así que los generadores se representan con matrices \(2 \times 2\). Las matrices \(M^{\rho\sigma}\) de \(4 \times 4\) que vimos antes eran los generadores de la representación vectorial (\((1/2, 1/2)\), dimensión \(4\)). Si la representación cambia, el tamaño de las matrices generadoras también cambia. Las matrices hermíticas \(2 \times 2\) que satisfacen \([J^i, J^j] = i\varepsilon^{ijk}J^k\) son — como aprendiste en mecánica cuántica — la mitad de las matrices de Pauli:
Donde \(\boldsymbol{\sigma} = (\sigma^1, \sigma^2, \sigma^3)\) son las matrices de Pauli:
🔵 Kai: Las matrices de Pauli las usé en el capítulo de espín \(1/2\) de mecánica cuántica.
🟡 Lina: Así es. Los generadores de boost son
Hay 2 opciones: \(+\) y \(-\).
🔵 Kai: ¿Por qué hay 2 opciones?
🟡 Lina: Buena pregunta. Intuitivamente, al verificar la relación de conmutación (B.17) calculando \([K^i, K^j]\), tanto con \(\mathbf{K} = +i\boldsymbol{\sigma}/2\) como con \(\mathbf{K} = -i\boldsymbol{\sigma}/2\) se obtiene \((\pm i)^2 = -1\) y el resultado es el mismo. En cuanto a (B.16), como en \([J^i, K^j] = i\varepsilon^{ijk}K^k\) el lado derecho también contiene \(K^k\), al cambiar el signo de \(K\) en el lado izquierdo, el signo de \(K^k\) en el lado derecho cambia simultáneamente y todo es consistente. Es decir, las 3 relaciones de conmutación son invariantes bajo la inversión global del signo de \(\mathbf{K}\) — por eso se permiten 2 opciones.
En la sección anterior vimos que las representaciones del álgebra de Lorentz se clasifican con el par \((j_+, j_-)\). Para espinores de 2 componentes hay dos representaciones: \((1/2, 0)\) y \((0, 1/2)\). Adelantando la conclusión: \(\mathbf{K} = -i\boldsymbol{\sigma}/2\) corresponde al levógiro \((1/2, 0)\) y \(\mathbf{K} = +i\boldsymbol{\sigma}/2\) al dextrógiro \((0, 1/2)\). Por qué es esta la correspondencia se verificará en la subsección siguiente "Correspondencia con \(\mathbf{J}_\pm\)", calculando concretamente \(\mathbf{J}_+\) y \(\mathbf{J}_-\). Primero verifiquemos que esta elección es consistente con las relaciones de conmutación. Comprobemos si \(\mathbf{J} = \boldsymbol{\sigma}/2\) y \(\mathbf{K} = +i\boldsymbol{\sigma}/2\) satisfacen las relaciones (B.15)–(B.17).
Primero (B.15): \([J^i, J^j] = [\sigma^i/2, \sigma^j/2] = \frac{1}{4}[\sigma^i, \sigma^j]\). Usando la relación de conmutación de las matrices de Pauli \([\sigma^i, \sigma^j] = 2i\varepsilon^{ijk}\sigma^k\) (relación confirmada en Apéndice A): \(= \frac{i}{2}\varepsilon^{ijk}\sigma^k = i\varepsilon^{ijk}J^k\). ✓
Luego (B.16): \([J^i, K^j] = [\sigma^i/2, i\sigma^j/2] = \frac{i}{4}[\sigma^i, \sigma^j] = \frac{i}{4} \cdot 2i\varepsilon^{ijk}\sigma^k = -\frac{1}{2}\varepsilon^{ijk}\sigma^k\).
Por otro lado \(i\varepsilon^{ijk}K^k = i\varepsilon^{ijk} \cdot \frac{i\sigma^k}{2} = \frac{i^2}{2}\varepsilon^{ijk}\sigma^k = -\frac{1}{2}\varepsilon^{ijk}\sigma^k\). ✓
Finalmente (B.17): \([K^i, K^j] = [i\sigma^i/2, i\sigma^j/2] = \frac{i^2}{4}[\sigma^i, \sigma^j] = -\frac{1}{4} \cdot 2i\varepsilon^{ijk}\sigma^k = -\frac{i}{2}\varepsilon^{ijk}\sigma^k = -i\varepsilon^{ijk}J^k\). ✓
🔵 Kai: Entiendo que todo se cumple con \(\mathbf{K} = +i\boldsymbol{\sigma}/2\), pero ¿también se cumple con la otra opción \(\mathbf{K} = -i\boldsymbol{\sigma}/2\)?
🟡 Lina: Probemos. Verificación de (B.17): \([K^i, K^j] = [-i\sigma^i/2, -i\sigma^j/2] = \frac{(-i)^2}{4}[\sigma^i, \sigma^j] = -\frac{i}{2}\varepsilon^{ijk}\sigma^k = -i\varepsilon^{ijk}J^k\), y también se cumple. Las 2 opciones de \(\pm\) corresponden precisamente al espinor de Weyl levógiro \(\psi_L\) y al espinor de Weyl dextrógiro \(\psi_R\).
Tabla B.2: Generadores y correspondencia de representaciones de los espinores de Weyl
| Generador de rotación \(\mathbf{J}\) | Generador de boost \(\mathbf{K}\) | Representación | |
|---|---|---|---|
| Levógiro \(\psi_L\) | \(\boldsymbol{\sigma}/2\) | \(-i\boldsymbol{\sigma}/2\) | \((1/2, 0)\) |
| Dextrógiro \(\psi_R\) | \(\boldsymbol{\sigma}/2\) | \(+i\boldsymbol{\sigma}/2\) | \((0, 1/2)\) |
🔵 Kai: Tienen el mismo generador para la rotación, pero el signo difiere para el boost.
🟡 Lina: Esa es la diferencia esencial entre "levógiro" y "dextrógiro". Solo con rotaciones no se distinguen, pero incluyendo boosts sí. Y esta diferencia de signo corresponde a la distinción entre las representaciones \((1/2, 0)\) y \((0, 1/2)\) — lo verificaremos concretamente calculando \(\mathbf{J}_\pm\) en la siguiente sección.
✅ Verificación de comprensión: ¿Los espinores de Weyl levógiro y dextrógiro se distinguen por las rotaciones o por los boosts? Indica concretamente la diferencia en los generadores.
Respuesta
El generador de rotación es el mismo para ambos: \(\mathbf{J} = \boldsymbol{\sigma}/2\), pero el generador de boost difiere en signo: para el levógiro es \(\mathbf{K} = -i\boldsymbol{\sigma}/2\) y para el dextrógiro \(\mathbf{K} = +i\boldsymbol{\sigma}/2\). Por lo tanto, se distinguen mediante los boosts.
Correspondencia con \(\mathbf{J}_\pm\)¶
🟡 Lina: Confirmémoslo en el lenguaje de los \(\mathbf{J}_\pm\) introducidos antes. Para el espinor levógiro \(\psi_L\), con \(\mathbf{K} = -i\boldsymbol{\sigma}/2\):
\(\mathbf{J}_+^2 = (\boldsymbol{\sigma}/2)^2 = \frac{3}{4}I = j_+(j_++1)I\) da \(j_+ = 1/2\), y \(\mathbf{J}_- = 0\) da \(j_- = 0\), así que es la representación \((1/2, 0)\).
🔵 Kai: Para el dextrógiro con \(\mathbf{K} = +i\boldsymbol{\sigma}/2\)... si hago el mismo cálculo, ¿qué cambia?
🟡 Lina: Solo cambia un signo y los papeles de \(\mathbf{J}_+\) y \(\mathbf{J}_-\) se intercambian limpiamente. La verificación la dejo como ejercicio.
📝 Ejercicios:
- Confirmación de \(\mathbf{J}_\pm\) para el espinor de Weyl dextrógiro y la representación \((0, 1/2)\) → Problema B-6. \(\mathbf{J}_+\) と \(\mathbf{J}_-\) から \(\mathbf{J}\), $\mathbf{K}…
Rotación de espinores — inversión de signo a \(360°\)¶
🟡 Lina: Confirmemos la propiedad más sorprendente de los espinores. La matriz de rotación alrededor del eje \(x^1\) es
Desarrollémosla en serie de Taylor usando la propiedad \((\sigma^i)^2 = I\) (\(I\) es la matriz identidad \(2 \times 2\)) de las matrices de Pauli. Definiendo \(\alpha \equiv \theta^1/2\):
Como \((\sigma^1)^2 = I\): \((\sigma^1)^n = I\) (si \(n\) es par), \((\sigma^1)^n = \sigma^1\) (si \(n\) es impar). Agrupando los términos pares: \(\sum_{k=0}^\infty \frac{(-1)^k\alpha^{2k}}{(2k)!}I = I\cos\alpha\); agrupando los impares: \(-i\sigma^1\sum_{k=0}^\infty \frac{(-1)^k\alpha^{2k+1}}{(2k+1)!} = -i\sigma^1\sin\alpha\). Por lo tanto
🔵 Kai: Este cálculo es el mismo que hice en el capítulo de espín de mecánica cuántica.
🟡 Lina: Exacto. Ahora sustituye \(\theta^1 = 2\pi\) (rotación de \(360°\)).
🔵 Kai: ¡Menos la matriz identidad! ¿Rotar \(360°\) no devuelve al estado original sino que invierte el signo?
🟡 Lina: Así es. Solo con una rotación de \(720°\) (\(\theta^1 = 4\pi\)) se recupera \(D = +I\). Esta es la propiedad esencial de los espinores — una transformación fundamentalmente diferente a la de los vectores.
⚪ Mei: Los vectores vuelven al original con \(360°\), así que el argumento de la rotación es \(\theta\) directamente. Los espinores tienen \(\theta/2\) en el argumento, así que con una vuelta completa de \(2\pi\) solo avanza la mitad \(\pi\) — por eso el signo se invierte.
🟡 Lina: Hermoso resumen. Esta propiedad ha sido confirmada experimentalmente: en 1975, el experimento de interferencia de neutrones de Rauch y colaboradores observó que al rotar un neutrón \(360°\) en un campo magnético, el patrón de interferencia se invierte (la fase se desplaza en \(\pi\)). Mira la Fig. B.1「Comparación de la rotación de vectores y espinores」 — muestra lado a lado cómo el vector vuelve al original con \(360°\) mientras que el espinor necesita \(720°\).
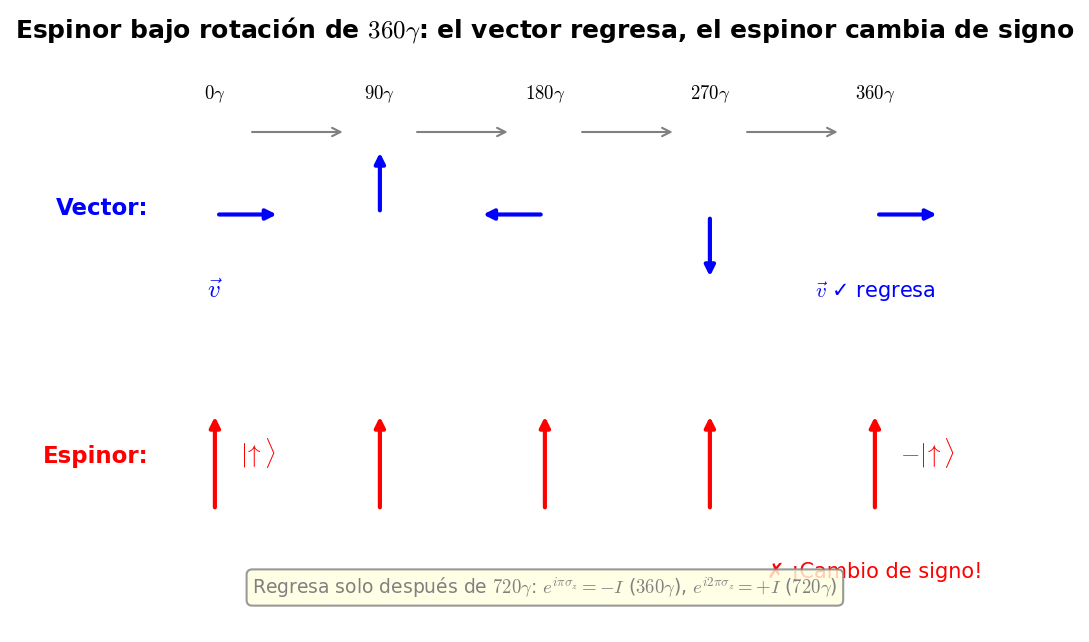
Fig. B.1: Comparación de la rotación de vectores y espinores. Un vector vuelve completamente al original con una rotación de \(360°\), pero un espinor invierte su signo a \(360°\) (\(-|\!\uparrow\rangle\)) y solo vuelve al original con una rotación de \(720°\). Esta diferencia se debe a que el argumento de la matriz de transformación es \(\theta\) (vectores) o \(\theta/2\) (espinores).
✅ Verificación de comprensión: Calcula la matriz de transformación al rotar un espinor \(720°\).
Respuesta
\(D(4\pi) = I\cos(2\pi) - i\sigma^1\sin(2\pi) = I \cdot 1 - i\sigma^1 \cdot 0 = I\). Con una rotación de \(720°\) se recupera la matriz identidad.
Boost de espinores — no unitariedad¶
🟡 Lina: Después de la rotación, veamos el boost. El boost en la dirección \(x^1\) del espinor de Weyl levógiro, sustituyendo \(\mathbf{K} = -i\boldsymbol{\sigma}/2\) (levógiro) en la ecuación (B.14):
🔵 Kai: En la rotación había un \(-i\) en el exponente, pero ahora el \(-i\) se cancela con el \(-i\) dentro de \(K\), y el exponente queda real.
🟡 Lina: Expandamos con el mismo procedimiento que la ecuación (B.30) usando \((\sigma^1)^2 = I\). Pero ahora como el exponente es el real \(-\phi/2\), en lugar de \(\cos\) y \(-i\sin\) aparecen \(\cosh\) y \(-\sinh\). Definiendo \(\alpha \equiv \phi/2\):
Como \((\sigma^1)^2 = I\), los términos pares dan \(I\) y los impares dan \(\sigma^1\). Agrupando pares: \(\sum_{k=0}^\infty \frac{\alpha^{2k}}{(2k)!}I = I\cosh\alpha\); agrupando impares: \(-\sigma^1\sum_{k=0}^\infty \frac{\alpha^{2k+1}}{(2k+1)!} = -\sigma^1\sinh\alpha\). Por lo tanto
🔵 Kai: En la rotación aparecían \(\cos\) y \(\sin\), pero ahora son \(\cosh\) y \(\sinh\). Es porque el exponente se volvió real.
🟡 Lina: Exacto. En la rotación el exponente era puramente imaginario \(-i\alpha\) y aparecían \(\cos\) y \(\sin\), pero ahora es real \(-\alpha\) y aparecen \(\cosh\) y \(\sinh\). Y hay otra diferencia importante. Mirando la ecuación (B.33), \(\cosh(\phi/2)\) es real y \(\sigma^1\) es una matriz hermítica, así que \(D_L\) en su totalidad también es hermítica (\(D_L^\dagger = D_L\)). Por lo tanto \(D_L^\dagger D_L = D_L^2\). Calculemos concretamente usando \((\sigma^1)^2 = I\):
Expandiendo con \((A - B)^2 = A^2 - AB - BA + B^2\). Aquí \(A = I\cosh(\phi/2)\) es un múltiplo escalar de la identidad, así que conmuta con cualquier matriz — es decir, \(AB = BA\). Por lo tanto podemos usar directamente la fórmula usual \((A-B)^2 = A^2 - 2AB + B^2\). \(A^2 = I\cosh^2(\phi/2)\), \(B^2 = (\sigma^1)^2\sinh^2(\phi/2) = I\sinh^2(\phi/2)\), \(2AB = 2\sigma^1\cosh(\phi/2)\sinh(\phi/2)\), así que
⚪ Mei: Usando los teoremas de adición de funciones hiperbólicas debería simplificarse.
🟡 Lina: Con las fórmulas \(\cosh^2 x + \sinh^2 x = \cosh 2x\) y \(2\cosh x\sinh x = \sinh 2x\):
Es decir, esta matriz no es unitaria.
🔵 Kai: No es unitaria... eso significa que \(D_L^\dagger D_L \neq I\), ¿verdad? ¿Qué problema hay con eso?
🟡 Lina: Buena duda. Que no sea unitaria significa que el boost cambia la "norma" del espinor. Esto está relacionado con una propiedad profunda del grupo de Lorentz. De hecho, no existen representaciones unitarias no triviales de dimensión finita del grupo de Lorentz. La causa es que el generador de boost \(\mathbf{K}\) es antihermítico (\(K^\dagger = -K\), es decir, no es hermítico).
Concretamente, como \(K^i = \pm i\sigma^i/2\): \((K^i)^\dagger = (\pm i)^*\sigma^i/2 = \mp i\sigma^i/2 = -K^i\) (las matrices de Pauli son hermíticas: \((\sigma^i)^\dagger = \sigma^i\)). Es decir, \(K^i\) es antihermítico. En cambio, el generador de rotación \(J^i = \sigma^i/2\) cumple \((J^i)^\dagger = \sigma^i/2 = J^i\), que es hermítico.
🔵 Kai: La rotación es unitaria y el boost es no unitario... Pero en mecánica cuántica, ¿las transformaciones no tenían que ser unitarias?
🟡 Lina: Buena duda. Lo que hay que distinguir aquí es la diferencia entre operadores que actúan sobre estados del espacio de Hilbert y matrices que mezclan componentes del campo. Los operadores de transformación del espacio de Hilbert deben ser unitarios (para conservar la probabilidad). Sin embargo, las matrices de dimensión finita \(D(\Lambda)\) que mezclan las componentes del campo no necesitan ser unitarias. En la teoría cuántica de campos, esta distinción es muy importante.
✅ Verificación de comprensión: ¿Por qué la no unitariedad de la matriz de transformación de boost del espinor no contradice la conservación de probabilidad de la mecánica cuántica?
Respuesta
Los operadores de transformación que actúan sobre estados del espacio de Hilbert deben ser unitarios, pero las matrices de dimensión finita \(D(\Lambda)\) que mezclan componentes del campo no necesitan serlo. La no unitariedad de la matriz de transformación de boost se refiere a la mezcla de componentes del campo y es un asunto distinto de la conservación de probabilidad en el espacio de Hilbert.
Transformación del espinor de Dirac¶
🟡 Lina: Finalmente, veamos la transformación del espinor de Dirac de 4 componentes. Para
donde apilamos verticalmente el levógiro \(\psi_L\) y el dextrógiro \(\psi_R\), la rotación es
🔵 Kai: El bloque superior izquierdo y el inferior derecho son la misma matriz, y el levógiro y dextrógiro no se mezclan. ¿Eso significa que solo con rotaciones no hace falta distinguir entre levógiro y dextrógiro?
🟡 Lina: Exactamente. El boost es
El bloque superior izquierdo y el inferior derecho tienen signo opuesto — esa es la diferencia entre levógiro y dextrógiro. Con rotaciones no se distinguen, pero con boosts sí — esta es la manifestación concreta de la diferencia entre las representaciones \((1/2, 0)\) y \((0, 1/2)\).
⚪ Mei: Entiendo, la diferencia de signo de \(\mathbf{K}\) que vimos en la sección anterior se manifiesta, al juntar todo en 4 componentes, como la diferencia de signo entre los bloques superior izquierdo e inferior derecho de la matriz de boost.
🟡 Lina: La matriz de transformación del espinor para una transformación de Lorentz general se escribe usando las matrices \(\gamma\) como
Aquí \(\sigma^{\mu\nu} = \frac{i}{2}[\gamma^\mu, \gamma^\nu]\) es el generador de la transformación de Lorentz del campo de Dirac. \(\omega_{\mu\nu}\) es el parámetro de transformación (tensor antisimétrico). Esta ecuación es la verdadera identidad de la matriz de transformación que usamos en Cap. 5 del texto principal.
🔵 Kai: Si \(\sigma^{\mu\nu}\) se construye a partir de las matrices \(\gamma\) de \(4 \times 4\), entonces la matriz de transformación del espinor de Dirac también es \(4 \times 4\). Se ha extendido correctamente desde las \(2 \times 2\) del espín.
✅ Verificación de comprensión: ¿Cuántas componentes independientes tiene \(\sigma^{\mu\nu}\)?
Respuesta
\(\sigma^{\mu\nu}\) es antisimétrico (\(\sigma^{\mu\nu} = -\sigma^{\nu\mu}\), \(\sigma^{\mu\mu} = 0\)), así que las componentes independientes son \(4 \times 3/2 = 6\). Esto coincide con el número de parámetros de la transformación de Lorentz (3 rotaciones + 3 boosts = 6).
📝 Ejercicios:
- Cálculo de \(\sigma^{12} = \frac{i}{2}[\gamma^1, \gamma^2]\) en la representación de Dirac → Problema B-7. Cálculo de la dimensión de representaciones
Álgebra de Poincaré y clasificación de partículas¶
🟡 Lina: Al añadir las traslaciones espacio-temporales a las transformaciones de Lorentz obtenemos el grupo de Poincaré. Sus generadores son
Tabla B.3: Generadores del grupo de Poincaré y magnitudes físicas
| Transformación | Generador | Magnitud física |
|---|---|---|
| Traslación temporal | \(P^0\) | Energía |
| Traslación espacial | \(P^i\) | Momento |
| Rotación espacial | \(J^i\) | Momento angular |
| Boost de Lorentz | \(K^i\) | Generador de boost |
Las relaciones de conmutación del álgebra de Poincaré son, además del álgebra de Lorentz (B.15)–(B.17):
Aquí hay que tener cuidado. El \(M^{\mu\nu}\) de esta ecuación no es la matriz \(4\times 4\) antihermítica definida en la ecuación (B.10), sino el generador abstracto obtenido multiplicándola por \(-i\) para hacerla hermítica. Es decir:
Con este \(M^{\mu\nu}\) hermítico se puede escribir simplemente \(J^i = \frac{1}{2}\varepsilon^{ijk}M^{jk}\), \(K^i = M^{0i}\) (en la ecuación (B.13b) escribíamos explícitamente el \(-i\) porque allí usábamos las \(M^{jk}\) antihermíticas de la ecuación (B.10)). En ambas notaciones los valores de \(J^i\), \(K^i\) son los mismos.
🔵 Kai: ¿No es confuso usar el mismo símbolo \(M^{\mu\nu}\) con dos significados?
🟡 Lina: Ciertamente es confuso. Pero es la costumbre en física y se distingue por el contexto. Resumiendo:
- \(M^{\rho\sigma}\) de la ecuación (B.10): Matriz \(4\times 4\) antihermítica en la representación vectorial. Aparece cuando escribimos la transformación infinitesimal como \(\Lambda = I + \omega\) mediante \(\omega^\mu{}_\nu = \frac{1}{2}\omega_{\rho\sigma}(M^{\rho\sigma})^\mu{}_\nu\)
- \(M^{\mu\nu}\) aquí: Generador abstracto hermítico independiente de la representación. La relación de conmutación (B.39) se refiere a este significado
De aquí en adelante en este capítulo, en el contexto del álgebra de Poincaré, \(M^{\mu\nu}\) se refiere siempre a la versión hermítica. La relación de conmutación (B.39) es una relación algebraica abstracta que se cumple independientemente de la representación particular.
🔵 Kai: (B.38) dice que "las traslaciones conmutan entre sí". Caminar primero al este y luego al norte, o al revés, da lo mismo.
🟡 Lina: Así es. (B.39) establece que "\(P^\rho\) se transforma como un 4-vector bajo transformaciones de Lorentz". Intuitivamente, así como la coordenada \(x^\rho\) cambia bajo una transformación de Lorentz infinitesimal como \(\delta x^\rho = \omega^\rho{}_\sigma x^\sigma\), \(P^\rho\) se mezcla de la misma manera — y (B.39) expresa esa "forma de mezclarse" en el lenguaje de relaciones de conmutación. El lado derecho \(\eta^{\mu\rho}P^\nu - \eta^{\nu\rho}P^\mu\) tiene la misma estructura que el resultado de que el generador \((M^{\mu\nu})^\rho{}_\sigma\) de la ecuación (B.10) actúe sobre \(P^\sigma\) (se verifica que \((M^{\mu\nu})^\rho{}_\sigma P^\sigma = (\eta^{\mu\rho}\delta^\nu{}_\sigma - \eta^{\nu\rho}\delta^\mu{}_\sigma)P^\sigma = \eta^{\mu\rho}P^\nu - \eta^{\nu\rho}P^\mu\)).
⚪ Mei: Es decir, (B.39) es la expresión algebraica de que "\(P^\rho\) se comporta como un 4-vector".
🟡 Lina: Veamos un ejemplo concreto. \(M^{12}\) era el generador de rotación en el plano \(xy\) (correspondiente a \(J^3\)). Con \(\rho = 1\):
Esto significa que "bajo una rotación alrededor del eje \(z\), \(P^1\) (momento en dirección \(x\)) se mezcla con \(P^2\) (momento en dirección \(y\))". Es lo mismo que las componentes de un vector mezclándose bajo rotación.
🔵 Kai: El momento se mezcla bajo rotación igual que las coordenadas. Entonces, para el conmutador del generador de boost \(K^i = M^{0i}\) con \(P^\mu\), ¿se mezclan la componente temporal y las espaciales?
🟡 Lina: Exacto. Intuitivamente, así como la coordenada \(x^\rho\) cambia bajo una transformación de Lorentz infinitesimal como \(\delta x^\rho = \omega^\rho{}_\sigma x^\sigma\), \(P^\rho\) también cambia como \(\delta P^\rho = \omega^\rho{}_\sigma P^\sigma\) — (B.39) expresa esta ley de transformación en lenguaje de conmutadores. En el caso del boost, el conmutador de \(M^{01}\) con \(P^0\) produce \(P^1\) — energía y momento se mezclan. La verificación de las demás componentes queda para que lo compruebes por tu cuenta.
Operadores de Casimir¶
🟡 Lina: A un operador que conmuta con todos los generadores del álgebra de Poincaré lo llamamos operador de Casimir. El álgebra de Poincaré tiene 2:
Aquí \(W^\mu\) es una cantidad llamada vector de Pauli-Lubanski. Déjame explicar la motivación. \(P^2\) determina la masa, pero ¿dónde está la información del espín? El momento angular \(M_{\nu\rho}\) por sí solo no es un operador de Casimir (no conmuta con \(P^\mu\)). Entonces, si combinamos el momento angular y el momento para "eliminar la información de la dirección del momento", obtenemos un nuevo invariante que conmuta con todos los generadores. Ese es
\(\varepsilon^{\mu\nu\rho\sigma}\) es el símbolo de Levi-Civita en 4 dimensiones — la extensión a 4 dimensiones del \(\varepsilon^{ijk}\) tridimensional usado en la ecuación (B.13), con \(\varepsilon^{0123} = +1\) y cambiando de signo con permutaciones impares de los índices, y valiendo \(0\) si hay índices repetidos. Intuitivamente, \(W^\mu\) es una cantidad que sustrae del momento angular la "contribución del movimiento orbital" para extraer solo la información pura del espín. Veámoslo concretamente.
🔵 Kai: En unidades naturales \(P^2 = -(P^0)^2 + |\mathbf{p}|^2 = -E^2 + |\mathbf{p}|^2 = -m^2\), ¿verdad? Eso determina la masa de la partícula.
🟡 Lina: Exacto. Para \(W^2\), es más fácil de entender considerando el sistema en reposo de una partícula masiva (\(m > 0\)). En el sistema en reposo \(P^\mu = (m, 0, 0, 0)\), así que la única componente no nula de \(P_\sigma\) es \(P_0 = \eta_{00}P^0 = -m\) (\(P_i = 0\)). Sustituyendo en la ecuación (B.42):
Para \(\mu = 0\): \(\varepsilon^{0\nu\rho 0} = 0\) (el mismo índice \(0\) aparece dos veces), así que \(W^0 = 0\). Para \(\mu = i\) (componentes espaciales), determinemos sistemáticamente el valor de \(\varepsilon^{i\nu\rho 0}\). \(\varepsilon^{\mu\nu\rho\sigma}\) es totalmente antisimétrico con \(\varepsilon^{0123} = +1\), así que por ejemplo encontremos \(\varepsilon^{1230}\). Totalmente antisimétrico significa que "cada vez que se intercambian dos índices cualesquiera, el signo se invierte". Partiendo de \(\varepsilon^{0123} = +1\), movemos el \(0\) hasta el extremo derecho: \((0,1,2,3) \to (1,0,2,3)\) (intercambio de 1º y 2º índice, signo \(\times(-1)\)) \(\to (1,2,0,3)\) (intercambio de 2º y 3º índice, signo \(\times(-1)\)) \(\to (1,2,3,0)\) (intercambio de 3º y 4º índice, signo \(\times(-1)\)). Con 3 intercambios adyacentes el signo cambia por \((-1)^3 = -1\), así que \(\varepsilon^{1230} = -1\). En general se cumple \(\varepsilon^{ijk0} = -\varepsilon^{ijk}\). Aquí el \(\varepsilon^{ijk}\) del lado derecho es el símbolo de Levi-Civita tridimensional (\(\varepsilon^{123} = +1\), \(+1\) para permutaciones pares, \(-1\) para impares). Esta relación se sigue de que "para mover el \(0\) desde el principio hasta el final se necesitan 3 intercambios adyacentes, y como es un número impar el signo se invierte".
🔵 Kai: Ya veo, mover el \(0\) desde el principio hasta el final requiere 3 intercambios y produce un signo menos.
🟡 Lina: Por lo tanto
Aquí \(\nu, \rho\) recorren \(0, 1, 2, 3\), pero \(\varepsilon^{i\nu\rho 0}\) solo es no nulo cuando los 4 índices \(i, \nu, \rho, 0\) son todos diferentes. Como \(0\) ya ocupa la 4ª posición, \(\nu\) y \(\rho\) deben ser índices espaciales \(j, k\) distintos de \(0\). Por lo tanto
⚪ Mei: Los dos signos negativos se cancelan y queda una forma limpia.
🟡 Lina: Ahora, como la definición de \(J^i\) es \(J^i = \frac{1}{2}\varepsilon^{ijk}M^{jk}\) escrita con \(M^{jk}\) con índices arriba, queremos reescribir \(M_{jk}\) como \(M^{jk}\). Para subir y bajar índices espaciales se usa \(\eta_{jk} = +\delta_{jk}\) (la parte espacial es la métrica euclídea ordinaria), así que \(M_{jk} = \eta_{ja}\eta_{kb}M^{ab} = \delta_{ja}\delta_{kb}M^{ab} = M^{jk}\) — es decir, para índices espaciales arriba o abajo dan el mismo valor (solo el índice temporal cambia de signo por \(\eta_{00} = -1\)). El \(M^{jk}\) aquí es la versión hermítica del generador introducida al comienzo de esta sección, con la que \(J^i = \frac{1}{2}\varepsilon^{ijk}M^{jk}\) se escribe simplemente. Usando esta relación:
En el sistema en reposo \(W^0 = 0\), así que calculemos \(W^2\) usando \(W^i = mJ^i\). \(W^2 \equiv W_\mu W^\mu = \eta_{\mu\nu}W^\mu W^\nu\), con la convención de signos \(\eta_{\mu\nu} = \mathrm{diag}(-1,+1,+1,+1)\):
Sustituyendo \(W^0 = 0\):
Los autovalores de \(\mathbf{J}^2\) son \(s(s+1)\) usando el número cuántico de espín \(s\) (estamos usando unidades naturales \(\hbar = 1\); restituyendo \(\hbar\) queda \(\hbar^2 s(s+1)\)):
donde \(s\) es el número cuántico de espín.
🔵 Kai: Oh, ¡el cuadrado del vector de Pauli-Lubanski resulta ser el producto de la masa y el espín!
⚪ Mei: Es decir, las partículas se clasifican completamente por los autovalores de los dos operadores de Casimir: masa \(m\) y espín \(s\).
🟡 Lina: Exactamente. Esta es la lista completa de clasificación de partículas derivada únicamente de la invariancia de Poincaré.
Tabla B.4: Clasificación de partículas por masa y espín
| Masa | Espín | Ejemplo |
|---|---|---|
| \(m > 0\) | \(s = 0\) | Partícula de Higgs |
| \(m > 0\) | \(s = 1/2\) | Electrón, quarks |
| \(m > 0\) | \(s = 1\) | Bosón \(W\), bosón \(Z\) |
| \(m = 0\) | Helicidad \(\pm 1\) | Fotón |
| \(m = 0\) | Helicidad \(\pm 2\) | Gravitón (hipotético) |
⚪ Mei: Es decir, \(P^2\) determina la masa y \(W^2\) determina el espín, y con solo estos dos números cuánticos las partículas quedan completamente clasificadas.
🔵 Kai: Solo la simetría restringe hasta este punto los tipos de partículas que pueden existir en la naturaleza... "La invariancia determina la física" resultó ser cierto. Pero una cosa que me llama la atención: ¿por qué las partículas sin masa se clasifican por "helicidad" en lugar de "espín"?
🟡 Lina: Buena pregunta. Las partículas sin masa se mueven a la velocidad de la luz, así que no existe un sistema en reposo. Sin sistema en reposo, la estructura del vector de Pauli-Lubanski cambia y en lugar del espín, solo la helicidad (la proyección del momento angular sobre la dirección de movimiento) queda como buen número cuántico. Los detalles se trataron en Cap. 4 del texto principal.
✅ Verificación de comprensión: Explica brevemente por qué las partículas sin masa se clasifican por helicidad en vez de espín.
Respuesta
Las partículas sin masa se mueven a la velocidad de la luz por lo que no existe sistema en reposo. Sin sistema en reposo, la estructura del vector de Pauli-Lubanski cambia y en lugar de todas las componentes del espín, solo queda como buen número cuántico la helicidad: la proyección del momento angular sobre la dirección de movimiento.
🟡 Lina: Esta es la cristalización matemática de la filosofía que recorre todo el Teoría Cuántica de Campos. Las ecuaciones de campo individuales (Klein-Gordon, Dirac, Maxwell) no son más que descripciones de campos correspondientes a representaciones particulares del grupo de Poincaré.
✅ Verificación de comprensión: ¿Cuáles son los dos operadores de Casimir del grupo de Poincaré? Indica el significado físico de cada uno.
Respuesta
\(C_1 = P^2 = P_\mu P^\mu\) (su autovalor es \(-m^2\) y determina el cuadrado de la masa de la partícula; con la métrica \((-,+,+,+)\): \(P^2 = -(P^0)^2 + |\mathbf{p}|^2 = -m^2\)) y \(C_2 = W^2 = W_\mu W^\mu\) (su autovalor es \(m^2 s(s+1)\) y determina el espín de la partícula).
Resumen — lo que obtuvimos en este Apéndice¶
🟡 Lina: Para terminar, organicemos los logros de este Apéndice.
- Generadores y aplicación exponencial: A partir del generador de la transformación infinitesimal, se construye la transformación finita mediante la exponencial \(e^{\pm i\alpha G}\) (el signo depende de la convención)
- Álgebra de Lorentz: Las relaciones de conmutación (B.15)–(B.17) de los generadores de rotación \(J^i\) y boost \(K^i\) determinan completamente la estructura infinitesimal del grupo de Lorentz
- Descomposición \(\mathfrak{su}(2) \oplus \mathfrak{su}(2)\): La introducción de \(\mathbf{J}_\pm = (\mathbf{J} \pm i\mathbf{K})/2\) permite descomponer el álgebra de Lorentz en dos \(\mathfrak{su}(2)\) independientes
- Clasificación de representaciones: El par \((j_+, j_-)\) determina el tipo de campo — escalar \((0,0)\), espinor de Weyl \((1/2, 0)\) y \((0, 1/2)\), vector \((1/2, 1/2)\)
- Construcción de espinores: Construimos concretamente las matrices de transformación de rotación y boost a partir de las matrices de Pauli. El origen de la propiedad de inversión de signo con rotación de \(360°\) se reduce a que el generador es \(\boldsymbol{\sigma}/2\) (el argumento es \(\theta/2\))
- Álgebra de Poincaré y clasificación de partículas: Los autovalores de los 2 operadores de Casimir (\(P^2\) y \(W^2\)) determinan la masa y el espín, clasificando completamente las partículas de la naturaleza
🔵 Kai: Que la matemática de la simetría determine todos los tipos de partículas es realmente impresionante.
⚪ Mei: Es decir, no es necesario memorizar las ecuaciones de campo individualmente: en el momento en que se elige \((j_+, j_-)\), la transformación del campo queda determinada y la forma de la ecuación también queda restringida. He podido ver la estructura de que "primero es la simetría", no "primero la ecuación".
🟡 Lina: Así es. Ahí reside el corazón de la belleza de la teoría cuántica de campos.
Avance del próximo capítulo¶
Apéndice C: Integral gaussiana e integral de Grassmann
Se reúnen en un solo lugar la integral gaussiana (base de la integral de camino para bosones) y el álgebra de números de Grassmann con la integral de Berezin (base de la integral de camino para fermiones), que aparecen repetidamente en los cálculos de la teoría cuántica de campos. Una vez que se comprende el contraste entre \((\det A)^{-1/2}\) para bosones y \(\det A\) para fermiones, la diferencia en el tratamiento de los dos tipos de partículas en la integral de camino queda claramente visible. En el siguiente Apéndice D "Caja de herramientas para cálculos a un loop", se avanza hacia técnicas prácticas para integrales de loop: análisis dimensional, parámetros de Feynman, rotación de Wick, etc.
Problemas de práctica¶
📝 Ejercicios:
- Verificación de \([K^i, K^j] = -i\varepsilon^{ijk}J^k\) en la representación vectorial → Problema M-3. Correspondencia entre la representación \((1/2, 1/2)\) y los cuadrivectores
- Rederivación del álgebra de Lorentz a partir de \(\mathbf{J}_\pm\) → Problema B-5. Recuperación de los generadores de rotación usando el símbolo de Levi-Civita
- Confirmación de \(\mathbf{J}_\pm\) para el espinor de Weyl dextrógiro y la representación \((0, 1/2)\) → Problema B-6. \(\mathbf{J}_+\) と \(\mathbf{J}_-\) から \(\mathbf{J}\), $\mathbf{K}…
- Cálculo de \(\sigma^{12} = \frac{i}{2}[\gamma^1, \gamma^2]\) en la representación de Dirac → Problema B-7. Cálculo de la dimensión de representaciones
Referencias¶
- Quantum Field Theory for the Gifted Amateur (Lancaster & Blundell) Capítulo 10 "Transformations", Capítulo 37 "Spinor Transformations"
- 坂本眞人『場の量子論 — 不変性と自由場を中心にして』 Capítulo 5 "Estructura relativista de la ecuación de Dirac", Capítulo 14 "Álgebra de Poincaré y clasificación de estados de una partícula"
- Quantum Field Theory and the Standard Model (Schwartz) Capítulo 8 "Spinors and the Dirac equation"
- Quantum Field Theory (Tong) Capítulo 4 "Lorentz group representations and spinors"
Feedback on this page
Let us know if something was unclear, incorrect, or could be improved.